Prototype-Guided Classification Sub-Task Decoupling Framework: Enhancing Generalization and Interpretability for Multivariate Time Series
Pith reviewed 2026-05-22 08:22 UTC · model grok-4.3
The pith
PDFTime reformulates time series classification as a multi-stage prototype-guided process that separates feature learning from decision logic to raise accuracy and transparency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
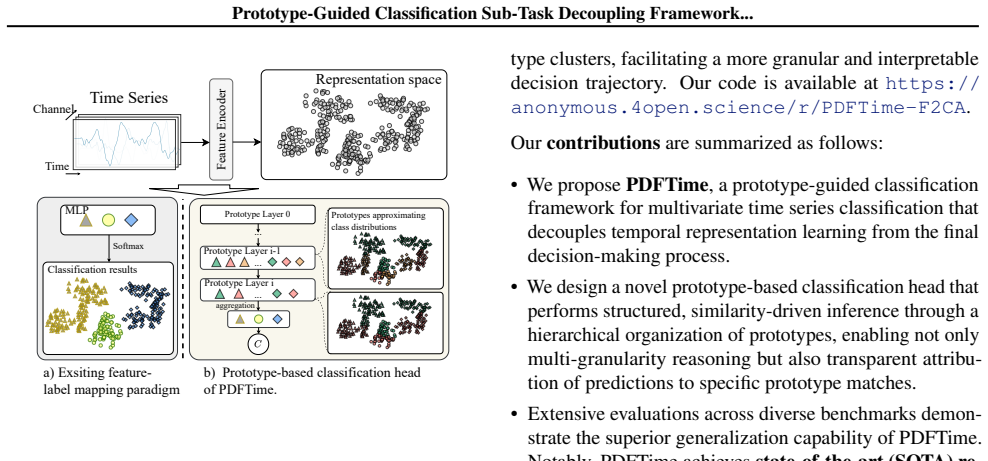
PDFTime is the first framework to reformulate time series classification as a decoupled, multi-stage similarity-based reasoning process. It leverages learned prototypes to approximate class-conditional feature distributions in the latent space, enabling progressive discrimination through classification sub-tasks of varying granularity and breaking the long-standing paradigm of direct black-box feature-to-label mapping.
What carries the argument
Learned prototypes that approximate class-conditional distributions, used to drive progressive discrimination across classification sub-tasks of varying granularity.
If this is right
- Achieves top-1 accuracy on 80 out of 128 UCR datasets.
- Delivers state-of-the-art performance with improved consistency and generalization on UEA and UCR benchmarks.
- Yields enhanced interpretability through explicit multi-stage similarity reasoning.
- Avoids conflating feature extraction and decision logic inside one inseparable mapping.
Where Pith is reading between the lines
- The same staged prototype approach could be tested on image or text classification to check whether progressive discrimination improves transparency outside time series.
- Prototypes might double as explanatory examples that let users see which class representatives most influenced each decision stage.
- Making the number or depth of stages depend on dataset complexity could be explored as a way to balance accuracy against computation.
- The structure may support transfer across related time series tasks by reusing the same prototypes for new but similar problems.
Load-bearing premise
Learned prototypes successfully approximate class-conditional feature distributions in the latent space, allowing the multi-stage sub-tasks to progressively discriminate classes without collapsing all information into a single linear projection.
What would settle it
An ablation that keeps the identical feature extractor but replaces the multi-stage prototype sub-tasks with a single linear classification head would show no accuracy gain or loss of consistency on the UCR archive.
Figures








read the original abstract
Time Series Classification (TSC) is a long-standing research problem that has gained increasing attention in recent years with the rapid growth of large-scale temporal data. Despite substantial progress enabled by deep learning, designing TSC models that are both accurate and interpretable remains a challenging task. Many existing approaches adopt a direct feature-to-label classification paradigm, by collapsing high-dimensional temporal embeddings into class logits via a single linear projection (often after global pooling), the paradigm conflates feature extraction and decision logic into an inseparable mapping. To address these limitations, we propose PDFTime, a prototype-guided framework that reformulates time series classification as a multi-stage decision process. Instead of direct feature-to-label mapping, PDFTime leverages learned prototypes to approximate class-conditional feature distributions in the latent space, enabling progressive discrimination through classification sub-tasks of varying granularity. To our knowledge, PDFTime is the first framework to reformulate time series classification as a decoupled, multi-stage similarity-based reasoning process, breaking the long-standing paradigm of direct, black-box feature-to-label mapping. Extensive evaluations demonstrate that PDFTime achieves state-of-the-art (SOTA) performance across UEA and UCR benchmarks. Notably, it secures the top-$1$ accuracy on 80 out of 128 datasets in the UCR archive, significantly outperforming recent strong baselines in both consistency and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PDFTime, a prototype-guided framework for multivariate time series classification that reformulates the task as a decoupled multi-stage similarity-based reasoning process. Learned prototypes approximate class-conditional distributions in latent space to enable progressive discrimination via sub-tasks of varying granularity, rather than collapsing embeddings into class logits through a single linear projection. The work claims to be the first such reformulation breaking the direct feature-to-label paradigm and reports SOTA results including top-1 accuracy on 80 of 128 UCR datasets.
