Autonomous LLM Agents & CTFs: A Second Look
Pith reviewed 2026-05-22 01:02 UTC · model grok-4.3
The pith
A general-purpose LLM agent matches the success rate of custom-engineered architectures on 30 web CTF challenges by solving 19 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
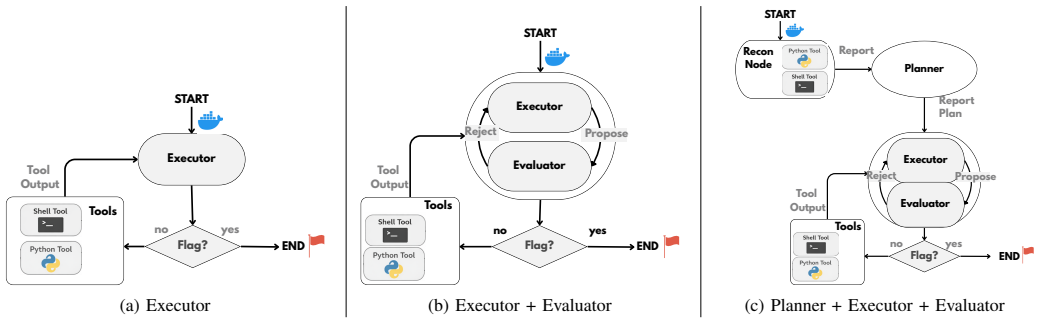
The paper shows that claude-code achieves performance comparable to the engineered architectures, solving 19 out of 30 tasks. Both the custom architectures and claude-code encounter the same difficulties in specific challenge categories, which points to barriers that keep current agents below human-level capability. By using the manually designed architectures, the authors measure the effect of added components and find that structured orchestration of specialized roles outperforms monolithic designs, which improves run-to-run consistency and reduces execution costs.
What carries the argument
claude-code, the general-purpose agent that automatically determines its internal architecture, serving as a baseline against custom modular designs of increasing complexity
If this is right
- General-purpose agents act as strong baselines for offensive security tasks without requiring heavy custom engineering.
- Certain vulnerability classes create persistent barriers that limit all current agents below human performance.
- Structured orchestration of specialized roles produces higher consistency and lower costs than monolithic agent designs.
Where Pith is reading between the lines
- Future work could prioritize base model improvements over added architectural complexity for these security tasks.
- Applying the agents to real-world security operations rather than isolated CTFs would test practical readiness.
- Teams might begin with a general agent and layer in modules only for the categories that show consistency problems.
Load-bearing premise
The 30 selected web-based CTF challenges across 14 vulnerability classes are representative enough to support general conclusions about agent capabilities and barriers.
What would settle it
Testing the same set of agents on a new collection of 30 CTF challenges from additional vulnerability classes or non-web settings and checking whether the 19 out of 30 success rate and shared failure patterns remain.
Figures

read the original abstract
Large Language Model (LLM) agents are increasingly proposed to automate offensive security tasks, with recent studies reporting near human-level success rates in Capture-the-Flag (CTF) challenges. We here revisit these results, providing a second look at these claims. We engineer different agent architectures of increasing complexity and modularity on 30 web-based CTFs challenges spanning 14 vulnerability classes. We instantiate these agents with multiple LLM backbones, and compare them with claude-code, a general-purpose agent that automatically determines its internal architecture. Our evaluation yields three main findings. First, claude-code achieves performance comparable to the engineered architectures (19/30 solved tasks), suggesting that general-purpose agents are strong baselines for offensive security tasks. Second, both our architectures and claude-code struggle in the same challenge categories, revealing persistent barriers that keep current agents below human-level capability. Third, by leveraging our manually designed architectures we can systematically measure the impact of additional components, finding that structured orchestration of specialized roles outperforms monolithic designs, improving run-to-run consistency, and reducing execution costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates engineered LLM agent architectures of increasing complexity and modularity against the general-purpose claude-code agent on 30 web-based CTF challenges spanning 14 vulnerability classes. It reports that claude-code solves 19/30 tasks with performance comparable to the engineered designs, identifies shared struggles across challenge categories as persistent barriers below human level, and finds that structured orchestration of specialized roles improves run-to-run consistency while reducing execution costs.
