"Refactoring Runaway": Understanding and Mitigating Tangled Refactorings in Coding Agents for Issue Resolution
Pith reviewed 2026-05-22 03:54 UTC · model grok-4.3
The pith
Coding agents introduce tangled refactorings less often than humans, but those they add reduce patch compilability; a targeted refinement step more than doubles the compilability rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
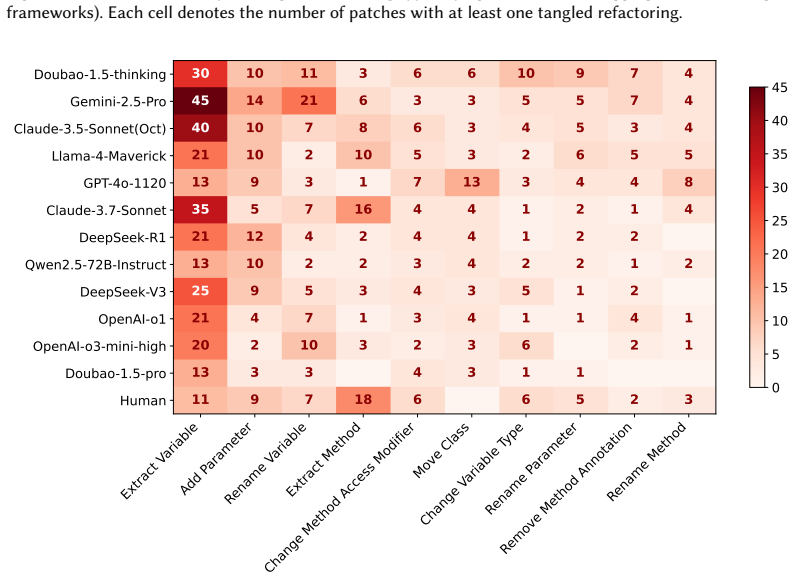
Tangled refactorings appear less frequently and with lower intensity in agent patches than in human ones, but they remain associated with sharply reduced compilability while showing no link to functional correctness. A refactoring-aware refinement approach that assesses necessity and safety of each tangled refactoring and then selectively removes or repairs the unsafe ones improves compilability from 19.34% to 38.33% and resolves 2.79% more issues.
What carries the argument
The refactoring-aware refinement approach, which identifies tangled refactorings in generated patches and judges their necessity and safety before deciding whether to remove or repair them.
If this is right
- Tangled refactorings reduce compilability of agent-generated patches.
- Agents display a wider range of refactoring types than human developers.
- The refinement step can be applied after any agent run to raise the share of compilable patches.
- Logistic regression shows the negative effect on compilability is independent of functional correctness.
Where Pith is reading between the lines
- Agents could be prompted or trained to limit refactoring to only what is required for the fix.
- The same necessity-and-safety check might help in other code-change tasks such as feature implementation.
- Training data drawn from open-source repositories may explain why agents still produce some tangled refactorings.
Load-bearing premise
That tangled refactorings found in agent patches can be judged for necessity and safety by the refinement method without missing important context or creating fresh problems.
What would settle it
Running the refinement on a new collection of agent patches and observing no rise in compilability or the appearance of new compilation errors.
Figures



read the original abstract
Recent advances in coding agents have shown remarkable progress in software issue resolution. In practice, real-world issues are typically bug fixes or feature requests in which human developers naturally incorporate refactoring as part of the resolution process, resulting in tangled refactoring. Since LLMs are trained on large-scale open-source repositories, coding agents may inherit such behaviors. In this paper, we conduct an empirical study on Multi-SWE-bench, analyzing 3,691 valid patches generated by three agent frameworks with 12 LLMs. We find that coding agents introduce tangled refactorings less frequently (21.43% vs. 36.72%) and with lower intensity (0.66 vs. 1.75) than human developers, although they exhibit a broader diversity of refactoring types. Logistic regression analysis further shows that tangled refactorings are strongly associated with reduced compilability, while exhibiting no significant association with functional correctness. Based on these findings, we propose a refactoring-aware refinement approach that assesses the necessity and safety of tangled refactorings and selectively removes or repairs problematic operations. Our approach improves compilability from 19.34% to 38.33%, and additionally resolves 2.79% previously unresolved issues. Overall, this work presents the first step towards understanding tangled refactoring practices in agentic issue resolution and opens up avenues for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study on 3,691 valid patches generated by three coding agent frameworks using 12 LLMs on the Multi-SWE-bench dataset. It reports that agents introduce tangled refactorings less frequently (21.43% vs. 36.72%) and with lower intensity (0.66 vs. 1.75) than human developers, though with broader diversity of refactoring types. Logistic regression shows tangled refactorings are strongly associated with reduced compilability but not with functional correctness. The authors propose an LLM-based refactoring-aware refinement approach to assess necessity and safety of tangled refactorings and selectively remove or repair them, claiming this raises compilability from 19.34% to 38.33% while resolving an additional 2.79% of previously unresolved issues.
