AI in the Enterprise: How People Use M365 Copilot Chat
Pith reviewed 2026-06-30 22:02 UTC · model grok-4.3
The pith
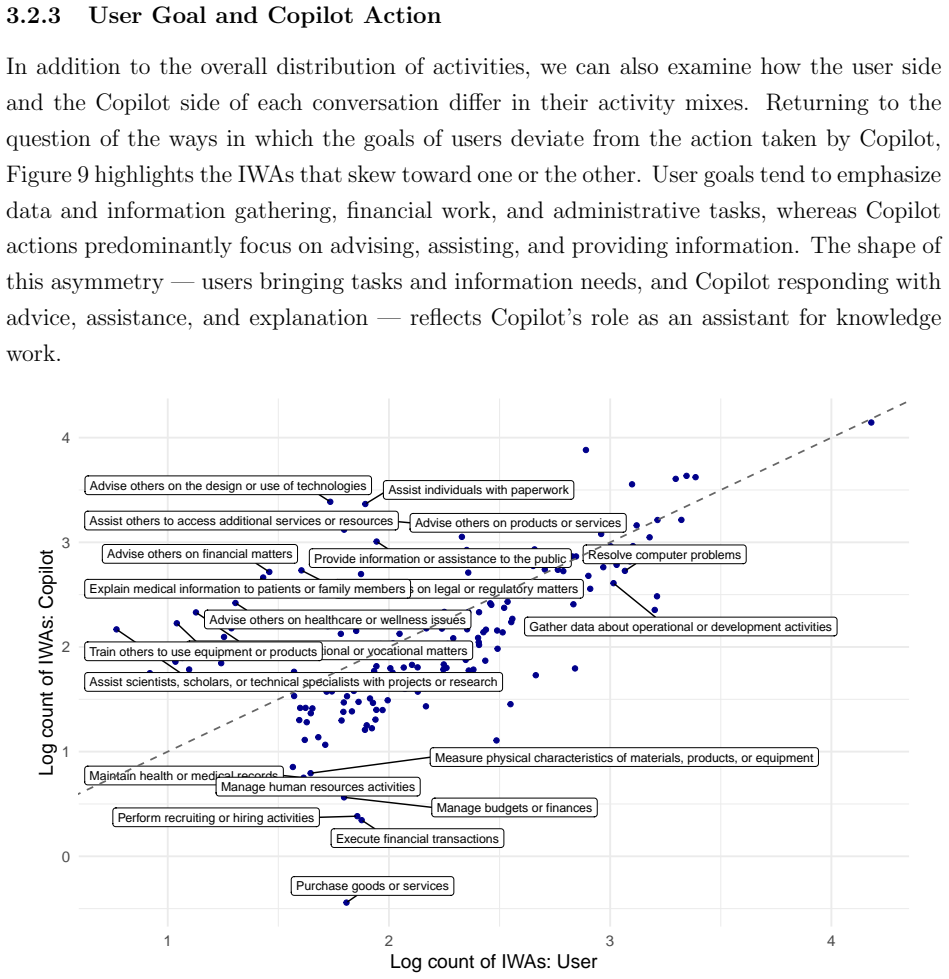
M365 Copilot Chat functions as an everyday assistant for knowledge work where writing leads and search use declines over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
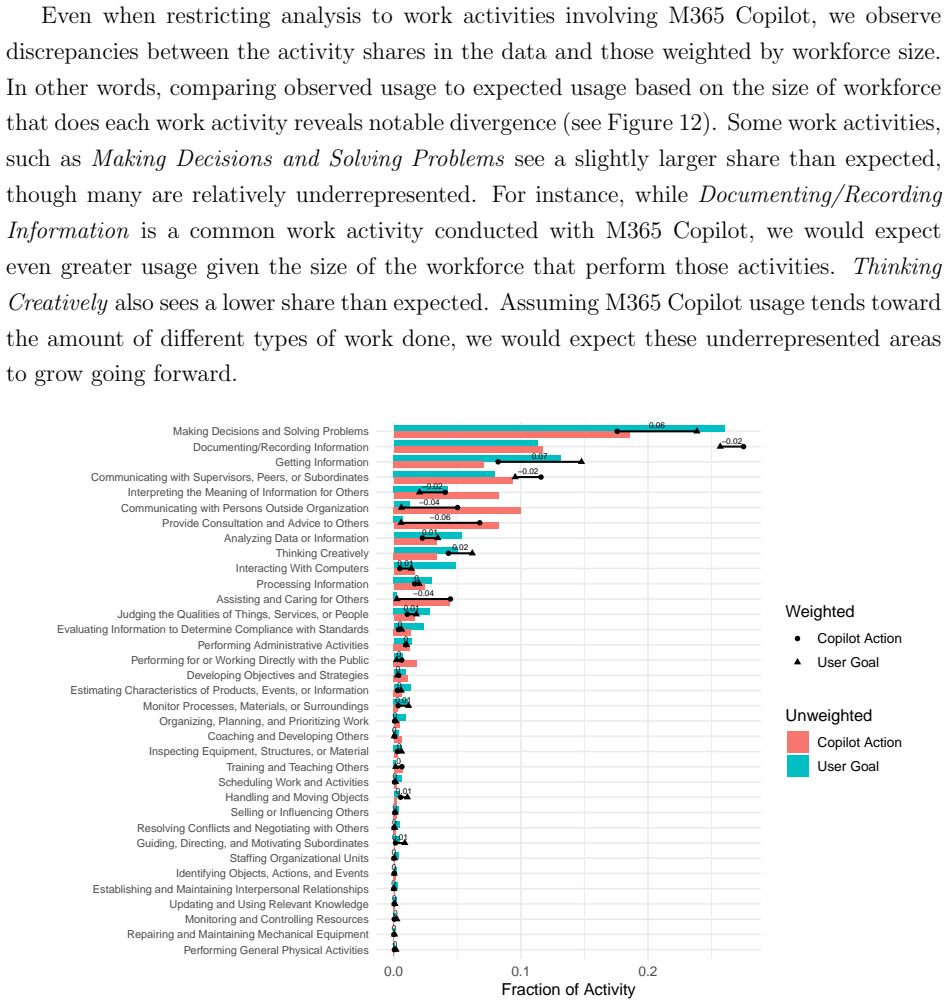
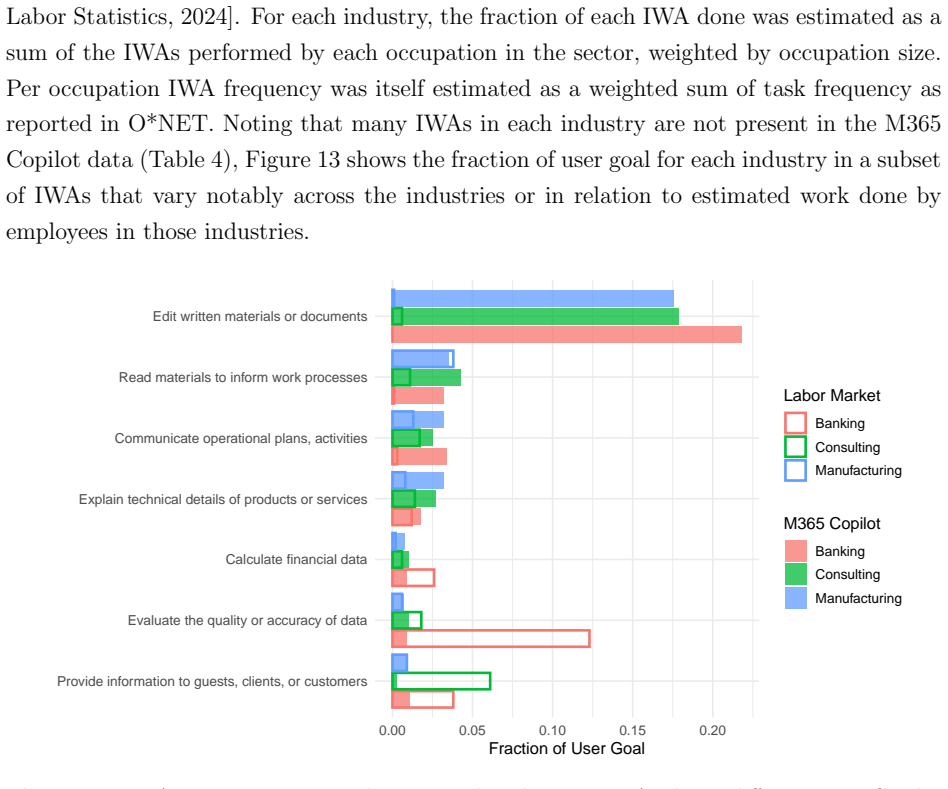
Based on direct classification of approximately 5.5 million sessions, M365 Copilot Chat supports a range of knowledge work activities with writing as the primary use, substantial reliance on information retrieval and analysis, and a measurable shift over time from chat-as-search toward content creation and communication. Patterns differ across occupational groups and diverge from standard labor market distributions in some activities.
What carries the argument
Learned classification of user intent from chat sessions combined with O*NET work activity mapping.
If this is right
- Writing tasks form the core use case for this class of enterprise AI.
- Information-seeking interactions are common but lose relative share to content and communication work.
- Usage cuts across some jobs while remaining tied to others, creating both broad and specialized patterns.
- Work activities underrepresented in current usage indicate the next areas for enterprise AI expansion.
