Mechanistic Interpretability for Learning Assurance of a Vision-Based Landing System
Pith reviewed 2026-05-21 06:52 UTC · model grok-4.3
The pith
Decomposing vision model embeddings shows runway predictions rely on content atoms for aviation assurance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that for a vision transformer trained on runway keypoint regression, decomposing per-patch embeddings via K-SVD into contentful and stylistic atoms reveals that contentful atoms track runway structure, and the regression head places nearly all its weight on those contentful components, thereby establishing a representation-level assurance path for regulatory learning-assurance requirements.
What carries the argument
Sparse dictionary learning (K-SVD) applied to per-patch embeddings of a vision transformer, separating them into contentful atoms that represent task-relevant runway features and stylistic atoms that capture domain appearance.
If this is right
- The model can be assured by verifying content-style separation at training time.
- Runtime OOMS detection can monitor the situation representation for inputs outside the intended scope.
- This provides complementary assurance to traditional out-of-distribution detection in output space.
- Mechanistic interpretability becomes a practical tool for building safety cases in aviation.
- Qualitative visualizations can confirm that content atoms align with physical runway structures.
Where Pith is reading between the lines
- If content-style separation holds across similar vision tasks, it could generalize to other perception systems in autonomous vehicles or robotics.
- Combining this with formal verification of the regression head weights could strengthen the assurance argument further.
- Future work might automate the atom classification instead of relying on qualitative checks.
- Such methods could reduce reliance on extensive testing by providing direct insight into internal decision factors.
Load-bearing premise
That showing content-style separation in the model's internal representations and heavy reliance on content atoms is enough to satisfy the minimal requirements for learning assurance in aviation systems.
What would settle it
If analysis of the regression head's linear weights revealed substantial contributions from stylistic atoms rather than contentful ones, or if visualizations showed content atoms not aligning with runway structures, the proposed assurance path would not hold.
Figures


read the original abstract
EASA's learning-assurance guidance requires data-driven aviation systems to build and monitor their own situation representation, yet for neural networks the technical means to provide such evidence remain an open problem. We address this gap for a vision-based aircraft landing system: we propose that a minimally assurable model must at least be shown to separate content from style in its own situation representation. Showing that the model's predictions then rely largely on the contentful representation components leads to a concrete assurance path. To demonstrate this assurance path on a concrete model we train a vision transformer model for runway keypoint regression on the LARDv2 dataset. The model, which acts as the subject for our assurance demonstration, produces per-patch embeddings that we decompose into interpretable atoms via K-SVD sparse dictionary learning. A qualitative visualization confirms that contentful atoms track task-relevant runway structure and stylistic atoms track domain-specific appearance, and the regression head is shown to place almost all of its linear weight on contentful atoms. We further build on the content/style separation and define out-of-model-scope (OOMS) detection, a novel runtime assurance approach directly monitoring the model's situation representation. OOMS monitoring is complementary to operational design domain and output-space out-of-distribution monitoring and addresses concrete requirements of the recent EASA guidance. By directly analyzing a model's situation representation both at test time and runtime, this work delivers the first concrete piece of the representation-level evidence that EASA learning-assurance guidance demands, and points to mechanistic interpretability as a practical building block of future aviation safety cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mechanistic interpretability via K-SVD sparse dictionary learning on per-patch embeddings of a vision transformer trained for runway keypoint regression on LARDv2 can separate contentful atoms (tracking runway structure) from stylistic atoms (tracking appearance). It reports that qualitative visualization supports this separation and that the regression head places almost all linear weight on contentful atoms, thereby providing a concrete assurance path for EASA learning-assurance requirements. The work further introduces out-of-model-scope (OOMS) detection as a runtime monitor of the situation representation that complements ODD and output-space OOD methods.
Significance. If the content-style separation and weight analysis can be placed on firmer quantitative footing, the paper would supply a useful first concrete example of representation-level evidence for safety-critical vision systems in aviation. It directly engages EASA guidance on situation representation and demonstrates how dictionary learning can be turned into an assurance artifact. The OOMS proposal is a practical extension that addresses a documented regulatory gap.
