EchoDistill:Alignment Noisy-to-Clean Self-Distillation for Robust Audio LLMs
Pith reviewed 2026-06-30 22:50 UTC · model grok-4.3
The pith
EchoDistill aligns a noisy Audio LLM student to a frozen clean teacher via GRPO token-consistency rewards to cut semantic drift without raising inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
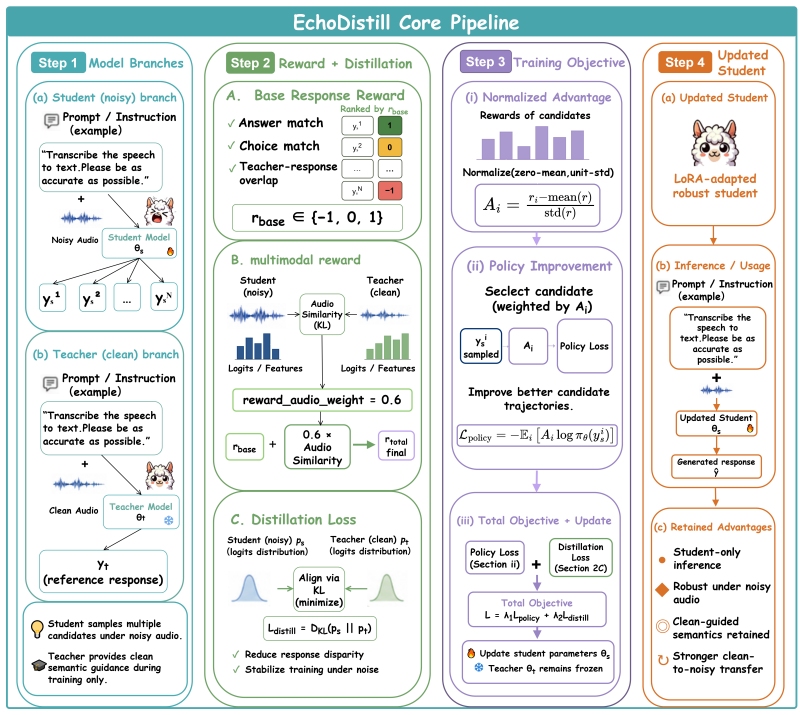
EchoDistill is an alignment-based noisy-to-clean self-distillation framework in which a frozen clean-audio teacher provides semantic references for an inference-time noisy-audio student; the student samples candidate responses under noise, and these trajectories are optimized via group-relative policy optimization where token-level consistency with the teacher acts as a reward bonus, yielding improved semantic reliability and task performance under complex noise with no added inference cost.
What carries the argument
Group-relative policy optimization (GRPO) on noisy student trajectories that uses token-level consistency with the clean teacher as the reward signal.
If this is right
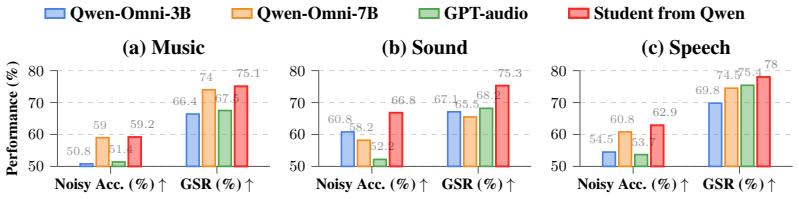
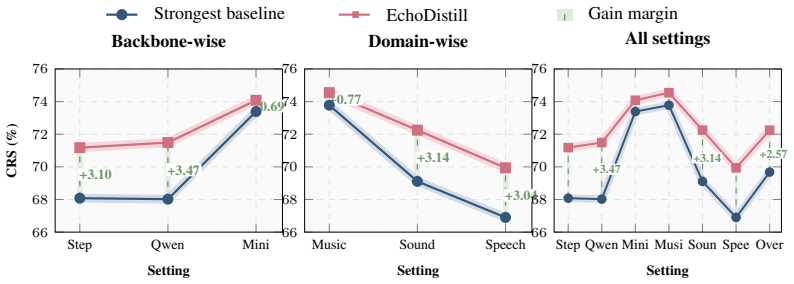
- Average GSR rises 4.18 percent under strong noise relative to the strongest prior baseline.