Significance. If the central claims hold under rigorous validation, the framework could provide a more interpretable alternative to black-box TSC models by explicitly separating feature extraction from staged decision logic, with potential benefits for generalization on diverse temporal datasets.
major comments (2)
- [§4 (Experiments)] The manuscript does not present an ablation comparing the full multi-stage sub-task decoupling against a single-stage prototype similarity baseline (e.g., direct matching to the complete set of learned prototypes in one forward pass). This comparison is required to establish that the progressive discrimination across granularity levels is load-bearing for the reported accuracy gains and the 'breaking the paradigm' assertion.
- [Table 2] Table 2 and the UCR results paragraph report top-1 wins on 80/128 datasets but supply no information on the number of independent runs, random seeds, statistical significance tests (e.g., Wilcoxon or Friedman), or confirmation that the same train/test splits and baseline implementations from the UCR archive were used.
minor comments (2)
- [§3] Notation for the prototype update rule and sub-task loss terms should be introduced earlier (ideally in §3) to improve readability before the experimental section.
- The abstract states 'extensive evaluations' on UEA and UCR but the text should explicitly note whether all datasets are univariate or if multivariate handling is demonstrated with dedicated results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper accordingly to strengthen the experimental validation and reproducibility details.
read point-by-point responses
-
Referee: [§4 (Experiments)] The manuscript does not present an ablation comparing the full multi-stage sub-task decoupling against a single-stage prototype similarity baseline (e.g., direct matching to the complete set of learned prototypes in one forward pass). This comparison is required to establish that the progressive discrimination across granularity levels is load-bearing for the reported accuracy gains and the 'breaking the paradigm' assertion.
Authors: We agree that an explicit ablation isolating the contribution of the multi-stage progressive discrimination would strengthen the evidence for our central claim. In the revised manuscript we will add this comparison: a single-stage baseline that performs direct similarity matching against the full set of learned prototypes in one forward pass, evaluated on the same UCR and UEA benchmarks under identical training conditions. The results will be reported alongside the full PDFTime model to quantify the performance lift attributable to the staged sub-task structure. revision: yes
-
Referee: [Table 2] Table 2 and the UCR results paragraph report top-1 wins on 80/128 datasets but supply no information on the number of independent runs, random seeds, statistical significance tests (e.g., Wilcoxon or Friedman), or confirmation that the same train/test splits and baseline implementations from the UCR archive were used.
Authors: We acknowledge that the original submission omitted key reproducibility information. In the revision we will expand Section 4 and Table 2 to report: five independent runs with distinct random seeds (explicitly listed), results of Friedman and post-hoc Wilcoxon signed-rank tests with Holm correction, and explicit confirmation that all experiments followed the official UCR/UEA train/test splits and used the publicly released baseline codebases. These additions will be placed in a new reproducibility subsection. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes PDFTime as a new prototype-guided framework that reformulates TSC as a multi-stage similarity-based process instead of direct feature-to-label mapping. The abstract and provided text contain no equations, derivations, or mathematical steps that reduce to self-defined quantities or fitted inputs by construction. Performance claims rest on external benchmark results (top-1 on 80/128 UCR datasets) presented as empirical validation, not internal predictions forced by the method's own parameters. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the given material. The central reformulation is asserted as novel but is not shown to collapse into its own inputs; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Learned prototypes can approximate class-conditional feature distributions in the latent space sufficiently well to support progressive discrimination via sub-tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PDFTime leverages learned prototypes to approximate class-conditional feature distributions in the latent space, enabling progressive discrimination through classification sub-tasks of varying granularity.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-level prototype design... similarity-based inference over the encoded representations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The UEA multivariate time series classification archive, 2018
