AERIC: Anticipatory Hidden-State Monitoring for Implicit Harmful Dialogue
Pith reviewed 2026-06-30 21:25 UTC · model grok-4.3
The pith
A 387-parameter linear head reading hidden states during ordinary decoding can anticipate implicit harmful drift in language model outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
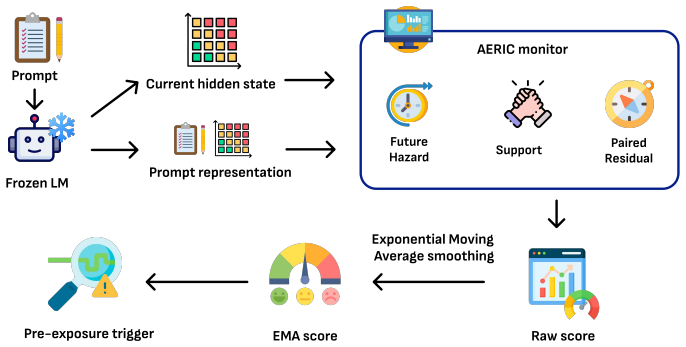
AERIC shows that a linear monitor with 387 trainable parameters, applied to hidden states under ordinary decoding, raises AUROC from 0.6830 to 0.7143 on DiaSafety and from 0.8219 to 0.8582 on Harmful Advice relative to Qwen3GuardStream-4B. Under a 10% safe-trigger budget it reaches trigger@64 rates of 0.6438 and 0.4656 on HarmBench DirectRequest and 0.6849 and 0.7363 on SocialHarmBench for two base models, while increasing mean latency by only 2.34% on a fixed-generation benchmark.
What carries the argument
The same-pass exponential moving average decision rule applied to a linear head that combines short-horizon hazard forecasting, support-sensitive suppression, and prompt-conditioned residual scoring.
If this is right
- Safety intervention can occur after fewer generated tokens than response-level methods require.
- The same monitor works across different base models without retraining the full system.
- Trigger decisions remain stable when the safe-trigger rate is capped at 10% of outputs.
- Mean added latency stays under 3% on fixed-length harmful-prompt generations.
Where Pith is reading between the lines
- The same hidden-state signal might be reused to forecast other forms of drift such as factual inconsistency or style shift.
- Calibration on one model family may transfer to larger models if the linear head is kept fixed and only the threshold is retuned.
- If the 387-parameter head generalizes, it could be attached to any decoder-only model as a lightweight safety layer during inference.
Load-bearing premise
Hidden states produced during ordinary decoding already contain enough anticipatory information about future harmful drift for a linear head to extract it without extra context or passes.
What would settle it
On a held-out set of prompts that produce initially safe-looking text but later turn harmful, the linear head's AUROC falls to or below the streaming baseline while the measured latency overhead stays above 5%.
