PREFINE: Preference-Based Implicit Reward and Cost Fine-Tuning for Safety Alignment
Pith reviewed 2026-05-21 05:28 UTC · model grok-4.3
The pith
PREFINE adapts direct preference optimization to fine-tune pre-trained RL policies using trajectory preferences so they avoid high-cost behaviors while keeping original rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
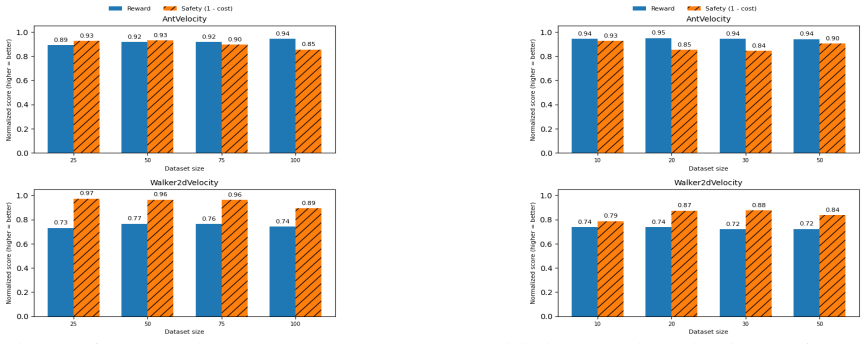
PREFINE adapts Direct Preference Optimization to the sequential decision-making setting by generating policy-sampled counterfactual trajectories from a small dataset of trajectory-level preferences. This allows joint optimization that reduces constraint violations and catastrophic failures by over 60 percent while preserving the original reward behavior. The resulting policies achieve low-cost high-reward performance with significantly better data and computational efficiency than full offline RL or imitation learning.
What carries the argument
PREFINE, which adapts DPO by constructing policy-sampled counterfactual trajectories to establish preference contrasts for joint reward retention and safety alignment optimization.
If this is right
- The fine-tuned policy produces low-cost behaviors while retaining high rewards.
- Constraint violations and catastrophic failures drop by more than 60 percent.
- Data and compute requirements stay far below those of full offline RL or imitation learning.
- Safety alignment becomes feasible for existing reward-optimized policies in continuous domains.
Where Pith is reading between the lines
- The same counterfactual construction might let preference data correct other undesired behaviors beyond explicit costs.
- Small trajectory preference sets could support iterative safety improvements without repeated full retraining.
- The approach may transfer to domains where only human judgments of trajectory quality are available rather than explicit cost functions.
Load-bearing premise
Policy-sampled counterfactual trajectories from a small preference dataset create meaningful contrasts that support joint optimization of reward retention and safety alignment.
What would settle it
Running the method on a new continuous-control task with fresh preference data and observing no reduction in constraint violations or a drop in reward performance compared to the base policy.
Figures












read the original abstract
We address the problem of making a pre-trained reinforcement learning (RL) policy safety-aware by incorporating cost constraints without retraining it from scratch. While costs could be numerically encoded, we assume a more general setting is when costs are provided as preferences. Given a reward-optimized policy and a small dataset of preferred (low-cost) and dispreferred (high-cost) trajectories, our goal is to fine-tune the policy to generate low-cost behaviors while retaining high rewards. Unlike standard RLHF in language models, where preferences are defined over responses to the same prompt, our setting involves trajectory-level preferences in continuous control environments. We introduce PREFINE: Preference-based Implicit Reward and Cost Fine-Tuning for Safety Alignment which is a preference-based fine-tuning method that adapts Direct Preference Optimization (DPO), which is now widely used for LLM fine-tuning, to the sequential decision making setting. PREFINE constructs policy-sampled counterfactual trajectories to establish meaningful preference contrasts and jointly optimizes for reward retention and safety alignment. Empirically, PREFINE reduces constraint violations and catastrophic failures by over 60% while maintaining original reward behavior. PREFINE produces policies that achieve low-cost, high-reward performance with significantly improved data and computational efficiency compared to full offline RL or imitation learning, bridging preference alignment and safe policy adaptation in continuous domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PREFINE, a preference-based fine-tuning method adapting Direct Preference Optimization (DPO) to sequential decision-making in continuous control. Given a reward-optimized policy and a small dataset of trajectory-level preferred (low-cost) and dispreferred (high-cost) pairs, it constructs policy-sampled counterfactual trajectories to create contrasts and jointly optimizes an adapted DPO objective for reward retention and safety alignment. The central empirical claim is a reduction of constraint violations and catastrophic failures by over 60% while preserving original reward behavior, with improved data and computational efficiency over full offline RL or imitation learning.
