VideoOdyssey: A Benchmark for Ultra-Long-Context and Omni-Modal Video Understanding
Pith reviewed 2026-05-25 05:50 UTC · model grok-4.3
The pith
Bottlenecks in current MLLMs for long videos extend beyond retrieval to continuous reasoning, fine-grained perception, and non-verbal omni-modal understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that VideoOdyssey, with its extreme durations and multi-level continuous certificates averaging 16 minutes for the visual subset and 12.8 minutes for the audio-visual subset, demonstrates that current MLLMs struggle with continuous reasoning across varying context lengths, fine-grained perception, and non-verbal omni-modal understanding rather than simple retrieval alone.
What carries the argument
continuous certificate length, the video length a human must continuously watch to definitively answer a question; it structures question design, subset creation, and diagnostic levels to force models into long temporal integration.
If this is right
- Models must demonstrate integration of information over continuous spans of 12 to 16 minutes on average to succeed.
- Performance varies systematically across five certificate levels, allowing targeted diagnosis of length-dependent failures.
- Omni-modal models require explicit handling of synchronized non-verbal audio-visual cues beyond speech.
- Progress depends on mechanisms for fine-grained perception sustained across long temporal contexts rather than retrieval alone.
Where Pith is reading between the lines
- The leveled structure could support staged training where models first master short certificates before scaling to hour-long ones.
- It points to a need for architectures with explicit long-term memory retention separate from context window size.
- Real-world applications such as video surveillance or lecture analysis may require similar certificate-based evaluation to ensure reliability.
- Extending the benchmark to interactive or multi-agent video scenarios could test whether the identified bottlenecks persist under dynamic conditions.
Load-bearing premise
The questions are written so that correct answers require watching the full continuous certificate length without being solvable through partial viewing, question phrasing, or video selection biases.
What would settle it
A model that answers the benchmark questions correctly after processing only short isolated segments, or human annotators who answer correctly without watching the full certificate length, would show the metric does not capture the intended cognitive load.
Figures







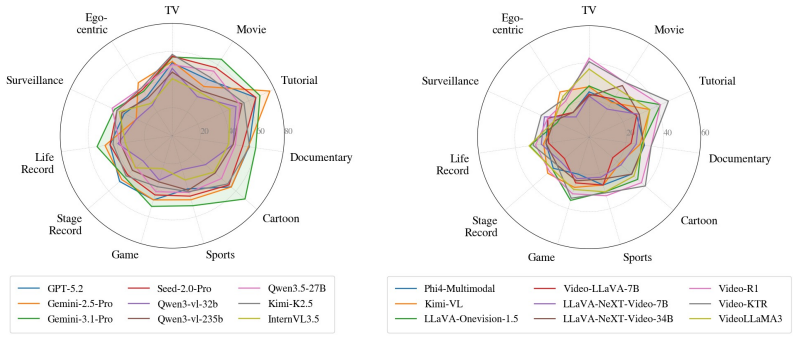
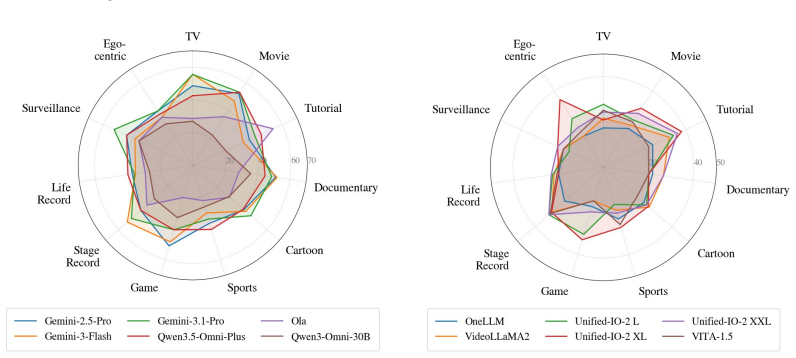







read the original abstract
Real-world long video understanding requires models to perform continuous tracking, information integration and memory retention over massive temporal spans within extreme video durations. Mastering this intense cognitive load constitutes the fundamental bottleneck in long video understanding. While existing benchmarks have driven progress by scaling up video duration, their evaluation tasks often require comprehending only short and isolated video segments, falling short of capturing the challenge of ultra-long-context reasoning. To measure this cognitive load, we emphasize continuous certificate length, defined as the video length a human must continuously watch to definitively answer a given question. Driven by this metric, we introduce VideoOdyssey, a benchmark specifically designed for ultra-long-context and omni-modal video understanding. VideoOdyssey is characterized by three key features: 1) Extreme video duration and diversity: spanning 11 domains and 54 subcategories with an average video duration of 109 minutes; 2) Comprehensive evaluation scenarios: offering two subsets to address different research focuses, i.e., VideoOdyssey-V for probing the limits of visual understanding in MLLMs, and VideoOdyssey-AV for evaluating synchronized audio-visual