Proxy-Based Approximation of Shapley and Banzhaf Interactions
Pith reviewed 2026-05-22 07:12 UTC · model grok-4.3
The pith
ProxySHAP approximates Shapley and Banzhaf interactions more accurately by using tree-based proxies plus residual correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
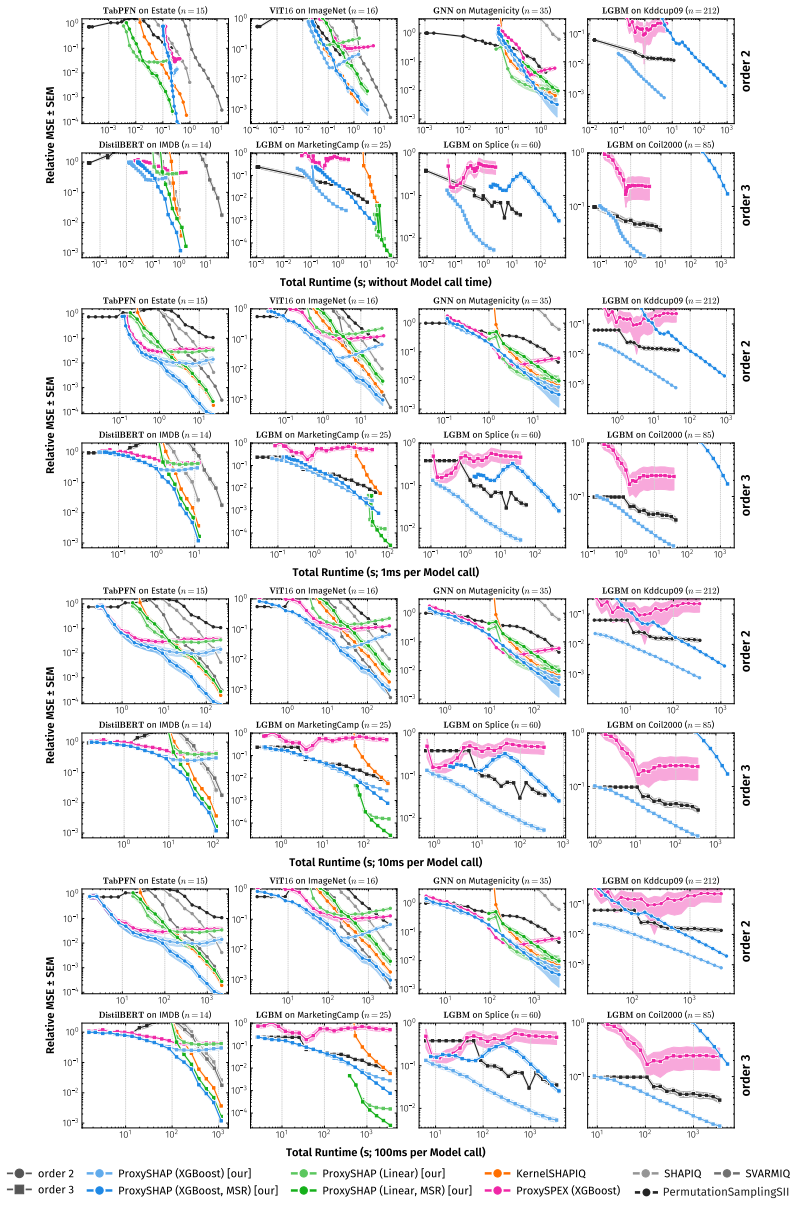
ProxySHAP reconciles the high sample efficiency of tree-based proxy models with a principled path to consistency via residual correction. On a theoretical level, it derives a polynomial-time generalization of interventional TreeSHAP to compute exact interaction indices for tree ensembles, successfully bypassing exponential tree-depth dependencies in prior methods. The residual adjustment strategy is shown to correct proxy bias under conditions where Maximum Sample Reuse keeps variance from scaling exponentially with interaction size.
What carries the argument
Residual adjustment via Maximum Sample Reuse applied to tree-based proxy models, which corrects bias while controlling variance growth and enables a polynomial-time exact TreeSHAP generalization for interactions.
If this is right
- ProxySHAP records the lowest approximation error among tested estimators in both small- and large-budget regimes.
- The method scales to applications with thousands of features while still outperforming ProxySPEX and KernelSHAP-IQ.
