When Does Model Collapse Occur in Structured Interactive Learning?
Pith reviewed 2026-05-20 06:27 UTC · model grok-4.3
The pith
Model collapse occurs exactly when the interaction graph satisfies a specific topological condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
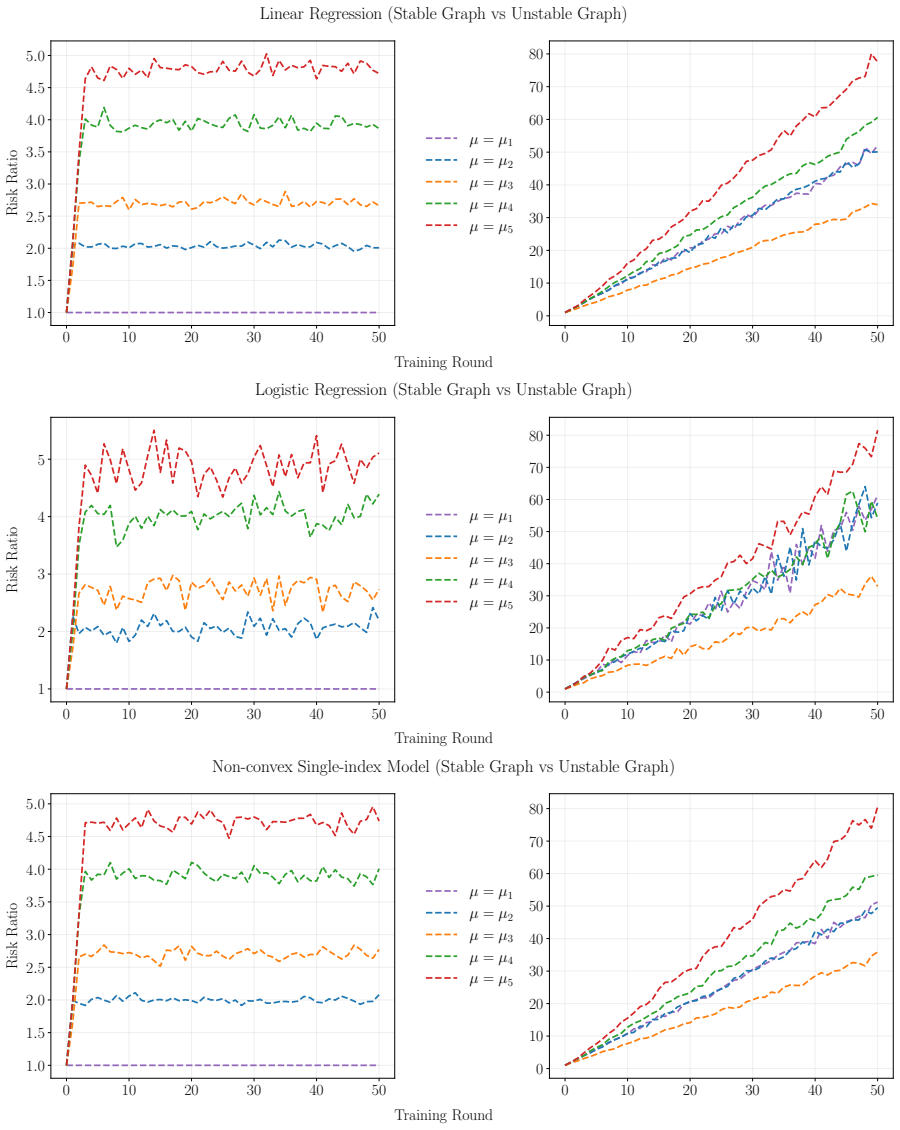
We formalize model interactions using directed graphs and derive an explicit necessary and sufficient condition characterizing when model collapse occurs. We further establish finite-sample results for linear regression and asymptotic guarantees for general M-estimators.
What carries the argument
Directed graph representation of model interactions, which encodes how synthetic outputs flow between models and determines collapse through its topology.
Load-bearing premise
Model interactions in the interactive learning environment can be accurately captured by a fixed directed graph topology without additional dynamics or feedback beyond the graph edges.
What would settle it
An experiment that runs models on an interaction graph satisfying the derived condition and checks whether collapse occurs or fails to occur.
