A Causal Argumentation Method for Explainability of Machine Learning Models
Pith reviewed 2026-05-22 08:53 UTC · model grok-4.3
The pith
A method that discovers causal relationships among features and maps them into a bipolar argumentation framework can explain why a machine learning model selects particular outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
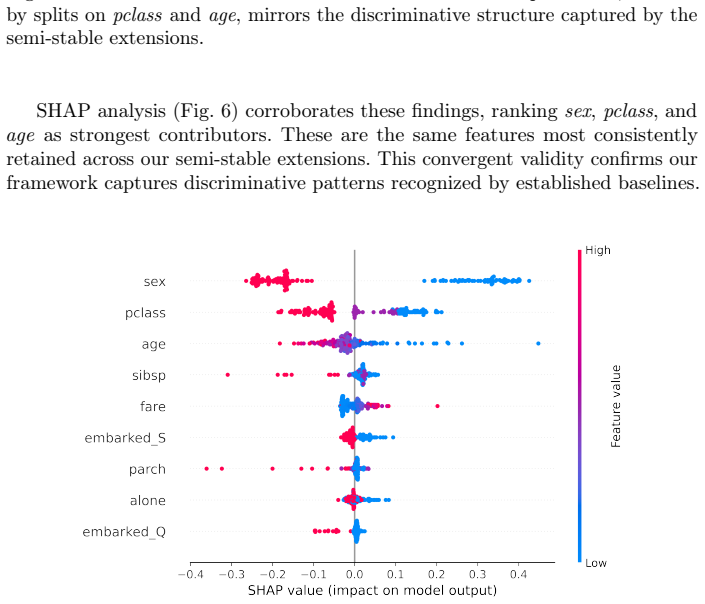
By identifying causal relationships among variables using causal discovery methods and translating these into a Bipolar Argumentation Framework (BAF) to represent supportive and opposing interactions among features, then using semi-stable semantics to find extensions of features that explain why certain outcomes may have been chosen, the method explains why models may be making predictions.
What carries the argument
Bipolar Argumentation Framework (BAF) built from causal discovery output, with semi-stable semantics that select consistent sets of features as explanatory extensions.
If this is right
- The approach yields explanations that incorporate both positive and negative interactions among features rather than treating features in isolation.
- Results can be produced for standard tabular benchmarks and directly compared with existing post-hoc attribution methods.
- Explanations remain tied to the causal structure present in the data instead of purely correlational importance scores.
Where Pith is reading between the lines
- If the causal step is sound, the method could flag cases where a model exploits non-causal shortcuts that standard feature-importance tools overlook.
- The same pipeline could be reused on new domains by swapping the causal discovery algorithm for one tuned to the data type.
- User-supplied constraints could be added as additional attack or support relations to steer the extensions toward domain-specific requirements.
Load-bearing premise
The causal relationships recovered by standard discovery algorithms from the training data are accurate and complete enough that the resulting argumentation extensions meaningfully reflect the model's actual decision process.
What would settle it
If the feature sets returned by the method on a benchmark dataset fail to match the features that actually change the model's output when perturbed, or if they include variables known to be non-causal in the data-generating process, the explanatory value of the extensions would be refuted.
Figures








read the original abstract
Explainable AI (XAI) methods identify which features are relevant to a model's predictions but often fail to clarify why certain decisions are made. In this work, we present a novel method that integrates causality with argument-based reasoning to explain why models may be making predictions. Our approach first identifies causal relationships among variables using causal discovery methods and then translates these into a Bipolar Argumentation Framework (BAF) to represent supportive and opposing interactions among features. By using semi-stable semantics, we find extensions of features that explain why certain outcomes may have been chosen. We demonstrate our method on two benchmark datasets and compare its results against standard post-hoc explainability approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a novel XAI method that integrates causal discovery with Bipolar Argumentation Frameworks (BAF). Causal relationships are identified from data, mapped to support/attack relations in BAF, and semi-stable extensions are used to explain model predictions. It is demonstrated on two benchmark datasets with comparisons to standard post-hoc explainability approaches.
Significance. If the method's explanations are shown to faithfully represent the model's reasoning, it could provide a more structured and causal basis for interpretability compared to feature attribution methods. The use of argumentation semantics adds a layer of reasoning that may help in understanding 'why' decisions are made. However, without detailed results or validation, the significance remains potential rather than demonstrated.
major comments (2)
- The abstract outlines the intended workflow but supplies no derivation details, no quantitative results, no error analysis, and no description of how the BAF extensions are validated against the model's actual behavior, making it impossible to assess whether the data or method supports the central claim.
- The pipeline runs causal discovery on the input dataset and constructs the BAF without inspecting the trained model (weights, decision surface, or feature attributions internal to the predictor). The central claim therefore requires that the model's predictions are driven by the recovered causal structure; when the model instead exploits non-causal correlations or approximations, the BAF extensions will not correspond to the features the model actually used.
minor comments (2)
- Clarify the specific causal discovery algorithms used and the exact translation rules from causal graph to BAF relations.