- Downstream explainability tasks such as interaction-based feature selection improve when using the new estimates.
- Exact interaction indices for tree ensembles become computable in polynomial time rather than exponential time in tree depth.
Where Pith is reading between the lines
- The same proxy-plus-residual pattern could be tested on non-tree models such as neural networks by substituting appropriate fast proxies.
- If the variance-control property generalizes, interaction-based fairness audits become feasible for high-dimensional tabular data.
- The polynomial-time TreeSHAP generalization might be adapted to compute other cooperative-game values beyond Shapley and Banzhaf.
Load-bearing premise
The residual adjustment strategy corrects proxy bias without its variance scaling exponentially with interaction size under the specific conditions that hold for the models and datasets evaluated in the paper.
What would settle it
An experiment on one of the paper's large-feature datasets in which the empirical variance of the residual-corrected estimator grows exponentially with interaction order instead of remaining controlled.
Figures


















read the original abstract
Shapley and Banzhaf interactions capture the complex dynamics inherent in modern machine learning applications. However, current estimators for these higher-order interactions trade off between speed and accuracy. To overcome this limitation, we introduce ProxySHAP. ProxySHAP reconciles the high sample efficiency of tree-based proxy models with a principled path to consistency via residual correction. On a theoretical level, we derive a polynomial-time generalization of interventional TreeSHAP to compute exact interaction indices for tree ensembles, successfully bypassing exponential tree-depth dependencies in prior methods. Furthermore, we formally analyze the residual adjustment strategy, characterizing the specific conditions under which Maximum Sample Reuse (MSR) corrects proxy bias without its variance scaling exponentially with interaction size. Extensive benchmarking demonstrates that ProxySHAP sets a new state-of-the-art standard for approximation quality, including in large-scale applications with thousands of features. By achieving the lowest error in both small- and large-budget regimes, ProxySHAP significantly outperforms the prior best estimators ProxySPEX and KernelSHAP-IQ, while also delivering superior performance on downstream explainability tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProxySHAP for approximating Shapley and Banzhaf interactions. It combines tree-based proxy models for sample efficiency with a residual correction strategy (Maximum Sample Reuse, MSR) claimed to ensure consistency. A key theoretical contribution is a polynomial-time generalization of interventional TreeSHAP that computes exact interaction indices for tree ensembles while avoiding exponential dependence on tree depth. The authors formally analyze the residual adjustment, characterizing conditions under which MSR corrects proxy bias without variance scaling exponentially in interaction order. Extensive benchmarks on small- and large-budget regimes, including datasets with thousands of features, show ProxySHAP achieving lower error than ProxySPEX and KernelSHAP-IQ and better performance on downstream explainability tasks.
Significance. If the formal characterization of MSR conditions holds and the empirical superiority is robust across diverse models and high-dimensional regimes, ProxySHAP would advance scalable higher-order interaction estimation, which is relevant for interpretability in modern ML. The polynomial-time TreeSHAP generalization for exact indices on ensembles is a clear technical strength that could be adopted independently.
major comments (1)
- [Theoretical analysis of residual adjustment / MSR] The formal analysis of the residual adjustment strategy (abstract and corresponding theoretical section) is load-bearing for the central SOTA claim in large-scale settings. The characterization of conditions under which MSR corrects proxy bias without variance scaling exponentially with interaction size must be stated explicitly, including any assumptions on proxy fidelity, feature correlations, or bounded higher-order effects. Without these details or a concrete verification that the conditions hold for models with thousands of features, the superiority over ProxySPEX and KernelSHAP-IQ in both budget regimes cannot be fully assessed.
minor comments (1)
- [Abstract and § on TreeSHAP generalization] The abstract claims 'polynomial-time' and 'exact' indices; ensure the complexity statement and any remaining exponential factors (e.g., in interaction order k) are clarified with precise big-O notation in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address the major comment below and have revised the paper to strengthen the explicit presentation of our theoretical results on the residual adjustment strategy.
read point-by-point responses
-
Referee: The formal analysis of the residual adjustment strategy (abstract and corresponding theoretical section) is load-bearing for the central SOTA claim in large-scale settings. The characterization of conditions under which MSR corrects proxy bias without variance scaling exponentially with interaction size must be stated explicitly, including any assumptions on proxy fidelity, feature correlations, or bounded higher-order effects. Without these details or a concrete verification that the conditions hold for models with thousands of features, the superiority over ProxySPEX and KernelSHAP-IQ in both budget regimes cannot be fully assessed.