Significance. If the challenge selection is representative, the work establishes general-purpose agents as strong baselines for offensive security tasks and provides actionable evidence on the value of modular designs. The multi-backbone comparison and direct performance counts add empirical weight to claims about agent limitations in cybersecurity.
major comments (2)
- [Abstract and evaluation setup] Abstract and evaluation setup: the central claims that claude-code's 19/30 performance shows general-purpose agents are strong baselines and that persistent barriers are revealed rest on the 30 challenges being representative across 14 classes, yet no selection criteria, difficulty calibration against human solvers, or coverage statistics are provided; this risks selection effects favoring easier web vulnerabilities such as SQLi and XSS.
- [Results section] Results section: the assertion of improved run-to-run consistency from structured orchestration lacks reported exact run counts per configuration or statistical tests supporting the consistency and cost-reduction claims, which are load-bearing for the third main finding.
minor comments (2)
- [Architecture descriptions] Notation for agent components could be standardized across sections to improve readability of the architecture comparisons.
- [Results] A table summarizing solved tasks per vulnerability class would help readers assess the distribution of successes and failures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and evaluation setup] Abstract and evaluation setup: the central claims that claude-code's 19/30 performance shows general-purpose agents are strong baselines and that persistent barriers are revealed rest on the 30 challenges being representative across 14 classes, yet no selection criteria, difficulty calibration against human solvers, or coverage statistics are provided; this risks selection effects favoring easier web vulnerabilities such as SQLi and XSS.
Authors: We acknowledge that the abstract and evaluation setup do not provide explicit selection criteria, difficulty calibration details, or coverage statistics. The 30 challenges were selected from public CTF platforms specifically to span 14 distinct web vulnerability classes, with the intent of covering a representative sample of common offensive security tasks. To address the concern about potential selection effects, we will revise the evaluation setup section to include a clear description of the challenge sources, the rationale for class coverage, and any available information on typical difficulty levels from CTF leaderboards. While comprehensive human solve-rate calibration data is not uniformly available across all challenges, we can add references to public benchmarks where they exist. These additions will clarify the representativeness of the set without altering the core findings. revision: yes
-
Referee: [Results section] Results section: the assertion of improved run-to-run consistency from structured orchestration lacks reported exact run counts per configuration or statistical tests supporting the consistency and cost-reduction claims, which are load-bearing for the third main finding.
Authors: We agree that the results section would be strengthened by reporting the exact number of runs performed and supporting statistical information. Our experiments involved multiple independent executions per agent configuration to observe consistency and cost differences, but these were summarized at a high level rather than presented with full counts or tests. We will revise the results section to specify the run counts (for example, the number of trials conducted for each architecture and backbone), report variance or standard deviation in success rates across runs to quantify consistency improvements, and include comparative cost metrics such as average token usage or execution time. This will provide the quantitative backing needed for the third main finding. revision: yes
Circularity Check
Empirical performance counts on external CTF benchmarks show no circular derivation
full rationale
The paper reports direct experimental results from running engineered and general-purpose LLM agents on a fixed set of 30 web-based CTF challenges, yielding counts such as 19/30 solved tasks and category-specific struggles. These outcomes are measured against external benchmarks rather than derived from fitted parameters, self-referential equations, or load-bearing self-citations. Architectures are manually specified and compared without any reduction of claims to prior author work or ansatz smuggling. The evaluation chain is therefore self-contained against observable performance data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 30 web-based CTF challenges spanning 14 vulnerability classes form a representative testbed for evaluating LLM agent capabilities in offensive security.
