From Accuracy to Auditability: A Survey of Determinism in Financial AI Systems
Pith reviewed 2026-06-30 22:25 UTC · model grok-4.3
The pith
Mechanical nondeterminism from hardware and architecture undermines reproducibility in financial AI systems used for credit, fraud, and AML tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
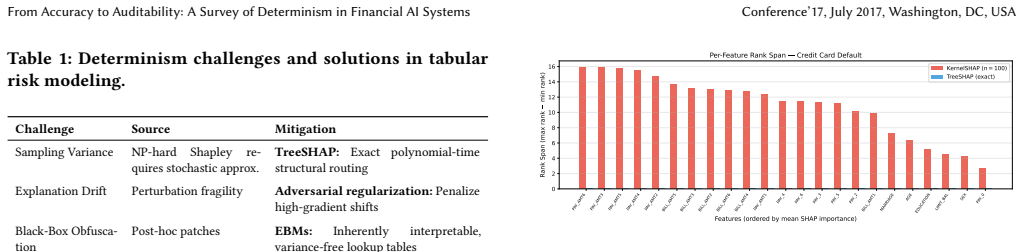
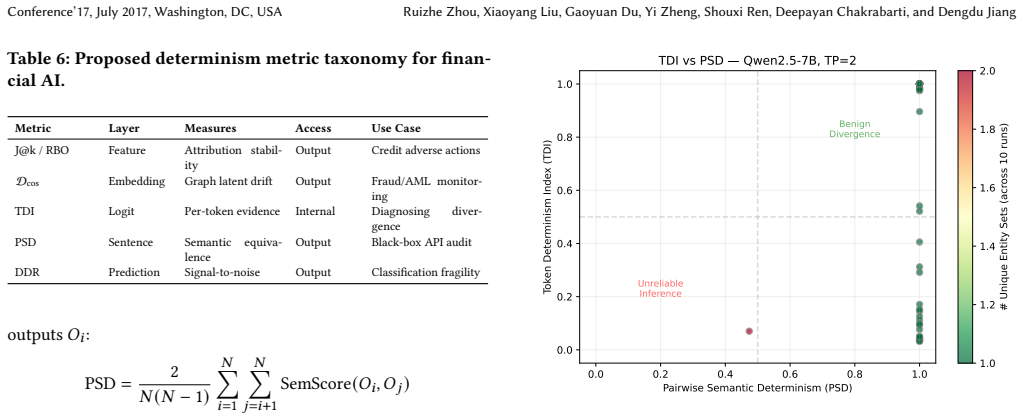
Mechanical nondeterminism rooted in hardware and architecture in deep neural networks and Generative AI has introduced critical vulnerabilities in algorithmic reproducibility across tabular models, graph networks, and LLM-based agentic workflows in financial applications. First-party experiments quantify explanation rank instability in credit scoring, prediction flip rates in GNN-based fraud detection, and tensor-parallel-induced output divergence in LLM entity extraction. A layered evaluation framework is proposed that links modality-specific metrics (RBO, D_cos, TDI, PSD) to audit readiness and validates the complementarity of logit-level and semantic-level determinism measures.
What carries the argument
Layered evaluation framework that maps modality-specific determinism metrics (RBO, D_cos, TDI, PSD) to audit readiness across tabular, graph, and LLM financial AI systems.
If this is right
- Tabular models for credit scoring exhibit unstable post-hoc explanations under nondeterminism.
- Graph networks for fraud detection show measurable prediction flip rates from stochastic sampling and temporal asynchrony.
- LLM-based agentic workflows display batch-dependent divergence and trajectory drift in entity extraction tasks.
- Logit-level and semantic-level measures provide complementary signals for assessing determinism.
- The framework supplies concrete metrics that can be applied to evaluate audit readiness in each modality.
Where Pith is reading between the lines
- Regulators could incorporate determinism testing into model validation requirements for financial AI.
- The same hardware-rooted issues may appear in other regulated domains that use similar model types.
- Practical deployment might require hardware or software constraints to enforce reproducibility where audits are mandatory.