- On Qwen-Omni, the full method adds 3.02 percent Acc, 3.89 percent Noisy, and 4.53 percent GSR over GRPO alone.
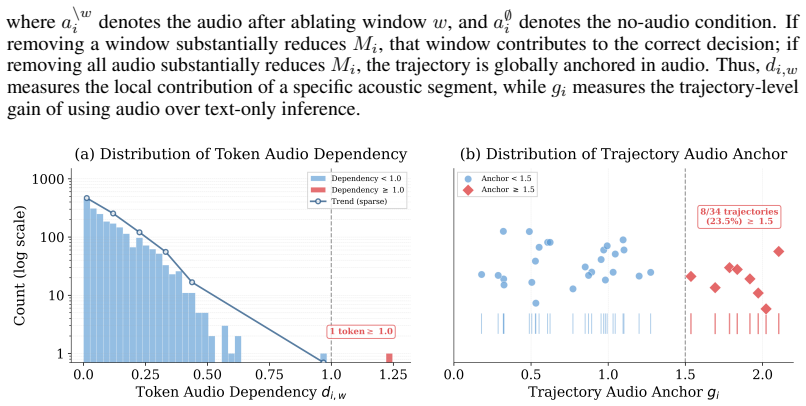
- Reasoning paths become both more correct and more directly tied to the actual acoustic input.
- The same model can be made robust after training by applying the alignment procedure only at test time.
Where Pith is reading between the lines
- The separation of a clean reference model from the deployed noisy model suggests a general pattern for test-time robustness in other multimodal settings where clean exemplars can be obtained offline.
- Because the optimization occurs only on sampled trajectories, the method could be combined with existing acoustic enhancement pipelines without retraining the core LLM.
- If the clean teacher itself contains domain biases, those biases would be transferred into the student's selected paths, an effect not measured in the current experiments.
Load-bearing premise
The frozen clean-audio teacher supplies semantic references that are reliable enough to serve as token-level consistency rewards for the noisy student.
What would settle it
Running the same noisy-audio evaluation suite and finding that EchoDistill produces no measurable gain in GSR or accuracy over the GRPO-only baseline would falsify the value of the teacher alignment step.
Figures
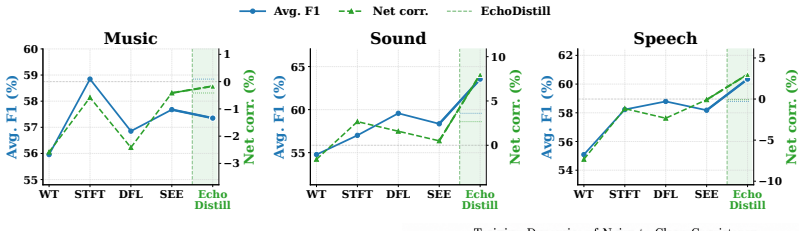
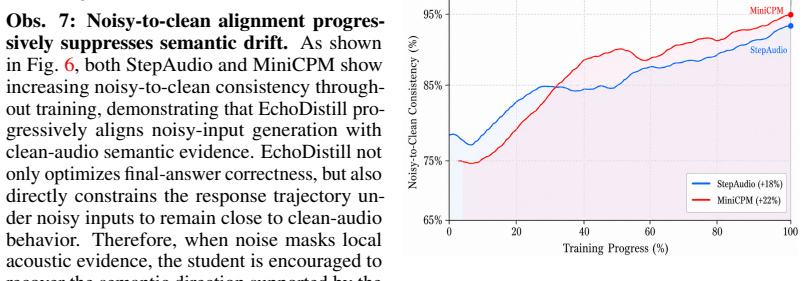
read the original abstract
Audio Large Language Models (ALLMs) are highly vulnerable to real-world noise, which often induces severe semantic drift and hallucinations. Existing robustness methods primarily rely on waveform-level acoustic enhancement, answer-level supervision, or the internal suppression of noise representations. To address these issues, we propose echodistill, an alignment-based noisy-to-clean self-distillation framework. Echodistill leverages a frozen clean-audio teacher to provide semantic references for an inference-time noisy-audio student. Specifically, the student samples candidate responses under noisy conditions to expose its test-time behavior. These trajectories are then optimized via group-relative policy optimization (GRPO), where the token-level consistency with the teacher acts as a reward bonus. By aligning the noisy student's candidate responses with clean semantic evidence, and applying audio-aware reward shaping, our method encourages reasoning trajectories that are both correct and genuinely acoustically grounded. Echodistill significantly improves the semantic reliability and task performance of Audio LLMs under complex noise, without introducing any additional inference costs. Extensive experiments show that: (I) Compared with the strongest baseline, echodistill achieves average improvements of 4.18\%$\uparrow$ in GSR under strong noise. (II) Ablation results on Qwen-Omni further show that echodistill improves over the GRPO-only variant by 3.02\%$\uparrow$ in Acc, 3.89\%$\uparrow$ in Noisy, and 4.53\%$\uparrow$ in GSR on average. Our codes are available at https://anonymous.4open.science/r/echodistill-10DE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EchoDistill, a noisy-to-clean self-distillation framework for Audio Large Language Models. A frozen clean-audio teacher supplies semantic references that are used to optimize an inference-time noisy student's sampled response trajectories via Group Relative Policy Optimization (GRPO), with token-level consistency serving as a reward bonus and audio-aware shaping applied. The method claims to improve semantic reliability and task performance under complex noise without added inference cost, reporting an average 4.18% GSR gain under strong noise versus the strongest baseline and further gains (3.02% Acc, 3.89% Noisy, 4.53% GSR) over a GRPO-only ablation on Qwen-Omni.