Reference graph
Works this paper leans on
-
[1]
M. Bishop, “About penetration testing,”IEEE Security & Privacy, vol. 5, no. 6, pp. 84–87, 2007
work page 2007
-
[2]
Technical Guide to Information Security Testing and Assessment,
Scarfone, Karen, Souppaya, Murugiah, and Cody, Amanda, “Technical Guide to Information Security Testing and Assessment,” National Insti- tute of Standards and Technology, Tech. Rep. NIST Special Publication 800-115, 2008
work page 2008
-
[3]
2024 isc2 cybersecurity workforce study,
ISC2, “2024 isc2 cybersecurity workforce study,” https://www.isc2. org/Insights/2024/10/ISC2-2024-Cybersecurity-Workforce-Study, Octo- ber 31 2024, accessed: 2026-03-09
work page 2024
-
[4]
2025 unit 42 global incident response report,
Palo Alto Networks Unit 42, “2025 unit 42 global incident response report,” https://www.paloaltonetworks.com/engage/ unit42-2025-global-incident-response-report, Palo Alto Networks, 2025, accessed: 2026-03-09
work page 2025
-
[5]
When llms meet cybersecu- rity: A systematic literature review,
J. Zhang, H. Bu, H. Wen, and Y . e. a. Liu, “When llms meet cybersecu- rity: A systematic literature review,”Cybersecurity, vol. 8, no. 1, p. 55, 2025
work page 2025
-
[6]
PentestGPT: Evaluating and harnessing large language models for automated pene- tration testing,
G. Deng, Y . Liu, V . Mayoral-Vilches, and P. L. et al., “PentestGPT: Evaluating and harnessing large language models for automated pene- tration testing,” in33rd USENIX Security Symposium, Aug. 2024, pp. 847–864
work page 2024
-
[7]
Getting pwn’d by ai: Penetration testing with large language models,
A. Happe and J. Cito, “Getting pwn’d by ai: Penetration testing with large language models,” inProceeding of the European Software Engineering Conference, 2023, pp. 2082–2086
work page 2023
-
[8]
Au- topenbench: A vulnerability testing benchmark for generative agents,
L. Gioacchini, A. Delsanto, I. Drago, and M. e. a. Mellia, “Au- topenbench: A vulnerability testing benchmark for generative agents,” inProceedings of the Conference on Empirical Methods in Natural Language Processing, 2025, pp. 1615–1624
work page 2025
-
[9]
Teams of llm agents can exploit zero-day vulnerabilities,
Y . Zhu, A. Kellermann, A. Gupta, and P. L. et al., “Teams of llm agents can exploit zero-day vulnerabilities,” 2025
work page 2025
-
[10]
Vulnbot: Autonomous penetration testing for a multi-agent collaborative framework,
H. Kong, D. Hu, J. Ge, L. Li, T. Li, and B. Wu, “Vulnbot: Autonomous penetration testing for a multi-agent collaborative framework,” 2025
work page 2025
-
[11]
Multi-agent penetration testing ai for the web,
I. David and A. Gervais, “Multi-agent penetration testing ai for the web,” 2025
work page 2025
-
[12]
Cybench: A framework for evaluating cybersecurity capabilities and risks of language models,
A. K. Zhang, N. Perry, R. Dulepet, and J. J. et al., “Cybench: A framework for evaluating cybersecurity capabilities and risks of language models,” inInternational Conference on Learning Representations, 2025
work page 2025
-
[13]
Y . Zhu, A. Kellermann, D. Bowman, and e. a. Philip Li, “CVE- bench: A benchmark for AI agents’ ability to exploit real-world web application vulnerabilities,” inInternational Conference on Machine Learning, 2025
work page 2025
-
[14]
Claude is competitive with humans in (some) cyber com- petitions,
Anthropic, “Claude is competitive with humans in (some) cyber com- petitions,” https://red.anthropic.com/2025/cyber-competitions/, August 9 2025, accessed: 2026-03-09
work page 2025
-
[15]
The road to top 1: How xbow did it,
XBOW, “The road to top 1: How xbow did it,” https://xbow.com/blog/ top-1-how-xbow-did-it, June 24 2025, accessed: 2026-03-09
work page 2025
-
[16]
Comparing AI agents to cybersecurity professionals in real-world penetration testing,
J. W. Lin, E. K. Jones, D. J. Jasper, and E. J. shen Ho et al., “Comparing AI agents to cybersecurity professionals in real-world penetration testing,” inThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[17]
Ten years of{iCTF}: The good, the bad, and the ugly,