Significance. If the refinement method can be shown to correctly distinguish necessary from unnecessary refactorings without discarding functional fixes or introducing new errors, the work supplies a concrete, deployable technique for improving the reliability of agent-generated patches in real issue-resolution workflows. The comparative statistics on agent versus human refactoring practices add to the growing literature on how LLM training corpora shape code-editing behavior. The study is a useful first step in characterizing side-effects of agentic code generation.
major comments (1)
- [Refinement approach section] Description of the refactoring-aware refinement approach: the necessity and safety assessment is described as LLM-based judgment performed on the patch. No explicit mechanism (prompt template, retrieval step, or rule set) is provided for incorporating the original issue description, failing test cases, or resolution intent. Because the reported compilability gain (19.34% → 38.33%) and the additional 2.79% resolutions rest directly on the correctness of these removals/repairs, the absence of grounding context is load-bearing and requires either a detailed prompt appendix or an ablation that measures functional regression after refinement.
minor comments (2)
- [Abstract and §3] The abstract states logistic regression results but supplies no model specification, variable list, or goodness-of-fit statistics; these details should appear in the main text or an appendix to support reproducibility.
- [Empirical study section] Table or figure reporting the 3,691-patch breakdown by framework and LLM is missing; adding it would allow readers to judge whether the frequency and intensity differences are driven by particular model families.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comment below and will incorporate the suggested clarifications and additional analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Refinement approach section] Description of the refactoring-aware refinement approach: the necessity and safety assessment is described as LLM-based judgment performed on the patch. No explicit mechanism (prompt template, retrieval step, or rule set) is provided for incorporating the original issue description, failing test cases, or resolution intent. Because the reported compilability gain (19.34% → 38.33%) and the additional 2.79% resolutions rest directly on the correctness of these removals/repairs, the absence of grounding context is load-bearing and requires either a detailed prompt appendix or an ablation that measures functional regression after refinement.
Authors: We agree that the current description of the refactoring-aware refinement approach is insufficiently detailed regarding the incorporation of grounding context. In the revised manuscript we will add the complete prompt template to an appendix. The template explicitly includes the original issue description, the failing test cases, and the resolution intent as part of the input provided to the LLM for necessity and safety assessment. We will also add an ablation study that reports functional correctness (pass rates on the original test suite) before and after refinement to confirm that the observed gains in compilability do not introduce regressions or discard functional fixes. revision: yes
Circularity Check
No significant circularity: empirical observational study with independent analysis
full rationale
The paper is an empirical study that analyzes 3,691 patches from coding agents on Multi-SWE-bench, applies logistic regression to report associations between tangled refactorings and compilability/functional correctness, and then proposes a refinement approach whose performance gains are measured directly on the data. No mathematical derivation chain, self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The logistic regression serves as standard statistical reporting of observed associations rather than a tautological reduction, and the reported improvements (19.34% to 38.33% compilability) are presented as empirical outcomes of the proposed method rather than forced by construction from the inputs. The work is self-contained against external benchmarks with no evident circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Logistic regression assumptions hold, including linearity of the logit and independence of observations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose RefUntangle, a refactoring-aware refinement approach that assesses the necessity and safety of tangled refactorings and selectively removes or repairs problematic operations.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Logistic regression analysis further shows that tangled refactorings are strongly associated with reduced compilability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pouria Alikhanifard and Nikolaos Tsantalis. 2025. A Novel Refactoring and Semantic Aware Abstract Syntax Tree Differencing Tool and a Benchmark for Evaluating the Accuracy of Diff Tools.ACM Transactions on Software Engineering and Methodology34, 2, Article 40 (Jan. 2025), 63 pages. doi:10.1145/3696002
-
[2]
Amirreza Bagheri and Péter Hegedüs. 2022. Is refactoring always a good egg? exploring the interconnection between bugs and refactorings. InProceedings of the 19th International Conference on Mining Software Repositories(Pittsburgh, J. ACM, Vol. 1, No. 1, Article 1. Publication date: March 2026. 1:26 Zhao Tian, Zifan Zhang, Tao Xiao, Dong Wang, Masanari Ko...