Figures

read the original abstract
Current language models create two safety challenges: risk must be detected early enough to avoid exposing harmful continuation, and the harmfulness itself may be implicit rather than signaled by overtly toxic text. Existing response-level guards are strong at judging completed text, and native streaming guards move closer to token time, but both settings leave open whether a lightweight monitor can anticipate implicit harmful drift from the generator's own internal trajectory. We study anticipatory same-pass monitoring, where a safety monitor may read hidden states produced during ordinary decoding but may not invoke an additional forward pass through the base model. We introduce AERIC, a transfer-oriented hidden-state approach for implicit harmful dialogue that combines short-horizon hazard forecasting, support-sensitive suppression, and prompt-conditioned residual scoring under a same-pass exponential moving average decision rule. The default linear monitor contains only 387 trainable head parameters. Against Qwen3GuardStream-4B on balanced benchmarks, AERIC improves AUROC from 0.6830 to 0.7143 on DiaSafety and from 0.8219 to 0.8582 on Harmful Advice. For promptlevel trigger benchmarks, we calibrate the AERIC threshold by a source-side safe-budget rule that maximizes trigger coverage while constraining the safe-trigger rate to at most 10%. Under that rule, trigger@64 reaches 0.6438 and 0.4656 on HarmBench DirectRequest and 0.6849 and 0.7363 on SocialHarmBench for Qwen and Gemma, respectively, withholding between 23.53 and 41.86 answer tokens on average. Same-pass deployment is also efficient: on a 63-prompt harmfulprompt fixed-generation benchmark aggregated over HarmBench DirectRequest and SocialHarmBench under Qwen3-8B, the monitor increases mean latency by only 2.34%, whereas Qwen3Guard-Stream-4B increases it by 79.40%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AERIC, a transfer-oriented hidden-state monitor for anticipatory detection of implicit harmful dialogue. It attaches a 387-parameter linear head to hidden states generated during ordinary autoregressive decoding (no extra forward pass) and combines short-horizon hazard forecasting, support-sensitive suppression, and prompt-conditioned residual scoring under a same-pass EMA decision rule. Against Qwen3GuardStream-4B it reports AUROC gains of 0.0313 on DiaSafety and 0.0363 on Harmful Advice; under a 10% safe-trigger budget it reports trigger@64 values of 0.6438/0.4656 on HarmBench DirectRequest and 0.6849/0.7363 on SocialHarmBench while adding only 2.34% mean latency.
Significance. If the central claim holds—that hidden states produced in standard decoding already contain extractable anticipatory signal about implicit harmful drift that a linear probe can read without richer context or an extra pass—this would be a meaningful advance for practical LLM safety. The same-pass efficiency, sub-400-parameter overhead, and explicit latency comparison are concrete strengths that would matter for deployment. The post-hoc safe-budget calibration and the reported trigger@64 numbers would also be useful if the underlying signal is shown to be robustly anticipatory rather than correlated with already-generated tokens.
major comments (3)
- [Abstract] Abstract: the central claim that hidden states generated during ordinary decoding contain usable anticipatory information about implicit harmful drift is load-bearing, yet the supplied text provides no derivation, ablation, or empirical test demonstrating that the signal precedes harmful tokens rather than being correlated with tokens already emitted. Without such evidence the reported AUROC gains and the same-pass efficiency advantage both rest on an unverified assumption.
- [Abstract] Abstract: the 10% safe-trigger budget rule used to calibrate the threshold and produce the trigger@64 numbers is described only at high level; no equation or procedure is given for how the constraint is enforced or how it interacts with the EMA decision rule, making it impossible to assess whether the reported trigger@64 improvements are robust or an artifact of post-hoc selection.
- [Abstract] Abstract: no ablation, error analysis, or comparison against non-linear heads or richer context is supplied to show that the 387-parameter linear monitor is sufficient; if the anticipatory signal requires non-linear features or future tokens, both the performance claims and the efficiency advantage collapse.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for stronger substantiation of the anticipatory claim, calibration procedure, and head design. We respond point-by-point below and will incorporate clarifications and additional analyses in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that hidden states generated during ordinary decoding contain usable anticipatory information about implicit harmful drift is load-bearing, yet the supplied text provides no derivation, ablation, or empirical test demonstrating that the signal precedes harmful tokens rather than being correlated with tokens already emitted. Without such evidence the reported AUROC gains and the same-pass efficiency advantage both rest on an unverified assumption.
Authors: We agree that an explicit demonstration of temporal precedence is necessary to support the anticipatory framing. The short-horizon hazard forecasting component is constructed to predict harm several tokens ahead from the current hidden state; the reported trigger@64 results (withholding 23–42 tokens on average) provide indirect evidence that detections occur before full harmful continuations are emitted. To strengthen this, we will add (i) a formal derivation of the forecasting objective and (ii) a lead-time analysis measuring the average number of tokens between first detection and the onset of harmful content in the revised methods and experiments sections. revision: yes
-
Referee: [Abstract] Abstract: the 10% safe-trigger budget rule used to calibrate the threshold and produce the trigger@64 numbers is described only at high level; no equation or procedure is given for how the constraint is enforced or how it interacts with the EMA decision rule, making it impossible to assess whether the reported trigger@64 improvements are robust or an artifact of post-hoc selection.