G. Vigna, K. Borgolte, J. Corbetta, and e. a. Doup ´e, Adam, “Ten years of{iCTF}: The good, the bad, and the ugly,” in2014 USENIX Summit on Gaming, Games, and Gamification in Security Education (3GSE 14), 2014
work page 2014
-
[18]
Nyu ctf bench: A scalable open-source benchmark dataset for evaluating llms in offensive security,
M. Shao, S. Jancheska, M. Udeshi, and B. e. a. Dolan-Gavitt, “Nyu ctf bench: A scalable open-source benchmark dataset for evaluating llms in offensive security,”Advances in Neural Information Processing Systems, vol. 37, pp. 57 472–57 498, 2024
work page 2024
-
[19]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,
L. Wang, W. Xu, Y . Lan, and e. a. Hu, Zhiqiang, “Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,” inProceedings of the Association for Computational Linguistics, Jul. 2023, pp. 2609–2634
work page 2023
-
[20]
Evaluation and benchmarking of llm agents: A survey,
M. Mohammadi, Y . Li, J. Lo, and W. Yip, “Evaluation and benchmarking of llm agents: A survey,” inProceedings of the SIGKDD Conference on Knowledge Discovery and Data Mining, 2025, pp. 6129–6139
work page 2025
-
[21]
Cognitive architectures for language agents,
T. Sumers, S. Yao, K. R. Narasimhan, and T. L. Griffiths, “Cognitive architectures for language agents,”Transactions on Machine Learning Research, 2023
work page 2023
-
[22]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, and e. a. Du, Nan, “React: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[23]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, and e. a. Raileanu, Roberta, “Toolformer: Language models can teach themselves to use tools,” Advances in neural information processing systems, vol. 36, pp. 68 539– 68 551, 2023
work page 2023
-
[24]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, and e. a. Li, Beibin, “Autogen: Enabling next-gen llm applications via multi-agent conversations,” in Conference on language modeling, 2024
work page 2024
-
[25]
Agentverse: Facili- tating multi-agent collaboration and exploring emergent behaviors,
W. Chen, Y . Su, J. Zuo, and e. a. Yang, Cheng, “Agentverse: Facili- tating multi-agent collaboration and exploring emergent behaviors,” in International Conference on Learning Representations, 2023
work page 2023
-
[26]
Cybersleuth: Autonomous blue-team llm agent for web attack forensics,
S. Fumero, K. Huang, M. Boffa, D. Giordano, M. Mellia, Z. B. Houidi, and D. Rossi, “Cybersleuth: Autonomous blue-team llm agent for web attack forensics,”arXiv preprint arXiv:2508.20643, 2025
-
[27]
From generation to judgment: Opportunities and challenges of llm-as-a-judge,
D. Li, B. Jiang, L. Huang, and e. a. Beigi, Alimohammad, “From generation to judgment: Opportunities and challenges of llm-as-a-judge,” inProceedings of the Conference on Empirical Methods in Natural Language Processing, 2025, pp. 2757–2791
work page 2025
-
[28]
“Claude code overview,” https://code.claude.com/docs/en/overview, An- thropic, 2026, claude Code is an agentic coding tool that reads your codebase, edits files, runs commands, and integrates with development tools
work page 2026
-
[29]
How claude remembers your project,
“How claude remembers your project,” https://code.claude.com/docs/en/ memory, Anthropic, 2026, describes CLAUDE.md and auto memory mechanisms that allow persistent context across sessions
work page 2026
-
[30]
Introducing gpt-4.1 in the api,
OpenAI, “Introducing gpt-4.1 in the api,” https://openai.com/index/ gpt-4-1/, 2025, official OpenAI model release announcement for GPT- 4.1
work page 2025
-
[31]
——, “Gpt-5 system card,” https://openai.com/index/ gpt-5-system-card/, 2025, official OpenAI system card describing GPT-5 architecture and safety
work page 2025
-
[32]
Anthropic, “Claude opus 4.6 system card,” https://www-cdn.anthropic. com/0dd865075ad3132672ee0ab40b05a53f14cf5288.pdf, 2026, official Anthropic model card for Claude Opus 4.6. APPENDIX A. Scholar-Like Enumeration – Succesful Execution At step 9, the agent confirms an IDOR vulnerability (arbi- trary order IDs accepted). Rather than exploiting it immedi- at...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.