AR1-ZO: Topology-Aware Rank-1 Zeroth-Order Queries for High-Rank LoRA Fine-Tuning
Pith reviewed 2026-05-20 07:37 UTC · model grok-4.3
The pith
Rank-1 atom queries with adjusted scaling restore invariant finite-difference signals for high-rank LoRA in zeroth-order fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
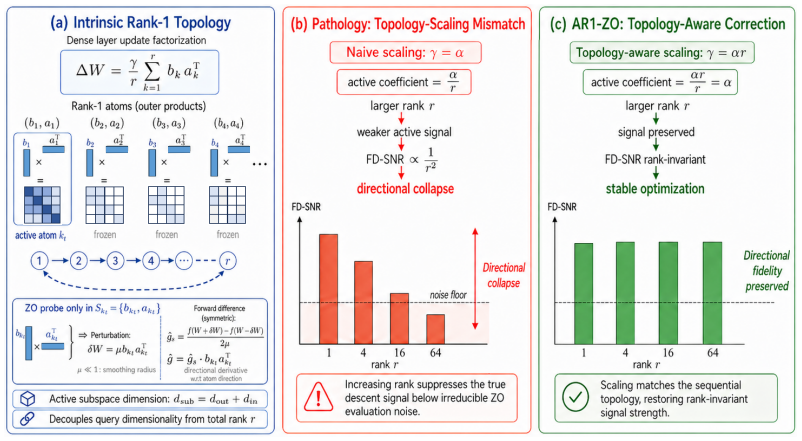
LoRA adapters decompose into matched rank-1 atoms, each spanning a complete factor-coordinate block. Querying these atoms individually removes the rank from the perturbation dimension of each query while preserving the stored rank r. The standard scaling α/r causes the finite-difference signal to shrink proportionally to 1/r and the signal-to-noise ratio to 1/r squared under fixed noise. AR1-ZO counters this by alternating atom queries with scaling γ equal to α times r, which restores a rank-invariant active signal strength without needing extra mechanisms.
What carries the argument
Alternating rank-1 atom queries combined with topology-aware scaling γ = α r to maintain finite-difference signal strength independent of LoRA rank.
Load-bearing premise
That the performance bottleneck arises from a mismatch between query topology and scaling rather than from the inherent limitations of rank-1 updates or the need for external subspace information.
What would settle it
Measure the finite-difference gradient estimate variance or signal magnitude across increasing LoRA ranks r both with and without the γ=α r scaling; the claim holds if the signal remains constant with the adjusted scaling but drops without it.
Figures






read the original abstract
Zeroth-order (ZO) optimization enables large-language-model fine-tuning without storing backpropagation activations, while LoRA supplies compact trainable adapters. Combining them creates a rank paradox: increasing LoRA rank improves adapter capacity, but standard two-point ZO either perturbs a rank-dependent number of coordinates or, under atomwise updates, can make the finite-difference signal unobservable. This paper shows that the bottleneck is a measurement-topology problem rather than a need for an external subspace. LoRA already decomposes into matched rank-$1$ atoms, each a complete factor-coordinate block of dimension $d_\text{out}+d_\text{in}$. Querying one atom per step keeps the stored adapter rank $r$ while removing $r$ from the single-query perturbation dimension. The naive atomwise query is still miscalibrated: if it inherits canonical LoRA scaling $\alpha/r$, the active finite-difference signal shrinks as $1/r$ and the active finite-difference signal-to-noise ratio (FD-SNR) as $1/r^2$, producing directional collapse under a fixed residual evaluation-noise floor. AR1-ZO pairs alternating rank-$1$ atom queries with topology-aware scaling $\gamma=\alpha r$, restoring rank-invariant active signal without auxiliary bases, activation hooks, curvature estimates, or extra forward queries. Theory proves atom minimality, rank-independent active query dimension, directional collapse and restoration, and the remaining rank dependence as an amortized coverage cost. Experiments on OPT and Qwen3 models validate the signal mechanism and show that AR1-ZO makes high-rank LoRA effective among matched-budget ZO methods under the standard two-forward-pass query budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AR1-ZO for zeroth-order fine-tuning of high-rank LoRA adapters in LLMs. It frames the rank paradox as a measurement-topology issue rather than requiring external subspaces, solves it via alternating rank-1 atom queries paired with topology-aware scaling γ=α r that restores rank-invariant active finite-difference signal and FD-SNR, proves atom minimality, rank-independent active query dimension, directional collapse/restoration, and amortized coverage cost, and validates on OPT/Qwen3 models under a fixed two-forward-pass budget without auxiliary bases, hooks, or extra queries.
