RoadTones: Tone Controllable Text Generation from Road Event Videos
Pith reviewed 2026-05-21 04:32 UTC · model grok-4.3
The pith
A new dataset, model, and evaluation suite enables video models to generate road event captions with controllable tone while preserving facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
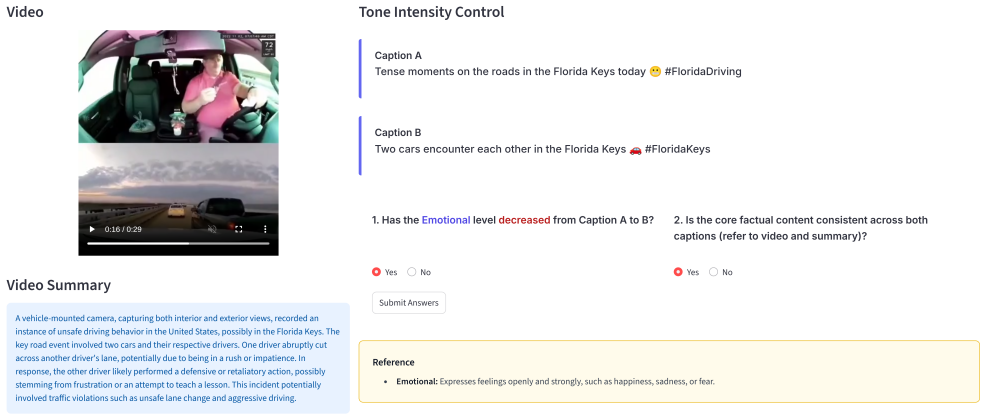
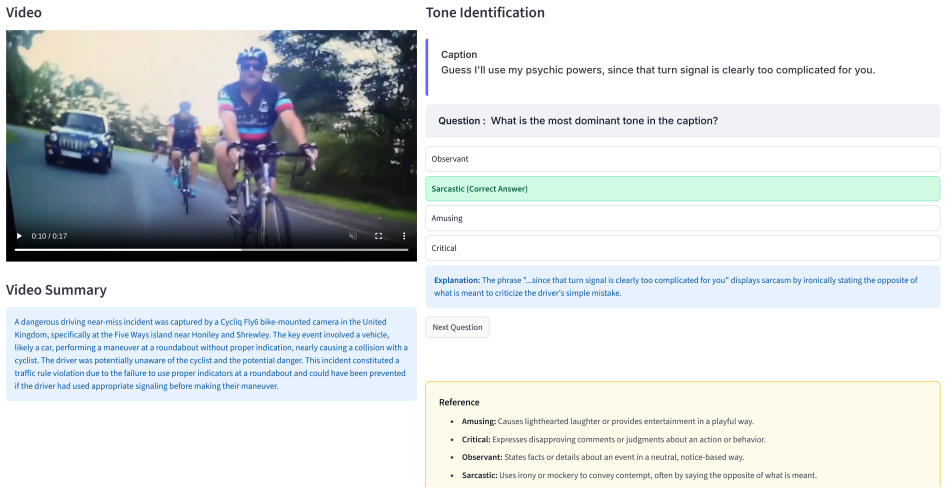
By expanding existing road-video corpora through a human-validated pipeline that adds diverse tonal annotations and multi-tone captions, the work creates the RoadTones-51K dataset. The RoadTones-VL-CoT model then generates tone-conditioned Chain-of-Thought intermediate drafts for interpretability, while RoadTones-Eval jointly assesses factual consistency and tone adherence. User studies confirm that the resulting captions maintain quality, adhere to the requested tone, and remain factually consistent.
What carries the argument
RoadTones-VL-CoT, a controllable video-to-text model that produces tone-conditioned Chain-of-Thought intermediate drafts to separate stylistic control from factual content.
If this is right
- The same road event can be described with different urgency or calmness without changing the underlying facts.
- Communication in safety-critical driving scenarios becomes more adaptable to audience or context needs.