Figures











read the original abstract
The proliferation of generative artificial intelligence has given rise to an interactive learning environment, where model parameters are continuously updated using not only data generated by natural processes, but also synthetic outputs produced by other models. This paradigm introduces two major challenges: (1) training data are no longer drawn exclusively from the target population, undermining a core assumption of classical statistical learning, and (2) model training processes become inherently correlated, as models interact with one another through repeated exposure to each other's synthetic outputs in a potentially complex manner. Establishing reliable statistical inference in such structured interactive learning environments therefore remains an important open problem. In particular, there is growing concern about model collapse, a phenomenon in which the performance of generative models progressively degrades as they are trained on synthetic data produced by earlier model generations. Prior work on model collapse primarily focuses on a single model trained on its own output, failing to capture model performance in multi-model interactive settings. In this work, we fill this gap by investigating the performance of generative models in an interactive learning environment with general interaction patterns. In particular, we formalize model interactions using directed graphs and show that the occurrence of model collapse depends critically on the topology of the interaction graph. We further derive an explicit necessary and sufficient condition characterizing when model collapse occurs, and establish finite-sample results for linear regression and asymptotic guarantees for general M-estimators. We support our theoretical findings through extensive numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates model collapse in interactive learning environments involving multiple generative models that train on each other's synthetic outputs. It formalizes these interactions using directed graphs and derives an explicit necessary and sufficient condition on the graph topology for when model collapse occurs. The work also establishes finite-sample results for linear regression, asymptotic guarantees for general M-estimators, and supports the findings with numerical experiments.
Significance. If the central results hold, this would represent a meaningful extension of model collapse analysis from isolated models to structured multi-model interactions. The graph-topology condition offers a concrete, topology-dependent characterization that could inform system design, while the finite-sample linear regression bounds and asymptotic M-estimator guarantees provide useful theoretical anchors. The numerical experiments add empirical support for the claims.
major comments (2)
- [§3] §3 (derivation of the necessary and sufficient condition): The condition is derived under a fixed directed-graph topology that is assumed to be static and exhaustive of all dependencies. This assumption is load-bearing for the necessity and sufficiency claim; if real interactive learning permits adaptive partner selection or time-varying feedback that alters effective edges mid-training, the underlying recurrence or contraction mapping no longer matches the process and the condition loses its claimed status.
- [§5.1] §5.1 (finite-sample linear regression results): The error bounds are stated to depend on graph topology, yet the explicit dependence (e.g., how the contraction factor or variance term scales with in-degree or strongly connected components) is not fully unpacked; without this, it is difficult to verify that the bounds remain informative for graphs that are only weakly connected.
minor comments (3)
- [Abstract] The abstract would benefit from a one-sentence statement of the precise form of the necessary-and-sufficient condition (e.g., a spectral or connectivity criterion).
- [Notation] Notation for the interaction graph G and the associated adjacency or Laplacian matrix should be introduced with an early illustrative figure to aid readability.
- [Experiments] The numerical experiments section would be strengthened by reporting the precise data-generation process, number of runs, and any exclusion criteria for synthetic samples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work. We address each major comment below and indicate the revisions we intend to make.
read point-by-point responses
-
Referee: [§3] §3 (derivation of the necessary and sufficient condition): The condition is derived under a fixed directed-graph topology that is assumed to be static and exhaustive of all dependencies. This assumption is load-bearing for the necessity and sufficiency claim; if real interactive learning permits adaptive partner selection or time-varying feedback that alters effective edges mid-training, the underlying recurrence or contraction mapping no longer matches the process and the condition loses its claimed status.
Authors: We agree that the necessary and sufficient condition is derived under the modeling assumption of a fixed, static directed interaction graph. This assumption enables the precise recurrence formulation and contraction-mapping argument that yield the sharp topological characterization. The framework is intended to capture structured interactive settings with predetermined interaction patterns, which arise in many multi-model systems. We acknowledge that adaptive partner selection or time-varying edges would require a distinct analysis. In the revision we will add a clarifying remark in Section 3 on the scope of the assumption and identify dynamic-graph extensions as a natural direction for future work. revision: partial
-
Referee: [§5.1] §5.1 (finite-sample linear regression results): The error bounds are stated to depend on graph topology, yet the explicit dependence (e.g., how the contraction factor or variance term scales with in-degree or strongly connected components) is not fully unpacked; without this, it is difficult to verify that the bounds remain informative for graphs that are only weakly connected.