Significance. If the central results hold, the work would offer a practical route to noise-robust ALLMs by aligning noisy inference trajectories to clean semantic evidence at no extra runtime cost. The use of GRPO on token-consistency rewards and the explicit separation of teacher and student audio conditions constitute a distinct technical contribution relative to waveform enhancement or answer-level supervision baselines.
major comments (2)
- The reported performance gains rest on the assumption that token-level consistency between the frozen clean teacher and the noisy student's trajectories constitutes a valid reward signal under GRPO. The manuscript provides no quantitative validation (e.g., correlation between teacher-student agreement rates and ground-truth correctness) that this signal rewards acoustically grounded reasoning rather than superficial lexical overlap; this check is load-bearing for the 4.18% GSR claim under strong noise.
- Ablation results on Qwen-Omni claim consistent improvements over the GRPO-only variant, yet the description does not specify how the teacher-derived reward is ablated (e.g., whether the teacher is replaced by a noisy reference or removed entirely) or report variance across noise types and seeds. Without these controls it is unclear whether the additional 3-4.5% gains are attributable to the clean-teacher alignment.
minor comments (2)
- The abstract states that codes are available at an anonymous repository; the final version should replace this with a permanent link and include the exact experimental configurations (noise levels, datasets, and GSR definition) used for the reported percentages.
- Notation for the reward bonus and audio-aware shaping is introduced only descriptively; an explicit equation or pseudocode block would clarify how the token-consistency term is combined with any base reward in the GRPO objective.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The reported performance gains rest on the assumption that token-level consistency between the frozen clean teacher and the noisy student's trajectories constitutes a valid reward signal under GRPO. The manuscript provides no quantitative validation (e.g., correlation between teacher-student agreement rates and ground-truth correctness) that this signal rewards acoustically grounded reasoning rather than superficial lexical overlap; this check is load-bearing for the 4.18% GSR claim under strong noise.
Authors: We agree that the manuscript lacks an explicit quantitative validation such as correlation between teacher-student agreement rates and ground-truth correctness. In the revised version we will add a dedicated analysis subsection that computes and reports Pearson correlations (and associated p-values) between per-trajectory agreement rates and correctness labels across all noise conditions and tasks. This will directly test whether the reward signal aligns with acoustically grounded reasoning. revision: yes
-
Referee: Ablation results on Qwen-Omni claim consistent improvements over the GRPO-only variant, yet the description does not specify how the teacher-derived reward is ablated (e.g., whether the teacher is replaced by a noisy reference or removed entirely) or report variance across noise types and seeds. Without these controls it is unclear whether the additional 3-4.5% gains are attributable to the clean-teacher alignment.