-
[3]
Gabriele Bavota, Bernardino De Carluccio, Andrea De Lucia, Massimiliano Di Penta, Rocco Oliveto, and Orazio Strollo
-
[4]
When Does a Refactoring Induce Bugs? An Empirical Study. InProceedings of the 2012 IEEE 12th International Working Conference on Source Code Analysis and Manipulation (SCAM ’12). IEEE Computer Society, USA, 104–113. doi:10.1109/SCAM.2012.20
-
[5]
Dennis Bijlsma, Miguel Alexandre Ferreira, Bart Luijten, and Joost Visser. 2012. Faster issue resolution with higher technical quality of software.Software quality journal20, 2 (2012), 265–285
work page 2012
- [6]
-
[7]
Zhi Chen and Lingxiao Jiang. 2025. Evaluating software development agents: Patch patterns, code quality, and issue complexity in real-world github scenarios. In2025 IEEE international conference on software analysis, evolution and reengineering (SANER). IEEE, 657–668
work page 2025
-
[8]
Zhi Chen, Wei Ma, and Lingxiao Jiang. 2026. Beyond Final Code: A Process-Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios. InProceedings of the IEEE/ACM 48th International Conference on Software Engineering
work page 2026
-
[9]
Steve Counsell, Vesna Nowack, Tracy Hall, David Bowes, Saemundur Haraldsson, Emily Winter, and John Woodward
-
[10]
In2022 48th Euromicro Conference on Software Engineering and Advanced Applications (SEAA)
An 80-20 Analysis of Buggy and Non-buggy Refactorings in Open-Source Commits. In2022 48th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 197–200. doi:10.1109/SEAA56994.2022.00038
-
[11]
Massimiliano Di Penta, Gabriele Bavota, and Fiorella Zampetti. 2020. On the relationship between refactoring actions and bugs: a differentiated replication. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Virtual Event, USA)(ESEC/FSE 2020). Association for Com...
-
[12]
Martín Dias, Alberto Bacchelli, Georgios Gousios, Damien Cassou, and Stéphane Ducasse. 2015. Untangling fine- grained code changes. In2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER). 341–350. doi:10.1109/SANER.2015.7081844
-
[13]
Isabella Ferreira, Eduardo Fernandes, Diego Cedrim, Anderson Uchôa, Ana Carla Bibiano, Alessandro Garcia, João Lu- cas Correia, Filipe Santos, Gabriel Nunes, Caio Barbosa, Baldoino Fonseca, and Rafael de Mello. 2018. The buggy side of code refactoring: understanding the relationship between refactorings and bugs. InProceedings of the 40th International Co...