Load-bearing premise
The first-party experiments on public financial datasets and the proposed metrics sufficiently demonstrate the scale of nondeterminism issues and the effectiveness of the layered evaluation framework for real-world regulated financial systems.
What would settle it
An empirical study on regulated financial deployments that finds the quantified nondeterminism levels produce no measurable change in audit outcomes or regulatory compliance would falsify the claim of critical vulnerabilities.
Figures

read the original abstract
Deploying machine learning in regulated financial environments -- credit risk, fraud detection, and anti-money laundering -- exposes critical vulnerabilities in algorithmic reproducibility. While early financial ML addressed statistical challenges such as backtest overfitting, deep neural networks and Generative AI have introduced mechanical nondeterminism rooted in hardware and architecture. This survey provides a systems perspective on reproducibility failures across three modalities now dominant in financial AI: tabular models (post-hoc explanation variance), graph networks (stochastic sampling and temporal asynchrony), and LLM-based agentic workflows (batch-dependent divergence and trajectory drift). We supplement the literature analysis with first-party experiments on public financial datasets -- quantifying explanation rank instability in credit scoring, prediction flip rates in GNN-based fraud detection, and tensor-parallel-induced output divergence in LLM entity extraction. We propose a layered evaluation framework linking modality-specific metrics (RBO, D_cos, TDI, PSD) to audit readiness, and empirically validate the complementarity of logit-level and semantic-level determinism measures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys mechanical nondeterminism in financial AI across tabular models (post-hoc explanation variance), graph networks (stochastic sampling and temporal asynchrony), and LLM-based agentic workflows (batch-dependent divergence and trajectory drift). It supplements the literature review with first-party experiments on public financial datasets that quantify explanation rank instability (RBO), prediction flip rates (D_cos), temporal divergence (TDI), and output divergence (PSD), and proposes a layered evaluation framework that links these modality-specific metrics to audit readiness while claiming empirical validation of the complementarity between logit-level and semantic-level determinism measures.
Significance. If the layered framework and metrics prove effective at quantifying and mitigating reproducibility failures, the work would provide a valuable systems-level contribution toward auditability in regulated financial domains. The survey structure and introduction of concrete metrics (RBO, D_cos, TDI, PSD) offer a structured way to connect hardware/architecture nondeterminism to practical evaluation, which could inform compliance practices if the public-dataset results generalize.
major comments (2)
- [first-party experiments on public financial datasets] First-party experiments section: the reported metric values on public datasets (RBO for credit scoring explanations, D_cos for GNN fraud detection flips, TDI/PSD for LLM divergence) are presented without explicit thresholds, decision-impact analysis, or mapping to regulatory compliance failures (e.g., changes in credit approval or AML alerts), so the central claim of 'critical vulnerabilities' in credit risk, fraud, and AML remains indirect.
- [layered evaluation framework] Layered evaluation framework section: the assertion that the metrics demonstrate complementarity and link to 'audit readiness' lacks quantitative validation against real regulatory constraints or proprietary-scale data (class imbalance, audit thresholds), leaving the framework's practical utility for regulated systems unestablished.
minor comments (1)
- [abstract] The abstract states that the framework is 'empirically validated' but supplies no numerical results, error bars, or dataset details; this should be expanded with concrete findings even in a survey context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our survey of determinism in financial AI systems. We address the two major comments point by point below, clarifying the scope of our public-dataset experiments and the proposed framework while noting inherent limitations of a survey format.
read point-by-point responses
-
Referee: [first-party experiments on public financial datasets] First-party experiments section: the reported metric values on public datasets (RBO for credit scoring explanations, D_cos for GNN fraud detection flips, TDI/PSD for LLM divergence) are presented without explicit thresholds, decision-impact analysis, or mapping to regulatory compliance failures (e.g., changes in credit approval or AML alerts), so the central claim of 'critical vulnerabilities' in credit risk, fraud, and AML remains indirect.