Authors: We acknowledge the ablation description is underspecified. In revision we will explicitly state that the GRPO-only baseline removes the teacher-derived token-consistency reward entirely (retaining only the task-performance component of the reward) and will report results with standard deviations across three random seeds, broken down by individual noise type (babble, music, environmental, etc.). These additions will clarify attribution to the clean-teacher signal. revision: yes
Circularity Check
No circularity: derivation relies on external teacher assumption and empirical results
full rationale
The paper presents EchoDistill as an empirical alignment framework in which a separately frozen clean-audio teacher supplies token-level consistency rewards to optimize a noisy student's GRPO trajectories. No equations, fitted parameters renamed as predictions, or self-citations are shown that would reduce the claimed performance gains (e.g., 4.18% GSR) to a definitional identity or tautological input. The method's load-bearing step is the external assumption that the clean teacher yields reliable semantic references, which is stated as an assumption rather than derived from the student's own outputs. All reported improvements are positioned as experimental outcomes from ablations and comparisons, leaving the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
De-noising by soft-thresholding.IEEE transactions on information theory, 41(3):613–627, 1995
1995
-
[2]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
2024
-
[3]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025
-
[4]
Pearson correlation coefficient
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. Pearson correlation coefficient. InNoise reduction in speech processing, pages 1–4. Springer, 2009
2009
-
[5]
Shuang Chen, Yue Guo, Zhaochen Su, Yafu Li, Yulun Wu, Jiacheng Chen, Jiayu Chen, Weijie Wang, Xiaoye Qu, and Yu Cheng. Advancing multimodal reasoning: From optimized cold start to staged reinforcement learning.arXiv preprint arXiv:2506.04207, 2025
-
[6]
Noise-robust sound event detection and counting via language-queried sound separation.IEEE Signal Processing Letters, 2025
Yuanjian Chen, Yang Xiao, Han Yin, Yadong Guan, and Xubo Liu. Noise-robust sound event detection and counting via language-queried sound separation.IEEE Signal Processing Letters, 2025
2025
-
[7]
Xize Cheng, Dongjie Fu, Xiaoda Yang, Minghui Fang, Ruofan Hu, Jingyu Lu, Bai Jionghao, Zehan Wang, Shengpeng Ji, Rongjie Huang, et al. Omnichat: Enhancing spoken dialogue systems with scalable synthetic data for diverse scenarios.arXiv preprint arXiv:2501.01384, 2025
-
[8]
Xize Cheng, Siqi Zheng, Zehan Wang, Minghui Fang, Ziang Zhang, Rongjie Huang, Ziyang Ma, Shengpeng Ji, Jialong Zuo, Tao Jin, et al. Omnisep: Unified omni-modality sound separation with query-mixup.arXiv preprint arXiv:2410.21269, 2024
-
[9]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Adverse effects of environmental noise on acoustic voice quality measurements.Journal of Voice, 19(1):15–28, 2005
Dimitar D Deliyski, Heather S Shaw, and Maegan K Evans. Adverse effects of environmental noise on acoustic voice quality measurements.Journal of Voice, 19(1):15–28, 2005
2005
-
[11]
Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator.IEEE Transactions on acoustics, speech, and signal processing, 32(6):1109–1121, 2003
Yariv Ephraim and David Malah. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator.IEEE Transactions on acoustics, speech, and signal processing, 32(6):1109–1121, 2003
2003
-
[12]
Alphaedit: Null-space constrained knowledge editing for language models
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. arXiv preprint arXiv:2410.02355, 2024
-
[13]
Born again neural networks
Tommaso Furlanello, Zachary Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. InInternational conference on machine learning, pages 1607–1616. PMLR, 2018
2018
-
[14]
Double the trouble: handling noise and reverberation in far-field automatic speech recognition
David Gelbart and Nelson Morgan. Double the trouble: handling noise and reverberation in far-field automatic speech recognition. InInterspeech, pages 2185–2188, 2002
2002
-
[15]
Explainable disentanglement on discrete speech representations for noise-robust asr
Shreyas Gopal, Ashutosh Anshul, Haoyang Li, Yue Heng Yeo, Hexin Liu, and Eng Siong Chng. Explainable disentanglement on discrete speech representations for noise-robust asr. In2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 2535–2540. IEEE, 2025. 10
