LionMuon: Alternating Spectral and Sign Descent for Efficient Training
Pith reviewed 2026-05-20 07:21 UTC · model grok-4.3
The pith
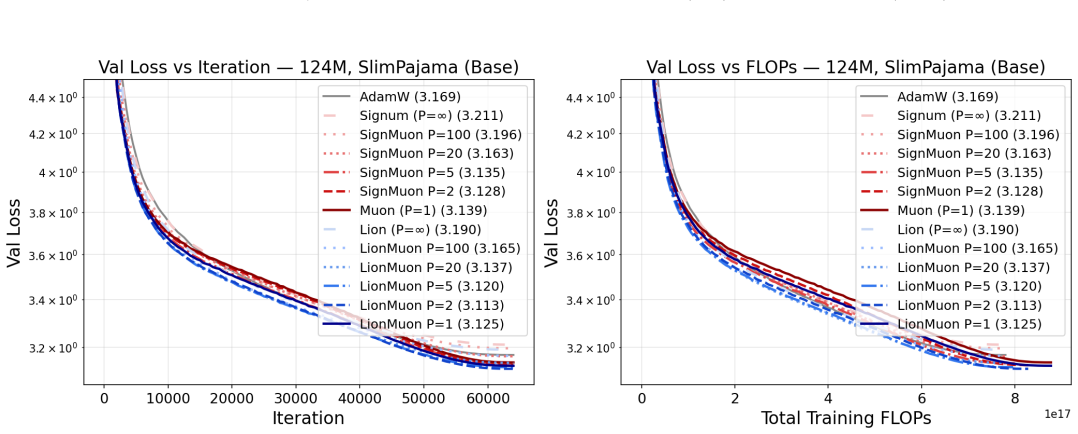
By alternating between Muon spectral steps and Lion sign steps every two iterations, LionMuon reaches lower validation loss at lower total compute than either optimizer alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LionMuon alternates Lion and Muon steps with period P and a shared dual-EMA buffer to match Lion's memory footprint while delivering Muon-level direction strength on average. At P equals 2 this hybrid Pareto-dominates the baselines on tested tasks from 124 million to 720 million parameters. The analysis proves complexity bounds under heavy-tailed noise that are controlled by the period-averaged smoothness and noise constants, which lie between those of the parent methods and correctly predict the best period.
What carries the argument
The fixed-period alternation between sign descent and spectral matrix-sign descent that shares a single dual-EMA momentum buffer, thereby interpolating per-step cost and update quality between Lion and Muon.
If this is right
- Complexity bounds directly predict the compute-optimal period from any measured smoothness and noise pair.
- The simpler single-EMA SignMuon variant already improves over pure Muon.
- Memory cost stays identical to Lion and half that of AdamW.
- The performance edge holds when scaling from 124 million to 720 million parameters.
Where Pith is reading between the lines
- The same fixed-period alternation could be tested with other pairs of low-cost and high-quality updates to discover new hybrids.
- Period averaging of smoothness and noise may serve as a general rule for designing efficient non-convex optimizers.
- Direct measurements of per-phase smoothness and noise on real runs could check whether the interpolation assumption holds in practice.
Load-bearing premise
The smoothness and noise levels averaged over each period accurately describe the real training dynamics and combine without extra penalties from the act of switching between the two update rules.
What would settle it
Repeating the 124-million-parameter experiments on a new dataset or architecture and finding that LionMuon at period 2 no longer reaches lower loss at lower total compute than the four baselines would disprove the reported dominance.
Figures












read the original abstract
In large-scale optimization, the cheapness and effectiveness of update steps are the most crucial factors for a successful optimizer. Sign-based optimizers like Lion or Signum produce cheap per-step updates, whereas Muon's spectral matrix-sign update gives a much stronger direction at a substantially higher per-step cost. In this work, we propose LionMuon, which retains the effectiveness of Muon steps while considerably cutting the averaged iteration cost, similar to sign-based methods. It alternates between Lion's and Muon's updates on a fixed period P, sharing a single dual-EMA momentum buffer between them. The optimizer state memory therefore matches Lion and is exactly half of AdamW's. A simpler single-EMA variant, SignMuon, by itself already outperforms pure Muon. At P = 2, LionMuon Pareto-dominates Muon, Lion, Signum, and AdamW on every dataset and architecture we tested at 124M model size, reaching lower validation loss at lower compute, and the same advantage persists at 355M and 720M scale. On the theory side, we prove sharp complexity bounds under heavy-tailed noise which are governed by period-averaged smoothness and noise that interpolate between Muon's and Lion's constants. These bounds predict the compute-optimal period and the conditions under which LionMuon outruns Muon and Lion. Code: https://github.com/brain-lab-research/lion-muon
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LionMuon, an optimizer that alternates between Lion (sign-based) and Muon (spectral matrix-sign) updates on a fixed period P while sharing a single dual-EMA momentum buffer. It claims that at P=2 this method Pareto-dominates Muon, Lion, Signum, and AdamW across datasets and architectures at 124M, 355M, and 720M scales, achieving lower validation loss at lower compute. A simpler SignMuon variant already beats pure Muon. On the theory side, sharp complexity bounds are derived under heavy-tailed noise; the leading constants are period averages of per-regime smoothness and noise parameters that are asserted to interpolate between the pure-Muon and pure-Lion regimes and to predict the observed compute-optimal period.