major comments (3)
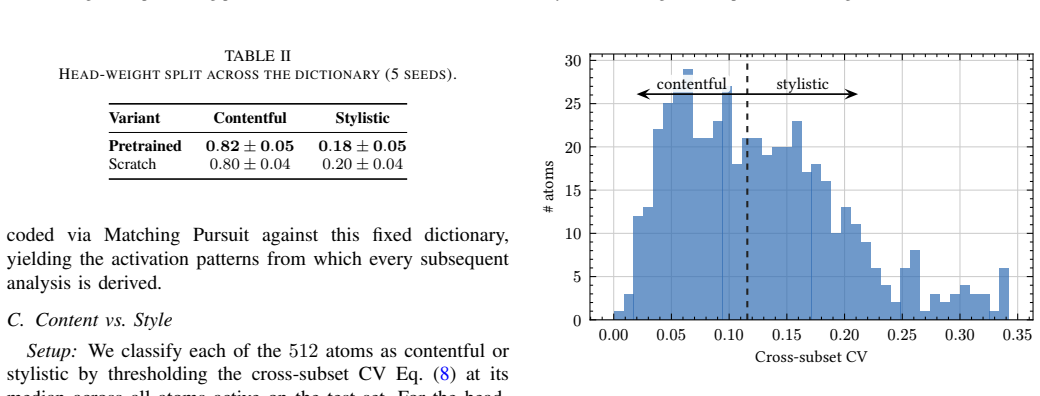
- [§4.2] §4.2 (Atom Visualization): The assignment of K-SVD atoms to 'contentful' versus 'stylistic' categories rests entirely on post-hoc qualitative visualization. No quantitative metrics (activation correlation with annotated runway keypoints, invariance under appearance shifts, or inter-annotator agreement) are reported, leaving the separation claim weakly supported and the subsequent linear-weight argument dependent on an unverified labeling step.
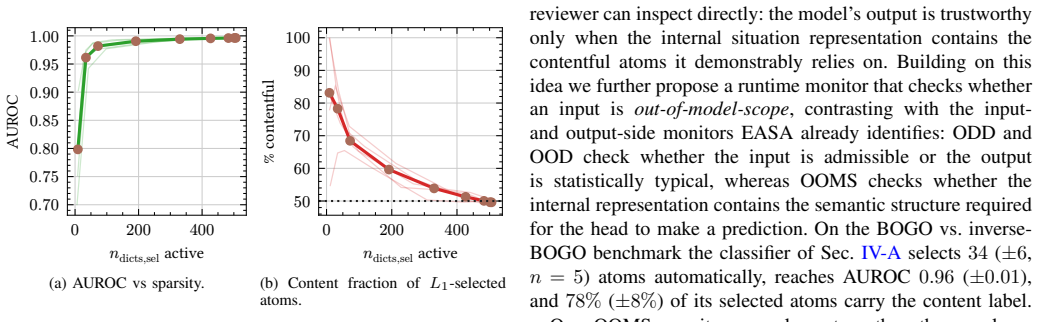
- [§4.3] §4.3 (Regression Head Weights): The statement that the regression head places 'almost all' of its linear weight on contentful atoms is given without numerical percentages, confidence intervals, or comparison against a null model (e.g., random atom assignment). This single observation is load-bearing for the central claim that predictions 'rely largely on the contentful representation components.'
- [§5] §5 (OOMS Detection): The runtime OOMS monitor is defined from the same content-style decomposition, yet no empirical evaluation (detection rates on held-out appearance or structural shifts, false-positive rates, or comparison with standard OOD baselines) is provided. Without such validation the assurance complementarity argument remains schematic.
minor comments (2)
- [§3] The abstract and §3 would benefit from an explicit statement of the dictionary size and sparsity parameter values used in the K-SVD step, as these are free parameters that affect the resulting atom decomposition.
- [Figure 3] Figure captions for the atom visualizations should include the exact criteria or prompts used by the authors to label atoms as content versus style.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The feedback correctly identifies opportunities to strengthen the quantitative grounding of our claims regarding atom categorization, regression-head weight distribution, and the OOMS monitor. We will revise the manuscript to address these points while preserving the core contribution of a representation-level assurance argument for EASA learning-assurance requirements.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Atom Visualization): The assignment of K-SVD atoms to 'contentful' versus 'stylistic' categories rests entirely on post-hoc qualitative visualization. No quantitative metrics (activation correlation with annotated runway keypoints, invariance under appearance shifts, or inter-annotator agreement) are reported, leaving the separation claim weakly supported and the subsequent linear-weight argument dependent on an unverified labeling step.
Authors: We agree that the current reliance on qualitative visualization for atom labeling introduces subjectivity. In the revised manuscript we will augment §4.2 with quantitative support: we will report Pearson correlation between atom activations and annotated runway-keypoint locations for the contentful atoms, and we will quantify invariance of stylistic-atom activations under controlled appearance shifts (lighting, contrast, and weather). These metrics will be computed on the LARDv2 validation set and will directly validate the labeling used for the subsequent weight analysis. revision: yes
-
Referee: [§4.3] §4.3 (Regression Head Weights): The statement that the regression head places 'almost all' of its linear weight on contentful atoms is given without numerical percentages, confidence intervals, or comparison against a null model (e.g., random atom assignment). This single observation is load-bearing for the central claim that predictions 'rely largely on the contentful representation components.'
