Partial Fusion of Neural Networks: Efficient Tradeoffs Between Ensembles and Weight Aggregation
Pith reviewed 2026-05-22 06:54 UTC · model grok-4.3
The pith
Partial fusion of neural networks interpolates between ensembles and weight aggregation by selectively combining only the most similar neurons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
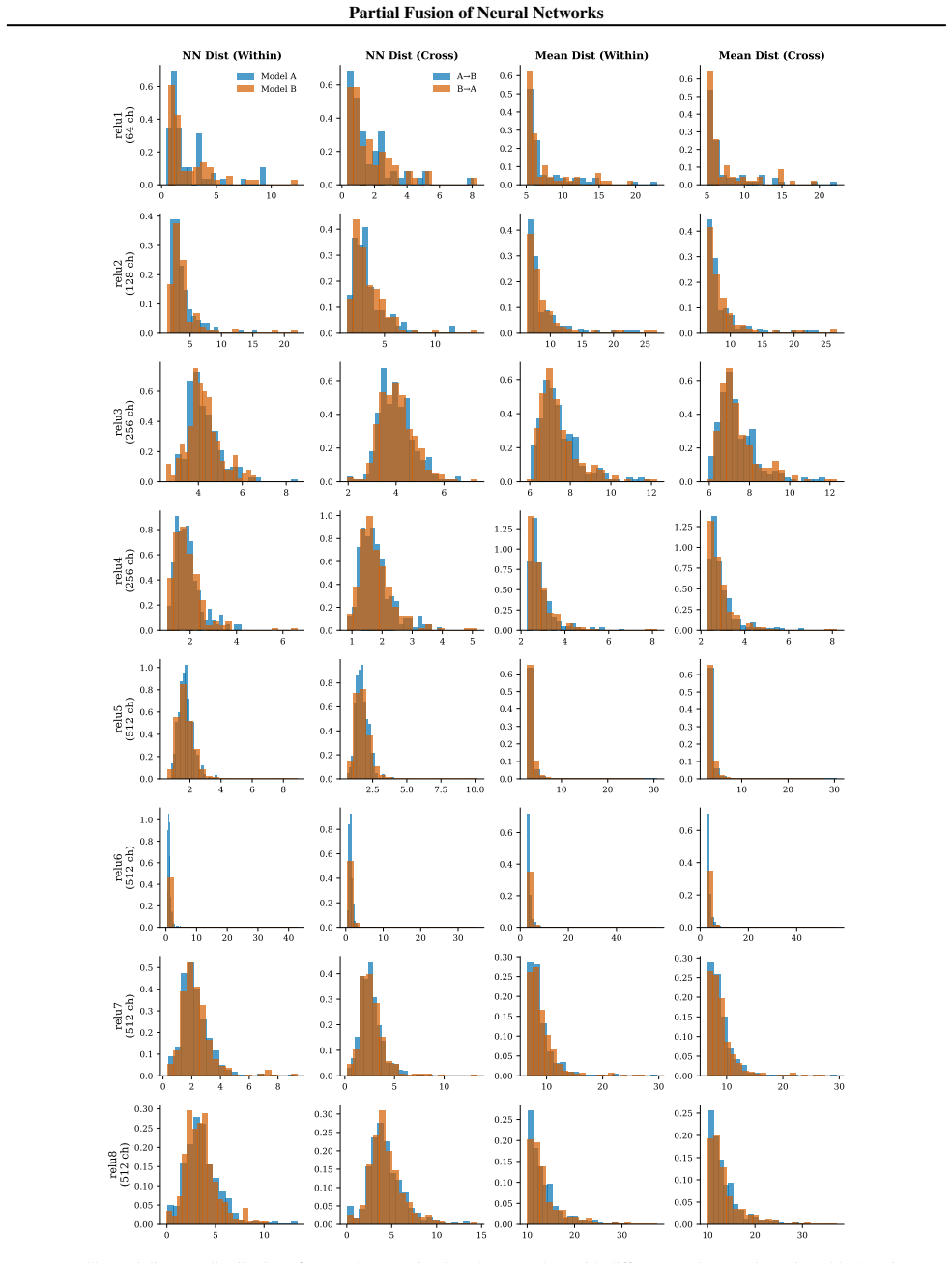
By extending existing neuron-level weight aggregation techniques with partial optimal transport, the authors show that only the most similar neurons need to be fused while dissimilar ones remain separate; the resulting partial-fusion models lie on a smooth performance-cost continuum between full ensembles and complete aggregates. The same principle reframes weight aggregation and partial fusion as generalized pruning of an ensemble, where neurons can be linearly combined rather than merely deleted, and the identical generalized-pruning view applied to a single network yields comparable trade-off benefits.
