SafeAlign-VLA: A Negative-Enhanced Safe Alignment Framework for Risk-Aware Autonomous Driving
Pith reviewed 2026-05-20 05:19 UTC · model grok-4.3
The pith
Negative data paired with counterfactual reasoning improves safety in vision-language-action autonomous driving models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SafeAlign-VLA is a unified framework that incorporates negative data into VLA models for autonomous driving. It first applies a counterfactual safety pairing paradigm to produce structured safety labels and counterfactual positive trajectories from risky scenarios. This is followed by negative-enhanced supervised fine-tuning for trajectory correction and then anchor-based group relative policy optimization that treats positive and negative trajectories as contrastive anchors to calculate group-relative advantages and reduce high-risk sampling.
What carries the argument
The counterfactual safety pairing paradigm that generates structured safety labels and corrected trajectories from risky scenarios, together with anchor-based group relative policy optimization that contrasts positive and negative trajectories to steer sampling.
If this is right
- Higher PDMS scores on NAVSIM v1 by adding negative data to the baseline.
- Lower collision rates on DeepAccident while preserving language and risk prediction accuracy.
- Explicit modeling of safety boundaries in long-tail scenarios through contrastive training.
- Improved failure feedback during supervised fine-tuning for trajectory correction.
Where Pith is reading between the lines
- The pairing technique could be reused to generate synthetic safety data for other sequential decision tasks outside driving.
- Consistent safety gains might support regulatory testing requirements that demand evidence of handling rare events.
- The contrastive anchor method could be combined with real-time risk sensors to adjust behavior on the fly.
Load-bearing premise
Counterfactual reasoning applied to risky driving scenarios can reliably produce accurate safety labels and safe positive trajectories.
What would settle it
A controlled experiment that replaces the generated counterfactual positive trajectories with deliberately flawed ones and checks whether the reported reductions in collision rate and gains in PDMS score disappear.
Figures



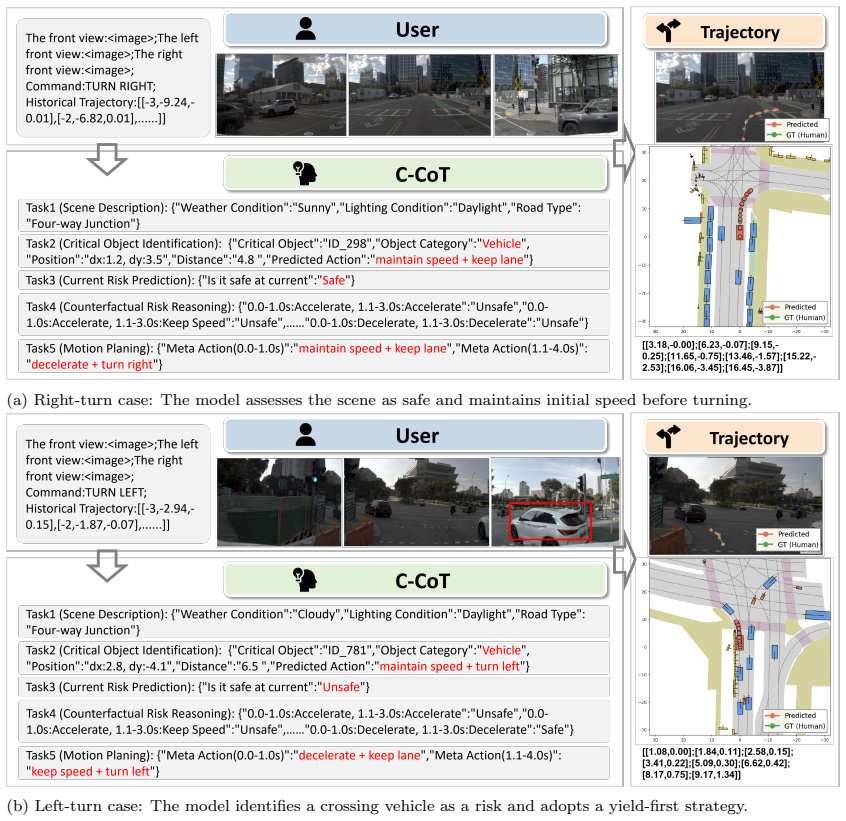

read the original abstract
End-to-end autonomous driving systems excel in common scenarios but struggle with safety-critical long-tail cases. Vision-Language-Action (VLA) models are promising due to their strong reasoning capabilities. However, most VLA-based approaches rely on positive expert demonstrations, rarely exploiting negative samples, leading to insufficient understanding of risky behaviors and safety boundaries. To address this limitation, we propose SafeAlign-VLA, a unified negative-enhanced safe alignment framework that incorporates negative data into supervised learning and reinforcement learning. First, we develop a counterfactual safety pairing paradigm to generate structured safety labels and counterfactual positive trajectories from risky scenarios via counterfactual reasoning. Then, a two-stage training strategy is adopted: negative-enhanced supervised fine-tuning for failure feedback and trajectory correction, followed by anchor-based group relative policy optimization that uses positive and negative trajectories as contrastive anchors to steer sampling and penalize high-risk behaviors via group-relative advantages. Experiments on NAVSIM and DeepAccident validate the proposed framework. SafeAlign-VLA achieves 89.1 PDMS on the NAVSIM v1 testset, improving over the baseline without negative data by 1.3%. On DeepAccident, it reduces the collision rate to 3.36%, while achieving 84.2% language accuracy and 85.8% risk prediction accuracy. These results demonstrate the effectiveness of the proposed negative-enhanced safe alignment framework for safe and robust autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SafeAlign-VLA, a negative-enhanced