- Interpretability increases because the model exposes its tone-conditioned reasoning steps before the final caption.
- Evaluation now requires joint measurement of factual accuracy and stylistic adherence rather than accuracy alone.
Where Pith is reading between the lines
- This approach could extend to real-time alert systems that match warning tone to the severity of detected hazards.
- Similar tone-conditioning pipelines might apply to other video domains such as medical or sports footage.
- If the data pipeline can be partially automated, larger-scale tone control becomes feasible with less human effort.
Load-bearing premise
The human-validated data generation pipeline produces reliable and unbiased tonal annotations and multi-tone captions that accurately reflect controllable stylistic variations independent of factual content.
What would settle it
A controlled test in which human raters or automated metrics show that changing the tone instruction consistently alters factual content or fails to produce the requested tone across multiple road events.
Figures



































read the original abstract
Existing video-language models can generate factual descriptions of road events but lack control over how these events are expressed: their tone, urgency, or style. This limits deployment in communication-critical settings where the effectiveness of a message depends on both content and presentation, not just factual accuracy. To mitigate this, we introduce a comprehensive dataset-model-evaluation suite for tone-controllable road video captioning. Our human-validated data generation pipeline expands road-video corpora with diverse tonal annotations and multi-tone captions, yielding the RoadTones-51K dataset. We propose RoadTones-VL-CoT, a controllable video-to-text model that also generates tone-conditioned Chain-of-Thought intermediate drafts for interpretability. We also introduce RoadTones-Eval, a new evaluation suite that jointly measures factual consistency and tone adherence. In addition, we conducted a user study whose results validate caption quality, tone control, and factual consistency. Together, these contributions lay the foundation for context-sensitive tone-controllable video captioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RoadTones, a comprehensive dataset-model-evaluation suite for tone-controllable captioning of road event videos. It constructs the RoadTones-51K dataset via a human-validated pipeline that augments existing road-video corpora with tonal annotations and multi-tone captions. The proposed RoadTones-VL-CoT model generates tone-conditioned Chain-of-Thought intermediate drafts for interpretability, while RoadTones-Eval jointly assesses factual consistency and tone adherence. A user study is reported to support claims of caption quality, tone control, and factual consistency.
Significance. If the central claims hold, the work supplies a useful resource for controllable video-to-text generation in safety-critical domains such as traffic monitoring and emergency communication, where stylistic presentation can influence message effectiveness. The combination of a sizable annotated dataset, an interpretable CoT-based model, and a dedicated joint evaluation suite could facilitate further research on style-content disentanglement in multimodal models. The human-validation step and user study represent constructive empirical grounding when accompanied by the necessary quantitative details.
major comments (2)
- [§3.2 (Human-Validated Data Generation Pipeline)] §3.2 (Human-Validated Data Generation Pipeline): The manuscript does not report inter-annotator agreement metrics or annotation guidelines that explicitly instruct annotators to decouple tone from factual event properties (e.g., collision severity or vehicle count). Without post-hoc correlation tests between tone labels and factual metadata, it remains unclear whether the multi-tone captions achieve stylistic variation independent of content; this directly undermines the claim that RoadTones-VL-CoT performs controllable tone generation rather than implicit content prediction.
- [§5 (User Study and RoadTones-Eval)] §5 (User Study and RoadTones-Eval): The user study is cited as validating caption quality, tone control, and factual consistency, yet the text supplies no quantitative results (e.g., mean scores, statistical tests, or inter-rater reliability), error analysis, or ablation details. This absence prevents verification of the strength of the empirical support for the central claims on tone adherence and factual consistency.
minor comments (2)
- [Abstract] The abstract would be strengthened by briefly stating the scale of the user study (number of participants, videos evaluated) and the key quantitative outcomes rather than only qualitative validation language.