Significance. If the empirical Pareto dominance and the interpolation property of the averaged constants both hold, the result would be significant for large-scale training: it combines the low per-step cost and memory footprint of sign methods with the stronger directional information of spectral methods without doubling optimizer state. The explicit complexity bounds under heavy-tailed assumptions and the prediction of an optimal switching period constitute a concrete theoretical contribution that could guide further hybrid optimizer design.
major comments (2)
- [Experiments] Experimental section: the central claim of consistent Pareto dominance at P=2 across three model scales rests on reported validation-loss curves, yet the manuscript provides neither data-split details, the precise hyper-parameter search protocol, nor statistical significance tests (e.g., multiple random seeds or confidence intervals). Without these, the empirical superiority cannot be independently verified and remains load-bearing for the main result.
- [Theory] Theory section: the complexity bounds are stated to be governed by period-averaged smoothness and noise constants that 'interpolate between Muon's and Lion's constants.' The manuscript does not supply the explicit definitions of these averages, nor does it demonstrate (analytically or numerically) that the alternation itself introduces no extra effective Lipschitz or tail cost beyond a convex combination. This assumption is load-bearing for the claim that the bounds predict the compute-optimal P=2 and explain the observed outperformance.
minor comments (2)
- [Abstract] The abstract and introduction use 'Pareto-dominates' without defining the precise axes (validation loss vs. total FLOPs or wall-clock time). A short clarifying sentence would remove ambiguity.
- [Method] Notation for the shared dual-EMA buffer and the spectral/sign switch should be introduced once with a compact equation rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the reproducibility and clarity of both the experimental and theoretical sections.
read point-by-point responses
-
Referee: [Experiments] Experimental section: the central claim of consistent Pareto dominance at P=2 across three model scales rests on reported validation-loss curves, yet the manuscript provides neither data-split details, the precise hyper-parameter search protocol, nor statistical significance tests (e.g., multiple random seeds or confidence intervals). Without these, the empirical superiority cannot be independently verified and remains load-bearing for the main result.
Authors: We agree that these details are necessary for independent verification. In the revised manuscript we will add an expanded Experiments subsection that specifies the exact train/validation/test splits for each dataset and architecture, the complete hyper-parameter search protocol (including the grid or random search ranges for learning rate, EMA coefficients, weight decay, and any other tuned values, together with the selection criterion), and statistical results obtained from at least three independent random seeds, reported as mean validation loss with 95% confidence intervals. These additions will directly support the Pareto-dominance claims. revision: yes
-
Referee: [Theory] Theory section: the complexity bounds are stated to be governed by period-averaged smoothness and noise constants that 'interpolate between Muon's and Lion's constants.' The manuscript does not supply the explicit definitions of these averages, nor does it demonstrate (analytically or numerically) that the alternation itself introduces no extra effective Lipschitz or tail cost beyond a convex combination. This assumption is load-bearing for the claim that the bounds predict the compute-optimal P=2 and explain the observed outperformance.