Authors: We thank the referee for highlighting the need for greater explicitness in our theoretical characterization, which is indeed central to supporting the large-scale claims. Section 4 of the manuscript already derives the conditions under which MSR achieves bias correction without exponential variance growth in interaction order, but we agree that a more enumerated presentation will improve clarity and allow better assessment of the SOTA results. In the revision, we will add a dedicated paragraph and a formal theorem statement that explicitly lists the assumptions: (1) proxy fidelity, requiring the tree proxy to approximate the target function with L2 error bounded by a small constant (empirically verified via validation MSE in our training procedure); (2) bounded higher-order effects, with the remainder term controlled by a factor independent of order k; and (3) feature correlations handled through the standard interventional distribution used in TreeSHAP computations, without additional restrictions. We will also include a brief verification discussion referencing our large-scale experiments (Section 5.3) on datasets with thousands of features, where observed error rates and lack of variance explosion align with the derived bounds, confirming the conditions hold for the evaluated models. These changes directly address the request and will be incorporated in the revised manuscript. revision: yes
Circularity Check
Derivation chain is self-contained with independent theoretical contributions.
full rationale
The paper introduces ProxySHAP by deriving a polynomial-time generalization of interventional TreeSHAP for exact interaction indices on tree ensembles and by formally characterizing conditions under which MSR residual correction removes proxy bias without exponential variance scaling in interaction order. These steps are presented as new theoretical results. Benchmarking comparisons to ProxySPEX and KernelSHAP-IQ are empirical and separate from the derivations. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citation chains appear in the abstract or described claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- Proxy model hyperparameters
axioms (1)
- domain assumption Tree-based models can serve as sufficiently accurate proxies for the target black-box model
Reference graph
Works this paper leans on
-
[1]
Efficient and Accurate Explanation Estimation with Distribution Compression
Hubert Baniecki, Giuseppe Casalicchio, Bernd Bischl, and Przemyslaw Biecek. Efficient and Accurate Explanation Estimation with Distribution Compression. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[2]
Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions
Hubert Baniecki, Maximilian Muschalik, Fabian Fumagalli, Barbara Hammer, Eyke Hüller- meier, and Przemyslaw Biecek. Explaining Similarity in Vision-Language Encoders with Weighted Banzhaf Interactions. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[3]
Weighted voting doesn’t work: A mathematical analysis.Rutgers Law Review, 19:317, 1964
John F Banzhaf III. Weighted voting doesn’t work: A mathematical analysis.Rutgers Law Review, 19:317, 1964
work page 1964
-
[4]
Proxy-SPEX: Sample-efficient interpretability via sparse feature interactions in LLMs
Landon Butler, Abhineet Agarwal, Justin Singh Kang, Yigit Efe Erginbas, Bin Yu, and Kannan Ramchandran. Proxy-SPEX: Sample-efficient interpretability via sparse feature interactions in LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[5]
Yu-Xuan Cai, Hai-Yan Chen, Ya-Jing Qu, Wen-Hao Zhao, Mei-Ying Wang, Ying Chen, and Jin Ma. Improved vertical distribution prediction of soil vocs contamination in site-scale utilizing ensemble machine learning approach integrated with molecular descriptors.Journal of Hazardous Materials, page 139452, 2025
work page 2025
-
[6]
Quantum cryptography: Public key distribution and coin tossing,
Javier Castro, Daniel Gómez, and Juan Tejada. Polynomial calculation of the Shapley value based on sampling.Computers & Operations Research, 36(5):1726–1730, 2009. doi: 10.1016/j. cor.2008.04.004
work page doi:10.1016/j 2009
-
[7]
Javier Castro, Daniel Gómez, Elisenda Molina, and Juan Tejada. Improving polynomial estima- tion of the Shapley value by stratified random sampling with optimum allocation.Computers & Operations Research, 82:180–188, 2017. doi: 10.1016/j.cor.2017.01.019
-
[8]
Xgboost: A scalable tree boosting system,
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 785–794. ACM, 2016. doi: 10.1145/2939672.2939785
-
[9]
Improving KernelSHAP: Practical Shapley Value Estimation Using Linear Regression
Ian Covert and Su-In Lee. Improving KernelSHAP: Practical Shapley Value Estimation Using Linear Regression. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 3457–3465, 2021
work page 2021
-
[10]
Stochastic amortization: A unified approach to accelerate feature and data attribution
Ian Connick Covert, Chanwoo Kim, Su-In Lee, James Zou, and Tatsunori Hashimoto. Stochastic amortization: A unified approach to accelerate feature and data attribution. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InProceedings of the International Conference on Learning Representation...