safe alignment framework for Vision-Language-Action (VLA) models in autonomous driving. It introduces a counterfactual safety pairing paradigm to generate structured safety labels and counterfactual positive trajectories from risky scenarios via the model's reasoning. This feeds into a two-stage process: negative-enhanced supervised fine-tuning for failure feedback and trajectory correction, followed by anchor-based group-relative policy optimization that treats positive and negative trajectories as contrastive anchors to compute group-relative advantages and penalize high-risk behaviors. Experiments on the NAVSIM v1 test set and DeepAccident benchmark report a PDMS score of 89.1 (1.3% above the no-negative-data baseline), a collision rate of 3.36%, 84.2% language accuracy, and 85.8% risk prediction accuracy.
Significance. If the counterfactual pairing reliably produces accurate positive trajectories and labels, the framework could advance risk-aware end-to-end driving by systematically incorporating negative samples to clarify safety boundaries in long-tail cases. The use of established external benchmarks (NAVSIM, DeepAccident) keeps the evaluation grounded, and the contrastive anchor mechanism in the policy optimization stage offers a concrete way to steer sampling away from risky behaviors. These elements would represent a useful contribution to safe VLA alignment if the unverified data-generation step is substantiated.
major comments (3)
- [Section 3.2] Section 3.2 (Counterfactual Safety Pairing): The paradigm generates structured safety labels and positive trajectories from risky scenarios using the model's own counterfactual reasoning, yet the manuscript supplies no independent validation against ground-truth safe behaviors, simulator rollouts, or expert annotations. This step is load-bearing for the central claims, as both the negative-enhanced SFT and the subsequent anchor-based optimization optimize against these synthesized anchors; systematic errors here would propagate directly into the reported 89.1 PDMS and 3.36% collision-rate figures.
- [Section 4] Section 4 (Experiments): The performance numbers (89.1 PDMS on NAVSIM v1, 3.36% collision rate on DeepAccident) are presented without statistical significance tests, variance across multiple runs, or ablation studies that isolate the counterfactual pairing from other training components. Without these controls, it is unclear whether the 1.3% improvement and collision reduction are attributable to genuine safety-boundary learning or to artifacts in the generated data.
- [§3.3] §3.3 (Anchor-based Group Relative Policy Optimization): The group-relative advantages are computed from positive and negative trajectory pairs to penalize high-risk behaviors, but the absence of any external check on the accuracy of the counterfactual positives means the optimization may be reinforcing flawed or overly optimistic trajectories rather than true safety improvements.
minor comments (2)
- [Abstract] Abstract: The acronym PDMS is used without definition; expand it on first use and briefly state what it measures.
- [Throughout] Throughout: Several method diagrams and result tables would benefit from explicit captions that highlight the role of negative data versus the baseline, improving readability for readers unfamiliar with the two-stage pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and describe the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Counterfactual Safety Pairing): The paradigm generates structured safety labels and positive trajectories from risky scenarios using the model's own counterfactual reasoning, yet the manuscript supplies no independent validation against ground-truth safe behaviors, simulator rollouts, or expert annotations. This step is load-bearing for the central claims, as both the negative-enhanced SFT and the subsequent anchor-based optimization optimize against these synthesized anchors; systematic errors here would propagate directly into the reported 89.1 PDMS and 3.36% collision-rate figures.