Where Pith is reading between the lines
- Design of future assistants could prioritize features that support the observed shift to content creation.
- Occupational differences may require profession-specific prompting or integration options.
- The data could be used to model which work activities are most ready for AI augmentation.
Load-bearing premise
The automated intent classification from chat logs accurately reflects users' real goals and the sampled sessions represent typical usage across the companies involved.
What would settle it
A controlled comparison where users directly report their goal for each session and the reports are matched against the model's classifications, or a replication study on sessions from a new set of companies that shows substantially different activity shares or time trends.
Figures
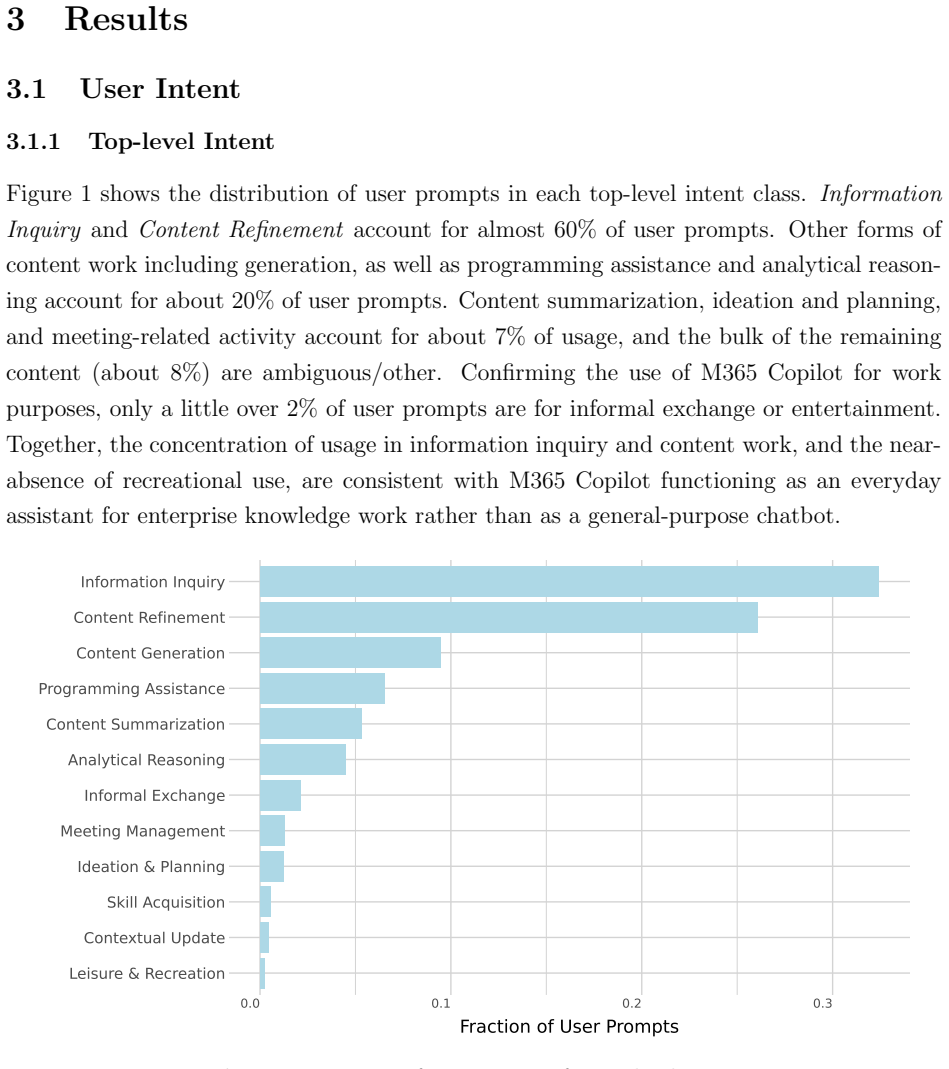
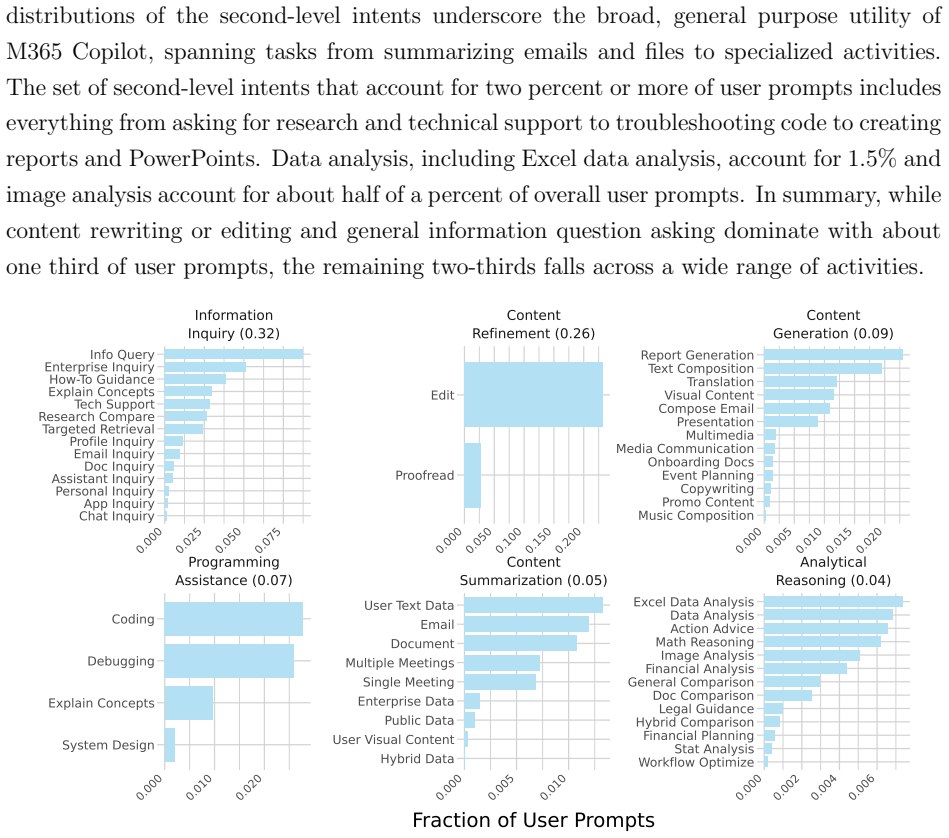
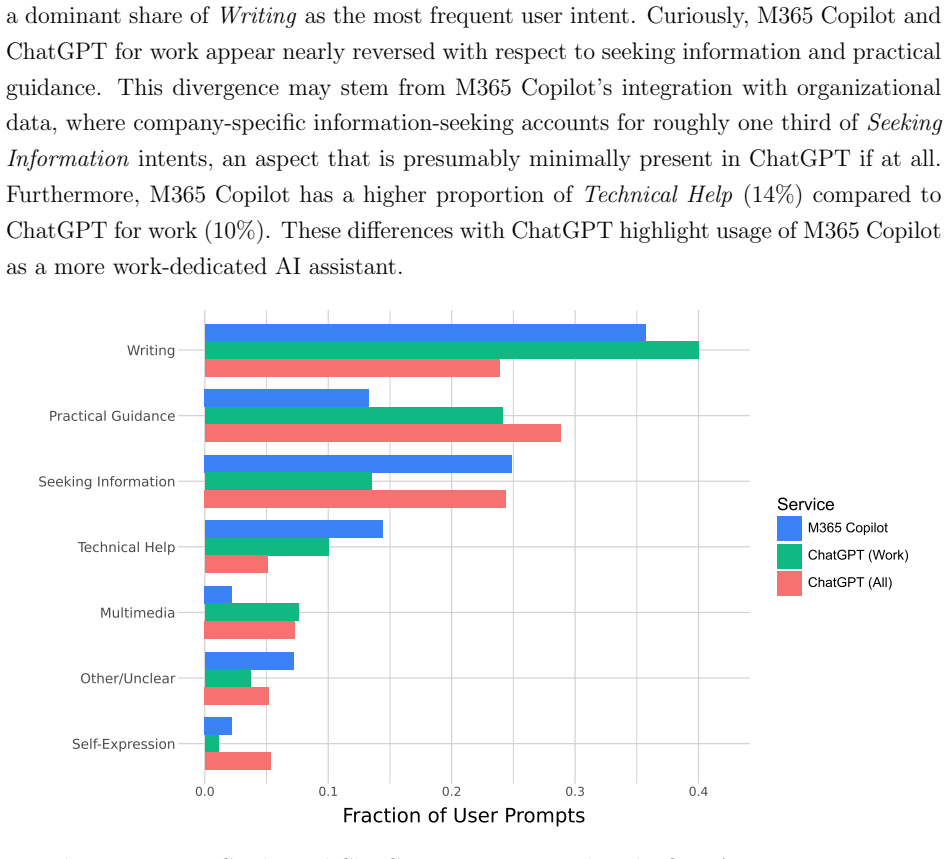
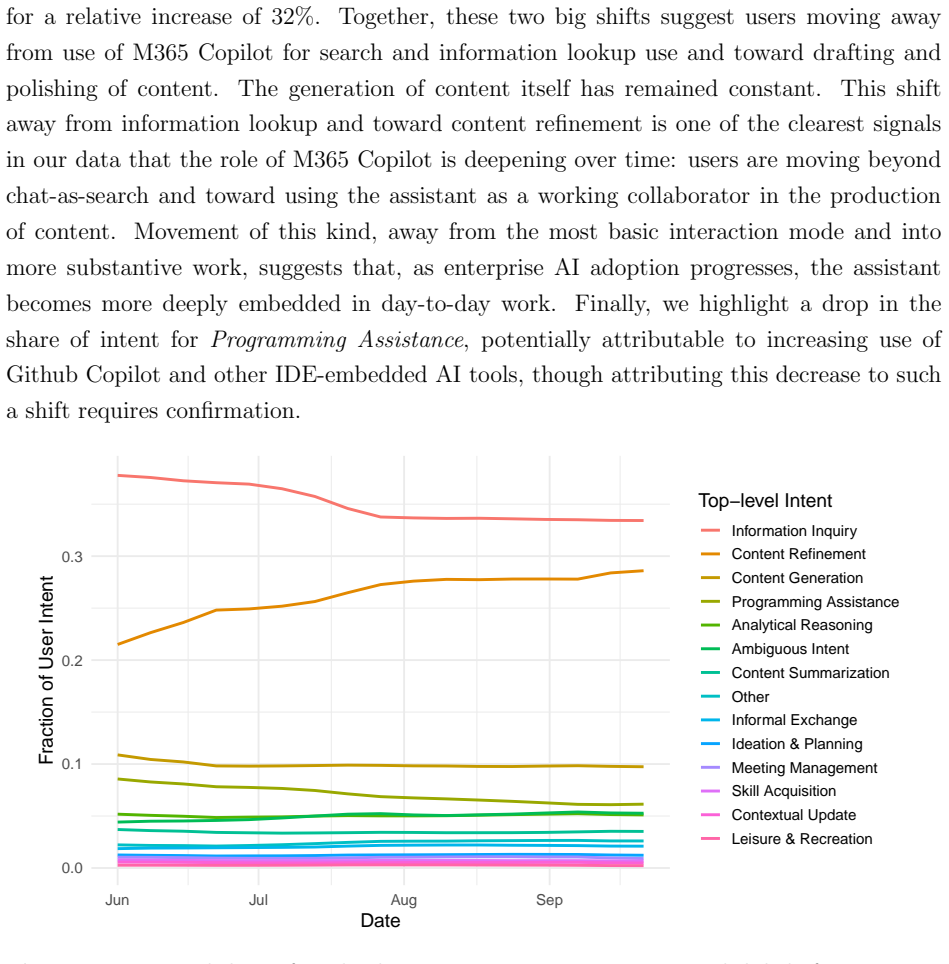

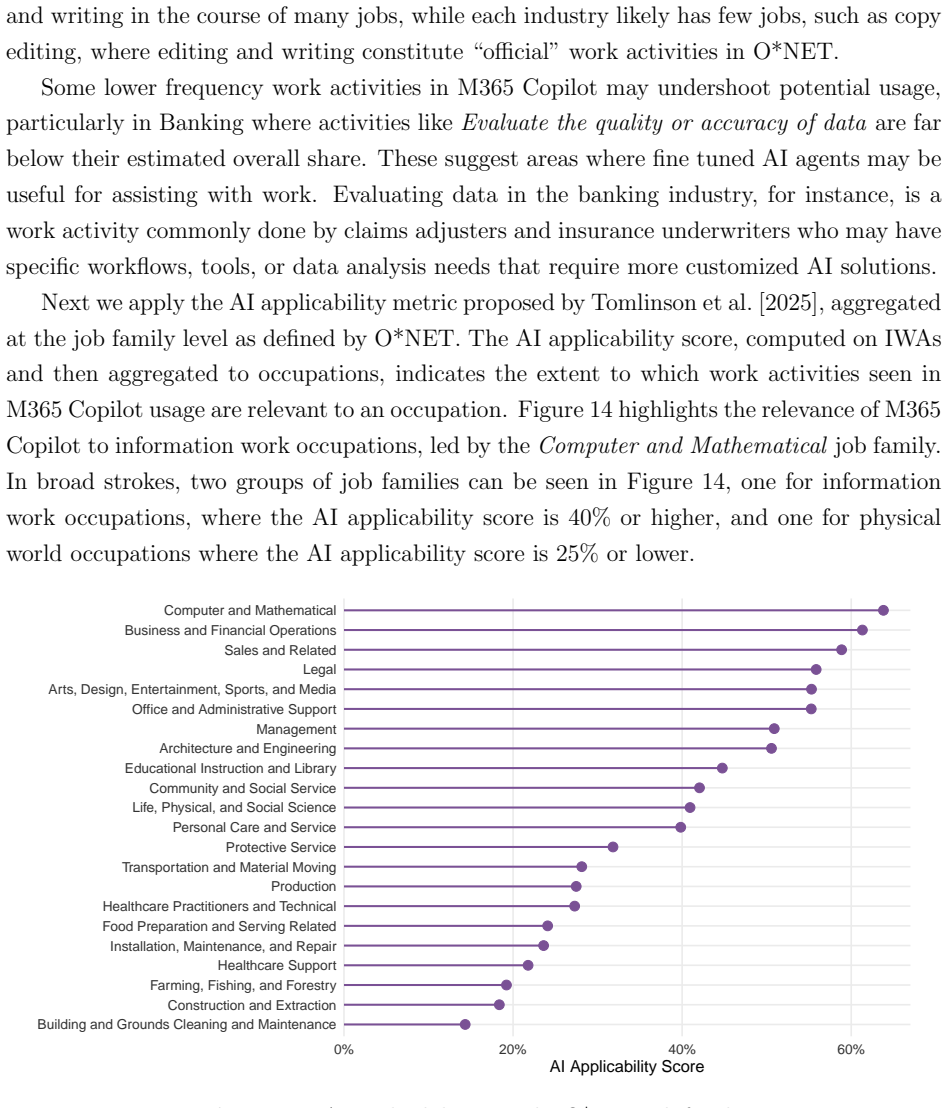

read the original abstract
M365 Copilot is used every week by millions of people across more than a million companies around the world as part of their workflows. Uniquely positioned in the AI landscape given its near-exclusive use for work purposes, M365 Copilot can offer a clear picture of how people use AI for work and where that usage may expand next. This paper characterizes that usage through direct classification of user interactions with M365 Copilot Chat. Based on an anonymized and privacy-preserving analysis of a sample of approximately 5.5 million sessions, we combine a learned classification of user intent with a classification