- [Figure 2] Figure captions for the model architecture diagram could more explicitly label the tone-conditioning input pathway and the CoT draft generation branch to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to improve transparency and empirical detail.
read point-by-point responses
-
Referee: [§3.2 (Human-Validated Data Generation Pipeline)] §3.2 (Human-Validated Data Generation Pipeline): The manuscript does not report inter-annotator agreement metrics or annotation guidelines that explicitly instruct annotators to decouple tone from factual event properties (e.g., collision severity or vehicle count). Without post-hoc correlation tests between tone labels and factual metadata, it remains unclear whether the multi-tone captions achieve stylistic variation independent of content; this directly undermines the claim that RoadTones-VL-CoT performs controllable tone generation rather than implicit content prediction.
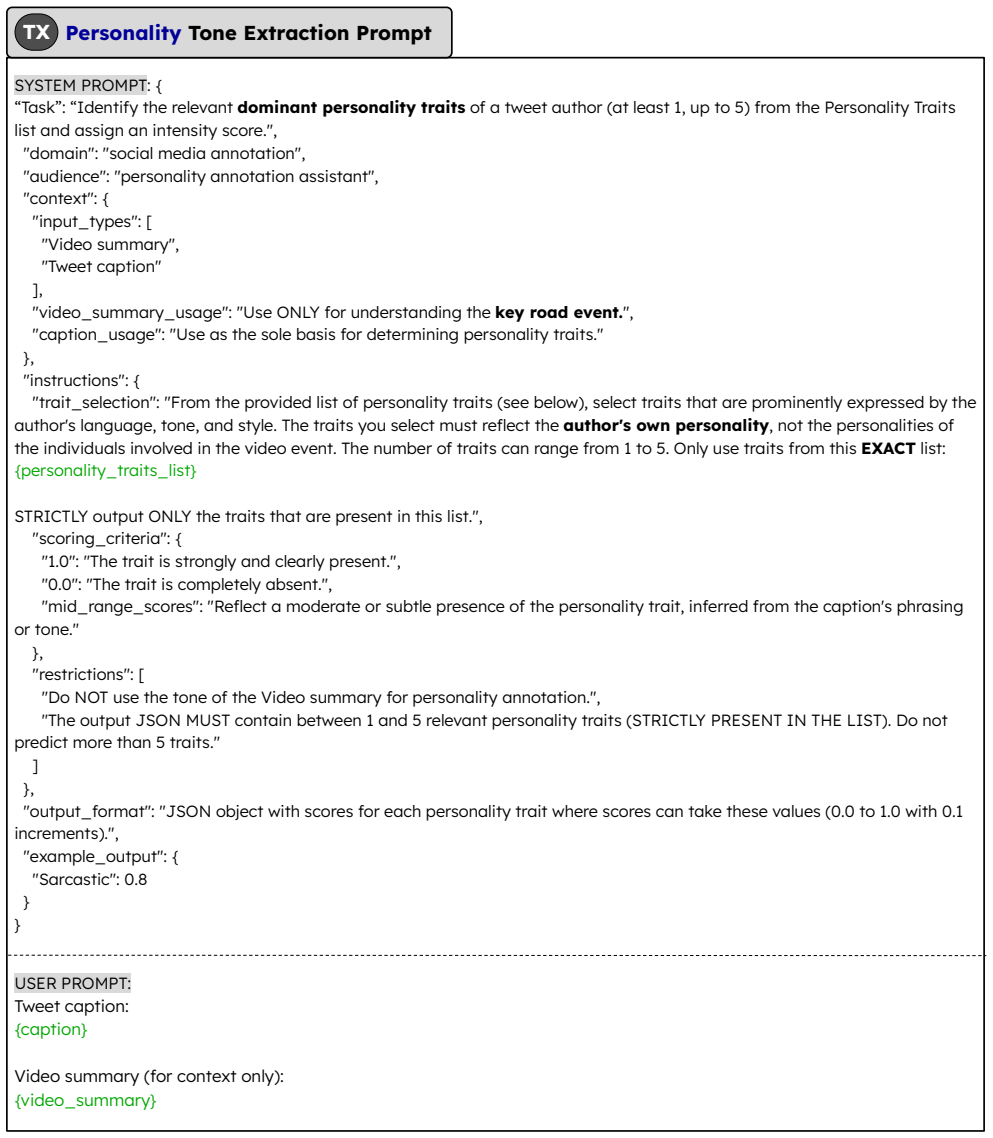
Authors: We acknowledge the value of explicit documentation for the annotation process. Although our human-validated pipeline was designed with instructions to prioritize tonal style over factual content, we did not include inter-annotator agreement statistics or the full guidelines in the manuscript. In the revised version, we will add the complete annotation guidelines to the supplementary material, report inter-annotator agreement (e.g., Fleiss’ kappa across annotators), and include post-hoc correlation analyses (Pearson and Spearman) between tone labels and factual metadata such as event severity and object counts. These additions will strengthen the evidence that stylistic variation is independent of content. revision: yes
-
Referee: [§5 (User Study and RoadTones-Eval)] §5 (User Study and RoadTones-Eval): The user study is cited as validating caption quality, tone control, and factual consistency, yet the text supplies no quantitative results (e.g., mean scores, statistical tests, or inter-rater reliability), error analysis, or ablation details. This absence prevents verification of the strength of the empirical support for the central claims on tone adherence and factual consistency.
Authors: We agree that the current description of the user study is insufficiently detailed. While the manuscript states that the study validates the relevant properties, specific quantitative results were summarized rather than fully reported. In the revision, we will expand §5 to include mean scores and standard deviations from the Likert-scale ratings, statistical tests (e.g., paired t-tests for tone control comparisons), inter-rater reliability metrics (e.g., Cronbach’s alpha), a concise error analysis, and any relevant ablation results. These details will be placed in the main text or appendix as appropriate to allow full verification of our claims. revision: yes
Circularity Check
No significant circularity in empirical dataset-model construction
full rationale
The paper presents an empirical contribution consisting of a new dataset (RoadTones-51K), a controllable video-to-text model (RoadTones-VL-CoT), and an evaluation suite (RoadTones-Eval), all built via a human-validated data generation pipeline and validated through user studies. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The central claims rest on external human annotation and validation processes rather than reducing to self-referential definitions or inputs by construction, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a comprehensive dataset-model-evaluation suite for tone-controllable road video captioning... RoadTones-VL-CoT... RoadTones-Eval suite