What carries the argument
Partial optimal transport that jointly identifies the most similar neurons across ensemble members and matches them for selective weight aggregation.
Load-bearing premise
Neuron-level similarity between independently trained networks can be measured reliably enough that selectively fusing only the closest neurons yields intermediate models without unexpected accuracy drops.
What would settle it
Running the partial-fusion procedure across a range of similarity thresholds and finding that the resulting models' accuracy either falls below the fully aggregated baseline or fails to improve smoothly toward the ensemble baseline would falsify the claimed continuum.
Figures
















read the original abstract
Ensembles of neural networks typically outperform individual networks but incur large computational costs, whereas weight aggregation produces less costly, yet also less accurate, aggregate models. We introduce partial fusion of networks, which interpolates between ensembles and weight aggregation and thus allows for a flexible tradeoff between computational cost and performance. A direct way to achieve this is to extend existing weight aggregation methods based on neuron-level similarity between different networks, where partial fusion then only aggregates weights of neurons which are most similar. We showcase one particular method to jointly identify which neurons are most similar and match them via partial optimal transport. Further, we consider the more general perspective of weight aggregation and partial fusion as generalized pruning of ensemble models, where neurons cannot just be deleted, but also linearly combined. Finally, we show that generalized pruning applied to a single network yields similar benefits as partial fusion by allowing for a tradeoff between isolating, deleting, and linearly combining neurons based on similarity. Our code is available at https://github.com/Fabian-Mor/partial_fusion_nn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce partial fusion of neural networks, which uses partial optimal transport to identify and aggregate only the most similar neurons across ensemble members. This interpolates between the high performance but high cost of full ensembles and the lower cost but reduced accuracy of weight aggregation, enabling tunable tradeoffs. The approach is also framed as generalized pruning (allowing deletion or linear combination of neurons) and is shown to yield similar benefits when applied to a single network.
Significance. If the method produces models whose accuracy and inference cost form a monotonic, useful continuum without unexpected degradations, it would provide a practical and flexible tool for model merging and pruning in deep learning. The open-sourced code and the generalized-pruning perspective are strengths that support reproducibility and connections to existing literature on neuron alignment and model compression.
major comments (2)
- [Method section describing partial optimal transport and neuron matching] The central tradeoff claim requires that partial OT matching on neuron weights/activations captures functionally interchangeable neurons rather than merely similar parameters; the manuscript does not detail regularization of the transport plan or validation against forward-pass equivalence, leaving open the risk of non-monotonic performance where intermediate fusion ratios exceed the error of both endpoints (as highlighted in the stress-test note).
- [Abstract and Experiments/Results] The abstract and visible description outline the approach and one implementation but report no quantitative results, error bars, ablation studies, or accuracy-vs-cost curves for varying fusion ratios or transport mass; this absence is load-bearing for verifying the claimed flexible tradeoff and the generalized-pruning benefits.
minor comments (2)
- [Abstract] The abstract could specify the architectures, datasets, and number of ensemble members used in the showcase to make the empirical claims more concrete.
- [Method] Notation for the similarity cutoff or transport mass parameter should be introduced with an explicit equation or definition to avoid ambiguity when describing the partial fusion procedure.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address the two major comments point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method section describing partial optimal transport and neuron matching] The central tradeoff claim requires that partial OT matching on neuron weights/activations captures functionally interchangeable neurons rather than merely similar parameters; the manuscript does not detail regularization of the transport plan or validation against forward-pass equivalence, leaving open the risk of non-monotonic performance where intermediate fusion ratios exceed the error of both endpoints (as highlighted in the stress-test note).
Authors: We agree that explicit regularization of the partial OT plan and direct validation of functional interchangeability would strengthen the central claim. In the revised manuscript we will add a dedicated subsection detailing the entropy regularization and mass penalty terms used in the partial OT objective, along with the specific solver parameters. We will also include new experiments that measure output equivalence (e.g., KL divergence between fused and original forward passes) for matched versus unmatched neurons. Regarding monotonicity, the stress-test note already reports that intermediate ratios do not exceed endpoint error on the evaluated models; we will expand this analysis with additional architectures and report the full curves to make the evidence more visible. revision: yes
-
Referee: [Abstract and Experiments/Results] The abstract and visible description outline the approach and one implementation but report no quantitative results, error bars, ablation studies, or accuracy-vs-cost curves for varying fusion ratios or transport mass; this absence is load-bearing for verifying the claimed flexible tradeoff and the generalized-pruning benefits.