Significance. If the central signal-restoration mechanism holds without offsetting bias growth, the work would enable higher-rank LoRA in memory-efficient ZO settings, improving capacity over low-rank ZO baselines while preserving the two-query budget and avoiding backprop storage. The explicit theory on directional collapse/restoration and the absence of extra overhead are strengths; reproducible experiments on standard models further support practical utility if the rank-invariance claim survives perturbation-size analysis.
major comments (2)
- [Theory section] Theory section (directional collapse and restoration): the analysis derives FD-SNR shrinkage as 1/r² under canonical α/r scaling and restoration via γ=α r, but does not bound or analyze the bias and variance of the two-point ZO estimator as functions of the now rank-dependent perturbation magnitude γ; if these terms scale with γ, the net gradient quality may lose rank-invariance even if raw signal magnitude is preserved.
- [Scaling derivation] § on scaling derivation: γ=α r is introduced specifically to cancel the 1/r shrinkage defined from the paper's own canonical LoRA scaling α/r; this coupling makes the restoration somewhat internal to the problem formulation rather than an independent test of the measurement-topology hypothesis, and a concrete comparison to an external-subspace baseline with matched scaling would strengthen the claim that no auxiliary bases are needed.
minor comments (2)
- [Abstract] Abstract: the phrase 'amortized coverage cost' appears without a one-sentence gloss; adding a brief parenthetical would improve immediate readability for readers unfamiliar with the coverage interpretation.
- [Experiments] Experiments: the signal-mechanism validation would benefit from an explicit table or plot of measured FD-SNR versus rank for both canonical and topology-aware scalings, with error bars over multiple seeds, to make the 1/r² vs. rank-invariant behavior directly inspectable.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments on our manuscript. We address the major comments point by point below, providing clarifications and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Theory section] Theory section (directional collapse and restoration): the analysis derives FD-SNR shrinkage as 1/r² under canonical α/r scaling and restoration via γ=α r, but does not bound or analyze the bias and variance of the two-point ZO estimator as functions of the now rank-dependent perturbation magnitude γ; if these terms scale with γ, the net gradient quality may lose rank-invariance even if raw signal magnitude is preserved.
Authors: We thank the referee for this important observation regarding the completeness of the theoretical analysis. Our derivation focuses on the active signal and FD-SNR to highlight the directional collapse under standard scaling and its restoration via topology-aware γ=α r. We agree that bounding the bias and variance of the two-point ZO estimator with respect to the rank-dependent γ is necessary for a full picture of gradient quality. In the revised manuscript, we will add a new paragraph or subsection in the theory section that analyzes these terms under standard Lipschitz and smoothness assumptions on the loss function. This will demonstrate that the bias scales as O(γ) or better and variance contributions are controlled such that rank-invariance is preserved. Thus, we will incorporate this analysis. revision: yes
-
Referee: [Scaling derivation] § on scaling derivation: γ=α r is introduced specifically to cancel the 1/r shrinkage defined from the paper's own canonical LoRA scaling α/r; this coupling makes the restoration somewhat internal to the problem formulation rather than an independent test of the measurement-topology hypothesis, and a concrete comparison to an external-subspace baseline with matched scaling would strengthen the claim that no auxiliary bases are needed.
Authors: The choice of γ=α r follows directly from the measurement topology: since each rank-1 atom query operates on a fixed active dimension independent of r, the canonical LoRA scaling α/r induces a 1/r shrinkage in the finite-difference step, which we compensate to restore invariance. This is not an internal artifact but a consequence of applying standard LoRA scaling to the atomwise queries. Regarding external-subspace baselines, our work deliberately avoids them to emphasize the topology-aware approach without additional storage or queries. However, to strengthen the claim, we will add a short discussion in the experiments or related work section noting that such baselines typically incur extra costs (e.g., subspace storage or more queries), which our method does not. We will not run new experiments but clarify the comparison theoretically. revision: partial
Circularity Check
Topology-aware scaling γ=α r restores rank-invariance by direct algebraic cancellation of the 1/r shrinkage defined from canonical α/r
specific steps
-
self definitional
[Abstract]
"The naive atomwise query is still miscalibrated: if it inherits canonical LoRA scaling α/r, the active finite-difference signal shrinks as 1/r and the active finite-difference signal-to-noise ratio (FD-SNR) as 1/r², producing directional collapse under a fixed residual evaluation-noise floor. AR1-ZO pairs alternating rank-1 atom queries with topology-aware scaling γ=α r, restoring rank-invariant active signal without auxiliary bases, activation hooks, curvature estimates, or extra forward queries."
