Deformba: Vision State Space Model with Adaptive State Fusion
Pith reviewed 2026-05-21 05:00 UTC · model grok-4.3
The pith
Deformba introduces adaptive state fusion to let vision state space models handle dynamic spatial structures and multi-modal queries while keeping linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deformba is a context adaptive method that dynamically augments the spatial structural information while maintaining the linear complexity of SSMs and allowing multi-modal fusion like cross attention, enabling strong performance on both 2D vision benchmarks and 3D BEV perception tasks.
What carries the argument
Adaptive state fusion, a context-driven mechanism that augments spatial structure on the fly and permits query-based multi-modal interactions without breaking linear-time scaling.
If this is right
- Vision SSMs can process images without manually designed fixed scanning orders.
- Multi-view 3D fusion becomes feasible within a linear-complexity SSM framework.
- The same architecture can be applied to both 2D perception and BEV tasks without redesign.
- Linear scaling is preserved even when spatial structure is augmented dynamically.
Where Pith is reading between the lines
- The fusion approach may extend to other sequence domains where cross-stream queries are needed.
- It could reduce reliance on attention layers in multi-modal models if the linear-cost claim holds at scale.
- Further tests on video or point-cloud sequences would check whether the adaptive mechanism generalizes beyond the reported benchmarks.
Load-bearing premise
The adaptive state fusion can be realized in practice without introducing hidden quadratic costs or needing heavy task-specific tuning.
What would settle it
Runtime or memory measurements on high-resolution images showing quadratic scaling, or benchmark scores that fall below comparable fixed-scan SSM baselines.
Figures
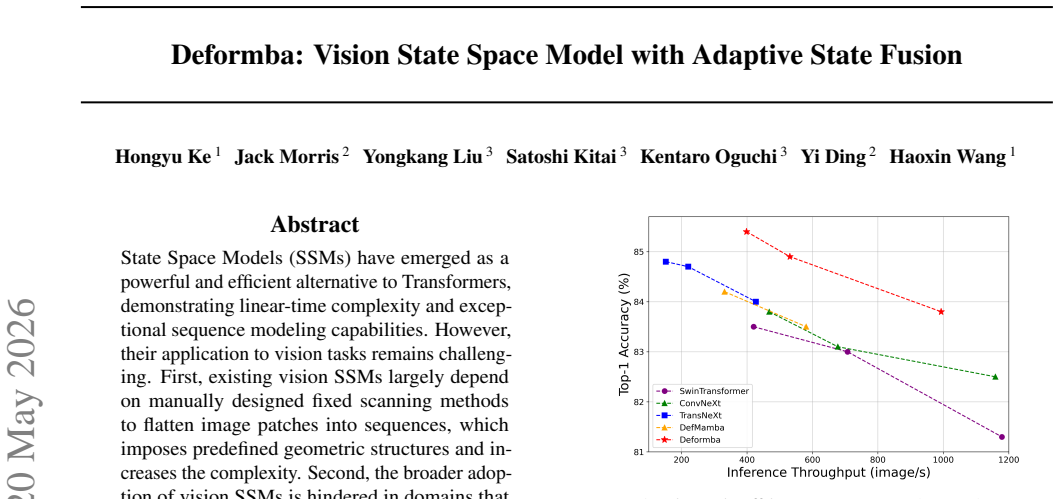






read the original abstract
State Space Models (SSMs) have emerged as a powerful and efficient alternative to Transformers, demonstrating linear-time complexity and exceptional sequence modeling capabilities. However, their application to vision tasks remains challenging. First, existing vision SSMs largely depend on manually designed fixed scanning methods to flatten image patches into sequences, which imposes predefined geometric structures and increases the complexity. Second, the broader adoption of vision SSMs is hindered in domains that require query-based interactions between distinct information streams. This is a result of the inherently causal and self-referential nature of SSMs designed for 1D sequence modeling tasks. This fusion mechanism is indispensable for critical perception tasks such as multi-view 3D fusion. To address these limitations, we propose Deformba, a context adaptive method that dynamically augments the spatial structural information while maintaining the linear complexity of SSMs. Deformba also allows multi-modal fusion like cross attention. To demonstrate the effectiveness and general applicability of Deformba, we test its performance on general 2D vision tasks such as image classification, object detection, and segmentation, as well as 3D vision tasks like BEV perception. Extensive experiments show that Deformba achieves strong performance across various visual perception benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Deformba, a vision State Space Model that introduces a context-adaptive state fusion mechanism to dynamically augment spatial structural information in visual inputs. It claims to preserve the linear complexity of SSMs while enabling multi-modal fusion comparable to cross-attention, addressing limitations of fixed scanning in prior vision SSMs and their causal/self-referential nature. The approach is evaluated on 2D tasks (image classification, object detection, segmentation) and 3D tasks (BEV perception), with claims of strong performance across benchmarks.