Authors: The experiments quantify mechanical nondeterminism on standard public financial datasets to illustrate the phenomena across modalities, using metrics chosen for their direct interpretability (e.g., RBO capturing explanation rank changes that could affect post-hoc audits). We do not provide explicit thresholds or direct mappings to regulatory outcomes such as credit approval changes because these are institution-specific and would require proprietary decision logs and compliance data unavailable for a survey. The central claim of vulnerabilities is supported by the quantified instability levels on representative data, but we agree the regulatory linkage is indirect. We will add a discussion subsection on potential decision impacts and how practitioners might calibrate thresholds, constituting a partial revision. revision: partial
-
Referee: [layered evaluation framework] Layered evaluation framework section: the assertion that the metrics demonstrate complementarity and link to 'audit readiness' lacks quantitative validation against real regulatory constraints or proprietary-scale data (class imbalance, audit thresholds), leaving the framework's practical utility for regulated systems unestablished.
Authors: Complementarity between logit-level and semantic-level measures is empirically demonstrated via the public-dataset experiments, where the metrics capture orthogonal aspects of divergence. The layered framework provides a conceptual mapping from these metrics to audit readiness as a systems-level proposal. We acknowledge that quantitative validation on proprietary-scale data with real regulatory constraints is not feasible here. We will revise the framework section to explicitly delineate its scope as a proposed structure with public proof-of-concept results rather than a fully validated production tool, constituting a partial revision for added clarity on limitations. revision: partial
- Quantitative validation of the layered framework or metrics against proprietary financial datasets that incorporate actual regulatory thresholds, class imbalance, and audit constraints.
- Direct empirical mapping from observed metric values to specific compliance failures (e.g., changes in AML alerts or credit decisions) without access to internal institutional systems and logs.
Circularity Check
No circularity: survey structure with independent literature review and public-dataset experiments
full rationale
The paper is a literature survey supplemented by first-party experiments on public financial datasets. It defines new metrics (RBO, D_cos, TDI, PSD) and applies them to quantify observed nondeterminism, then links them to an audit framework. No equations or derivations reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims rest on external literature plus reproducible experiments on public data, with no reduction of the 'critical vulnerabilities' claim to author-defined inputs by construction. This is the expected non-finding for a survey paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Managing explanations: how regulators can address AI explainability in Model Risk Management
Bank for International Settlements (BIS). Managing explanations: how regulators can address AI explainability in Model Risk Management . FSI Insights on policy implementation, 2024
2024
-
[2]
Regulation (EU) 2024/1689 laying down har- monised rules on Artificial Intelligence (Artificial Intelligence Act)
European Parliament and Council. Regulation (EU) 2024/1689 laying down har- monised rules on Artificial Intelligence (Artificial Intelligence Act) . Official Journal of the European Union, 2024. From Accuracy to Auditability: A Survey of Determinism in Financial AI Systems Conference’17, July 2017, Washington, DC, USA
2024
-
[3]
Harvey, Yan Liu, and Heqing Zhu
Campbell R. Harvey, Yan Liu, and Heqing Zhu.... and the Cross-Section of Expected Returns. The Review of Financial Studies, 29(1):5–68, 2016
2016
-
[4]
Bailey and Marcos López de Prado.The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting, and Non-Normality
David H. Bailey and Marcos López de Prado.The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting, and Non-Normality. The Journal of Portfolio Management, 40(5):89–107, 2014
2014
-
[5]
Arian et al
H. Arian et al. Backtest overfitting in the machine learning era: A comparison of out-of-sample testing methods. Knowledge-Based Systems, 2024
2024
-
[6]
S. Bhojanapalli et al. On the Reproducibility of Neural Network Predictions . arXiv preprint arXiv:2102.03349, 2021
-
[7]
Detlefsen et al