understanding for omni-modal models; 3) Ultra-long and multi-level continuous certificates: extending the average continuous certificate to 16 minutes for VideoOdyssey-V and 12.8 minutes for VideoOdyssey-AV. Crucially, we design 5 granular levels from seconds to hours, providing a comprehensive diagnostic tool to evaluate models across varying context lengths and cognitive loads. Extensive evaluations show that bottlenecks of current MLLMs extend beyond simple retrieval to include struggles with continuous reasoning across varying context lengths, fine-grained perception, and non-verbal omni-modal understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoOdyssey, a benchmark for ultra-long-context and omni-modal video understanding. It features videos averaging 109 minutes across 11 domains and 54 subcategories, two subsets (VideoOdyssey-V and VideoOdyssey-AV), and defines 'continuous certificate length' (avg. 16 min for V, 12.8 min for AV) with five granular levels from seconds to hours. Evaluations on MLLMs are reported to show that bottlenecks extend beyond retrieval to continuous reasoning across context lengths, fine-grained perception, and non-verbal omni-modal understanding.
Significance. If the continuous certificate length metric is validated and the evaluations are methodologically sound, the benchmark could provide a useful diagnostic for long-video MLLM limitations that existing shorter-segment benchmarks do not capture, potentially guiding targeted improvements in memory and integration capabilities.
major comments (2)
- [Abstract] Abstract (definition of continuous certificate length): the central claim that performance drops across context lengths isolate 'continuous reasoning' load depends on the untested premise that questions require the full specified duration; no ablation, human study, or truncation experiment is described showing that shorter segments render questions unanswerable.
- [Evaluation section] Evaluation/results section: the abstract states that 'extensive evaluations show' specific bottlenecks, yet the manuscript supplies no task examples, data statistics, question construction details, or validation procedures for the certificate lengths, preventing assessment of whether the empirical findings support the conclusions.
minor comments (1)
- [Abstract] The abstract lacks any numerical data statistics (e.g., total questions, distribution across levels) or example questions, which would improve clarity even if present in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our methodology while committing to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (definition of continuous certificate length): the central claim that performance drops across context lengths isolate 'continuous reasoning' load depends on the untested premise that questions require the full specified duration; no ablation, human study, or truncation experiment is described showing that shorter segments render questions unanswerable.
Authors: Continuous certificate length is established via a human annotation protocol in which annotators determine the shortest continuous video segment that allows definitive question resolution; this process directly encodes the requirement that shorter segments are insufficient. We acknowledge that the initial manuscript did not include explicit truncation ablations or additional human studies beyond the annotation itself. We will expand the methods section with a fuller description of the annotation guidelines and consider adding supporting truncation analyses where feasible. revision: partial
-
Referee: [Evaluation section] Evaluation/results section: the abstract states that 'extensive evaluations show' specific bottlenecks, yet the manuscript supplies no task examples, data statistics, question construction details, or validation procedures for the certificate lengths, preventing assessment of whether the empirical findings support the conclusions.