Authors: The calibration is performed by selecting the EMA threshold that maximizes trigger coverage on a held-out safe set while enforcing a safe-trigger rate of at most 10%. We will revise the abstract and add an explicit optimization formulation together with pseudocode showing how the threshold is chosen and how it interacts with the EMA update in the main experimental setup section. revision: yes
-
Referee: [Abstract] Abstract: no ablation, error analysis, or comparison against non-linear heads or richer context is supplied to show that the 387-parameter linear monitor is sufficient; if the anticipatory signal requires non-linear features or future tokens, both the performance claims and the efficiency advantage collapse.
Authors: The linear head was chosen to minimize overhead while still achieving the reported AUROC gains. We acknowledge the absence of a direct non-linear comparison. In the revision we will add an ablation that replaces the linear head with a small two-layer MLP (approximately 2 k parameters) and reports the resulting AUROC and latency deltas on the same benchmarks, allowing readers to evaluate whether the linear probe is sufficient for the observed gains. revision: yes
Circularity Check
No circularity detected: paper presents empirical results with no visible derivation chain or equations
full rationale
The supplied manuscript text is limited to the abstract and contains no equations, derivation steps, or self-citations. The central claim consists of reported AUROC and trigger@64 improvements from a 387-parameter linear head applied to hidden states during ordinary decoding. Because no mathematical reduction, fitted-input prediction, or load-bearing self-citation is present, the result cannot be shown to collapse to its inputs by construction. This is the expected honest non-finding when the text supplies no derivation chain to inspect.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden states during ordinary decoding contain anticipatory information about implicit harmful drift
Reference graph
Works this paper leans on
-
[1]
From Judgment to Interfer- ence: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring, September
Yang Li, Qiang Sheng, Yehan Yang, Xueyao Zhang, and Juan Cao. From Judgment to Interfer- ence: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring, September
- [2]
-
[3]
Predict, Don't React: Value-Based Safety Forecasting for LLM Streaming
Pride Kavumba, Koki Wataoka, Huy H. Nguyen, Jiaxuan Li, and Masaya Ohagi. Predict, Don’t React: Value-Based Safety Forecasting for LLM Streaming, April 2026. URL http: //arxiv.org/abs/2604.03962. arXiv:2604.03962 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
ShieldHead: Decoding-time Safeguard for Large Language Models
Zitao Xuan, Xiaofeng Mao, Da Chen, Xin Zhang, Yuhan Dong, and Jun Zhou. ShieldHead: Decoding-time Safeguard for Large Language Models. In Wanxiang Che, Joyce Nabende, Ekate- rina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computa- tional Linguistics: ACL 2025, pages 18129–18143, Vienna, Austria, July 2025. Association fo...
-
[5]
Mitigating Covertly Unsafe Text within Natural Language Systems
Alex Mei, Anisha Kabir, Sharon Levy, Melanie Subbiah, Emily Allaway, John Judge, Desmond Patton, Bruce Bimber, Kathleen McKeown, and William Yang Wang. Mitigating Covertly Unsafe Text within Natural Language Systems. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 291...
-
[6]
On the Safety of Conversational Models: Taxonomy, Dataset, and Benchmark
Hao Sun, Guangxuan Xu, Jiawen Deng, Jiale Cheng, Chujie Zheng, Hao Zhou, Nanyun Peng, Xiaoyan Zhu, and Minlie Huang. On the Safety of Conversational Models: Taxonomy, Dataset, and Benchmark. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Findings of the Association for Computational Linguistics: ACL 2022, pages 3906–3923, Dublin, Ir...