Significance. If the results hold under rigorous validation, the work offers a practical bridge between preference alignment techniques from language models and safe policy adaptation in continuous RL domains. The emphasis on implicit reward/cost fine-tuning from limited trajectory preferences and avoidance of full retraining could enable more efficient safety alignment in real-world control tasks.
major comments (2)
- [§3] §3 (Method), counterfactual trajectory sampling procedure: the central claim relies on policy-sampled counterfactuals producing sufficient cost separation between preferred and dispreferred trajectories. In a reward-optimized policy for continuous control, high-cost regions typically have low probability mass, so dispreferred samples may exhibit heavily overlapping cost distributions with preferred ones. This risks an insufficient implicit cost signal in the adapted DPO loss, weakening the joint optimization for violation reduction while retaining reward. The manuscript should provide explicit analysis (e.g., cost histograms or KL divergence between sets) or importance sampling to address this.
- [Empirical evaluation] Empirical evaluation section (results and tables): the >60% reduction in violations is load-bearing for the safety-alignment claim, yet the abstract and reported results lack details on experimental setup, including specific environments, baseline methods (e.g., standard DPO, constrained RL, or imitation), number of independent runs, statistical tests (e.g., t-tests or confidence intervals), and controls for confounds like preference dataset size or hyperparameter sensitivity. Without these, it is unclear whether the data robustly supports the claim of maintained reward behavior alongside the violation reduction.
minor comments (2)
- [§3.1] Clarify the exact form of the adapted DPO loss for the sequential setting, particularly how the implicit reward and cost terms are combined and any assumptions on the reference policy.
- [Discussion] Add discussion of limitations, such as sensitivity to the quality and size of the trajectory preference dataset or potential failure modes in highly stochastic environments.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We appreciate the emphasis on strengthening the methodological justification and empirical reporting. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method), counterfactual trajectory sampling procedure: the central claim relies on policy-sampled counterfactuals producing sufficient cost separation between preferred and dispreferred trajectories. In a reward-optimized policy for continuous control, high-cost regions typically have low probability mass, so dispreferred samples may exhibit heavily overlapping cost distributions with preferred ones. This risks an insufficient implicit cost signal in the adapted DPO loss, weakening the joint optimization for violation reduction while retaining reward. The manuscript should provide explicit analysis (e.g., cost histograms or KL divergence between sets) or importance sampling to address this.
Authors: We acknowledge this valid concern about potential overlap in cost distributions for policy-sampled counterfactuals in continuous domains. Our sampling procedure intentionally draws from the current policy to create contrasts with the provided preference dataset, but we agree that explicit validation of separation is needed. In the revised manuscript, we will augment §3 with cost histograms for preferred and dispreferred trajectory sets, along with KL divergence metrics between their cost distributions. We will also discuss the role of importance sampling as a potential mitigation if separation is limited in certain environments. These additions will directly demonstrate the strength of the implicit cost signal in the adapted DPO objective. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation section (results and tables): the >60% reduction in violations is load-bearing for the safety-alignment claim, yet the abstract and reported results lack details on experimental setup, including specific environments, baseline methods (e.g., standard DPO, constrained RL, or imitation), number of independent runs, statistical tests (e.g., t-tests or confidence intervals), and controls for confounds like preference dataset size or hyperparameter sensitivity. Without these, it is unclear whether the data robustly supports the claim of maintained reward behavior alongside the violation reduction.
Authors: We agree that fuller reporting of the experimental protocol is essential for validating the central claims. In the revised Empirical Evaluation section, we will specify the continuous control environments, detail all baselines (including adapted DPO, constrained RL, and imitation learning variants), report results averaged over multiple independent runs with statistical tests and confidence intervals, and include sensitivity analyses for preference dataset size and hyperparameters. These expansions will provide transparent support for the reported violation reductions while confirming reward retention. revision: yes
Circularity Check
No significant circularity; method is an empirical adaptation of DPO without self-referential derivations
full rationale