work page 2021
-
[12]
InstaSHAP: Interpretable additive models explain shapley values instantly
James Enouen and Yan Liu. InstaSHAP: Interpretable additive models explain shapley values instantly. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[13]
Tabarena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), 2026
work page 2026
-
[14]
Katsushige Fujimoto, Ivan Kojadinovic, and Jean-Luc Marichal. Axiomatic characterizations of probabilistic and cardinal-probabilistic interaction indices.Games and Economic Behavior, 55(1):72–99, 2006. doi: 10.1016/j.geb.2005.03.002
-
[15]
SHAP-IQ: Unified Approximation of any-order Shapley Interactions
Fabian Fumagalli, Maximilian Muschalik, Patrick Kolpaczki, Eyke Hüllermeier, and Barbara Hammer. SHAP-IQ: Unified Approximation of any-order Shapley Interactions. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), pages 11515–11551, 2023
work page 2023
-
[16]
KernelSHAP-IQ: Weighted Least Square Optimization for Shapley Interactions
Fabian Fumagalli, Maximilian Muschalik, Patrick Kolpaczki, Eyke Hüllermeier, and Barbara Hammer. KernelSHAP-IQ: Weighted Least Square Optimization for Shapley Interactions. In Proceedings of the International Conference on Machine Learning (ICML), pages 14308–14342, 2024
work page 2024
-
[17]
Unifying Feature-Based Explanations with Functional ANOV A and Cooperative Game Theory
Fabian Fumagalli, Maximilian Muschalik, Eyke Hüllermeier, Barbara Hammer, and Julia Herbinger. Unifying Feature-Based Explanations with Functional ANOV A and Cooperative Game Theory. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 5140–5148, 2025
work page 2025
-
[18]
SHAP values via sparse fourier repre- sentation
Ali Gorji, Andisheh Amrollahi, and Andreas Krause. SHAP values via sparse fourier repre- sentation. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[19]
Michel Grabisch and Marc Roubens. An axiomatic approach to the concept of interaction among players in cooperative games.International Journal of Game Theory, 28(4):547–565,
-
[20]
doi: 10.1007/s001820050125
-
[21]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablon- ski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schö...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[22]
Naofumi Hama, Masayoshi Mase, and Art B. Owen. Deletion and insertion tests in regression models.Journal of Machine Learning Research, 24:290:1–290:38, 2023
work page 2023
-
[23]
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American Statistical Association, 58:13–30, 1963
work page 1963
-
[24]
Accurate predictions on small data with a tabular foundation model,
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tab- ular foundation model.Nature, 637(8045):319–326, 2025. doi: 10.1038/s41586-024-08328-6
-
[25]
Fast- SHAP: Real-Time Shapley Value Estimation
Neil Jethani, Mukund Sudarshan, Ian Connick Covert, Su-In Lee, and Rajesh Ranganath. Fast- SHAP: Real-Time Shapley Value Estimation. InProceedings of the International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[26]
Ruoxi Jia, David Dao, Boxin Wang, Frances Ann Hubis, Nick Hynes, Nezihe Merve Gürel, Bo Li, Ce Zhang, Dawn Song, and Costas J. Spanos. Towards efficient data valuation based on the shapley value. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 1167–1176, 2019
work page 2019
-
[27]
Peng Jin, Hao Li, Li Yuan, Shuicheng Yan, and Jie Chen. Hierarchical Banzhaf interaction for general video-language representation learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2125–2139, 2025. 11
work page 2025
-
[28]
SPEX: Scaling feature interaction explanations for LLMs
Justin Singh Kang, Landon Butler, Abhineet Agarwal, Yigit Efe Erginbas, Ramtin Pedarsani, Bin Yu, and Kannan Ramchandran. SPEX: Scaling feature interaction explanations for LLMs. InProceedings of the Conference on Machine Learning (ICML), pages 28878–28903, 2025
work page 2025
-
[29]
Jeroen Kazius, Ross McGuire, and Roberta Bursi. Derivation and validation of toxicophores for mutagenicity prediction.Journal of Medicinal Chemistry, 48(1):312–320, 2005. doi: 10.1021/jm040835a