-
[14]
2018.Refactoring: improving the design of existing code
Martin Fowler. 2018.Refactoring: improving the design of existing code. Addison-Wesley Professional
work page 2018
- [15]
-
[16]
Yuan Gao, Hui Liu, Xiaozhong Fan, Zhendong Niu, and Bridget Nyirongo. 2015. Analyzing Refactorings’ Impact on Regression Test Cases. InProceedings of the 2015 IEEE 39th Annual Computer Software and Applications Conference - Volume 02 (COMPSAC ’15). IEEE Computer Society, USA, 222–231. doi:10.1109/COMPSAC.2015.16
-
[17]
Ahmed E Hassan. 2009. Predicting faults using the complexity of code changes. In2009 IEEE 31st international conference on software engineering. IEEE, 78–88
work page 2009
-
[18]
Steffen Herbold, Alexander Trautsch, Benjamin Ledel, Alireza Aghamohammadi, Taher A. Ghaleb, Kuljit Kaur Chahal, Tim Bossenmaier, Bhaveet Nagaria, Philip Makedonski, Matin Nili Ahmadabadi, Kristof Szabados, Helge Spieker, Matej Madeja, Nathaniel Hoy, Valentina Lenarduzzi, Shangwen Wang, Gema Rodríguez-Pérez, Ricardo Colomo- Palacios, Roberto Verdecchia, P...
-
[19]
Kim Herzig and Andreas Zeller. 2013. The impact of tangled code changes. InProceedings of the 10th Working Conference on Mining Software Repositories(San Francisco, CA, USA)(MSR ’13). IEEE Press, 121–130
work page 2013
- [20]
-
[21]
2013.Applied logistic regression
David W Hosmer Jr, Stanley Lemeshow, and Rodney X Sturdivant. 2013.Applied logistic regression. John Wiley & Sons
work page 2013
-
[22]
Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2014.An Introduction to Statistical Learning: with Applications in R. Springer Publishing Company, Incorporated. J. ACM, Vol. 1, No. 1, Article 1. Publication date: March 2026. “Refactoring Runaway”: Understanding and Mitigating Tangled Refactorings in Coding Agents for Issue Resolution 1:27
work page 2014
- [23]
-
[24]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
work page 2024
- [25]
-
[26]
Yutaro Kashiwa, Kazuki Shimizu, Bin Lin, Gabriele Bavota, Michele Lanza, Yasutaka Kamei, and Naoyasu Ubayashi
-
[27]
In2021 IEEE International Conference on Software Maintenance and Evolution (ICSME)
Does Refactoring Break Tests and to What Extent?. In2021 IEEE International Conference on Software Maintenance and Evolution (ICSME). 171–182. doi:10.1109/ICSME52107.2021.00022
-
[28]
Jong Hae Kim. 2019. Multicollinearity and misleading statistical results.Korean journal of anesthesiology72, 6 (2019), 558–569
work page 2019
-
[29]
Hiroyuki Kirinuki, Yoshiki Higo, Keisuke Hotta, and Shinji Kusumoto. 2014. Hey! are you committing tangled changes?. InProceedings of the 22nd International Conference on Program Comprehension(Hyderabad, India)(ICPC 2014). Association for Computing Machinery, New York, NY, USA, 262–265. doi:10.1145/2597008.2597798
-
[30]
Zengyang Li, Guangzong Cai, Qinyi Yu, Peng Liang, Ran Mo, and Hui Liu. 2024. Bug priority change: An empirical study on Apache projects.Journal of Systems and Software212 (2024), 112019
work page 2024
-
[31]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.ACM Comput. Surv.55, 9, Article 195 (Jan. 2023), 35 pages. doi:10.1145/3560815
-
[32]
Mehran Mahmoudi, Sarah Nadi, and Nikolaos Tsantalis. 2019. Are Refactorings to Blame? An Empirical Study of Refactorings in Merge Conflicts. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). 151–162. doi:10.1109/SANER.2019.8668012
-
[33]
Matias Martinez and Xavier Franch. 2026. What’s in a Benchmark? The Case of SWE-Bench in Automated Program Repair. InProceedings of the 48th International Conference on Software Engineering: Software Engineering in Practice. IEEE
work page 2026
-
[34]