Authors: The manuscript contains sections on benchmark construction that report video statistics, domain coverage, and the multi-level certificate design, along with question generation guidelines. To address the concern about accessibility and completeness, we will insert concrete task examples, additional summary statistics, and an explicit subsection detailing the certificate-length validation steps directly into the evaluation section. revision: yes
Circularity Check
No circularity: benchmark metric is explicitly defined without reduction to inputs or self-citations
full rationale
The paper is a benchmark introduction with no equations, derivations, fitted parameters, or predictions. The continuous certificate length is defined directly as 'the video length a human must continuously watch to definitively answer a given question' and used to curate questions; this is a design choice, not a self-referential loop or fitted input renamed as output. No self-citation chains or uniqueness theorems are invoked as load-bearing. The evaluation is purely empirical on the new dataset, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video understanding tasks can be constructed such that answering requires continuous attention to long temporal spans rather than isolated segments.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat (Peano recovery from orbit under generator) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
continuous certificate length, defined as the video length a human must continuously watch to definitively answer a given question... 5 granular levels from seconds to hours
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z (Z-monotonicity defines temporal order) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bottlenecks of current MLLMs extend beyond simple retrieval to include struggles with continuous reasoning across varying context lengths
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.arXiv preprint arXiv:2503.01743,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Infinibench: A benchmark for large multi-modal models in long-form movies and tv shows
Kirolos Ataallah, Eslam Mohamed Bakr, Mahmoud Ahmed, Chenhui Gou, Khushbu Pahwa, Jian Ding, and Mohamed Elhoseiny. Infinibench: A benchmark for large multi-modal models in long-form movies and tv shows. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19496–19523,
2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cg-bench: Clue-grounded question answering benchmark for long video understanding
Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, and Limin Wang. Cg-bench: Clue-grounded question answering benchmark for long video understanding. arXiv preprint arXiv:2412.12075,
-
[6]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025a. Chaoyou Fu, Haojia Lin, X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
10 Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, et al. Av-odyssey bench: Can your multimodal llms really understand audio-visual information?arXiv preprint arXiv:2412.02611,
-
[11]
ZhaoYang Han, Qihan Lin, Hao Liang, Bowen Chen, Zhou Liu, and Wentao Zhang. Longinsightbench: A comprehensive benchmark for evaluating omni-modal models on human-centric long-video understanding.arXiv preprint arXiv:2510.17305,
-
[12]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos.arXiv preprint arXiv:2501.13826,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024a. Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Jiafu Tang, Zhenghao Song, Dingling Zhang, et al. Omnivideobench: Toward...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025b. Yizhi Li, Ge Zhang, Yinghao Ma, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, et al. ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024a
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024a. Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos?ArXiv preprint, 2024b. Zuyan Liu, Yuhao Dong, Jiah...
-
[17]
Introducing GPT-4.1 in the API
OpenAI. Introducing GPT-4.1 in the API. https://openai.com/index/gpt-4-1/, 2025a. Ac- cessed: 2025-04-14. OpenAI. Introducing OpenAI o3 and o4-mini. https://openai.com/index/ introducing-o3-and-o4-mini/, 2025b. Accessed: 2025-05-15. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via la...
2025
-
[18]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Keda Tao, Yuhua Zheng, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, et al. Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms.arXiv preprint arXiv:2603.19217,
-
[20]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen3.5-omni technical report, 2026a
Qwen Team. Qwen3.5-omni technical report, 2026a. URL https://arxiv.org/abs/2604. 15804. Qwen Team. Qwen3. 5: Towards native multimodal agents.URL: https://qwen. ai/blog, 2026b. Shulin Tian, Ruiqi Wang, Hongming Guo, Penghao Wu, Yuhao Dong, Xiuying Wang, Jingkang Yang, Hao Zhang, Hongyuan Zhu, and Ziwei Liu. Ego-r1: Chain-of-tool-thought for ultra-long ego...
-
[23]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025a. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoy...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100,
-
[26]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025a. Xiaoyi Zhang, Zhaoyang Jia, Zongyu Guo, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Deep video di...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 13691–13701, 2025a. Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-omni: Towards audio-visual reason...
-
[28]
As illustrated in the figures, there is a clear negative correlation between the continuous certificate length and human accuracy. InVideoOdyssey-V, human performance starts at a high of 90.7% for extremely short evidence lengths ( <0.5 mins) but drops strictly and significantly to 74.5% for evidence lengths exceeding 60 minutes. A similar declining trend...
2024
-
[29]
What did you say?
When evaluating this model using the ground-truth certificate window, the sampling strategy is as follows: • Window length < 128 seconds: We densely extract frames at a rate of 1fps to preserve maximum temporal granularity. • Window length ≥ 128 seconds: We uniformly sample 128 frames across the entire duration of the window to provide a comprehensive ove...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.