Authors: We agree that independent validation of the counterfactual safety pairing would strengthen the central claims. The current approach leverages the VLA model's reasoning to synthesize positive trajectories from risky scenarios, which is a core contribution. In the revised manuscript, we will expand Section 3.2 with a new validation subsection that includes (i) qualitative examples of the counterfactual reasoning process and (ii) quantitative consistency checks on a sampled subset of scenarios against simulator rollouts for safety metrics such as collision avoidance. These additions will help substantiate the quality of the generated anchors. revision: yes
-
Referee: [Section 4] Section 4 (Experiments): The performance numbers (89.1 PDMS on NAVSIM v1, 3.36% collision rate on DeepAccident) are presented without statistical significance tests, variance across multiple runs, or ablation studies that isolate the counterfactual pairing from other training components. Without these controls, it is unclear whether the 1.3% improvement and collision reduction are attributable to genuine safety-boundary learning or to artifacts in the generated data.
Authors: We acknowledge the value of greater statistical rigor and component isolation. In the revised Section 4, we will report all key metrics with standard deviations computed over multiple independent runs (different random seeds) and add ablation studies that systematically remove the counterfactual pairing step while keeping other components fixed. We will also include statistical significance tests (e.g., paired t-tests) comparing SafeAlign-VLA against the no-negative-data baseline to support the reported 1.3% PDMS gain and collision-rate reduction. revision: yes
-
Referee: [§3.3] §3.3 (Anchor-based Group Relative Policy Optimization): The group-relative advantages are computed from positive and negative trajectory pairs to penalize high-risk behaviors, but the absence of any external check on the accuracy of the counterfactual positives means the optimization may be reinforcing flawed or overly optimistic trajectories rather than true safety improvements.
Authors: This concern is directly linked to the validation issue raised for Section 3.2. Once the planned validation of counterfactual positives is added, we will augment §3.3 with a discussion and supporting analysis showing that the anchor-based group-relative advantages successfully steer the policy away from high-risk behaviors, as reflected in the observed collision-rate reductions on DeepAccident. We will clarify that the contrastive mechanism operates on the synthesized pairs to clarify safety boundaries even when the positives are model-generated rather than externally verified. revision: partial
Circularity Check
No significant circularity; framework grounded in external benchmarks
full rationale
The paper describes a counterfactual safety pairing paradigm and two-stage training (negative-enhanced SFT followed by anchor-based group-relative policy optimization) without presenting any equations, derivations, or first-principles results that reduce to fitted parameters or self-defined quantities by construction. Performance claims rest on evaluation against independent external benchmarks (NAVSIM v1 testset and DeepAccident), not on internal consistency checks or self-generated labels alone. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify core steps. The method introduces new components but does not rename known empirical patterns or force predictions via statistical construction from the same inputs. This is a standard non-circular empirical framework paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Counterfactual reasoning applied to risky driving scenarios produces accurate positive trajectories and structured safety labels
Reference graph
Works this paper leans on
-
[1]
J. Zhao, Y. Wu, R. Deng, S. Xu, J. Gao, A. Burke, A survey of autonomous driving from a deep learning perspective, ACM Computing Surveys 57 (10) (2025) 1–60
work page 2025
- [2]
-
[3]
S. Li, K. Yang, Z. Wei, Y. Zheng, Z. Chen, X. Tang, A survey on interaction-aware decision-making for autonomous driving: Challenges, solutions, and perspectives, IEEE Transactions on Intelligent Transportation Systems (2026)
work page 2026
-
[4]
R. Hussain, S. Zeadally, Autonomous cars: Research results, issues, and future chal- lenges, IEEE Communications Surveys & Tutorials 21 (2) (2018) 1275–1313
work page 2018
-
[5]
Y. Lian, K. Zhang, M. Li, Cdkformer: Contextual deviation knowledge-based trans- former for long-tail trajectory prediction, Transportation Research Part C: Emerging Technologies 183 (2026) 105430
work page 2026
-
[6]
S. Hu, L. Chen, P. Wu, H. Li, J. Yan, D. Tao, St-p3: End-to-end vision-based au- tonomous driving via spatial-temporal feature learning, in: European Conference on Computer Vision, Springer, 2022, pp. 533–549