of O*NET work activities done with M365 Copilot Chat. We find that M365 Copilot is emerging as an everyday assistant for knowledge work: writing dominates, but users also rely on it for information retrieval, analysis, decision making and strategizing, and evaluating and diagnosing programs and systems, among others. Information seeking tasks remain common, but time trends suggest a relative shift away from ``chat as search'' and toward content and communication-related work. Comparisons across occupational groupings and to work done in the labor market further show that usage is broad but uneven, where the relative share of work done with M365 Copilot Chat cuts across jobs in some cases and is occupation-specific in others. Areas of relative underrepresentation in the labor market suggest the next frontier for enterprise AI adoption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes a sample of approximately 5.5 million anonymized M365 Copilot Chat sessions using a learned intent classifier combined with O*NET work activity mappings. It claims that writing dominates usage for knowledge work, information-seeking tasks are common but declining relatively over time in favor of content and communication tasks, and usage is broad but uneven across occupational groups, with implications for future enterprise AI adoption.
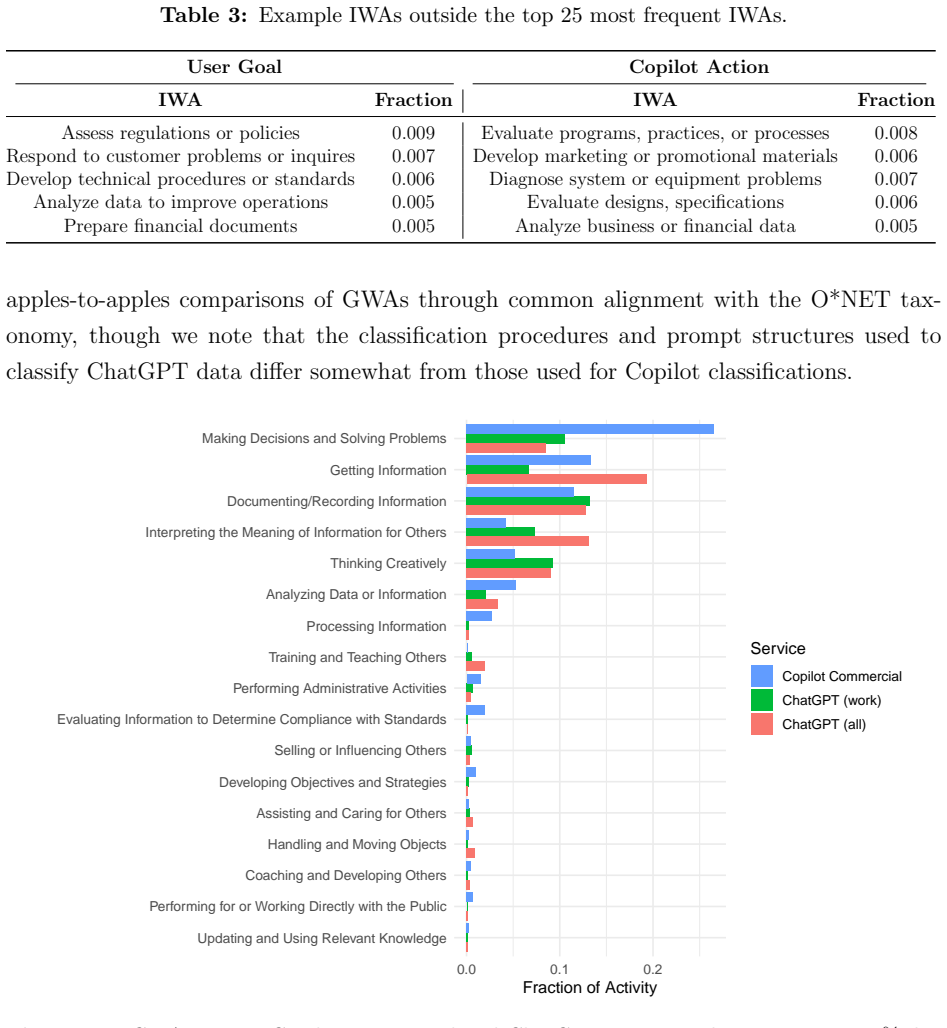
Significance. If the intent classification is shown to be reliable, the study would provide one of the largest-scale empirical characterizations of real-world enterprise generative AI usage, enabling direct comparisons to labor-market task distributions via O*NET and highlighting adoption gaps.