Authors: The finite-sample bounds are expressed via the contraction factor of the interaction matrix, which encodes the topological dependence. To improve transparency we will revise Section 5.1 to explicitly relate the contraction factor and variance terms to in-degree and the decomposition into strongly connected components. We will also add a short discussion of the bounds under weak connectivity, showing that they remain informative (though potentially slower) when the topological condition for collapse is not satisfied. These changes will make the scaling and applicability clearer. revision: yes
Circularity Check
Derivation of necessary and sufficient condition on interaction graph topology is mathematically independent
full rationale
The paper defines model interactions via a fixed directed graph, then performs analysis to obtain an explicit necessary and sufficient condition for model collapse along with finite-sample and asymptotic guarantees. No step reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work by the same authors. The central claim is a derived property of the recurrence or contraction under the stated graph topology rather than a tautology or re-labeling of inputs. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model interactions in the interactive learning environment can be formalized as a directed graph where edges represent use of synthetic outputs for training.
Reference graph
Works this paper leans on
- [1]
-
[2]
High dimensional probability II , pages=
Preservation theorems for Glivenko-Cantelli and uniform Glivenko-Cantelli classes , author=. High dimensional probability II , pages=. 2000 , publisher=
work page 2000
-
[3]
Weak convergence and empirical processes: with applications to statistics , pages=
Weak convergence , author=. Weak convergence and empirical processes: with applications to statistics , pages=. 1996 , publisher=
work page 1996
-
[4]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
Large Language Models Can Self-Improve , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
work page 2023
-
[5]
The Elements of Statistical Learning: Data Mining, Inference, and Prediction , author=. 2009 , publisher=
work page 2009
-
[6]
Ng, Andrew and Jordan, Michael , booktitle =. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and naive Bayes , volume =
-
[7]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[8]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Variational Inference with Normalizing Flows , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
work page 2015
-
[10]
Attention is All you Need , volume =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , volume =
-
[11]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
- [12]
- [13]
-
[14]
Improving image generation with better captions , author=. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf , volume=
-
[15]
The Twelfth International Conference on Learning Representations , year=
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
Self-Consuming Generative Models Go
Sina Alemohammad and Josue Casco-Rodriguez and Lorenzo Luzi and Ahmed Imtiaz Humayun and Hossein Babaei and Daniel LeJeune and Ali Siahkoohi and Richard Baraniuk , booktitle=. Self-Consuming Generative Models Go
-
[17]
arXiv preprint arXiv:2306.07899 , year=
Artificial artificial artificial intelligence: Crowd workers widely use large language models for text production tasks , author=. arXiv preprint arXiv:2306.07899 , year=
-
[18]
Proceedings of the 2nd Machine Learning for Healthcare Conference , pages =
Generating Multi-label Discrete Patient Records using Generative Adversarial Networks , author =. Proceedings of the 2nd Machine Learning for Healthcare Conference , pages =. 2017 , editor =
work page 2017
-
[19]
JMIR medical informatics , volume=
Reliability of supervised machine learning using synthetic data in health care: model to preserve privacy for data sharing , author=. JMIR medical informatics , volume=. 2020 , publisher=
work page 2020
-
[20]
Annals of internal medicine , volume=
Implications of the use of artificial intelligence predictive models in health care settings: a simulation study , author=. Annals of internal medicine , volume=. 2023 , publisher=
work page 2023
-
[21]
Machine learning for synthetic data generation: a review.arXiv preprint arXiv:2302.04062,
Machine learning for synthetic data generation: a review , author=. arXiv preprint arXiv:2302.04062 , year=
-
[22]
Harrison Lee and Samrat Phatale and Hassan Mansoor and Kellie Ren Lu and Thomas Mesnard and Johan Ferret and Colton Bishop and Ethan Hall and Victor Carbune and Abhinav Rastogi , year=
-
[23]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
A Survey on Knowledge Distillation of Large Language Models
A Survey on Knowledge Distillation of Large Language Models , author=. arXiv preprint arXiv:2402.13116 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
AI models collapse when trained on recursively generated data , author=. Nature , year=
-