work page 2022
-
[7]
Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al., Planning-oriented autonomous driving, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17853–17862
work page 2023
-
[8]
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, X. Wang, Vadv2: End-to-end vectorized autonomous driving via probabilistic planning, arXiv preprint arXiv:2402.13243 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, H. Li, End-to-end autonomous driv- ing: Challenges and frontiers, IEEE Transactions on Pattern Analysis and Machine Intelligence 46 (12) (2024) 10164–10183
work page 2024
-
[10]
F. Codevilla, E. Santana, A. M. López, A. Gaidon, Exploring the limitations of behav- ior cloning for autonomous driving, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9329–9338
work page 2019
- [11]
-
[12]
X. Hu, Y. Lian, M. Li, K. Zhang, Y. Li, Y. Su, Lift: Interpretable truck driving risk prediction with literature-informed fine-tuned llms, Transportation Research Part C: Emerging Technologies 185 (2026) 105570. 18
work page 2026
-
[13]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp, et al., Emma: End-to-end multimodal model for autonomous driving, arXiv preprint arXiv:2410.23262 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, H. Li, Drivelm: Driving with graph visual question answering, in: European Conference on Computer Vision, Springer, 2024, pp. 256–274
work page 2024
- [15]
-
[16]
Y. Wang, S. Wu, Y. Zhang, S. Yan, Z. Liu, J. Luo, H. Fei, Multimodal chain-of-thought reasoning: A comprehensive survey, arXiv preprint arXiv:2503.12605 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
M. Nie, R. Peng, C. Wang, X. Cai, J. Han, H. Xu, L. Zhang, Reason2drive: Towards in- terpretable and chain-based reasoning for autonomous driving, in: European Conference on Computer Vision, Springer, 2024, pp. 292–308
work page 2024
-
[18]
Z. Xu, Y. Zhang, E. Xie, Z. Zhao, Y. Guo, K.-Y. K. Wong, Z. Li, H. Zhao, Drivegpt4: Interpretable end-to-end autonomous driving via large language model, IEEE Robotics and Automation Letters 9 (10) (2024) 8186–8193
work page 2024
-
[19]
H. Shao, Y. Hu, L. Wang, G. Song, S. L. Waslander, Y. Liu, H. Li, Lmdrive: Closed- loop end-to-end driving with large language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15120–15130
work page 2024
-
[20]
X. Zhou, X. Han, F. Yang, Y. Ma, V. Tresp, A. Knoll, Opendrivevla: Towards end- to-end autonomous driving with large vision language action model, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40, 2026, pp. 13782–13790
work page 2026
-
[21]
X. Tian, J. Gu, B. Li, Y. Liu, Y. Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, H. Zhao, DriveVLM: The convergence of autonomous driving and large vision-language models, arXiv preprint arXiv:2402.12289 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
S. Wang, Z. Yu, X. Jiang, S. Lan, M. Shi, N. Chang, J. Kautz, Y. Li, J. M. Alvarez, Om- nidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning, in: Proceedings of the computer vision and pattern recognition conference, 2025, pp. 22442–22452
work page 2025
-
[23]
S. Shang, Y. Chen, Y. Wang, Y. Li, Z. Zhang, Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving, arXiv preprint arXiv:2509.17940 (2025)
- [24]
-
[25]
Y. Lu, J. Fu, G. Tucker, X. Pan, E. Bronstein, R. Roelofs, B. Sapp, B. White, A. Faust, S. Whiteson, et al., Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios, in: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2023, pp. 7553–7560
work page 2023
-
[26]
Z. Wang, S. Lan, X. Sun, N. Chang, Z. Li, Z. Yu, J. M. Alvarez, Enhancing autonomous driving safety with collision scenario integration, in: 2025 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), IEEE, 2025, pp. 10116–10123
work page 2025
-
[27]
J. Patrikar, A. Sharma, S. Veer, B. Li, S. Scherer, M. Pavone, The case for nega- tive data: From crash reports to counterfactuals for reasonable driving, arXiv preprint arXiv:2509.18626 (2025)
-
[28]
R. Sapkota, Y. Cao, K. I. Roumeliotis, M. Karkee, Vision-language-action models: Con- cepts, progress, applications and challenges, arXiv preprint arXiv:2505.04769 (2025)
- [29]
-
[30]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, X. Wang, Senna: Bridging large vision-language models and end-to-end autonomous driving, arXiv preprint arXiv:2410.22313 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
B. Jiang, S. Chen, Q. Zhang, W. Liu, X. Wang, Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning, arXiv preprint arXiv:2503.07608 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, X. Bai, Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation, in: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2025, pp. 24823–24834
work page 2025
-
[33]