Authors: The Experiments section already contains accuracy-versus-inference-cost curves for multiple fusion ratios and transport-mass values, together with error bars from five independent runs and ablations on similarity metrics (weight vs. activation). We will revise the abstract to include one or two key quantitative highlights (e.g., “at 50 % fusion we retain 98 % of ensemble accuracy at 60 % of the cost”) and will add a short table summarizing the generalized-pruning results on single networks. These changes make the empirical support immediately visible without altering the existing figures or tables. revision: partial
Circularity Check
No significant circularity in partial fusion derivation
full rationale
The paper proposes partial fusion as a new interpolation technique between ensembles and weight aggregation, implemented via partial optimal transport on neuron similarities. This builds directly on established concepts of weight aggregation and optimal transport without any self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central tradeoff claim to its own inputs by construction. The method is presented as an independent algorithmic contribution with explicit code release, and the generalized pruning perspective is framed as an extension rather than a renaming or ansatz smuggled from prior author work. No equations or performance claims in the provided text reduce to tautological equivalence with the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- similarity cutoff or transport mass parameter
axioms (1)
- domain assumption Neurons across different networks admit a well-defined similarity measure that correlates with functional equivalence.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We showcase one particular method to jointly identify which neurons are most similar and match them via partial optimal transport... partial fusion then only aggregates weights of neurons which are most similar.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
generalized pruning of ensemble models, where neurons cannot just be deleted, but also linearly combined
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Manifold Integrated Gradients:
Zaher, Eslam and Trzaskowski, Maciej and Nguyen, Quan and Roosta, Fred , booktitle =. Manifold Integrated Gradients:
-
[5]
Approximate Geodesics for Deep Generative Models , url =
Chen, Nutan , year =. Approximate Geodesics for Deep Generative Models , url =
-
[6]
Shao, Hang and Kumar, Abhishek and Fletcher, P. Thomas , booktitle =. The
-
[7]
International Conference on Artificial Neural Networks , pages =
Fast Approximate Geodesics for Deep Generative Models , author =. International Conference on Artificial Neural Networks , pages =. 2019 , publisher =
work page 2019
-
[8]
Advances in Neural Information Processing Systems , volume =
A Geometric Perspective on Variational Autoencoders , author =. Advances in Neural Information Processing Systems , volume =
-
[9]
International Conference on Learning Representations , year =
Wasserstein Auto-Encoders , author =. International Conference on Learning Representations , year =
-
[10]
Raghu, Maithra and Gilmer, Justin and Yosinski, Jason and Sohl-Dickstein, Jascha , booktitle =
-
[11]
Convergent Learning: Do different neural networks learn the same representations? , author =. Proceedings of the 1st International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015 , pages =. 2015 , volume =
work page 2015
-
[12]
Advances in Neural Information Processing Systems , volume =
Insights on Representational Similarity in Neural Networks with Canonical Correlation , author =. Advances in Neural Information Processing Systems , volume =
-
[13]
International Conference on Machine Learning , pages =
Similarity of Neural Network Representations Revisited , author =. International Conference on Machine Learning , pages =. 2019 , publisher =
work page 2019
-
[14]
Advances in Neural Information Processing Systems , volume =
Similarity and Matching of Neural Network Representations , author =. Advances in Neural Information Processing Systems , volume =
-
[15]
Advances in Neural Information Processing Systems , volume =
Model Fusion via Optimal Transport , author =. Advances in Neural Information Processing Systems , volume =
-
[16]
Advances in Neural Information Processing Systems , volume =
Deep Model Reassembly , author =. Advances in Neural Information Processing Systems , volume =
-
[17]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , url =
Bricken, Trenton and Templeton, Adly and Batson, Joshua and Chen, Brian and Jermyn, Adam and Conerly, Tom and Turner, Nick and Olah, Chris , year =. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , url =
-
[18]
International Conference on Artificial Intelligence and Statistics , pages =
Towards Optimal Transport with Global Invariances , author =. International Conference on Artificial Intelligence and Statistics , pages =. 2019 , publisher =
work page 2019
-
[19]
International Conference on Machine Learning , pages =