Authors: We acknowledge that the explicit definitions and the justification for the interpolation were insufficiently detailed. In the revision we will insert the precise mathematical definitions of the period-averaged smoothness and noise constants (as explicit convex combinations of the per-regime constants weighted by the fraction of Lion versus Muon steps within each period P). We will also add a short remark (or appendix paragraph) showing that, under the stated heavy-tailed noise model, the alternation introduces no additional effective Lipschitz or tail-index cost beyond the convex combination; this follows directly from the triangle inequality applied to the per-step gradient norms and the sub-exponential tail bounds already used in the proof. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives its complexity bounds from first principles under heavy-tailed noise assumptions, using period-averaged smoothness and noise constants that are stated to interpolate between the pure Muon and Lion regimes. These bounds are presented as mathematical results that then predict the compute-optimal period, without evidence that the constants were fitted to the experimental runs or that P=2 was chosen first and the theory retrofitted. The empirical Pareto-dominance claims at 124M/355M/720M scales rest on direct training runs rather than on the theory. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided derivation steps. The analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- switching period P
axioms (1)
- domain assumption Gradient noise is heavy-tailed with finite moments that allow interpolation between Muon and Lion constants
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
period-averaged smoothness and noise constants that interpolate between Muon's and Lion's constants... These bounds predict the compute-optimal period
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
period P determines the interpolation between Muon's and Lion's smoothness and noise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Kimi K2: Open Agentic Intelligence
10 Figure 4: Best validation loss vs. total training FLOPs on FineWeb / GPT-2 at355M(1×Chinchilla,∼23TPP, left) and720M(1/4Chinchilla,∼5TPP,right). At 355M the alternating methods (LionMuonandSignMuonat smallP) Pareto-dominate pureMuon. At under-trained 720M,SignMuonP=2still beats pureMuon, the alternation effect survives the scale jump. Kimi Team. Kimi K...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
George E. Dahl, Frank Schneider, Zachary Nado, Naman Agarwal, Chandramouli Shama Sastry, Philipp Hennig, Sourabh Medapati, Runa Eschenhagen, Priya Kasimbeg, Daniel Suo, Juhan Bae, Justin Gilmer, Abel L. Peirson, Bilal Khan, Rohan Anil, Mike Rabbat, Shankar Krishnan, Daniel Snider, Ehsan Amid, Kongtao Chen, Chris J. Maddison, Rakshith Vasudev, Michal Badur...
-
[3]
Preconditioned Norms: A Unified Framework for Steepest Descent, Quasi-Newton and Adaptive Methods
Andrey Veprikov, Arman Bolatov, Samuel Horv´ ath, Aleksandr Beznosikov, Martin Tak´ aˇ c, and Slavomir Hanzely. Preconditioned norms: A unified framework for steepest descent, quasi-newton and adaptive methods.arXiv preprint arXiv:2510.10777,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Doll´ ar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is sca...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Old Optimizer, New Norm: An Anthology
URLhttps://arxiv.org/ abs/2409.20325. Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
signSGD with Majority Vote is Communication Efficient And Fault Tolerant
Jeremy Bernstein, Jiawei Zhao, Kamyar Azizzadenesheli, and Anima Anandkumar. signsgd with majority vote is communication efficient and fault tolerant.arXiv preprint arXiv:1810.05291, 2018b. Egor Petrov, Grigoriy Evseev, Aleksey Antonov, Andrey Veprikov, Nikolay Bushkov, Stanislav Moiseev, and Alek- sandr Beznosikov. Leveraging coordinate momentum in signs...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Nikita Kornilov, Philip Zmushko, Andrei Semenov, Mark Ikonnikov, Alexander Gasnikov, and Alexander Beznosikov. Sign operator for coping with heavy-tailed noise in non-convex optimization: High probability bounds under(l 0, l1)-smoothness.arXiv preprint arXiv:2502.07923,
-
[9]
Sign-Based Optimizers Are Effective Under Heavy-Tailed Noise
Dingzhi Yu, Hongyi Tao, Yuanyu Wan, Luo Luo, and Lijun Zhang. Sign-based optimizers are effective under heavy-tailed noise.arXiv preprint arXiv:2602.07425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2603.10067. Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295,