R. Zhao, Q. Yuan, J. Li, H. Hu, Y. Li, Z. Gao, F. Gao, Sce2drivex: A generalized mllm framework for scene-to-drive learning, IEEE Robotics and Automation Letters (2025)
work page 2025
-
[34]
Y. Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, et al., Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving, arXiv preprint arXiv:2506.08052 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
K. Renz, L. Chen, E. Arani, O. Sinavski, Simlingo: Vision-only closed-loop autonomous driving with language-action alignment, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11993–12003
work page 2025
-
[36]
K. Tian, Y. Lian, K. Yang, X. Chen, S. Li, C-cot: Counterfactual chain-of-thought with vision-language models for safe autonomous driving, arXiv preprint arXiv:2605.10744 (2026). 20
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [37]
-
[38]
J. Cheng, Y. Chen, Q. Chen, Pluto: Pushing the limit of imitation learning-based planning for autonomous driving, arXiv preprint arXiv:2404.14327 (2024)
-
[39]
W. Sun, X. Lin, Y. Shi, C. Zhang, H. Wu, S. Zheng, Sparsedrive: End-to-end au- tonomous driving via sparse scene representation, in: 2025 IEEE International Confer- ence on Robotics and Automation (ICRA), IEEE, 2025, pp. 8795–8801
work page 2025
-
[40]
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, Y. Qiao, Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline, Advances in Neural Information Processing Systems 35 (2022) 6119–6132
work page 2022
- [41]
-
[42]
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
M. Bansal, A. Krizhevsky, A. Ogale, Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst, arXiv preprint arXiv:1812.03079 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Z. Zhou, R. Yang, Y. Guo, S. X. Chen, T. Feng, K. Pistunova, Y. Shen, L. Su, J. Ma, et al., Spanvla: Efficient action bridging and learning from negative-recovery samples for vision-language-action model, arXiv preprint arXiv:2604.19710 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [44]
- [45]
- [46]
-
[47]
S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Pollefeys, T. Funkhouser, et al., Openscene: 3d scene understanding with open vocabularies, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 815– 824
work page 2023
-
[48]
T. Wang, S. Kim, J. Wenxuan, E. Xie, C. Ge, J. Chen, Z. Li, P. Luo, Deepaccident: A motion and accident prediction benchmark for v2x autonomous driving, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 2024, pp. 5599–5606. 21
work page 2024
-
[49]
National Transportation Safety Board, The use of forward collision avoidance systems to prevent and mitigate rear-end crashes, Special Investigation Report NTSB/SIR-15/01, National Transportation Safety Board, Washington, DC, pB2015-104098 (May 2015)
work page 2015
-
[50]
A. Prakash, K. Chitta, A. Geiger, Multi-modal fusion transformer for end-to-end au- tonomous driving, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7077–7087
work page 2021
-
[51]
X. Weng, B. Ivanovic, Y. Wang, Y. Wang, M. Pavone, Para-drive: Parallelized architec- ture for real-time autonomous driving, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15449–15458
work page 2024
-
[52]
R. Feng, N. Xi, D. Chu, R. Wang, Z. Deng, A. Wang, L. Lu, J. Wang, Y. Huang, Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving, IEEE Robotics and Automation Letters 11 (1) (2025) 226–233
work page 2025
-
[53]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y. Zhang, Q. Zhang, et al., Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12037–12047
work page 2025
-
[54]
Y. Li, Y. Wang, Y. Liu, J. He, L. Fan, Z. Zhang, End-to-end driving with online trajec- tory evaluation via bev world model, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 27137–27146
work page 2025
-
[55]
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, Y. Duan, H. Tian, W. Su, J. Shao, et al., InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models, arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al., Qwen3-vl technical report, arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Y. Chen, Y. Wang, Z. Zhang, Drivinggpt: Unifying driving world modeling and plan- ning with multi-modal autoregressive transformers, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26890–26900
work page 2025
-
[58]
B. Xiao, C. Feng, Z. Huang, F. Yan, Y. Zhong, L. Ma, Robotron-sim: improving real- world driving via simulated hard-case, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 27380–27389
work page 2025
-
[59]
Z. Zhou, T. Cai, S. Zhao, Y. Zhang, Z. Huang, B. Zhou, J. Ma, Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcementfine-tuning, AdvancesinNeuralInformationProcessingSystems38(2026) 27920–27956. 22 Appendix A. Implementation Details Appendix A.1. Network Architecture Our model architecture cons...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.