[26]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Model Collapse Demystified: The Case of Regression , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[27]
The Twelfth International Conference on Learning Representations , year=
On the Stability of Iterative Retraining of Generative Models on their own Data , author=. The Twelfth International Conference on Learning Representations , year=
-
[28]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Will Large-scale Generative Models Corrupt Future Datasets? , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
work page 2023
-
[29]
ACM computing surveys , volume=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM computing surveys , volume=. 2023 , publisher=
work page 2023
-
[30]
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[31]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[32]
arXiv preprint arXiv:2502.18049 , year=
Golden ratio weighting prevents model collapse , author=. arXiv preprint arXiv:2502.18049 , year=
-
[33]
http://yann.lecun.com/exdb/mnist/ , year=
The MNIST database of handwritten digits , author=. http://yann.lecun.com/exdb/mnist/ , year=
-
[34]
The Curse of Recursion: Training on Generated Data Makes Models Forget
The curse of recursion: Training on generated data makes models forget , author=. arXiv preprint arXiv:2305.17493 , year=
work page internal anchor Pith review arXiv
-
[35]
Forty-first International Conference on Machine Learning , year=
A Tale of Tails: Model Collapse as a Change of Scaling Laws , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
arXiv preprint arXiv:2509.22341 , year=
Preventing model collapse under overparametrization: Optimal mixing ratios for interpolation learning and ridge regression , author=. arXiv preprint arXiv:2509.22341 , year=
-
[37]
Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation? , author=. arXiv preprint arXiv:2303.01255 , year=
-
[38]
Towards Understanding the Interplay of Generative Artificial Intelligence and the Internet , author=. Epi UAI , year=
-
[39]
arXiv preprint arXiv:2311.12202 , year=
Nepotistically Trained Generative-AI Models Collapse , author=. arXiv preprint arXiv:2311.12202 , year=
-
[40]
Large language models suffer from their own output: An analysis of the self-consuming training loop,
Large Language Models Suffer From Their Own Output: An Analysis of the Self-Consuming Training Loop , author=. arXiv preprint arXiv:2311.16822 , year=
-
[41]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
work page 2024
-
[42]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
-
[43]
Roberts and Diyi Yang and David L
Matthias Gerstgrasser and Rylan Schaeffer and Apratim Dey and Rafael Rafailov and Henry Sleight and John Hughes and Tomasz Korbak and Rajashree Agrawal and Dhruv Pai and Andrey Gromov and Daniel A. Roberts and Diyi Yang and David L. Donoho and Sanmi Koyejo , booktitle=. Is Model Collapse Inevitable?
-
[44]
The Thirteenth International Conference on Learning Representations , year=
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Verification , author=. The Thirteenth International Conference on Learning Representations , year=
-
[45]
The Thirteenth International Conference on Learning Representations , year=
Strong Model Collapse , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Scaling laws for learning with real and surrogate data , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[47]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Neural Information Processing Systems , year=
The Llama 3 herd of models , author=. Neural Information Processing Systems , year=
-
[49]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[51]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[52]
Improving language understanding by generative pre-training , author=. 2018 , publisher=
work page 2018
-
[53]
arXiv preprint arXiv:2503.03150 , year=
Position: Model collapse does not mean what you think , author=. arXiv preprint arXiv:2503.03150 , year=
-
[54]
arXiv preprint arXiv:2504.08755 , year=
Delving into: The quantification of Ai-Generated content on the internet (Synthetic Data) , author=. arXiv preprint arXiv:2504.08755 , year=
-
[55]
Are we in the AI-generated text world already? Quantifying and monitoring AIGT on social media , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
- [56]
-
[57]
When Models Don't Collapse: On the Consistency of Iterative
Daniel Barzilai and Ohad Shamir , journal=. When Models Don't Collapse: On the Consistency of Iterative. 2025 , url=
work page 2025
-
[58]
First Conference on Language Modeling , year=
How bad is training on synthetic data? A statistical analysis of language model collapse , author=. First Conference on Language Modeling , year=
-
[59]
arXiv preprint arXiv:2505.21677 , year=
What happens when generative AI models train recursively on each others' generated outputs? , author=. arXiv preprint arXiv:2505.21677 , year=
-
[60]
The Annals of Probability , volume=
Covariance estimation for distributions with 2 + moments , author=. The Annals of Probability , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.