N. Detlefsen et al. TorchMetrics - Measuring Reproducibility in Deep Learning . Journal of Open Source Software, 7(70):4101, 2022
2022
-
[8]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[9]
Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M
Scott M. Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From Local Explanations to Global Understanding with Explainable AI for Trees . Nature Machine Intelligence, 2(1):56–67, 2020
2020
-
[10]
Intelligible Models for Classification and Regression
Yin Lou, Rich Caruana, and Johannes Gehrke. Intelligible Models for Classification and Regression. Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 150–158, 2012
2012
-
[11]
Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hos- pital 30-day Readmission
Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hos- pital 30-day Readmission. Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 1721–1730, 2015
2015
-
[12]
Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods
Dylan Slack, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods . AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2020
2020
-
[13]
M. Weber et al. Graph Neural Networks for Financial Fraud Detection: A Survey . arXiv preprint arXiv:2411.05815, 2024
-
[14]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive Representation Learning on Large Graphs . Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[15]
Replayable Financial Agents: A Determinism-Faithfulness Assurance Harness for Tool-Using LLM Agents
Raffi Khatchadourian. Replayable Financial Agents: A Determinism-Faithfulness Assurance Harness for Tool-Using LLM Agents . arXiv preprint arXiv:2601.15322, 2026
-
[16]
L. Wang and Y. Wang. Assessing Consistency and Reproducibility in the Outputs of Large Language Models: Evidence Across Diverse Finance and Accounting Tasks . arXiv preprint arXiv:2503.16974, 2025
- [17]
-
[18]
Defeating Nondeterminism in LLM Inference
Thinking Machines Lab. Defeating Nondeterminism in LLM Inference . Technical Report, 2025. https://thinkingmachines.ai/defeating-nondeterminism
2025
-
[19]
En- abling Determinism in LLM Inference with Verified Speculation
Raja Gond, Aditya K Kamath, Ramachandran Ramjee, and Ashish Panwar. En- abling Determinism in LLM Inference with Verified Speculation . arXiv preprint arXiv:2601.17768, 2025
-
[20]
Why Should I Trust You?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "Why Should I Trust You?": Explaining the Predictions of Any Classifier . Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016
2016
-
[21]
Improving KernelSHAP: Practical Shapley Value Estima- tion Using Linear Regression
Ian Covert and Su-In Lee. Improving KernelSHAP: Practical Shapley Value Estima- tion Using Linear Regression . Proceedings of AISTATS (PMLR 130), 2021
2021
-
[22]
A Similarity Measure for Indefinite Rankings
William Webber, Alistair Moffat, and Justin Zobel. A Similarity Measure for Indefinite Rankings. ACM Transactions on Information Systems (TOIS), 28(4):1– 34, 2010
2010
-
[23]
Interpretation of Neural Networks is Fragile
Amirata Ghorbani, Abubakar Abid, and James Zou. Interpretation of Neural Networks is Fragile. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01):3681–3688, 2019
2019
-
[24]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating Text Generation with BERT . International Conference on Learning Representations (ICLR), 2020
2020
-
[25]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. International Conference on Learning Representations (ICLR), 2017
2017
-
[26]
Pitfalls of Graph Neural Network Evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of Graph Neural Network Evaluation . NeurIPS Relational Representation Learning Workshop, 2018. arXiv:1811.05868
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. Temporal Graph Networks for Deep Learning on Dynamic Graphs. ICML Workshop on Graph Representation Learning, 2020
2020
-
[28]
Fast Graph Representation Learning with PyTorch Geometric
Matthias Fey and Jan Eric Lenssen. Fast Graph Representation Learning with PyTorch Geometric. ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019
2019
-
[29]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAt- tention: Fast and Memory-Efficient Exact Attention with IO-A wareness. Advances in Neural Information Processing Systems (NeurIPS), 35, 2022
2022
-
[30]
Huang, Hui Wang, and Yi Yang
Allen H. Huang, Hui Wang, and Yi Yang. FinBERT: A Large Language Model for Extracting Information from Financial Text . Contemporary Accounting Research, 40(2):806–841, 2023
2023
-