-
[11]
arXiv preprint arXiv:2510.16981 , year=
Ahmed Khaled, Kaan Ozkara, Tao Yu, Mingyi Hong, and Youngsuk Park. MuonBP: Faster Muon via block-periodic orthogonalization.arXiv preprint arXiv:2510.16981,
- [12]
-
[13]
Noah Amsel, David Persson, Christopher Musco, and Robert M
URLhttps://arxiv.org/abs/2602.01105. Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The Polar Express: Optimal matrix sign methods and their application to the Muon algorithm.arXiv preprint arXiv:2505.16932,
-
[14]
URLhttps://arxiv.org/abs/2506.10935. Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank-wolfe.arXiv preprint arXiv:2506.04192,
-
[15]
Improving Generalization Performance by Switching from Adam to SGD
Nitish Shirish Keskar and Richard Socher. Improving generalization performance by switching from Adam to SGD. arXiv preprint arXiv:1712.07628,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Adaptive Gradient Methods with Dynamic Bound of Learning Rate
Liangchen Luo, Yuanhao Xiong, Yan Liu, and Xu Sun. Adaptive gradient methods with dynamic bound of learning rate.arXiv preprint arXiv:1902.09843,
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[17]
From gradient clipping to normalization for heavy tailed sgd.arXiv preprint arXiv:2410.13849,
Florian H¨ ubler, Ilyas Fatkhullin, and Niao He. From gradient clipping to normalization for heavy tailed sgd.arXiv preprint arXiv:2410.13849,
- [18]
-
[19]
On the Convergence Analysis of Muon
13 Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon. arXiv preprint arXiv:2505.23737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Asgo: Adaptive structured gradient optimization.arXiv preprint arXiv:2503.20762,
Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. Asgo: Adaptive structured gradient optimization.arXiv preprint arXiv:2503.20762,
-
[21]
Shuntaro Nagashima and Hideaki Iiduka. Improved convergence rates of muon optimizer for nonconvex optimiza- tion.arXiv preprint arXiv:2601.19400,
-
[22]
Hideaki Iiduka. Muon converges under heavy-tailed noise: Nonconvex h\"{o}lder-smooth empirical risk minimiza- tion.arXiv preprint arXiv:2603.15059,
-
[23]
arXiv preprint arXiv:2509.01440 , year=
Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pre- training.arXiv preprint arXiv:2509.01440,
-
[24]
Nikita Kornilov, Aleksandr Beznosikov, and Alexander Gasnikov. Accelerated stochastic ExtraGradient: Mixing hessian and gradient similarity to reduce communication in distributed and federated learning.arXiv preprint arXiv:2305.15938,
-
[25]
From gradient clipping to normalization for heavy tailed sgd
Florian H¨ ubler, Ilyas Fatkhullin, and Niao He. From gradient clipping to normalization for heavy tailed sgd. In AISTATS 2025,
work page 2025
-
[26]
t−1X j=0 βj 2 (1−β 2)St−j +β 2Rt−j ⋆ # ≤β t 2 · ∥E0∥⋆ + t−1X j=0 βj+1 2 E[∥Rt−j∥⋆] +E
∇f(W t)−G t . Further, we use the notationsSt =∇f(W t)−G t andR t =∇f(W t)− ∇f(W t−1)to unroll the recursion: Et =β 2Et−1 + (1−β 2)St +β 2Rt =β t 2E0 + t−1X j=0 βj 2 (1−β 2)St−j +β 2Rt−j . Now, we observe that ∥Rt−j∥⋆ =∥∇f(W t−j)− ∇f(W t−j−1)∥⋆ ≤L∥W t−j −W t−j−1∥=Lη t−1∥Ut−j−1∥ ≤LA. Therefore, we estimate using the norm equivalence Assumption 3: E[∥Et∥⋆]≤...
work page 2023
-
[27]
Taking the maximum over these two cases forP∈(1,∞), we getA2 = max{ηM , α·η L}
Using the norm equality (11), we have∥Uτ ∥2 ≈αand stepsizeη τ =η L. Taking the maximum over these two cases forP∈(1,∞), we getA2 = max{ηM , α·η L}. WhenP= 1, allτsteps belong only toSmuon andA 2 =η M . Step 2: Refined analysis of theLionSteps (t∈Slion).Fort∈S lion, the update utilizes the infinite norm∥·∥∞. To use Lemmas 1 and 2, we estimate the uniform u...
work page 2024
-
[28]
The selected cells areSignMuonP=2:(η M , ηL)=(3×10−3,2×10 −5);SignMuonP=5:(5×10 −3,2×10 −5);SignMuon 31 T able 3:Full experimental configuration. Model architecture Number of layers 12 Number of heads 12 Embedding dim 768 Sequence length 512 Vocabulary size 50,304 (GPT-2 BPE) Architectures GPT-2 base; LLaMA (no biases, RoPE, SwiGLU) Training schedule Iter...
work page 2025
-
[29]
32 Figure 5: Hyperparameter tuning heatmap across all methods. Inductive step:assumingM ′ t−1 = (1−β)M t−1, we have M ′ t =βM ′ t−1 + (1−β)G t =β(1−β)M t−1 + (1−β)G t = (1−β) βMt−1 +G t = (1−β)M t. Since bothmsignandsignare positively homogeneous of degree zero (i.e.,msign(αX) = msign(X)for anyα >0), the update directionsmsign(M t)andmsign(M ′ t)are ident...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.