Harmony in Diversity: Merging Neural Networks with Canonical Correlation Analysis , author =. International Conference on Machine Learning , pages =. 2024 , publisher =
work page 2024
-
[20]
CMES - Computer Modeling in Engineering and Sciences , volume =
Lightweight Network Ensemble Architecture for Environmental Perception on the Autonomous System , author =. CMES - Computer Modeling in Engineering and Sciences , volume =
-
[21]
International Conference on Learning Representations , year =
Git Re-Basin: Merging Models Modulo Permutation Symmetries , author =. International Conference on Learning Representations , year =
-
[22]
arXiv preprint arXiv:2210.06671 , year =
Wasserstein Barycenter-based Model Fusion and Linear Mode Connectivity of Neural Networks , author =. arXiv preprint arXiv:2210.06671 , year =
-
[23]
International Conference on Artificial Intelligence and Statistics , pages=
Proving linear mode connectivity of neural networks via optimal transport , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[24]
Annual Meeting of the Association for Computational Linguistics , pages =
Merging Text Transformer Models from Different Initializations , author =. Annual Meeting of the Association for Computational Linguistics , pages =
-
[25]
International Conference on Learning Representations , year =
Editing Models with Task Arithmetic , author =. International Conference on Learning Representations , year =
-
[26]
Matena, Michael S and Raffel, Colin A , booktitle =. Merging Models with
-
[27]
Jordan, Keller and Sedghi, Hanie and Saukh, Olga and Entezari, Rahim and Neyshabur, Behnam , booktitle =
-
[28]
Stoica, George and Bolya, Daniel and Bjorner, Jakob and Ramesh, Pratik and Hearn, Taylor and Hoffman, Judy , booktitle =
-
[29]
International Conference on Learning Representations , year =
Transformer Fusion with Optimal Transport , author =. International Conference on Learning Representations , year =
-
[30]
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin and Bansal, Mohit , booktitle =
-
[31]
arXiv preprint arXiv:2507.00037 , year =
Model Fusion via Neuron Interpolation , author =. arXiv preprint arXiv:2507.00037 , year =
-
[32]
arXiv preprint arXiv:2503.21657 , year =
Model Assembly Learning with Heterogeneous Layer Weight Merging , author =. arXiv preprint arXiv:2503.21657 , year =
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Training-Free Pretrained Model Merging , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[34]
arXiv preprint arXiv:2501.00061 , year =
Training-Free Heterogeneous Model Merging , author =. arXiv preprint arXiv:2501.00061 , year =
-
[35]
IEEE International Conference on Acoustics, Speech and Signal Processing , pages =
On Cross-Layer Alignment for Model Fusion of Heterogeneous Neural Networks , author =. IEEE International Conference on Acoustics, Speech and Signal Processing , pages =
-
[36]
Bhatt, Aditya and Palenicek, Daniel and Belousov, Boris and Argus, Max and Amiranashvili, Artemij and Brox, Thomas and Peters, Jan , booktitle =
-
[37]
International Conference on Learning Representations , year =
Exploration by Random Network Distillation , author =. International Conference on Learning Representations , year =
-
[38]
International Conference on Learning Representations , year =
Pink Noise is All You Need: Colored Noise Exploration in Deep Reinforcement Learning , author =. International Conference on Learning Representations , year =
-
[39]
International Conference on Machine Learning , pages =
Addressing Function Approximation Error in Actor-Critic Methods , author =. International Conference on Machine Learning , pages =. 2018 , publisher =
work page 2018
-
[40]
International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. International Conference on Machine Learning , pages =. 2018 , publisher =
work page 2018
-
[41]
Soft Actor-Critic Algorithms and Applications
Soft Actor-Critic Algorithms and Applications , author =. arXiv preprint arXiv:1812.05905 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models , author =. arXiv preprint arXiv:2301.04104 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Hansen, Nicklas and Su, Hao and Wang, Xiaolong , booktitle =
-
[44]
AAAI Conference on Artificial Intelligence , pages =
Rainbow: Combining Improvements in Deep Reinforcement Learning , author =. AAAI Conference on Artificial Intelligence , pages =
-
[45]
International Conference on Learning Representations , year =
Continuous Control with Deep Reinforcement Learning , author =. International Conference on Learning Representations , year =
-
[46]
International Conference on Machine Learning , pages =
Dueling Network Architectures for Deep Reinforcement Learning , author =. International Conference on Machine Learning , pages =. 2016 , publisher =
work page 2016
-
[47]
Hiraoka, Takuya and Imagawa, Takahisa and Hashimoto, Taisei and Onishi, Takashi and Tsuruoka, Yoshimasa , booktitle =. Dropout
-
[48]
Chen, Xinyue and Wang, Che and Zhou, Zijian and Ross, Keith , booktitle =. Randomized Ensembled Double
-
[49]
AAAI Conference on Artificial Intelligence , pages =
Maximum Entropy Inverse Reinforcement Learning , author =. AAAI Conference on Artificial Intelligence , pages =