-
[30]
LightGBM: A Highly Efficient Gradient Boosting Decision Tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), pages 3146–3154, 2017
work page 2017
-
[31]
Approximating the shapley value without marginal contributions
Patrick Kolpaczki, Viktor Bengs, Maximilian Muschalik, and Eyke Hüllermeier. Approximating the shapley value without marginal contributions. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 13246–13255, 2024
work page 2024
-
[32]
SV ARM-IQ: efficient approximation of any-order shapley interactions through stratification
Patrick Kolpaczki, Maximilian Muschalik, Fabian Fumagalli, Barbara Hammer, and Eyke Hüllermeier. SV ARM-IQ: efficient approximation of any-order shapley interactions through stratification. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 3520–3528, 2024
work page 2024
-
[33]
Datasets: A community library for natural language processing
Quentin Lhoest, Albert Villanova del Moral, Patrick von Platen, Thomas Wolf, Mario Šaško, Yacine Jernite, Abhishek Thakur, Lewis Tunstall, Suraj Patil, Mariama Drame, Julien Chaumond, Julien Plu, Joe Davison, Simon Brandeis, Victor Sanh, Teven Le Scao, Kevin Canwen Xu, Nicolas Patry, Steven Liu, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger, Nat...
work page 2021
-
[34]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. In European Conference on Computer Vision ECCV, volume 8693, pages 740–755, 2014
work page 2014
-
[35]
Marius Lindauer, Katharina Eggensperger, Matthias Feurer, André Biedenkapp, Difan Deng, Carolin Benjamins, Tim Ruhkopf, René Sass, and Frank Hutter. Smac3: A versatile bayesian optimization package for hyperparameter optimization.Journal of Machine Learning Research, 23(54):1–9, 2022. URLhttp://jmlr.org/papers/v23/21-0888.html
work page 2022
-
[36]
Tianran Liu, Nicky Evans, Kangyu Ji, Ronaldo Lee, Aaron Zhu, Vinn Nguyen, James Serdy, Elizabeth M Wall, Yongli Lu, Florian A Formica, et al. Disentangling environmental effects on perovskite solar cell performance via interpretable machine learning.ACS Energy Letters, 11: 1609–1617, 2026
work page 2026
-
[37]
Scott M. Lundberg and Su-In Lee. A Unified Approach to Interpreting Model Predictions. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), pages 4765– 4774, 2017
work page 2017
-
[38]
Scott M. Lundberg, Gabriel G. Erion, Hugh Chen, Alex J. DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From local explanations to global understanding with explainable AI for trees.Nature Machine Intelligence, 2(1):56–67,
-
[39]
doi: 10.1038/s42256-019-0138-9
-
[40]
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y . Ng, and Christopher Potts. Learning word vectors for sentiment analysis. InProceedings of the Association for Computational Linguistics: Human Language Technologies (HLT), pages 142–150, 2011
work page 2011
-
[41]
Axiomatic characterizations of generalized values.Discrete Applied Mathematics, 155(1):26–43, 2007
Jean-Luc Marichal, Ivan Kojadinovic, and Katsushige Fujimoto. Axiomatic characterizations of generalized values.Discrete Applied Mathematics, 155(1):26–43, 2007. doi: 10.1016/J.DAM. 2006.05.002. 12
-
[42]
Amortized Linear-time Exact Shapley Value for Product-Kernel Methods
Majid Mohammadi, Siu Lun Chau, and Krikamol Muandet. Computing exact Shapley values in polynomial time for product-kernel methods.arXiv preprint, arXiv:2505.16516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
General pitfalls of model-agnostic interpretation methods for machine learning models
Christoph Molnar, Gunnar König, Julia Herbinger, Timo Freiesleben, Susanne Dandl, Chris- tian A Scholbeck, Giuseppe Casalicchio, Moritz Grosse-Wentrup, and Bernd Bischl. General pitfalls of model-agnostic interpretation methods for machine learning models. InxxAI-Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, pages 39–68, 2022
work page 2020
-
[44]
shapiq: Shapley Interactions for Machine Learning