- Provide more details on the benchmark datasets, the ML models trained, and the quantitative comparison metrics used against standard XAI methods.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our paper. We address each of the major comments in detail below and indicate the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: The abstract outlines the intended workflow but supplies no derivation details, no quantitative results, no error analysis, and no description of how the BAF extensions are validated against the model's actual behavior, making it impossible to assess whether the data or method supports the central claim.
Authors: We agree that the abstract, as currently written, is high-level and does not include specific details on derivations, results, or validation. The body of the manuscript provides these elements: derivation of the BAF construction is detailed in Section 3, quantitative results and comparisons to other XAI methods are presented in Section 5 with error analysis, and validation of the semi-stable extensions against model predictions is described in Section 4. To address the referee's concern and improve the standalone readability of the abstract, we will revise it to include a concise summary of the key results and validation approach. revision: yes
-
Referee: The pipeline runs causal discovery on the input dataset and constructs the BAF without inspecting the trained model (weights, decision surface, or feature attributions internal to the predictor). The central claim therefore requires that the model's predictions are driven by the recovered causal structure; when the model instead exploits non-causal correlations or approximations, the BAF extensions will not correspond to the features the model actually used.
Authors: The referee correctly identifies a key characteristic of our proposed method. By design, the approach is model-agnostic and derives explanations from the causal structure in the data rather than from internal model parameters. This allows it to provide causal argumentation-based explanations applicable to any ML model. We do not claim that the explanations always perfectly mirror the model's internal reasoning if the model has learned non-causal patterns. In the revised version, we will clarify this scope in the introduction and add a limitations section discussing scenarios where the model may rely on spurious correlations. Additionally, we will include new experiments that compare our causal explanations with SHAP values or other model-specific attributions on the benchmark datasets to empirically assess their correspondence. revision: partial
Circularity Check
No circularity in the causal argumentation explainability pipeline
full rationale
The paper proposes a constructive pipeline that applies standard causal discovery algorithms to the input dataset, maps the resulting graph into a Bipolar Argumentation Framework to encode support and attack relations among features, and extracts semi-stable extensions as explanatory sets. No equations, fitted parameters, or self-referential definitions appear in the described method; the output extensions are generated by applying established argumentation semantics to the discovered causal structure rather than being defined in terms of themselves or statistically forced by a fit on the same data. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are invoked. The central claim is therefore a methodological construction whose validity rests on external assumptions about causal discovery accuracy and correspondence to model behavior, not on any internal reduction of the claimed explanations to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Causal discovery methods applied to the dataset will recover the relevant causal relationships among features.
- domain assumption The translation of causal relationships into a Bipolar Argumentation Framework preserves the explanatory power needed for model decisions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach first identifies causal relationships among variables using causal discovery methods and then translates these into a Bipolar Argumentation Framework (BAF) to represent supportive and opposing interactions among features. By using semi-stable semantics, we find extensions of features that explain why certain outcomes may have been chosen.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
In: 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI)
Bistarelli, S., Mancinelli, A., Santini, F., Taticchi, C.: Arg-XAI: a Tool for Explaining Machine Learning Results. In: 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI). pp. 205–212 (Oct 2022).https://doi.org/10 .1109/ICTAI56018.2022.00037 , https://ieeexplore.ieee.org/document/100 97957
-
[3]
Transactions on Machine Learning Research (Jan 2024),https: //openreview.net/forum?id=PGLbZpVk2n
Bystrova, D., Assaad, C.K., Arbel, J., Devijver, E., Gaussier, E., Thuiller, W.: Causal Discovery from Time Series with Hybrids of Constraint-Based and Noise- Based Algorithms. Transactions on Machine Learning Research (Jan 2024),https: //openreview.net/forum?id=PGLbZpVk2n