-
[50]
A Theoretical Analysis of Deep
Fan, Jianqing and Wang, Zhaoran and Xie, Yuchen and Yang, Zhuoran , booktitle =. A Theoretical Analysis of Deep. 2020 , publisher =
work page 2020
-
[51]
Conference on Learning Theory , pages =
Mean-Field Theory of Two-Layers Neural Networks: Dimension-Free Bounds and Kernel Limit , author =. Conference on Learning Theory , pages =. 2019 , publisher =
work page 2019
-
[52]
Proceedings of the National Academy of Sciences , volume =
A Mean Field View of the Landscape of Two-Layer Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =
-
[53]
Conference on Uncertainty in Artificial Intelligence , pages =
Averaging Weights Leads to Wider Optima and Better Generalization , author =. Conference on Uncertainty in Artificial Intelligence , pages =. 2018 , publisher =
work page 2018
-
[54]
Advances in Neural Information Processing Systems , volume =
Diverse Weight Averaging for Out-of-Distribution Generalization , author =. Advances in Neural Information Processing Systems , volume =
-
[55]
International Conference on Machine Learning , pages =
Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy without Increasing Inference Time , author =. International Conference on Machine Learning , pages =. 2022 , publisher =
work page 2022
-
[56]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Robust Fine-Tuning of Zero-Shot Models , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
- [57]
-
[58]
International Conference on Machine Learning , pages =
Do Deep Neural Network Solutions Form a Star Domain? , author =. International Conference on Machine Learning , pages =. 2024 , publisher =
work page 2024
-
[59]
International Conference on Machine Learning , pages =
Mechanistic Mode Connectivity , author =. International Conference on Machine Learning , pages =. 2023 , publisher =
work page 2023
-
[60]
International Conference on Learning Representations , year =
Linear Connectivity Reveals Generalization Strategies , author =. International Conference on Learning Representations , year =
-
[61]
International Conference on Machine Learning , pages =
Geometry of the Loss Landscape in Overparameterized Neural Networks: Symmetries and Invariances , author =. International Conference on Machine Learning , pages =. 2021 , publisher =
work page 2021
-
[62]
Advances in Neural Information Processing Systems , volume =
Input Space Mode Connectivity in Deep Neural Networks , author =. Advances in Neural Information Processing Systems , volume =
- [63]
-
[64]
International Conference on Machine Learning , pages =
Linear Mode Connectivity and the Lottery Ticket Hypothesis , author =. International Conference on Machine Learning , pages =. 2020 , publisher =
work page 2020
-
[65]
International Conference on Learning Representations , year =
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks , author =. International Conference on Learning Representations , year =
-
[66]
Garipov, Timur and Izmailov, Pavel and Podoprikhin, Dmitrii and Vetrov, Dmitry P. and Wilson, Andrew G. , booktitle =. Loss Surfaces, Mode Connectivity, and Fast Ensembling of
-
[67]
Advances in Neural Information Processing Systems , volume =
Visualizing the Loss Landscape of Neural Nets , author =. Advances in Neural Information Processing Systems , volume =
-
[68]
Advances in Neural Information Processing Systems , volume =
Large Scale Structure of Neural Network Loss Landscapes , author =. Advances in Neural Information Processing Systems , volume =
-
[69]
arXiv preprint arXiv:2506.22712 , year =
Generalized Linear Mode Connectivity for Transformers , author =. arXiv preprint arXiv:2506.22712 , year =
-
[70]
Daxberger, Erik and Kristiadi, Agustinus and Immer, Alexander and Eschenhagen, Runa and Bauer, Matthias and Hennig, Philipp , booktitle =. Laplace Redux -- Effortless
-
[71]
Archive for Rational Mechanics and Analysis , volume =
The Optimal Partial Transport Problem , author =. Archive for Rational Mechanics and Analysis , volume =. 2010 , publisher =
work page 2010
-
[72]
Proceedings of the IEEE , volume =
Gradient-Based Learning Applied to Document Recognition , author =. Proceedings of the IEEE , volume =
-
[73]
Learning Multiple Layers of Features from Tiny Images , author =
-
[74]
International Conference on Learning Representations , year =
Very Deep Convolutional Networks for Large-Scale Image Recognition , author =. International Conference on Learning Representations , year =
-
[75]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[76]
Journal of the American Statistical Association , volume =
Hierarchical Grouping to Optimize an Objective Function , author =. Journal of the American Statistical Association , volume =
- [77]
-
[78]
ACM Computing Surveys , volume =
Data Clustering: A Review , author =. ACM Computing Surveys , volume =
-
[79]
Lance, G. N. and Williams, W. T. , journal =. A General Theory of Classificatory Sorting Strategies: 1
-
[80]
Aloise, Daniel and Deshpande, Amit and Hansen, Pierre and Popat, Preyas , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.