Maximilian Muschalik, Hubert Baniecki, Fabian Fumagalli, Patrick Kolpaczki, Barbara Ham- mer, and Eyke Hüllermeier. shapiq: Shapley Interactions for Machine Learning. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), pages 130324–130357, 2024
work page 2024
-
[45]
Beyond TreeSHAP: Efficient Computation of Any-Order Shapley Interactions for Tree Ensembles
Maximilian Muschalik, Fabian Fumagalli, Barbara Hammer, and Eyke Hüllermeier. Beyond TreeSHAP: Efficient Computation of Any-Order Shapley Interactions for Tree Ensembles. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 14388–14396,
-
[46]
doi: 10.1609/aaai.v38i13.29352
-
[47]
Exact Computation of Any- Order Shapley Interactions for Graph Neural Networks
Maximilian Muschalik, Fabian Fumagalli, Paolo Frazzetto, Janine Strotherm, Luca Hermes, Alessandro Sperduti, Eyke Hüllermeier, and Barbara Hammer. Exact Computation of Any- Order Shapley Interactions for Graph Neural Networks. InProceedings of the Conference on Learning Representations (ICLR), 2025
work page 2025
-
[48]
Christopher Musco and R. Teal Witter. Provably Accurate Shapley Value Estimation via Leverage Score Sampling. InProceedings of the International Conference on Learning Repre- sentations (ICLR), 2025
work page 2025
-
[49]
From decision trees to boolean logic: A fast and unified SHAP algorithm
Alexander Nadel and Ron Wettenstein. From decision trees to boolean logic: A fast and unified SHAP algorithm. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 24476–24485, 2026. doi: 10.1609/AAAI.V40I29.39630
-
[50]
Lars H. B. Olsen, Ingrid K. Glad, Martin Jullum, and Kjersti Aas. Using Shapley values and variational autoencoders to explain predictive models with dependent mixed features.Journal of Machine Learning Research, 23(213):1–51, 2022
work page 2022
-
[51]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the International Conference on Machine Learning ICML, pages 8748–8763, 2021
work page 2021
-
[52]
The shapley value in machine learning
Benedek Rozemberczki, Lauren Watson, Péter Bayer, Hao-Tsung Yang, Oliver Kiss, Sebastian Nilsson, and Rik Sarkar. The shapley value in machine learning. InProceedings of International Joint Conference on Artificial Intelligence (IJCAI), pages 5572–5579, 2022
work page 2022
-
[53]
Evaluating attribution for graph neural networks
Benjamin Sanchez-Lengeling, Jennifer Wei, Brian Lee, Emily Reif, Peter Wang, Wesley Qian, Kevin McCloskey, Lucy Colwell, and Alexander Wiltschko. Evaluating attribution for graph neural networks. InThe Thirty-third Annual Conference on Neural Information Processing Systems, volume 33, pages 5898–5910, 2020
work page 2020
-
[54]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.CoRR, abs/1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[55]
Investigating the impact of conceptual metaphors on LLM-based NLI through shapley interactions
Meghdut Sengupta, Maximilian Muschalik, Fabian Fumagalli, Barbara Hammer, Eyke Hüller- meier, Debanjan Ghosh, and Henning Wachsmuth. Investigating the impact of conceptual metaphors on LLM-based NLI through shapley interactions. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 17393–17403, 2025
work page 2025
-
[56]
L. S. Shapley. A Value for n-Person Games. InContributions to the Theory of Games (AM-28), Volume II, pages 307–318. Princeton University Press, 1953
work page 1953
-
[57]
Adaptive prompting: Ad-hoc prompt composition for social bias detection
Maximilian Spliethöver, Tim Knebler, Fabian Fumagalli, Maximilian Muschalik, Barbara Hammer, Eyke Hüllermeier, and Henning Wachsmuth. Adaptive prompting: Ad-hoc prompt composition for social bias detection. InProceedings of the Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics, 2025. 13
work page 2025
-
[58]
Erik Strumbelj and Igor Kononenko. An Efficient Explanation of Individual Classifications using Game Theory.Journal of Machine Learning Research, 11:1–18, 2010
work page 2010
-
[59]
Erik Strumbelj and Igor Kononenko. Explaining prediction models and individual predictions with feature contributions.Knowledge and Information Systems, 41(3):647–665, 2014. doi: 10.1007/s10115-013-0679-x