work page 2024
-
[4]
Caminada, M.: Semi-Stable Semantics. In: Proceedings of the 2006 conference on Computational Models of Argument: Proceedings of COMMA 2006. pp. 121–130. IOS Press, NLD (May 2006)
work page 2006
-
[5]
Cayrol, C., Lagasquie-Schiex, M.C.: On the Acceptability of Arguments in Bipolar Argumentation Frameworks. In: Godo, L. (ed.) Symbolic and Quantitative Ap- proaches to Reasoning with Uncertainty. pp. 378–389. Springer, Berlin, Heidelberg (2005).https://doi.org/10.1007/11518655_33
-
[6]
National Geographic Books (Oct 2020), google-Books-ID: KGCNEAAAQBAJ
Christian, B.: The Alignment Problem: Machine Learning and Human Values. National Geographic Books (Oct 2020), google-Books-ID: KGCNEAAAQBAJ
work page 2020
-
[7]
Artificial Intelligence 77(2), pp
Dung, P.M.: On the acceptability of arguments and its fundamental role in non- monotonic reasoning, logic programming andn-person games. Artificial Intelligence 77(2), 321–357 (Sep 1995).https://doi.org/10.1016/0004-3702(94)00041-X , https://www.sciencedirect.com/science/article/pii/000437029400041X
-
[8]
Friedman, J.H.: Greedy function approximation: A gradient boosting machine. The Annals of Statistics29(5), 1189–1232 (Oct 2001).https://doi.org/10.1214/aos/ 1013203451, https://projecteuclid.org/journals/annals-of-statistics/vo lume-29/issue-5/Greedy-function-approximation-A-gradient-boosting-mac hine/10.1214/aos/1013203451.full
-
[9]
Glymour, C., Zhang, K., Spirtes, P.: Review of Causal Discovery Methods Based on Graphical Models. Frontiers in Genetics10(Jun 2019).https://doi.org/10.3 389/fgene.2019.00524, https://www.frontiersin.org/journals/genetics/ar ticles/10.3389/fgene.2019.00524/full A Causal-Argumentation Method 19
-
[10]
Cambridge University Press (Aug 1996), google-Books-ID: uu6zXrogwWAC
Josephson, J.R., Josephson, S.G.: Abductive Inference: Computation, Philos- ophy, Technology. Cambridge University Press (Aug 1996), google-Books-ID: uu6zXrogwWAC
work page 1996
-
[11]
Artif Intell345, 104346 (2025)
Miller, T.: Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence267, 1–38 (Feb 2019).https://doi.org/10.1016/j.artint .2018.07.007, https://www.sciencedirect.com/science/article/pii/S00043 70218305988
-
[12]
Packt Publishing Ltd (May 2023), google-Books-ID: 4V3DEAAAQBAJ
Molak, A.: Causal Inference and Discovery in Python: Unlock the secrets of mod- ern causal machine learning with DoWhy, EconML, PyTorch and more. Packt Publishing Ltd (May 2023), google-Books-ID: 4V3DEAAAQBAJ
work page 2023
-
[13]
Molnar, C.: Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, vol. 510. Christoph Molnar, 1 edn. (2019)
work page 2019
-
[14]
In: Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.R., Samek, W
Molnar, C., König, G., Herbinger, J., Freiesleben, T., Dandl, S., Scholbeck, C.A., Casalicchio, G., Grosse-Wentrup, M., Bischl, B.: General Pitfalls of Model-Agnostic Interpretation Methods for Machine Learning Models. In: Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.R., Samek, W. (eds.) xxAI - Beyond Explainable AI: International Workshop, He...
-
[15]
Mothilal, R.K., Sharma, A., Tan, C.: Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations. In: Proceedings of the 2020 Confer- ence on Fairness, Accountability, and Transparency. pp. 607–617 (Jan 2020).https: //doi.org/10.1145/3351095.3372850 , http://arxiv.org/abs/1905.07697 , arXiv:1905.07697 [cs]
-
[16]
Basic Books (May 2018), google-Books-ID: 9H0dDQAAQBAJ
Pearl, J., Mackenzie, D.: The Book of Why: The New Science of Cause and Effect. Basic Books (May 2018), google-Books-ID: 9H0dDQAAQBAJ
work page 2018
-
[17]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M
Reimers, C., Runge, J., Denzler, J.: Determining the Relevance of Features for Deep Neural Networks. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020, vol. 12371, pp. 330–346. Springer International Publishing, Cham (2020). https://doi.org/10.1007/978-3-030-58574-7_20 , https://link.springer.com/10.1007/978- 3- 030- 5...
-
[18]
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
Ribeiro, M.T., Singh, S., Guestrin, C.: "Why Should I Trust You?": Explaining the Predictions of Any Classifier (Aug 2016),http://arxiv.org/abs/1602.04938, arXiv:1602.04938 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Salgado, H., Kendall, M.R., Ceberio, M.: Causal Discovery for Explainable AI: A Dual-Encoding Approach. In: The 17th International Conference on Ambient Systems, Networks and Technologies (ANT 2023) / The 3rd International Workshop on Causality, Agents and Large Models (CALM-26). Procedia Computer Science, Springer, Istanbul, Turkey (Apr 2026).https://doi...
-
[20]
MIT Press (Jan 2001), google-Books-ID: OZ0vEAAAQBAJ
Spirtes, P., Glymour, C., Scheines, R.: Causation, Prediction, and Search. MIT Press (Jan 2001), google-Books-ID: OZ0vEAAAQBAJ
work page 2001
-
[21]
Zheng, Y., Huang, B., Chen, W., Ramsey, J., Gong, M., Cai, R., Shimizu, S., Spirtes, P., Zhang, K.: Causal-learn: Causal Discovery in Python (Jul 2023).https: //doi.org/10.48550/arXiv.2307.16405 , http://arxiv.org/abs/2307.16405 , arXiv:2307.16405 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.