Bagnall, A., Dau, H. A., Lines, J., Flynn, M., Large, J., Bostrom, A., Southam, P., and Keogh, E. The uea mul- tivariate time series classification archive, 2018.arXiv preprint arXiv:1811.00075,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Chen, X., Qiu, P., Zhu, W., Li, H., Wang, H., Sotiras, A., Wang, Y ., and Razi, A. Timemil: Advancing multivariate time series classification via a time-aware multiple in- stance learning.arXiv preprint arXiv:2405.03140,
-
[3]
Chen, X., Zhu, W., Qiu, P., Wang, H., Li, H., Li, Z., Wang, Y ., Sotiras, A., and Razi, A. Fic-tsc: Learning time series classification with fisher information constraint.arXiv preprint arXiv:2505.06114,
-
[4]
Eldele, E., Ragab, M., Chen, Z., Wu, M., Kwoh, C. K., Li, X., and Guan, C. Time-series representation learning via temporal and contextual contrasting.arXiv preprint arXiv:2106.14112,
-
[5]
Eldele, E., Ragab, M., Chen, Z., Wu, M., and Li, X. Tslanet: Rethinking transformers for time series representation learning.arXiv preprint arXiv:2404.08472,
-
[6]
Ismail Fawaz, H., Lucas, B., Forestier, G., Pelletier, C., Schmidt, D. F., Weber, J., Webb, G. I., Idoumghar, L., Muller, P.-A., and Petitjean, F. Inceptiontime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 34(6):1936–1962,
work page 1936
-
[7]
Liu, Z., Luo, Y ., Li, B., Eldele, E., Wu, M., and Ma, Q. Learning soft sparse shapes for efficient time-series clas- sification.arXiv preprint arXiv:2505.06892, 2025b. Lu, Y ., Liu, D., Wang, Q., Han, C., Cui, Y ., Cao, Z., Zhang, X., Chen, Y . V ., and Fan, H. Promotion: Prototypes as motion learners. InProceedings of the IEEE/CVF Conference on Computer...
-
[8]
Middlehurst, M., Sch ¨afer, P., and Bagnall, A. Bake off redux: a review and experimental evaluation of recent time series classification algorithms.Data Mining and Knowledge Discovery, 38(4):1958–2031,
work page 1958
-
[9]
Na, Y ., Park, M., Tae, Y ., and Joo, S. Guiding masked repre- sentation learning to capture spatio-temporal relationship of electrocardiogram.arXiv preprint arXiv:2402.09450,
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y . A time series is worth 64words: Long-term forecast- ing with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Multivariate Time Series Classification with WEASEL+MUSE
Sch¨afer, P. and Leser, U. Multivariate time series classification with weasel+ muse.arXiv preprint arXiv:1711.11343,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Test: Text prototype aligned embedding to activate llm’s ability for time series
Sun, C., Li, H., Li, Y ., and Hong, S. Test: Text prototype aligned embedding to activate llm’s ability for time series. arXiv preprint arXiv:2308.08241,
-
[13]
Tang, W., Long, G., Liu, L., Zhou, T., Blumenstein, M., and Jiang, J. Omni-scale cnns: a simple and effective kernel size configuration for time series classification.arXiv preprint arXiv:2002.10061,
-
[14]
Woo, G., Liu, C., Sahoo, D., Kumar, A., and Hoi, S
10 Prototype-Guided Classification Sub-Task Decoupling Framework... Woo, G., Liu, C., Sahoo, D., Kumar, A., and Hoi, S. Cost: Contrastive learning of disentangled seasonal-trend rep- resentations for time series forecasting.arXiv preprint arXiv:2202.01575,
-
[15]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
Wu, H., Hu, T., Liu, Y ., Zhou, H., Wang, J., and Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
is one of the most comprehensive collections of univariate datasets for time series analysis. It encompasses 128 datasets spanning diverse domains such as healthcare, finance, and environmental monitoring. The variety within this archive provides a robust platform to evaluate the effectiveness and generalization of PDFTime. Notably, several datasets in th...
work page 2022
-
[17]
More details about the UEA and UCR datasets can be found in https://www.timeseriesclassification. com/. B. Fair Experimental Comparison To ensure a fair and reproducible comparison, we strictly follow the experimental protocols and implementation settings adopted in prior works whenever possible. For baseline methods whose official implementations and hyp...
work page 2022
-
[18]
No dataset-specific tuning is performed for any baseline method
For baseline models without publicly released hyperparameter configurations, we employ the default settings suggested in the corresponding papers or official codebases. No dataset-specific tuning is performed for any baseline method. For the proposed PDFTime framework, we adopt a unified set of hyperparameters across all datasets, as summarized in 12 Prot...
work page 1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.