-
[7]
A Benchmark for Understanding Dialogue Safety in Mental Health Support, July 2023
Huachuan Qiu, Tong Zhao, Anqi Li, Shuai Zhang, Hongliang He, and Zhenzhong Lan. A Benchmark for Understanding Dialogue Safety in Mental Health Support, July 2023. URL http://arxiv.org/abs/2307.16457. arXiv:2307.16457 [cs]
-
[8]
Unveiling the Implicit Toxicity in Large Language Models, November 2023
Jiaxin Wen, Pei Ke, Hao Sun, Zhexin Zhang, Chengfei Li, Jinfeng Bai, and Minlie Huang. Unveiling the Implicit Toxicity in Large Language Models, November 2023. URL http: //arxiv.org/abs/2311.17391. arXiv:2311.17391 [cs]
-
[9]
Harmful advice dataset, 2025
Lennart Luettgau, Henry Davidson, Elizabeth Nguyen, Daria Butuc, and Christopher Sum- merfield. Harmful advice dataset, 2025. URL https://huggingface.co/datasets/ ai-safety-institute/harmful-advice-dataset
2025
-
[10]
People readily follow personal advice from AI but it does not improve their well-being
Lennart Luettgau, Vanessa Cheung, Magda Dubois, Keno Juechems, Jessica Bergs, Luke Symes, Henry Davidson, Bessie O’Dell, Hannah Rose Kirk, Max Rollwage, and Christopher Summerfield. People readily follow personal advice from AI but it does not improve their well-being, April 2026. URL http://arxiv.org/abs/2511.15352. arXiv:2511.15352 [cs] version: 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Root Defense Strategies: Ensuring Safety of LLM at the Decoding Level
Xinyi Zeng, Yuying Shang, Jiawei Chen, Jingyuan Zhang, and Yu Tian. Root Defense Strategies: Ensuring Safety of LLM at the Decoding Level. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1974–1988,...
-
[12]
Think Twice, Generate Once: Safeguarding by Progressive Self-Reflection
Hoang Phan, Victor Li, and Qi Lei. Think Twice, Generate Once: Safeguarding by Progressive Self-Reflection. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 9466–9483, Suzhou, China, November 2025. Association for Computational Linguistic...
-
[13]
Prefix Probing: Lightweight Harmful Content Detection for Large Language Models, December 2025
Jirui Yang, Hengqi Guo, Zhihui Lu, Yi Zhao, Yuansen Zhang, Shijing Hu, Qiang Duan, Yinggui Wang, and Tao Wei. Prefix Probing: Lightweight Harmful Content Detection for Large Language Models, December 2025. URL http://arxiv.org/abs/2512.16650. arXiv:2512.16650 [cs] version: 1. 10
-
[14]
LLM Safety From Within: Detecting Harmful Content with Internal Representations, April
Difan Jiao, Yilun Liu, Ye Yuan, Zhenwei Tang, Linfeng Du, Haolun Wu, and Ashton Anderson. LLM Safety From Within: Detecting Harmful Content with Internal Representations, April
-
[15]
LLM Safety From Within: Detecting Harmful Content with Internal Representations
URLhttp://arxiv.org/abs/2604.18519. arXiv:2604.18519 [cs] version: 1
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Characteristics of Harmful Text: Towards Rigorous Bench- marking of Language Models, October 2022
Maribeth Rauh, John Mellor, Jonathan Uesato, Po-Sen Huang, Johannes Welbl, Laura Wei- dinger, Sumanth Dathathri, Amelia Glaese, Geoffrey Irving, Iason Gabriel, William Isaac, and Lisa Anne Hendricks. Characteristics of Harmful Text: Towards Rigorous Bench- marking of Language Models, October 2022. URL http://arxiv.org/abs/2206.08325. arXiv:2206.08325 [cs]
-
[17]
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection, July 2022. URLhttp://arxiv.org/abs/2203.09509. arXiv:2203.09509 [cs]
-
[18]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The Internal State of an LLM Knows When It’s Lying. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore, December 2023. As- sociation for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https://aclantholog...
-
[19]
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
Koyena Pal, Jiuding Sun, Andrew Yuan, Byron Wallace, and David Bau. Future Lens: Anticipating Subsequent Tokens from a Single Hidden State. In Jing Jiang, David Re- itter, and Shumin Deng, editors,Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), pages 548–560, Singapore, December 2023. Asso- ciation for Computational ...