Davood Mazinanian, Ameya Ketkar, Nikolaos Tsantalis, and Danny Dig. 2017. Understanding the use of lambda expressions in Java.Proc. ACM Program. Lang.1, OOPSLA, Article 85 (Oct. 2017), 31 pages. doi:10.1145/3133909
- [35]
-
[36]
Nachiappan Nagappan and Thomas Ball. 2005. Use of relative code churn measures to predict system defect density. InProceedings of the 27th international conference on Software engineering. 284–292
work page 2005
-
[37]
Stas Negara, Nicholas Chen, Mohsen Vakilian, Ralph E Johnson, and Danny Dig. 2013. A comparative study of manual and automated refactorings. InEuropean Conference on Object-Oriented Programming. Springer, 552–576
work page 2013
-
[38]
Feifei Niu, Junqian Shao, Christoph Mayr-Dorn, Liguo Huang, KG Wesley Assunção, Chuanyi Li, Jidong Ge, and Alexander Egyed. 2025. Refactoring ≠ bug-inducing: Improving defect prediction with code change tactics analysis. In 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 527–538
work page 2025
- [39]
- [40]
-
[41]
Anthony Peruma, Mohamed Wiem Mkaouer, Michael J. Decker, and Christian D. Newman. 2018. An empirical investigation of how and why developers rename identifiers. InProceedings of the 2nd International Workshop on Refactoring(Montpellier, France)(IWoR 2018). Association for Computing Machinery, New York, NY, USA, 26–33. doi:10.1145/3242163.3242169
- [42]
-
[43]
Danilo Silva, João Paulo da Silva, Gustavo Santos, Ricardo Terra, and Marco Tulio Valente. 2021. RefDiff 2.0: A Multi-Language Refactoring Detection Tool.IEEE Transactions on Software Engineering47, 12 (2021), 2786–2802. doi:10.1109/TSE.2020.2968072
-
[44]
Xin Sun, Daniel Ståhl, Kristian Sandahl, and Christoph Kessler. 2025. Quality Assurance of LLM-generated Code: Addressing Non-Functional Quality Characteristics.arXiv preprint arXiv:2511.10271(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Wei Tao, Yucheng Zhou, Yanlin Wang, Wenqiang Zhang, Hongyu Zhang, and Yu Cheng. 2024. MAGIS: LLM-based multi-agent framework for GitHub issue ReSolution. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Article J. ACM, Vol. 1, No. 1, Art...
work page 2024
-
[46]
Yida Tao and Sunghun Kim. 2015. Partitioning composite code changes to facilitate code review. InProceedings of the 12th Working Conference on Mining Software Repositories(Florence, Italy)(MSR ’15). IEEE Press, 180–190
work page 2015
-
[47]
Zhao Tian, Zifan Zhang, Tao Xiao, Dong Wang, Manasanari Kondo, Junjie Chen, and Kamei Yasutaka. [n. d.]. Research artifact – "Refactoring Runaway": Understanding and Mitigating Tangled Refactorings in Coding Agents for Issue Resolution. https://github.com/zifan-zhang/llm-refactoring-research [Online; accessed 2026-05-21]
work page 2026
-
[48]
Nikolaos Tsantalis, Ameya Ketkar, and Danny Dig. 2022. RefactoringMiner 2.0.IEEE Transactions on Software Engineering48, 3 (2022), 930–950. doi:10.1109/TSE.2020.3007722
-
[49]
Dong Wang, Hanmo You, Lingwei Zhu, Kaiwei Lin, Zheng Chen, Chen Yang, Junji Yu, Zan Wang, and Junjie Chen
- [50]
-
[51]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
work page 2025
-
[52]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[53]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, ...
work page 2024
-
[54]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. 2025. SWE-smith: Scaling Data for Software Engineering Agents. arXiv:2504.21798 [cs.SE] https://arxiv.org/abs/2504.21798
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv:2504.02605 [cs.SE] https://arxiv.org/abs/2504.02605
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. AutoCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1592–1604. doi:10.1145/ 3650212.3680384 J. ACM, Vol. 1, No...