-
[60]
The Shapley Taylor Interaction Index
Mukund Sundararajan, Kedar Dhamdhere, and Ashish Agarwal. The Shapley Taylor Interaction Index. InProceedings of the International Conference on Machine Learning (ICML), pages 9259–9268, 2020
work page 2020
-
[61]
Che-Ping Tsai, Chih-Kuan Yeh, and Pradeep Ravikumar. Faith-Shap: The Faithful Shapley Interaction Index.Journal of Machine Learning Research, 24(94):1–42, 2023
work page 2023
-
[62]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, local- ization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Jiachen T. Wang and Ruoxi Jia. Data banzhaf: A robust data valuation framework for machine learning. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 6388–6421, 2023
work page 2023
-
[64]
Wang, Prateek Mittal, and Ruoxi Jia
Jiachen T. Wang, Prateek Mittal, and Ruoxi Jia. Efficient data Shapley for weighted nearest neighbor algorithms. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 2557–2565, 2024
work page 2024
-
[65]
HyperSHAP: Shapley Values and Interactions for Hyperparameter Importance
Marcel Wever, Maximilian Muschalik, Fabian Fumagalli, and Marius Lindauer. HyperSHAP: Shapley Values and Interactions for Hyperparameter Importance. InAAAI, 2026
work page 2026
-
[66]
Teal Witter, Yurong Liu, and Christopher Musco
R. Teal Witter, Yurong Liu, and Christopher Musco. Regression-adjusted monte carlo esti- mators for shapley values and probabilistic values. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), 2025. URL https://openreview.net/forum? id=Qabko39AS5
work page 2025
-
[67]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InProceedings of the International Conference on Learning Representations (ICLR),
-
[68]
URLhttps://openreview.net/forum?id=ryGs6iA5Km
-
[69]
Interventional SHAP values and interac- tion values for piecewise linear regression trees
Artjom Zern, Klaus Broelemann, and Gjergji Kasneci. Interventional SHAP values and interac- tion values for piecewise linear regression trees. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 11164–11173, 2023
work page 2023
-
[70]
Proxy-based Approximation of Shapley and Banzhaf Interactions
Chenyang Zhao, Kun Wang, Janet H. Hsiao, and Antoni B. Chan. Grad-ECLIP: Gradient-based visual and textual explanations for CLIP. InProceedings of the International Conference on Machine Learning ICML, 2024. 14 Appendix for “Proxy-based Approximation of Shapley and Banzhaf Interactions” A Proofs 16 A.1 Proof of Proposition 3.2 . . . . . . . . . . . . . . ...
work page 2024
-
[71]
We also compare leverage weights, as used in LeverageSHAP [45], with KernelSHAP- IQ weights [ 16]
as model-agnostic residual approxima- tors. We also compare leverage weights, as used in LeverageSHAP [45], with KernelSHAP- IQ weights [ 16]. As underlying games, we use VIT4BY4PATCHES, BIKESHARINGLO- CALXAI, CALIFORNIAHOUSINGLOCALXAI, CORRGROUPS60LOCALXAI, and COMMUNI- TIESANDCRIMELOCALXAI; details on these datasets are provided in Section C.1. For each...
-
[72]
Sampling and evaluation.Coalitions T ⊆2 N are sampled and evaluated, yielding the dataset D={(T, ν(T))} T∈T
-
[73]
Proxy fitting.A gradient-boosted tree model, by default LightGBM, is fitted on D by minimizing the mean squared error
-
[74]
Fourier extraction and truncation.Fourier coefficients are extracted from the fitted tree proxy. ProxySPEX then keeps a minimal subset C ⋆ ⊆ F of coefficients that explains at least95%of the total squared Fourier mass, C ⋆ = arg min C⊆F |C|s.t. P F∈C F 2 P F∈F F 2 ≥0.95, whereFdenotes the set of Fourier coefficients extracted from the tree
-
[75]
Adjustment.Given the truncated coefficient set C ⋆, ProxySPEX applies a refinement step to improve the extracted Fourier coefficients. It constructs a design matrix X∈ {−1,+1} |T |×|C ⋆| with entries Xi,j = (−1)|Ti∩Cj |, and solves the regularized regression problem F ⋆ = arg min F∈R |C⋆ | ∥ν−XF∥ 2 2 +λ∥F∥ 2 2. The truncation step is essential for making ...
-
[76]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.