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Narrative Control (NC) governs the narrative voice by specifying... personality... writing style... Structural Control (SC) regulates the presentation structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Tianlang Chen, Zhongping Zhang, Quanzeng You, Chen Fang, Zhaowen Wang, Hailin Jin, and Jiebo Luo. “fac- tual”or“emotional”: Stylized image captioning with adaptive learning and attention. InProceedings of the european con- ference on computer vision (ECCV), pages 519–535, 2018. 2
work page 2018
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 6, 7, 14, 15, 34, 35, 36, 37, 38,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Nexar dashcam collision...CVPR, 2025
Moura et al. Nexar dashcam collision...CVPR, 2025. 19
work page 2025
-
[6]
Mscap: Multi-style image captioning with unpaired stylized text
Longteng Guo, Jing Liu, Peng Yao, Jiangwei Li, and Han- qing Lu. Mscap: Multi-style image captioning with unpaired stylized text. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4204–4213,
-
[7]
Robotron- drive: All-in-one large multimodal model for autonomous driving
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Ze- qun Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Robotron- drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 8011–8021, 2025. 6
work page 2025
-
[8]
Textual explanations for self-driving vehicles
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. InProceedings of the European conference on computer vision (ECCV), pages 563–578, 2018. 1, 2
work page 2018
-
[9]
From generation to judgment: Opportunities and challenges of llm-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757–2791, 2025. 6, 7, 20
work page 2025
-
[10]
O2na: An object-oriented non- autoregressive approach for controllable video captioning
Fenglin Liu, Xuancheng Ren, Xian Wu, Bang Yang, Shen Ge, Yuexian Zou, and Xu Sun. O2na: An object-oriented non- autoregressive approach for controllable video captioning. arXiv preprint arXiv:2108.02359, 2021. 2
-
[11]
Dolphins: Multimodal language model for driving
Yingzi Ma, Yulong Cao, Jiachen Sun, Marco Pavone, and Chaowei Xiao. Dolphins: Multimodal language model for driving. InEuropean Conference on Computer Vision, pages 403–420. Springer, 2024. 1, 2, 6
work page 2024
-
[12]
Drama: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1043–1052, 2023
work page 2023
-
[13]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan H¨unermann, Alice Karn- sund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024. 1, 2, 7, 8, 13, 16, 17
work page 2024
-
[14]
Senticap: Generating image descriptions with sentiments
Alexander Mathews, Lexing Xie, and Xuming He. Senticap: Generating image descriptions with sentiments. InProceed- ings of the AAAI conference on artificial intelligence, 2016. 2
work page 2016
-
[15]
Tomoya Nitta, Takumi Fukuzawa, and Toru Tamaki. Fine- grained length controllable video captioning with ordinal embeddings.IEEE Access, 12:189667–189688, 2024. 2
work page 2024
-
[16]
OpenAI. Gpt-5 system card. https://cdn.openai. com/gpt-5-system-card.pdf, 2025. 6