-
[57]
Correctness first: the fix must resolve the reported issue
-
[58]
Minimize change scope: avoid unnecessary modifications
-
[59]
Refactoring discipline: keep only refactorings that directly support the fix or are tightly coupled to it
-
[60]
Maintain backward compatibility: do not introduce breaking changes to public APIs unless absolutely necessary
-
[61]
A.2 Component 1: Refactoring Assessment
Preserve test interfaces: avoid changes that break existing test contracts Note: Output format requirements are specified in the phase-specific system prompts. A.2 Component 1: Refactoring Assessment
-
[62]
Component-specific system prompt template: You are a senior Java engineer specializing in patch analysis and refactoring evaluation. Your goal is to assess each refactoring detected in a bug-fix patch and recommend appropriate actions. Evaluation Dimensions:
-
[63]
**Necessity** - Is this refactoring necessary for the fix to work? - NECESSARY: The fix cannot work without this refactoring (e.g., must add parameter to pass critical data) - UNNECESSARY: The refactoring is cosmetic cleanup unrelated to the fix
-
[64]
**Safety** - Is the refactoring implementation correct? - SAFE: The refactoring is correctly implemented with no issues * All API changes are consistently applied across all call sites * Type signatures are compatible or properly updated * Behavior is preserved (same logic, proper wiring, equivalent control flow) - UNSAFE: The refactoring has implementati...
work page 2026
-
[65]
**Recommended Action** - What should be done with this refactoring? - KEEP: Necessary + safe -> keep as-is - REMOVE: Unnecessary (even if safe) -> remove entirely to minimize patch - FIX: Necessary but unsafe -> fix the safety issues while preserving functionality Decision Process: For EACH detected refactoring, evaluate: a. Locate the exact diff hunks th...
work page 2026
-
[66]
Case-specific user prompt template: You will be provided with an issue description, optional code context, the candidate patch diff, and a list of detected refactorings. <issue> {issue_description} </issue> <code> {code_sections} </code> <patch> {patch_diff} </patch> <detected_refactorings> J. ACM, Vol. 1, No. 1, Article 1. Publication date: March 2026. 1...
work page 2026
-
[67]
Locate the corresponding diff hunks (cite file names and line numbers) b
For EACH refactoring in the list above: a. Locate the corresponding diff hunks (cite file names and line numbers) b. Assess NECESSITY: Is it necessary/unnecessary for the bug fix? c. Check SAFETY: Are there any implementation issues? - Missing call site updates? - Type incompatibilities? - Behavior changes? d. If unsafe, list specific safety issues e. Rec...
-
[68]
Provide overall assessment: - "overall_verdict": "all_safe" (all are safe and necessary) | "has_issues" (some need action) | "uncertain" - "actions_needed": Count how many refactorings need each action type
-
[69]
Be OBJECTIVE: - Necessary refactorings with implementation issues should be marked for FIX , not REMOVE - Unnecessary refactorings should be marked for REMOVE, even if they are safe - Focus on minimizing the patch while preserving the fix functionality - Keep reasoning consistent with safety/action (no contradictions) - If a refactoring is fully supported...
-
[70]
Component-specific system prompt template: You are a senior Java engineer tasked with refining a bug-fix patch. Your goal is to apply the specified actions to each refactoring while keeping the core bug fix intact. J. ACM, Vol. 1, No. 1, Article 1. Publication date: March 2026. “Refactoring Runaway”: Understanding and Mitigating Tangled Refactorings in Co...
work page 2026
-
[71]
**Preserve the bug fix**: The primary fix must remain functional after refinement
-
[72]
**Apply actions precisely**: - KEEP: Leave the refactoring changes as-is - REMOVE: Revert only the refactoring-related changes, preserving the bug fix - FIX: Apply the fix_suggestion to make the refactoring safe
-
[73]
**Minimize changes**: Only modify what is necessary to apply the actions
-
[74]
**Maintain compilability**: Ensure the refined patch will compile successfully Output requirements: - Output ONLY a unified diff for the refined patch - Use standard Git diff format with the following structure: * diff --git a/path b/path * (optional) index line * --- a/path * +++ b/path * @@ ... @@ hunks - Each file change must include at minimum: diff -...
-
[75]
Case-specific user prompt template: You will be given:
-
[76]
The original patch diff
-
[77]
remove": revert the refactoring-related changes while preserving the bug fix - If action is
A list of refactoring assessments with recommended actions <patch> {patch_diff} </patch> <assessments> {refactoring_assessments} </assessments> Apply the recommended actions: For each refactoring assessment: - If action is "keep": leave those changes unchanged J. ACM, Vol. 1, No. 1, Article 1. Publication date: March 2026. 1:34 Zhao Tian, Zifan Zhang, Tao...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.