major comments (2)
- [Methods] Methods section (classification procedure): the abstract states that results rest on a 'learned classification of user intent' applied to 5.5M sessions, yet no training data description, model details, human validation metrics (precision, recall, F1, inter-annotator agreement), or error analysis are supplied. Because every reported proportion, time trend, and occupational comparison derives from these labels, the absence of validation metrics renders the central empirical claims impossible to assess for bias or accuracy.
- [Data] Data and sample section: the paper asserts the 5.5M sessions are drawn from usage across more than a million companies and are representative, but provides no information on sampling frame, inclusion/exclusion criteria, stratification by company size or role, or checks for selection bias. This directly undermines the generalizability of the 'broad but uneven' usage findings and the labor-market comparisons.
minor comments (1)
- [Abstract] Abstract: the phrase 'learned classification' is introduced without any accompanying performance qualifier, which could be clarified in one sentence to help readers immediately gauge the evidential basis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional transparency is needed to support the paper's claims. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods] Methods section (classification procedure): the abstract states that results rest on a 'learned classification of user intent' applied to 5.5M sessions, yet no training data description, model details, human validation metrics (precision, recall, F1, inter-annotator agreement), or error analysis are supplied. Because every reported proportion, time trend, and occupational comparison derives from these labels, the absence of validation metrics renders the central empirical claims impossible to assess for bias or accuracy.
Authors: We agree that the absence of these details in the current manuscript is a significant limitation that prevents readers from evaluating the reliability of the intent labels. The referee's point is correct. In the revised version we will expand the methods section with a description of the training data, model architecture and training procedure, human validation metrics (precision, recall, F1), inter-annotator agreement, and an error analysis to the extent permitted by data-access constraints. revision: yes
-
Referee: [Data] Data and sample section: the paper asserts the 5.5M sessions are drawn from usage across more than a million companies and are representative, but provides no information on sampling frame, inclusion/exclusion criteria, stratification by company size or role, or checks for selection bias. This directly undermines the generalizability of the 'broad but uneven' usage findings and the labor-market comparisons.
Authors: The referee correctly identifies that the data section provides insufficient information on sampling and potential biases. We will revise the section to add available details on the sampling frame, inclusion/exclusion criteria, and any representativeness checks. Full stratification information by company size or role cannot be disclosed due to privacy and enterprise confidentiality agreements; we will explicitly note this limitation and its implications for generalizability. revision: partial
- Complete disclosure of the full sampling frame, company-level stratification, and certain model-training details due to binding privacy and confidentiality constraints on enterprise usage data.