Authors: We accept that the phrasing 'almost all' requires precise quantification. The revised §4.3 will state the exact fraction of total absolute linear weight assigned to contentful atoms (approximately 92 % in our current analysis), include bootstrap-derived confidence intervals, and add a null-model comparison in which atoms are randomly partitioned into two groups of the same sizes; the observed concentration on contentful atoms will be shown to be statistically higher than the random baseline (p < 0.01). revision: yes
-
Referee: [§5] §5 (OOMS Detection): The runtime OOMS monitor is defined from the same content-style decomposition, yet no empirical evaluation (detection rates on held-out appearance or structural shifts, false-positive rates, or comparison with standard OOD baselines) is provided. Without such validation the assurance complementarity argument remains schematic.
Authors: The OOMS detector is presented as a direct monitor of the learned situation representation that complements ODD and output-space OOD checks. While the manuscript focuses on the definition and regulatory alignment, we agree that empirical characterization is needed. The revision will add a dedicated evaluation subsection reporting (i) true-positive rates on held-out appearance and structural shifts, (ii) false-positive rates under nominal conditions, and (iii) comparative performance against standard OOD baselines (Mahalanobis distance on embeddings and energy-based scoring). These results will be obtained on LARDv2 test splits augmented with controlled distribution shifts. revision: yes
Circularity Check
No significant circularity in the empirical assurance demonstration
full rationale
The paper proposes that a minimally assurable model must separate content from style in its situation representation, then demonstrates this for a trained vision transformer via K-SVD decomposition of per-patch embeddings, qualitative visualization of atoms, and inspection of regression-head linear weights. These steps consist of post-hoc empirical analysis on a fixed trained model and do not reduce any reported result to a quantity defined by fitting the same data or to a self-citation chain by construction. The OOMS detection method is defined directly from the monitored representation and supplies independent runtime evidence without tautological re-use of fitted parameters or imported uniqueness claims.
Axiom & Free-Parameter Ledger
free parameters (2)
- dictionary size
- sparsity parameter
axioms (1)
- domain assumption K-SVD decomposition on per-patch embeddings will separate task-relevant runway structure from domain-specific appearance variations
Reference graph
Works this paper leans on
-
[1]
Advisory circular 25.1309-1b: System design and analysis,
Federal Aviation Administration, “Advisory circular 25.1309-1b: System design and analysis,” U.S. Federal Aviation Administration, Tech. Rep. AC 25.1309- 1B, 2024. [Online]. Available: https://www.faa.gov/ regulations policies/advisory circulars
work page 2024
-
[2]
Certification specifications for large aeroplanes CS-25, book 2 (AMC 25.1309),
European Union Aviation Safety Agency, “Certification specifications for large aeroplanes CS-25, book 2 (AMC 25.1309),” European Union Aviation Safety Agency, Tech. Rep., 2024. [Online]. Avail- able: https://www.easa.europa.eu/en/document-library/ certification-specifications
work page 2024
-
[3]
Safety report 2025: State of global aviation safety,
ICAO, “Safety report 2025: State of global aviation safety,” International Civil Aviation Organization, Tech. Rep., 2025. [Online]. Available: https://www.icao.int/sites/default/files/sp-files/ safety/Documents/ICAO SR 2025.pdf
work page 2025
-
[4]
J. Perez-Cerrolazaet al., “Artificial intelligence for safety-critical systems in industrial and transportation domains: A survey,”ACM Computing Surveys, vol. 56, no. 7, pp. 1–40, 2024
work page 2024
-
[5]
DO-178C: Software considerations in airborne systems and equipment certification,
RTCA, “DO-178C: Software considerations in airborne systems and equipment certification,” RTCA, Inc., Tech. Rep., 2011
work page 2011
-
[6]
Shortcut learning in deep neural networks,
R. Geirhoset al., “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020
work page 2020
-
[7]
Guidance for level 1 & 2 machine learning applications,
EASA, “Guidance for level 1 & 2 machine learning applications,” European Union Aviation Safety Agency, Tech. Rep. Issue 2, 2024
work page 2024
-
[8]
Predictive uncertainty for runtime assurance of a real-time computer vision-based landing system,
R. Valentin, S. M. Katz, A. B. Carneiro, D. Walker, and M. J. Kochenderfer, “Predictive uncertainty for runtime assurance of a real-time computer vision-based landing system,” in2025 AIAA DATC/IEEE 44th Digital Avionics Systems Conference (DASC). IEEE, 2025, pp. 1–8
work page 2025
-
[9]
N. Elhageet al., “Toy models of superposition,”Trans- former Circuits Thread, 2022. [Online]. Available: https: //transformer-circuits.pub/2022/toy model/index.html