Significance. If the adaptive fusion mechanism rigorously maintains strict linear complexity without hidden super-linear costs from context-dependent operations or cross-stream interactions, the work would offer a meaningful advance in efficient vision backbones. It could enable broader use of SSMs in multi-view 3D and multi-modal perception settings where query-based fusion is required, providing an alternative to attention-based models with better scaling properties.
major comments (2)
- [Abstract] Abstract and method description: The central claims of performance gains, linear complexity preservation, and effective multi-modal fusion are stated without any equations, ablation studies, error bars, dataset details, or complexity derivations. This prevents verification of whether the context-adaptive augmentation and query-based fusion avoid quadratic costs.
- [Method] Method section (adaptive state fusion): The replacement of fixed scanning with a learned, context-dependent process and the addition of cross-stream query interactions are presented as preserving O(N) complexity. However, no operation count, recurrence formulation, or proof is given to confirm that state-dependent weights, deformable offsets, or pairwise relations are computed strictly locally or recurrently rather than via global aggregation.
minor comments (1)
- [Abstract] The abstract would benefit from a brief mention of the specific benchmarks and baseline comparisons used to support the 'strong performance' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that greater detail on equations, ablations, error bars, and complexity derivations would improve verifiability. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects while preserving the core technical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: The central claims of performance gains, linear complexity preservation, and effective multi-modal fusion are stated without any equations, ablation studies, error bars, dataset details, or complexity derivations. This prevents verification of whether the context-adaptive augmentation and query-based fusion avoid quadratic costs.
Authors: We acknowledge that the abstract is high-level by design. The full manuscript already contains the adaptive state fusion equations in Section 3, ablation studies in Section 4.3, and benchmark details in Section 4.1. To directly address the verification concern, we will add a dedicated complexity analysis subsection with explicit operation counts, a recurrence formulation, and a short proof sketch demonstrating that context-dependent weights and deformable offsets are computed locally and recurrently. We will also include error bars on all reported metrics and expand dataset descriptions. These additions will confirm that no hidden quadratic terms arise from the adaptive or cross-stream components. revision: yes
-
Referee: [Method] Method section (adaptive state fusion): The replacement of fixed scanning with a learned, context-dependent process and the addition of cross-stream query interactions are presented as preserving O(N) complexity. However, no operation count, recurrence formulation, or proof is given to confirm that state-dependent weights, deformable offsets, or pairwise relations are computed strictly locally or recurrently rather than via global aggregation.