work page 2025
-
[17]
OpenAI. Introducing gpt-4.1. https://openai.com/ index/gpt-4-1/, 2025. 3, 4, 6, 16, 17, 18, 20
work page 2025
-
[18]
Chirag Parikh, Rohit Saluja, CV Jawahar, and Ravi Kiran Sarvadevabhatla. Idd-x: A multi-view dataset for ego-relative important object localization and explanation in dense and unstructured traffic. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 14815–14821. IEEE, 2024. 2
work page 2024
-
[19]
T., Tathagata Ghosh, and Ravi Kiran Sarvadevabhatla
Chirag Parikh, Deepti Rawat, Rakshitha R. T., Tathagata Ghosh, and Ravi Kiran Sarvadevabhatla. Roadsocial: A di- verse videoqa dataset and benchmark for road event under- standing from social video narratives, 2025. 1, 2, 3, 6, 8, 16, 17
work page 2025
-
[20]
Tianheng Qiu, Jingchun Gao, Jingyu Li, Huiyi Leong, Xuan Huang, Xi Wang, Xiaocheng Zhang, Kele Xu, and Lan Zhang. Intentvcnet: Bridging spatio-temporal gaps for intention- oriented controllable video captioning.arXiv preprint arXiv:2507.18531, 2025. 2
-
[21]
Qwen. Qwen3-vl-8b-instruct. https://huggingface. co/Qwen/Qwen3-VL-8B-Instruct , 2025. 5, 6, 7, 14, 15, 34, 35, 36, 37, 38, 39, 40, 41
work page 2025
-
[22]
Captionsmiths: Flexi- bly controlling language pattern in image captioning.ICCV,
Kuniaki Saito, Donghyun Kim, Kwanyong Park, Atsushi Hashimoto, and Yoshitaka Ushiku. Captionsmiths: Flexi- bly controlling language pattern in image captioning.ICCV,
-
[23]
Engaging image captioning via personality,
Kurt Shuster, Samuel Humeau, Hexiang Hu, Antoine Bordes, and Jason Weston. Engaging image captioning via personality,
-
[24]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 1, 2
work page 2024
-
[25]
Peipei Song, Dan Guo, Xun Yang, Shengeng Tang, and Meng Wang. Emotional video captioning with vision-based emo- tion interpretation network.IEEE Transactions on Image Processing, 33:1122–1135, 2024. 2
work page 2024
-
[26]
Controllable video captioning with pos sequence guidance based on gated fusion network
Bairui Wang, Lin Ma, Wei Zhang, Wenhao Jiang, Jingwen Wang, and Wei Liu. Controllable video captioning with pos sequence guidance based on gated fusion network. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 2641–2650, 2019. 2
work page 2019
-
[27]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 6 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Li Xu, He Huang, and Jun Liu. Sutd-trafficqa: A question an- swering benchmark and an efficient network for video reason- ing over traffic events. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 9878–9888, 2021. 1, 2, 7, 8, 13, 16, 17
work page 2021
-
[29]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wen- shuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking effi- cient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025. 6, 14, 15, 34, 35, 36, 37, 38, 39, 40, 41
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Con- trollable video captioning with an exemplar sentence
Yitian Yuan, Lin Ma, Jingwen Wang, and Wenwu Zhu. Con- trollable video captioning with an exemplar sentence. In Proceedings of the 28th ACM International Conference on Multimedia, pages 1085–1093, 2020. 2
work page 2020
-
[31]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Embodied understanding of driving scenarios