The paper presents PREFINE as an adaptation of Direct Preference Optimization (DPO) to trajectory-level preferences in continuous control, using policy-sampled counterfactual trajectories to create preference contrasts for joint reward retention and safety alignment. No equations, derivations, or load-bearing steps are described that reduce the optimization objective or claimed performance gains to fitted parameters or self-citations by construction. The >60% reduction claim is positioned as an empirical outcome from experiments rather than a mathematical identity or renamed input. Self-citations are not invoked for uniqueness theorems or ansatzes. The derivation chain is self-contained against external benchmarks like standard DPO and offline RL baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. InICML, pages 22–31, 2017
work page 2017
-
[2]
Eitan Altman.Constrained Markov Decision Processes. Chapman and Hall/CRC, 1999
work page 1999
-
[3]
Argall, Sonia Chernova, Manuela Veloso, and Brett Browning
Brenna D. Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. A survey of robot learning from demonstration.Robotics and Autonomous Systems, 57(5):469–483, 2009
work page 2009
-
[4]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[5]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, pages 4299–4311, 2017
work page 2017
-
[6]
Offline safe reinforcement learning using trajectory classification
Ze Gong, Akshat Kumar, and Pradeep Varakantham. Offline safe reinforcement learning using trajectory classification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16880–16887, 2025
work page 2025
-
[7]
Bullet-safety-gym: A framework for constrained reinforcement learning
Sven Gronauer. Bullet-safety-gym: A framework for constrained reinforcement learning. 2022
work page 2022
-
[8]
Constraint- conditioned actor-critic for offline safe reinforcement learning
Zijian Guo, Weichao Zhou, Shengao Wang, and Wenchao Li. Constraint- conditioned actor-critic for offline safe reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[9]
Safedice: Offline safe imitation learning with non-preferred demonstrations
Youngsoo Jang, Geon-Hyeong Kim, Jongmin Lee, Sungryull Sohn, Byoungjip Kim, Honglak Lee, and Moontae Lee. Safedice: Offline safe imitation learning with non-preferred demonstrations. InNeurIPS, volume 36, 2023
work page 2023
-
[10]
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Josef Dai, and Yaodong Yang. Safety gymnasium: A unified safe reinforcement learning benchmark.Advances in Neural Information Processing Systems, 36:18964–18993, 2023
work page 2023
-
[11]
J., Kim, B., Lee, H., Bae, K., and Lee, M
Geon-Hyeong Kim, Youngsoo Jang, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, and Moontae Lee. Safedpo: A simple approach to direct prefer- ence optimization with enhanced safety.arXiv preprint arXiv:2505.20065, 2025
-
[12]
Demodice: Offline imitation learning with supplementary imperfect demonstrations
Geon-Hyeong Kim, Seokin Seo, Jongmin Lee, Wonseok Jeon, HyeongJoo Hwang, Hongseok Yang, and Kee-Eung Kim. Demodice: Offline imitation learning with supplementary imperfect demonstrations. InICLR, 2022
work page 2022
-
[13]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Prajwal Koirala, Zhanhong Jiang, Soumik Sarkar, and Cody Fleming. Latent safety-constrained policy approach for safe offline reinforcement learning.arXiv preprint arXiv:2412.08794, 2024
-
[15]
Imitation learning via off-policy distribution matching
Ilya Kostrikov, Ofir Nachum, and Jonathan Tompson. Imitation learning via off-policy distribution matching. InICLR, 2020
work page 2020
-
[16]
Constrained variational policy optimiza- tion for safe reinforcement learning
Yang Liu, Jialin Ding, and Xueqian Liu. Constrained variational policy optimiza- tion for safe reinforcement learning. InICML, pages 13644–13658, 2022
work page 2022
-
[17]
Yang Liu, Jialin Ding, and Xueqian Liu. Dsrl: Benchmarking safe offline reinforce- ment learning with diverse safety requirements.arXiv preprint arXiv:2401.14758, 2024
-
[18]
Provably mitigating overoptimization in rlhf: Your sft loss is implicitly an adversarial regularizer
Zhihan Liu, Miao Lu, Shenao Zhang, Boyi Liu, Hongyi Guo, Yingxiang Yang, Jose Blanchet, and Zhaoran Wang. Provably mitigating overoptimization in rlhf: Your sft loss is implicitly an adversarial regularizer. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volu...
work page 2024
-
[19]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Dexperts: Decoding-time controlled text generation with experts and anti-experts. InACL, pages 6691–6713, 2022
work page 2022
-
[20]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Train- ing language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[22]
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), volume 15 ofPMLR, pages 627–635, 2011
work page 2011
-
[23]
Stefan Schaal. Learning from demonstration. InAdvances in Neural Information Processing Systems (NeurIPS), volume 9, pages 1040–1046, 1996
work page 1996
-
[24]
Responsive safety in rein- forcement learning by pid lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in rein- forcement learning by pid lagrangian methods. InNeurIPS, pages 11244–11255, 2020
work page 2020
-
[25]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 1998
work page 1998
-
[26]
Yue Wu, Shuangrui Zhai, and Nitish Srivastava. Dwbc: Mitigating catastrophic forgetting in dynamic imitation learning via weight-based consolidation. In NeurIPS, volume 35, pages 3722–3734, 2022
work page 2022
-
[27]
Constraints penalized q-learning for safe offline reinforcement learning
Haoran Xu, Xingyu Zhan, Honglei Yin, and Huiling Qin. Constraints penalized q-learning for safe offline reinforcement learning. InAAAI, volume 36, pages 8753–8760, 2022. A APPENDIX A.1 DSRL Task Description We evaluate our approach on the DSRL benchmark [17], a widely adopted suite for studying offline safe reinforcement learning. DSRL offers a compre- he...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.