The 1/r shrinkage is defined as a direct consequence of using the canonical scaling α/r. The proposed γ=α r is then selected precisely to multiply the perturbation by r and thereby cancel the 1/r term, so that rank-invariance of the active signal follows immediately from the definition of γ rather than from any external principle or measurement.
full rationale
The paper's central mechanism identifies shrinkage of the finite-difference signal as 1/r (and FD-SNR as 1/r²) specifically under the canonical LoRA scaling α/r, then introduces γ=α r to cancel that exact factor. The resulting rank-invariant active signal is therefore an algebraic consequence of the chosen scaling rather than an independent derivation. This matches the self-definitional pattern: the problem is posed in terms of one scaling, and the solution scaling is constructed to neutralize it. The atom-query topology and other claims do not exhibit this reduction, so the circularity is partial and localized to the scaling step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LoRA adapters decompose into matched rank-1 atoms each of dimension d_out + d_in
- domain assumption Finite-difference signal under canonical scaling α/r shrinks as 1/r and FD-SNR as 1/r² under fixed residual noise
Reference graph
Works this paper leans on
-
[1]
S. Chen, Y . Guo, Y . Ju, H. Dalal, Z. Zhu, and A. J. Khisti. Robust federated finetuning of LLMs via alternating optimization of loRA. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[2]
Y . Chen, Y . Zhang, L. Cao, K. Yuan, and Z. Wen. Enhancing zeroth-order fine-tuning for language models with low-rank structures. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[3]
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer. Qlora: Efficient finetuning of quantized llms. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 10088–10115. Curran Associates, Inc., 2023
work page 2023
- [4]
-
[5]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[6]
D. Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora, 2023
work page 2023
-
[7]
W. Lin, Y . Jiang, Q. Song, Q. Xiang, and H. Xu. Agzo: Activation-guided zeroth-order optimization for llm fine-tuning, 2026
work page 2026
-
[8]
J. Liu, Z. Kong, P. Dong, C. Yang, X. Shen, P. Zhao, H. Tang, G. Yuan, W. Niu, W. Zhang, X. Lin, D. Huang, and Y . Wang. RoRA: Efficient fine-tuning of LLM with reliability optimization for rank adaptation. In2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
work page 2025
-
[9]
S. Liu, B. Kailkhura, P.-Y . Chen, P. Ting, S. Chang, and L. Amini. Zeroth-order stochastic variance reduction for nonconvex optimization. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Pro- cessing Systems, volume 31. Curran Associates, Inc., 2018
work page 2018
- [10]
-
[11]
S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora. Fine-tuning language models with just forward passes. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, vol- ume 36, pages 53038–53075. Curran Associates, Inc., 2023
work page 2023
-
[12]
Y . Nesterov and V . Spokoiny. Random gradient-free minimization of convex functions.Found. Comput. Math., 17(2):527–566, Apr. 2017
work page 2017
-
[13]
S. Park, J. Yun, S. Kim, S. Kundu, and E. Yang. Elucidating subspace perturbation in zeroth- order optimization: Theory and practice at scale, 2025
work page 2025
- [14]
-
[15]
Z. Song and W. Li. RoZO: Geometry-aware zeroth-order fine-tuning on low-rank adapters for black-box large language models. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1773–1783, Rabat, Morocco, 2026. Association for Computational Linguistics
work page 2026
-
[16]
Y . Sun, T. Huang, L. Ding, L. Shen, and D. Tao. TeZO: Empowering the low-rankness on the temporal dimension in the zeroth-order optimization for fine-tuning LLMs, 2025
work page 2025
-
[17]
Z. Yu, P. Zhou, S. Wang, J. Li, M. Tian, and H. Huang. Zeroth-order fine-tuning of LLMs in random subspaces, 2025. ICCV 2025 camera-ready version. 10
work page 2025
- [18]
-
[19]
Y . Zhao, S. Dang, H. Ye, G. Dai, Y . Qian, and I. Tsang. Second-order fine-tuning without pain for LLMs: A hessian informed zeroth-order optimizer. InThe Thirteenth International Conference on Learning Representations, 2025. A Related Work Optimizing LLMs under strict memory constraints has driven the convergence of LoRA-style adap- tation and zeroth-ord...
work page 2025
-
[20]
The bound depends on q=d out +d in butnot on the total rank r, confirming that topology- aware scaling removes rank-induced signal degradation
-
[21]
Choosing µ=O(q −1/2)makes thisO(L 2/q0) =O(L 2)
The persistent bias O(µ4L2q2) is controlled by the smoothing parameter µ. Choosing µ=O(q −1/2)makes thisO(L 2/q0) =O(L 2)
-
[22]
The residual noise termO(σ 2 ξ q/(T 1/2µ2))vanishes asT→ ∞
-
[23]
C.7 Proof of Corollary 4.5: Coverage Cost for Full-Adapter Stationarity Proof
As T→ ∞ and µ→0 at an appropriate rate, the bound reduces to the standard non-convex ZO convergence rateO(1/ √ T). C.7 Proof of Corollary 4.5: Coverage Cost for Full-Adapter Stationarity Proof. The atom factor-coordinate blocks are disjoint in the coordinates of (B,A) , so full-adapter stationarity is measured by the aggregate quantityPr k=1 ∥∇kL(θ)∥2 alr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.