Yunsong Zhou, Linyan Huang, Qingwen Bu, Jia Zeng, Tianyu Li, Hang Qiu, Hongzi Zhu, Minyi Guo, Yu Qiao, and Hongyang Li. Embodied understanding of driving scenarios. InEuropean Conference on Computer Vision, pages 129–148. Springer, 2024. 1, 2 10 RoadTones: Tone Controllable Text Generation from Road Event Videos Supplementary Material 11 Contents
work page 2024
-
[33]
TC-Gen Tone-Controlled Caption Generation
Dataset Creation 3 4.1. TC-Gen Tone-Controlled Caption Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 4.2. TX Tone Extractor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 4.3. Data Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[34]
VLM for Tone-Controllable Captioning 5
-
[35]
TE Tone Evaluation Metrics 6
-
[36]
Let’s look out for one another
User Study 8 10 . Conclusion 8 List of Figures 13 A . Dataset Creation 16 A.1 .TC-GenTone-Controlled Caption Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 .TX Tone Extractor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.3 . Data Statistics . . . . . . . . . . ...
-
[37]
The colors in the generated captions map to blue for Personality and brown for Writing Style. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 3 Tone-controlled Caption Generation pipeline.Inputs A.1 and A.2 include the target Tone Con- trols (Narrative and Structural) and a detailed video summary respectively. T...
work page 2048
-
[38]
A car pulled out from a side road without leaving sufficient space, nearly hitting a cyclist
Key Event summary: A dashcam video captured a near-miss incident involving dangerous and careless driving in London, United Kingdom. A car pulled out from a side road without leaving sufficient space, nearly hitting a cyclist. The primary reason for the near-miss was the driver’s carelessness and failure to yield right of way to the cyclist. The incident ...
-
[39]
Caption with Writing style and structure applied (informativeness, word count, binary toggles): I seriously can’t believe how close that car came to hitting me today! [scream emoji] Some drivers. . . #CyclistLife
-
[40]
Caption with Personality traits refined (preserving writing style and structural controls): I seriously can’t believe how close that car came to hitting me today! [scream emoji] Some drivers. . . #CyclistLife Selection: The third step candidate best satisfies the provided personality, writing style and structural controls; returning it as final. [/REASONI...
-
[41]
Compare meanings of traits. Map generated traits to ground truth traits based on semantic similarity. - Example: "Assertive" can align with "Dominant" if close in meaning. - If a ground-truth trait has no similar trait in generated, mark it as missing. - If generated has extra traits not related to ground-truth, treat as mismatch
-
[42]
- If meanings align and scores are close, reward higher similarity
After mapping, compare the intensity scores (0 to 1). - If meanings align and scores are close, reward higher similarity. - If meanings align but scores differ a lot, penalize slightly
-
[43]
Produce a final similarity score. Return the score as a single float value between 0.0 and 1.0 (two decimals), with no other text or characters. Output (JSON only): { "personality_similarity_score": float } Personality Trait Evaluation PromptTE Figure 27.Personality tone alignment evaluation prompt (S p). 31 SYSTEM PROMPT: You are an expert writing style ann...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.