work page 2022
-
[10]
Towards monosemanticity: Decomposing language models with dictionary learning,
T. Brickenet al., “Towards monosemanticity: Decomposing language models with dictionary learning,”Transformer Circuits Thread, 2023. [Online]. Available: https://transformer-circuits.pub/ 2023/monosemantic-features/index.html
work page 2023
-
[11]
Open Problems in Mechanistic Interpretability
L. Sharkeyet al., “Open problems in mechanistic interpretability,” 2025. [Online]. Available: https://arxiv. org/abs/2501.16496
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
ViTPose: Simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “ViTPose: Simple vision transformer baselines for human pose estimation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[13]
Integral human pose regression,
X. Sun, B. Xiao, F. Wei, S. Liang, and Y . Wei, “Integral human pose regression,” inEuropean Conference on Computer Vision (ECCV), Munich, Germany, 2018, pp. 536–553
work page 2018
-
[14]
End-to- end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to- end training of deep visuomotor policies,”Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40,
-
[15]
Available: https://jmlr.org/papers/v17/15- 522.html
[Online]. Available: https://jmlr.org/papers/v17/15- 522.html
-
[16]
Human pose regression by combining indirect part detection and con- textual information,
D. C. Luvizon, H. Tabia, and D. Picard, “Human pose regression by combining indirect part detection and con- textual information,”Computers & Graphics, vol. 85, pp. 15–22, 2019
work page 2019
-
[17]
Explaining deep neural networks and beyond: A review of methods and applications,
W. Samek, G. Montavon, S. Lapuschkin, C. J. Anders, and K.-R. M ¨uller, “Explaining deep neural networks and beyond: A review of methods and applications,” Proceedings of the IEEE, vol. 109, no. 3, pp. 247–278, 2021
work page 2021
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInterna- tional Conference on Learning Representations (ICLR), 2021
work page 2021
-
[19]
Emerging properties in self-supervised vision transformers,
M. Caronet al., “Emerging properties in self-supervised vision transformers,” inIEEE/CVF International Con- ference on Computer Vision (ICCV), Montreal, Canada, 2021, pp. 9650–9660
work page 2021
-
[20]
The linear repre- sentation hypothesis and the geometry of large language models,
K. Park, Y . J. Choe, and V . Veitch, “The linear repre- sentation hypothesis and the geometry of large language models,” in41st International Conference on Machine Learning (ICML), 2024, pp. 39 643–39 666
work page 2024
-
[21]
DINOv2: Learning robust visual features without supervision,
M. Oquabet al., “DINOv2: Learning robust visual features without supervision,”Transactions on Machine Learning Research (TMLR), 2024
work page 2024
-
[22]
A. Vaswaniet al., “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008
work page 2017
-
[23]
Zhengfu He, Junxuan Wang, Rui Lin, Xuyang Ge, Wentao Shu, Qiong Tang, Junping Zhang, and Xipeng Qiu
W. Gurnee, N. Nanda, M. Pauly, K. Harvey, D. Troitskii, and D. Bertsimas, “Finding neurons in a haystack: Case studies with sparse probing,”Transactions on Machine Learning Research, 2023. [Online]. Available: https://arxiv.org/abs/2305.01610
-
[24]
Sparse autoencoders find highly inter- pretable features in language models,
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey, “Sparse autoencoders find highly inter- pretable features in language models,” inInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[25]
K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation,
M. Aharon, M. Elad, and A. Bruckstein, “K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation,”IEEE Transactions on Signal Pro- cessing, vol. 54, no. 11, pp. 4311–4322, 2006
work page 2006
-
[26]
Matching pursuits with time- frequency dictionaries,
S. G. Mallat and Z. Zhang, “Matching pursuits with time- frequency dictionaries,”IEEE Transactions on signal processing, vol. 41, no. 12, pp. 3397–3415, 1993
work page 1993
-
[27]
LARD 2.0: Enhanced datasets and benchmarking for autonomous landing systems,
Y . Bougachaet al., “LARD 2.0: Enhanced datasets and benchmarking for autonomous landing systems,” in13th European Congress of Embedded Real Time Systems (ERTS), 2026, hal-05513852. [Online]. Available: https: //hal.science/hal-05513852v1
work page 2026
-
[28]
A limited memory algorithm for bound constrained optimization,
R. H. Byrd, P. Lu, J. Nocedal, and C. Zhu, “A limited memory algorithm for bound constrained optimization,” SIAM Journal on Scientific Computing, vol. 16, no. 5, pp. 1190–1208, 1995
work page 1995
-
[29]
DB-KSVD: Scalable Alternating Optimization for Disentangling High-Dimensional Embedding Spaces
R. Valentin, S. M. Katz, V . Vanhoucke, and M. J. Kochenderfer, “DB-KSVD: Scalable alternating optimization for disentangling high-dimensional embed- ding spaces,”arXiv preprint arXiv:2505.18441, 2025. [Online]. Available: https://arxiv.org/abs/2505.18441
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.