Circularity Check
No circularity: purely empirical analysis of usage data
full rationale
The paper performs direct classification of 5.5M anonymized sessions via a learned intent model mapped to external O*NET work activities, then reports observed distributions and trends. No equations, fitted parameters relabeled as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. All claims rest on observable session data and an independent taxonomy rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Intent classification model parameters
axioms (1)
- domain assumption O*NET taxonomy provides a valid categorization of work activities performed with AI tools
Reference graph
Works this paper leans on
-
[1]
Accessed: 2025-10-05
URLhttps://www.anthropic.com/research/ anthropic-economic-index-september-2025-report. Accessed: 2025-10-05. Ruth Appel, Maxim Massenkoff, Peter McCrory, Miles McCain, Ryan Heller, Tyler Neylon, and Alex Tamkin. Anthropic economic index report: eco- nomic primitives,
2025
-
[2]
Alexander Bick, Adam Blandin, and David J Deming
URLhttps://www.anthropic.com/research/ anthropic-economic-index-january-2026-report. Alexander Bick, Adam Blandin, and David J Deming. The rapid adoption of generative AI. Management Science,
2026
-
[3]
doi: 10.1287/mnsc.2025.02523. Timothy F Bresnahan and Manuel Trajtenberg. General purpose technologies: “engines of growth”?Journal of Econometrics, 65(1):83–108,
-
[4]
26 Accessed: 2025-10-12
URLhttps://www.wsj.com/opinion/ ais-overlooked-97-billion-contribution-to-the-economy-users-service-da6e8f55. 26 Accessed: 2025-10-12. Kevin Zheyuan Cui, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers.Management Science,
2025
-
[5]
Early impacts of M365 Copilot.arXiv preprint arXiv:2504.11443,
Eleanor Wiske Dillon, Sonia Jaffe, Sida Peng, and Alexia Cambon. Early impacts of M365 Copilot.arXiv preprint arXiv:2504.11443,
-
[6]
Troy, Dario Amodei, Jared Kaplan, Jack Clark, and Deep Ganguli
Kunal Handa, Alex Tamkin, Miles McCain, Saffron Huang, Esin Durmus, Sarah Heck, Jared Mueller, Jerry Hong, Stuart Ritchie, Tim Belonax, Kevin K. Troy, Dario Amodei, Jared Kaplan, Jack Clark, and Deep Ganguli. Which economic tasks are performed with AI? evidence from millions of Claude conversations. arXiv:2503.04761 [cs.CY],
-
[7]
Accessed: 2025-10-12
URLhttps://www.microsoft.com/en-us/research/wp-content/uploads/ 2024/07/Generative-AI-in-Real-World-Workplaces.pdf. Accessed: 2025-10-12. Maxim Massenkoff, Eva Lyubich, Peter McCrory, Ruth Appel, and Ryan Heller. An- thropic economic index report: Learning curves,
2024
-
[8]
com/research/economic-index-march-2026-report
URLhttps://www.anthropic. com/research/economic-index-march-2026-report. Microsoft. AI diffusion report: Where AI is most used, developed, and built. Techni- cal report, Microsoft Corporation,
2026
-
[9]
Ac- cessed: 2025-11-06
URLhttps://www.microsoft.com/en-us/ research/wp-content/uploads/2025/10/Microsoft-AI-Diffusion-Report.pdf. Ac- cessed: 2025-11-06. Amit Misra, Jane Wang, Scott McCullers, Kevin White, and Juan Lavista Ferres. Measuring AI diffusion: A population-normalized metric for tracking global AI usage,
2025
-
[10]
National Center for O*NET Development
URL https://arxiv.org/abs/2511.02781. National Center for O*NET Development. O*NET Database Version 29.0,
-
[11]
Accessed: 2025-05-29
URL https://www.onetcenter.org/db_releases.html. Accessed: 2025-05-29. Shakked Noy and Whitney Zhang. Experimental evidence on the productivity effects of generative artificial intelligence.Science, 381(6654):187–192,
2025
-
[12]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
URLhttps: //www.gallup.com/workplace/691643/work-nearly-doubled-two-years.aspx. Ac- cessed: 2025-10-19. Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. The impact of AI on developer productivity: Evidence from GitHub copilot.arXiv preprint arXiv:2302.06590,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Working with AI: Measuring the applicability of AI to occupations
Kiran Tomlinson, Sonia Jaffe, Will Wang, Scott Counts, and Siddharth Suri. Working with AI: Measuring the applicability of AI to occupations. arXiv:2507.07935 [cs.AI],
-
[14]
Bureau of Labor Statistics
U.S. Bureau of Labor Statistics. Occupational Employment and Wage Statistics (OEWS), May 2024,
2024
-
[15]
Accessed: 2025-05-29
URLhttps://www.bls.gov/oes/tables.htm. Accessed: 2025-05-29. Mengting Wan, Tara Safavi, Sujay Kumar Jauhar, Yujin Kim, Scott Counts, Jen- nifer Neville, Siddharth Suri, Chirag Shah, Ryen W. White, Longqi Yang, Reid Andersen, Georg Buscher, Dhruv Joshi, and Nagu Rangan. Tnt- llm: Text mining at scale with large language models. InKDD, March
2025
-
[16]
28 A Figures & Tables 0.0000.0250.0500.075 Chat Inquiry App Inquiry Personal Inquiry Assistant Inquiry Doc Inquiry Email Inquiry Profile Inquiry T argeted Retrieval Research Compare T ech Support Explain Concepts How-T o Guidance Enterprise Inquiry Info Query 0.0000.0500.1000.1500.200 Proofread Edit 0.0000.0050.0100.0150.020 Music Composition Promo Conten...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.