-
[20]
ShieldGemma: Generative AI Content Moderation Based on Gemma, August
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, Olivia Sturman, and Oscar Wahltinez. ShieldGemma: Generative AI Content Moderation Based on Gemma, August
-
[21]
ShieldGemma: Generative AI Content Moderation Based on Gemma
URLhttp://arxiv.org/abs/2407.21772. arXiv:2407.21772 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs, December 2024. URL http://arxiv.org/abs/2406. 18495. arXiv:2406.18495 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, Baosong Yang, Chen Cheng, Jialong Tang, Jiandong Jiang, Jianwei Zhang, Jijie Xu, Ming Yan, Minmin Sun, Pei Zhang, Pengjun Xie, Qiaoyu Tang, Qin Zhu, Rong Zhang, Shibin Wu, Shuo Zhang, Tao He, Tianyi Tang, Tingyu Xia, Wei Liao, Wei...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
NExT-Guard: Training-Free Streaming Safeguard without Token-Level Labels, February 2026
Junfeng Fang, Nachuan Chen, Houcheng Jiang, Dan Zhang, Fei Shen, Xiang Wang, Xiangnan He, and Tat-Seng Chua. NExT-Guard: Training-Free Streaming Safeguard without Token-Level Labels, February 2026. URL http://arxiv.org/abs/2603.02219. arXiv:2603.02219 [cs]
-
[25]
Hidden- Guard: Fine-Grained Safe Generation with Specialized Representation Router, October 2024
Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Ruibin Yuan, and Xueqi Cheng. Hidden- Guard: Fine-Grained Safe Generation with Specialized Representation Router, October 2024. URLhttp://arxiv.org/abs/2410.02684. arXiv:2410.02684 [cs]
-
[26]
Kelp: A Streaming Safeguard for Large Models via Latent Dynamics-Guided Risk Detection, October 2025
Xiaodan Li, Mengjie Wu, Yao Zhu, Yunna Lv, YueFeng Chen, Cen Chen, Jianmei Guo, and Hui Xue. Kelp: A Streaming Safeguard for Large Models via Latent Dynamics-Guided Risk Detection, October 2025. URL http://arxiv.org/abs/2510.09694. arXiv:2510.09694 [cs]
-
[27]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson 11 Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsso...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal, February 2024. URLhttp://arxiv.org/abs/2402.04249. arXiv:2402.04249 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Social- HarmBench: Revealing LLM Vulnerabilities to Socially Harmful Requests, February 2026
Punya Syon Pandey, Hai Son Le, Devansh Bhardwaj, Rada Mihalcea, and Zhijing Jin. Social- HarmBench: Revealing LLM Vulnerabilities to Socially Harmful Requests, February 2026. URLhttp://arxiv.org/abs/2510.04891. arXiv:2510.04891 [cs]
-
[31]
OR-Bench: An Over-Refusal Benchmark for Large Language Models
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. OR-Bench: An Over-Refusal Benchmark for Large Language Models. InProceedings of the 42nd International Conference on Machine Learning, June 2025. URLhttps://openreview.net/forum?id=CdFnEu0JZV
2025
- [32]
-
[33]
Vigliermo, Sonia Bergamaschi, and Luca Sala
Giovanni Sullutrone, Riccardo A. Vigliermo, Sonia Bergamaschi, and Luca Sala. COVER: Context-Driven Over-Refusal Verification in LLMs. In Wanxiang Che, Joyce Nabende, Ekate- rina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computa- tional Linguistics: ACL 2025, pages 24214–24229, Vienna, Austria, July 2025. Association fo...
-
[34]
International AI Safety Report 2026
International AI Safety Report. International AI Safety Report 2026. Technical report, Interna- tional AI Safety Report, February 2026. URL https://internationalaisafetyreport. org/publication/international-ai-safety-report-2026. A Systems Measurement Details We measure runtime on a single NVIDIA RTX 6000 Ada Generation GPU with 48GB memory, driver versio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.