2025
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Evaluating robustness of large audio language models to audio injection: An empirical study
Guanyu Hou, Jiaming He, Yinhang Zhou, Ji Guo, Yitong Qiao, Rui Zhang, and Wenbo Jiang. Evaluating robustness of large audio language models to audio injection: An empirical study. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25671–25687, 2025
2025
-
[19]
A tandem algorithm for pitch estimation and voiced speech segregation.IEEE Transactions on Audio, Speech, and Language Processing, 18(8):2067–2079, 2010
Guoning Hu and DeLiang Wang. A tandem algorithm for pitch estimation and voiced speech segregation.IEEE Transactions on Audio, Speech, and Language Processing, 18(8):2067–2079, 2010
2067
-
[20]
Audiogpt: Understanding and generating speech, music, sound, and talking head
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. Audiogpt: Understanding and generating speech, music, sound, and talking head. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 23802–23804, 2024
2024
-
[21]
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025
-
[22]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026
-
[24]
Audio augmentation for speech recognition
Tom Ko, Vijayaditya Peddinti, Daniel Povey, and Sanjeev Khudanpur. Audio augmentation for speech recognition. InInterspeech, volume 2015, page 3586, 2015
2015
-
[25]
Robustness in Large Language Models: A Survey of Mitigation Strategies and Evaluation Metrics,
Pankaj Kumar and Subhankar Mishra. Robustness in large language models: A survey of mitigation strategies and evaluation metrics.arXiv preprint arXiv:2505.18658, 2025
-
[26]
Mmau- pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence
Sonal Kumar, Šimon Sedlá ˇcek, Vaibhavi Lokegaonkar, Fernando López, Wenyi Yu, Nishit Anand, Hyeonggon Ryu, Lichang Chen, Maxim Pli ˇcka, Miroslav Hlavá ˇcek, et al. Mmau- pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2...
2026
-
[27]
Bohan Li, Wenbin Huang, Yuhang Qiu, Yiwei Guo, Hankun Wang, Zhihan Li, Jing Peng, Ziyang Ma, Xie Chen, and Kai Yu. Isa-bench: Benchmarking instruction sensitivity for large audio language models.arXiv preprint arXiv:2510.23558, 2025
-
[28]
Applications of large language models and multimodal large models in autonomous driving: A comprehensive review.Drones, 9(4):238, 2025
Jing Li, Jingyuan Li, Guo Yang, Lie Yang, Haozhuang Chi, and Lichao Yang. Applications of large language models and multimodal large models in autonomous driving: A comprehensive review.Drones, 9(4):238, 2025
2025
-
[29]
Robust automatic speech recogni- tion: a bridge to practical applications
Jinyu Li, Li Deng, Reinhold Haeb-Umbach, and Yifan Gong. Robust automatic speech recogni- tion: a bridge to practical applications. 2015
2015
-
[30]
Hidden in the noise: Unveiling backdoors in audio llms alignment through latent acoustic pattern triggers
Liang Lin, Miao Yu, Kaiwen Luo, Yibo Zhang, Lilan Peng, Dexian Wang, Xuehai Tang, Yuanhe Zhang, Xikang Yang, Zhenhong Zhou, et al. Hidden in the noise: Unveiling backdoors in audio llms alignment through latent acoustic pattern triggers. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32015–32023, 2026
2026
-
[31]
ChronosAudio: A Comprehensive Long-Audio Benchmark for Evaluating Audio-Large Language Models
Kaiwen Luo, Liang Lin, Yibo Zhang, Moayad Aloqaily, Dexian Wang, Zhenhong Zhou, Junwei Zhang, Kun Wang, Li Sun, and Qingsong Wen. Chronosaudio: A comprehensive long-audio benchmark for evaluating audio-large language models.arXiv preprint arXiv:2601.04876, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, et al. Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix.arXiv preprint arXiv:2505.13032, 2025
-
[33]
Daniel S Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D Cubuk, and Quoc V Le. Specaugment: A simple data augmentation method for automatic speech recognition.arXiv preprint arXiv:1904.08779, 2019
-
[34]
SEGAN: Speech Enhancement Generative Adversarial Network
Santiago Pascual, Antonio Bonafonte, and Joan Serra. Segan: Speech enhancement generative adversarial network.arXiv preprint arXiv:1703.09452, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Deep learning for audio signal processing.IEEE Journal of Selected Topics in Signal Processing, 13(2):206–219, 2019
Hendrik Purwins, Bo Li, Tuomas Virtanen, Jan Schlüter, Shuo-Yiin Chang, and Tara Sainath. Deep learning for audio signal processing.IEEE Journal of Selected Topics in Signal Processing, 13(2):206–219, 2019