Authors: The mechanism computes deformable offsets and state-dependent fusion weights via lightweight local operators (small MLPs or convolutions on neighboring features) that feed directly into the standard SSM recurrence; cross-stream queries are likewise folded into the linear state update without global pairwise computation. We agree an explicit derivation was omitted. In revision we will insert the full recurrence equations, an operation-count table, and a brief argument showing that all additional terms scale linearly because they remain position-local and recurrent rather than requiring global aggregation. revision: yes
Circularity Check
No significant circularity; method introduced as independent architectural proposal
full rationale
The paper presents Deformba as a new context-adaptive state fusion mechanism for vision SSMs that augments spatial structure while preserving linear complexity and enabling multi-modal fusion. No equations or derivations in the provided abstract reduce a claimed prediction or result back to a fitted parameter or self-citation by construction. The central claims rest on the proposed architecture's design choices rather than re-deriving quantities from prior fitted results or self-referential definitions. External benchmarks and experiments are invoked to demonstrate effectiveness, keeping the derivation chain self-contained against independent validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose Deformba, a context adaptive method that dynamically augments the spatial structural information while maintaining the linear complexity of SSMs. Deformba also allows multi-modal fusion like cross attention.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CASF decouples the SSM write/read and inserts an offset predictor to sample context-adaptive evidence from the hidden state map
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Chen, K., Wang, J., Pang, J., Cao, Y ., Xiong, Y ., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., et al. Mmdetection: Open mmlab detection toolbox and benchmark.arXiv preprint arXiv:1906.07155,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[2]
Dao, T. and Gu, A. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Efficiently Modeling Long Sequences with Structured State Spaces
Gu, A., Goel, K., and R ´e, C. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021a. Gu, A., Johnson, I., Goel, K., Saab, K., Dao, T., Rudra, A., and R´e, C. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems, 34...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Damamba: Vision state space model with dynamic adaptive scan.arXiv preprint arXiv:2502.12627,
Li, T., Li, C., Lyu, J., Pei, H., Zhang, B., Jin, T., and Ji, R. Damamba: Vision state space model with dynamic adaptive scan.arXiv preprint arXiv:2502.12627,
-
[6]
10 Deformba: Vision State Space Model with Adaptive State Fusion Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Qiao, Y ., and Dai, J. Bevformer: Learning bird’s-eye-view repre- sentation from multi-camera images via spatiotemporal transformers.arXiv preprint arXiv:2203.17270, 2022a. Li, Z., Wang, W., Xie, E., Yu, Z., Anandkumar, A., Alvarez, J. M.,...
-
[7]
Spatial-mamba: Effective visual state space models via structure-aware state fusion,
Wang, W., Xie, E., Li, X., Fan, D.-P., Song, K., Liang, D., Lu, T., Luo, P., and Shao, L. Pvt v2: Improved baselines with pyramid vision transformer.Computational visual media, 8(3):415–424, 2022a. 11 Deformba: Vision State Space Model with Adaptive State Fusion Wang, Y ., Guizilini, V . C., Zhang, T., Wang, Y ., Zhao, H., and Solomon, J. Detr3d: 3d objec...
-
[8]
Grootvl: Tree topology is all you need in state space model,
Xiao, Y ., Song, L., Huang, S., Wang, J., Song, S., Ge, Y ., Li, X., and Shan, Y . Grootvl: Tree topology is all you need in state space model.arXiv preprint arXiv:2406.02395, 2024b. Xu, B., Dai, X., Tang, D., and Zhang, K. One surrogate to fool them all: Universal, transferable, and targeted adver- sarial attacks with clip. InProceedings of the 2025 ACM ...
-
[9]
Yang, C., Chen, Z., Espinosa, M., Ericsson, L., Wang, Z., Liu, J., and Crowley, E. J. Plainmamba: Improving non- hierarchical mamba in visual recognition.arXiv preprint arXiv:2403.17695, 2024a. Yang, S., Wang, B., Zhang, Y ., Shen, Y ., and Kim, Y . Par- allelizing linear transformers with the delta rule over se- quence length.Advances in neural informati...
-
[10]
MedSynapse-V: Bridging Visual Perception and Clinical Intuition via Latent Memory Evolution
Zhu, C., Lin, Y ., Chen, S., Wang, Y ., and Lin, J. Medeyes: Learning dynamic visual focus for medical progressive diagnosis. InProceedings of the AAAI Conference on Ar- tificial Intelligence, volume 40, pp. 13916–13924, 2026a. Zhu, C., Zeng, J., Jiang, J., Lin, J., and Wang, Y . Medsynapse-v: Bridging visual perception and clinical intuition via latent m...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J. De- formable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Many of the existing components follow the methodologies of (Li et al., 2022a), (Liu et al., 2023), and (Ke et al., 2025b). The encoding function fenc is parameterized by the ResNet backbone, feature pyramid network (FPN), BEV encoder, and temporal fusion modules. The pipeline has three main stages as follows. First, image feature maps of different scales...
work page 2023
-
[13]
We train the models from scratch using a randomly initialized network for the encoder layers
A 0.1 multiplier is applied to the learning rate of the backbone weights and the deformable attention sampling offsets (Zhu et al., 2020). We train the models from scratch using a randomly initialized network for the encoder layers. For experiments on the COCO dataset, we trained each decoder configuration using 3 decoder layers for 5 epochs at a learning...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.