[31]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models . International Conference on Learning Representations (ICLR), 2023
2023
-
[32]
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
Boxin Wang, Chankyu Lee, Nayeon Lee, Sheng-Chieh Lin, Wenliang Dai, Yang Chen, Yangyi Chen, Zhuolin Yang, Zihan Liu, Mohammad Shoeybi, Bryan Catan- zaro, and Wei Ping. Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models . arXiv preprint arXiv:2512.13607, 2025
-
[33]
LLM Output Drift: Cross-Provider Validation & Mitigation for Financial Workflows
Raffi Khatchadourian and Rolando Franco. LLM Output Drift: Cross-Provider Validation & Mitigation for Financial Workflows. arXiv preprint arXiv:2511.07585, 2025
-
[34]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf.Efficient Guided Generation for Large Language Models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
SHAP Stability in Credit Risk Management: A Case Study in Credit Card Default Model
Liang Lin and Yue Wang. SHAP Stability in Credit Risk Management: A Case Study in Credit Card Default Model . Risks, 2025. arXiv:2508.01851
-
[36]
Benoit.Evaluating the Stability of Model Explanations in Instance-Dependent Cost-Sensitive Credit Scoring
Matteo Ballegeer, Matthias Bogaert, and Dries F. Benoit.Evaluating the Stability of Model Explanations in Instance-Dependent Cost-Sensitive Credit Scoring . European Journal of Operational Research, 326(3), 2025
2025
-
[37]
Deterministic Inference across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch
Ziyang Zhang, Xinheng Ding, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, and Zirui Liu. Deterministic Inference across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch. arXiv preprint arXiv:2511.17826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
STED and Consistency Scoring: A Framework for Evaluating LLM Structured Output Reliability
Guanchen Wang et al. STED and Consistency Scoring: A Framework for Evaluating LLM Structured Output Reliability . NeurIPS Workshop, 2025. arXiv:2512.23712
-
[39]
AEMA: Verifiable Evaluation Framework for Trustworthy and Controlled Agentic LLM Systems
Yu-Ting Lee et al. AEMA: Verifiable Evaluation Framework for Trustworthy and Controlled Agentic LLM Systems . arXiv preprint arXiv:2601.11903, 2026
-
[40]
Bruno Deprez, Toon Vanderschueren, Bart Baesens, Tim Verdonck, and Wouter Verbeke. Network Analytics for Anti-Money Laundering – A Systematic Literature Review and Experimental Evaluation . INFORMS Journal on Data Science, 2024. arXiv:2405.19383
-
[41]
Dang Sy Duy, Nguyen Duy Chien, Kapil Dev, and Jeff Nijsse. Normalisation and Initialisation Strategies for Graph Neural Networks in Blockchain Anomaly Detection. arXiv preprint arXiv:2602.23599, 2026
-
[42]
Jsonschemabench: A rigorous benchmark of structured outputs for language models
Derek Tam et al. Generating Structured Outputs from Language Models . arXiv preprint arXiv:2501.10868, 2025
-
[43]
Estimating LLM Uncertainty with Logits
Shuo Chen, Tian Dong, Jiaqi Wang, and Dieter Fox. Estimating LLM Uncertainty with Logits. Proceedings of the International Conference on Machine Learning (ICML), 2025. arXiv:2502.00290
-
[44]
Towards Mod- eling Data Quality and Machine Learning Model Performance
Usman Anjum, Chris Trentman, Elrod Caden, and Justin Zhan. Towards Mod- eling Data Quality and Machine Learning Model Performance . arXiv preprint arXiv:2412.05882, 2024
-
[45]
Arik and Tomas Pfister.TabNet: Attentive Interpretable Tabular Learning
Sercan Ö. Arik and Tomas Pfister.TabNet: Attentive Interpretable Tabular Learning. Proceedings of the AAAI Conference on Artificial Intelligence, 35(8):6679–6687, 2021
2021
-
[46]
Hamilton, and Jure Leskovec
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. Graph Convolutional Neural Networks for Web-Scale Recom- mender Systems. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 974–983, 2018
2018
-
[47]
Effi- cient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Effi- cient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM . Proceedings of the International Conference for High Perfor...
2021
-
[48]
SemScore: Automated Evaluation of Instruction-Tuned LLMs based on Semantic Textual Similarity
Ansar Aynetdinov and Alham Fikri Aji. SemScore: Automated Evaluation of Instruction-Tuned LLMs based on Semantic Textual Similarity . arXiv preprint arXiv:2401.17072, 2024. A LOGU UNCERTAINTY DECOMPOSITION LogU [43] treats the top-𝐾 logits as Dirichlet parametersDir(𝛼1, . . . , 𝛼𝐾 ). The aleatoric uncertainty (AU) captures relative entropy:AU(𝑎𝑡 ) = −Í𝐾 𝑘...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.