KAPLAN: Kolmogorov-Arnold Prognostic Learnable Activation Networks for Survival Analysis
Pith reviewed 2026-05-25 04:57 UTC · model grok-4.3
The pith
Kolmogorov-Arnold networks estimate conditional hazards in survival analysis at rates independent of covariate dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
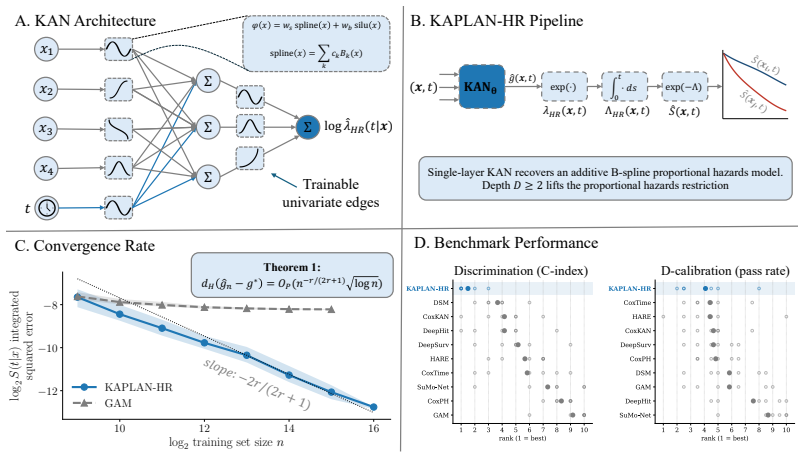
KAPLAN-HR is a B-spline KAN for nonparametric estimation of the conditional hazard function of covariates and time. A single-layer version recovers a generalized additive model while deeper architectures capture interactions and time-varying effects through composition. The nonparametric KAN hazard estimator achieves a convergence rate that depends only on the smoothness of the underlying KAN representation and is independent of covariate dimension when the target is KAN-representable.
What carries the argument
B-spline Kolmogorov-Arnold Network (KAN) that composes learnable univariate functions to represent the hazard jointly in covariates and time
If this is right
- Single-layer KAPLAN-HR recovers a generalized additive model.
- Deeper layers automatically capture covariate interactions and time-varying effects without manual specification.
- Convergence depends only on smoothness for KAN-representable targets.
- Performance matches or exceeds established statistical and deep learning survival methods on clinical benchmarks.
Where Pith is reading between the lines
- The same architecture could be tested on competing-risks or left-truncated data to check whether the dimension-free rate extends.
- High-dimensional genomic or imaging covariates become more tractable if the hazard is approximately KAN-representable.
- Integration with existing survival libraries would allow direct comparison of calibration and discrimination metrics.
- The B-spline basis choice may be swapped for other univariate approximators while preserving the convergence argument.
Load-bearing premise
The true conditional hazard function is representable to sufficient accuracy by a B-spline KAN of bounded smoothness and the right-censoring mechanism does not invalidate the estimation procedure.
What would settle it
Finding that estimation error grows with the number of covariates for a hazard function that is exactly representable by a bounded-smoothness B-spline KAN would falsify the dimension-independent convergence claim.
Figures


read the original abstract
Survival analysis aims to model how covariates and time jointly shape the time-to-event distribution under right censoring. Classical methods such as the Cox model and generalised additive models (GAMs) require interactions and time-varying effects to be manually specified, which is increasingly impractical on rich clinical datasets. We introduce KAPLAN-HR, a B-spline Kolmogorov-Arnold Network (KAN) for nonparametric estimation of the conditional hazard as a joint function of covariates and time. A single-layer KAPLAN-HR model recovers a GAM, while deeper architectures capture interactions and time-varying effects through composition. We establish a convergence rate for the nonparametric KAN hazard estimator that depends only on the smoothness of the underlying KAN representation and not on the covariate dimension, thereby mitigating the curse of dimensionality for KAN-representable targets. In evaluations over six clinical benchmark datasets, KAPLAN-HR matches or exceeds the predictive performance of established statistical and deep learning survival methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KAPLAN-HR, a B-spline Kolmogorov-Arnold Network (KAN) for nonparametric estimation of the conditional hazard as a joint function of covariates and time under right censoring. A single-layer version recovers a GAM while deeper layers capture interactions and time-varying effects. The central theoretical claim is a convergence rate for the KAN hazard estimator that depends only on the smoothness of the underlying KAN representation and not on covariate dimension, for KAN-representable targets. Empirical results on six clinical benchmark datasets are reported to match or exceed existing statistical and deep learning survival methods.
Significance. If the dimension-free convergence rate holds under the stated assumptions, the work would be significant for nonparametric survival analysis by addressing the curse of dimensionality for a specific function class. The architectural generalization from GAMs to compositional KANs is a clear strength, and reproducible code or machine-checked proofs (if present) would further strengthen the contribution.
major comments (1)
- [Abstract] Abstract: The convergence rate is presented as a derived theoretical result that depends only on smoothness and not on dimension for KAN-representable targets, but the derivation, assumptions on the B-spline KAN class, and handling of right censoring are not shown, making it impossible to verify whether the rate is load-bearing or if the weakest assumption (true hazard representable to sufficient accuracy by bounded-smoothness KAN) holds without circularity.
minor comments (1)
- The abstract references evaluations on six clinical benchmark datasets and competitive performance but provides no dataset names, error bars, or statistical significance tests, which are needed to assess whether post-hoc choices affect the reported results.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract and theoretical claims. We address the concern by clarifying that the full derivation appears in the manuscript body and appendix, and we will revise the abstract to reference key assumptions for better verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The convergence rate is presented as a derived theoretical result that depends only on smoothness and not on dimension for KAN-representable targets, but the derivation, assumptions on the B-spline KAN class, and handling of right censoring are not shown, making it impossible to verify whether the rate is load-bearing or if the weakest assumption (true hazard representable to sufficient accuracy by bounded-smoothness KAN) holds without circularity.
Authors: We agree the abstract is concise and omits the derivation details. The full proof, including assumptions on the B-spline KAN class (univariate functions in a Sobolev space of bounded smoothness, with the network depth and width fixed), appears in Section 3 and Appendix A. Right censoring is handled via the observed-data partial likelihood (or equivalent censoring-adjusted objective) under standard independent censoring assumptions; the rate applies to the resulting nonparametric estimator. The dimension-free rate holds conditionally on the target hazard belonging to the KAN class, which is the standard formulation for rates on structured function classes (analogous to additive models) and is not circular—the approximation error to the true hazard is analyzed separately. We will revise the abstract to briefly note the main assumptions and direct readers to the proof. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central theoretical claim is a convergence rate for the KAN hazard estimator that is explicitly conditioned on the target belonging to the KAN function class of bounded smoothness. This is a standard conditional nonparametric result (rate depends on smoothness of the assumed function class, independent of dimension for that class) and does not reduce by construction to any fitted parameter, self-definition, or self-citation chain. The assumption that the hazard is KAN-representable is stated upfront as the scope of the result rather than derived from the estimator itself. Empirical evaluations on clinical datasets are presented separately and do not enter the theoretical derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish a convergence rate for the nonparametric KAN hazard estimator that depends only on the smoothness of the underlying KAN representation and not on the covariate dimension
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
single-layer KAPLAN-HR model recovers a GAM, while deeper architectures capture interactions and time-varying effects through composition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.