2019
-
[36]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[37]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[38]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
2026
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Taskbench: Benchmarking large language models for task automation.Advances in Neural Information Processing Systems, 37:4540–4574, 2024
Yongliang Shen, Kaitao Song, Xu Tan, Wenqi Zhang, Kan Ren, Siyu Yuan, Weiming Lu, Dongsheng Li, and Yueting Zhuang. Taskbench: Benchmarking large language models for task automation.Advances in Neural Information Processing Systems, 37:4540–4574, 2024
2024
-
[42]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[44]
Beyond Compromise: Pareto-Lenient Consensus for Efficient Multi-Preference LLM Alignment
Renxuan Tan, Rongpeng Li, Zhifeng Zhao, and Honggang Zhang. Beyond compromise: Pareto- lenient consensus for efficient multi-preference llm alignment.arXiv preprint arXiv:2604.05965, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models.arXiv preprint arXiv:2310.13289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
A hybrid dsp/deep learning approach to real-time full-band speech enhance- ment
Jean-Marc Valin. A hybrid dsp/deep learning approach to real-time full-band speech enhance- ment. In2018 IEEE 20th international workshop on multimedia signal processing (MMSP), pages 1–5. IEEE, 2018
2018
-
[47]
Audiobench: A universal benchmark for audio large language models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy Chen. Audiobench: A universal benchmark for audio large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
2025
-
[48]
Supervised speech separation based on deep learning: An overview.IEEE/ACM transactions on audio, speech, and language processing, 26(10):1702– 1726, 2018
DeLiang Wang and Jitong Chen. Supervised speech separation based on deep learning: An overview.IEEE/ACM transactions on audio, speech, and language processing, 26(10):1702– 1726, 2018
2018
-
[49]
ESPnet: End-to-End Speech Processing Toolkit
Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, et al. Espnet: End-to-end speech processing toolkit.arXiv preprint arXiv:1804.00015, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Xlsr-mamba: A dual-column bidirectional state space model for spoofing attack detection.IEEE Signal Processing Letters, 2025
Yang Xiao and Rohan Kumar Das. Xlsr-mamba: A dual-column bidirectional state space model for spoofing attack detection.IEEE Signal Processing Letters, 2025
2025
-
[52]
Adakws: Towards robust keyword spotting with test-time adaptation
Yang Xiao, Tianyi Peng, Yanghao Zhou, and Rohan Kumar Das. Adakws: Towards robust keyword spotting with test-time adaptation. InINTERSPEECH 2025, 2025
2025
-
[53]
Self-training with noisy student improves imagenet classification
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. Self-training with noisy student improves imagenet classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10687–10698, 2020
2020
-
[54]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Air-bench: Benchmarking large audio-language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. Air-bench: Benchmarking large audio-language models via generative comprehension. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1979–1998, 2024
1979
-
[56]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Leveraging llm and text-queried separation for noise-robust sound event detection
Han Yin, Yang Xiao, Jisheng Bai, and Rohan Kumar Das. Leveraging llm and text-queried separation for noise-robust sound event detection. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Satellite Workshop on Speech and Audio Language Models (SALMA), 2024
2025
-
[60]
Han Yin, Yang Xiao, Younghoo Kwon, Ting Dang, and Jung-Woo Choi. Focus then listen: Exploring plug-and-play audio enhancer for noise-robust large audio language models.arXiv preprint arXiv:2603.04862, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Yuanhe Zhang, Jiayu Tian, Yibo Zhang, Shilinlu Yan, Liang Lin, Zhenhong Zhou, Li Sun, and Sen Su. See: Signal embedding energy for quantifying noise interference in large audio language models.arXiv preprint arXiv:2601.07331, 2026
-
[63]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 13 A Related Work Knowledge Distillation and Frontier Self-Distillation.Knowledge distillation minimizes the functional or distributional discrepan...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.