Beyond Predefined Learning Objects: A Thinking-Learning Interaction Model for Up-to-Date Autonomous Robot Learning
Pith reviewed 2026-06-30 19:33 UTC · model grok-4.3
The pith
A bidirectional thinking-learning model lets autonomous robots adapt beyond fixed input features, output categories, and action routines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a thinking-learning interaction model in which the thinking process guides learning by identifying potential changes, selecting useful evidence, organizing training materials, and planning verification actions, while the learning process promotes thinking by updating task knowledge, feature-selection experience, action strategies, and future reasoning processes. This bidirectional mechanism enables the robot to move beyond predefined learning settings and adapt its recognition relations and action relations through continuous interaction with the environment, specifically supporting adaptive input feature discovery, output category expansion, learning model update, and
What carries the argument
The thinking-learning interaction model, a bidirectional mechanism where thinking directs learning by spotting changes and evidence while learning refines thinking by updating knowledge and strategies.
Load-bearing premise
A thinking process can reliably identify potential changes, select useful evidence, and organize training materials in open environments without any predefined structures or external guidance.
What would settle it
A long-term robot experiment in an environment with novel features and categories where the model produces no accuracy gains or action shortening beyond the predefined baseline would falsify the central claim.
Figures

read the original abstract
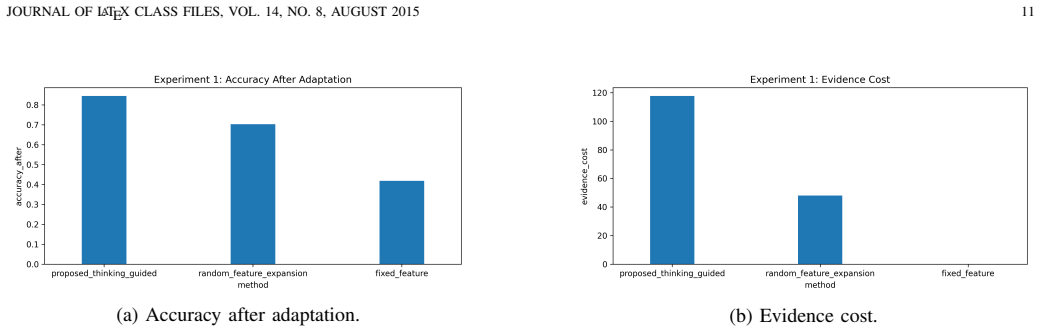
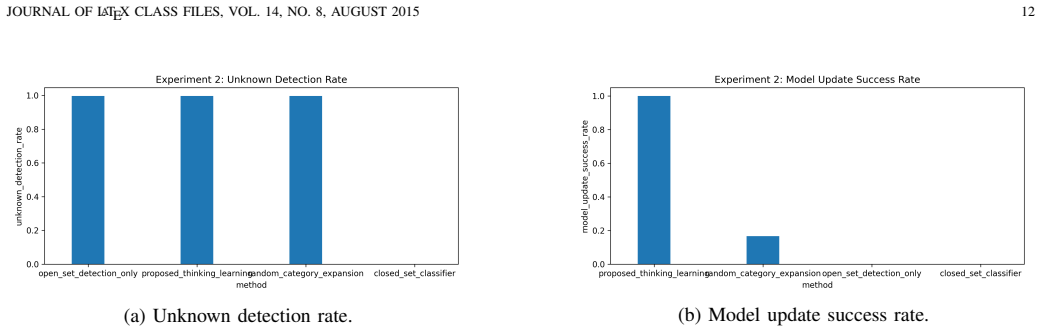
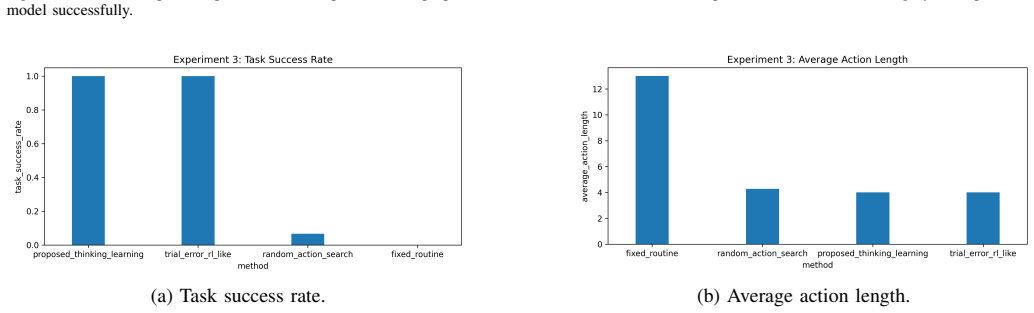
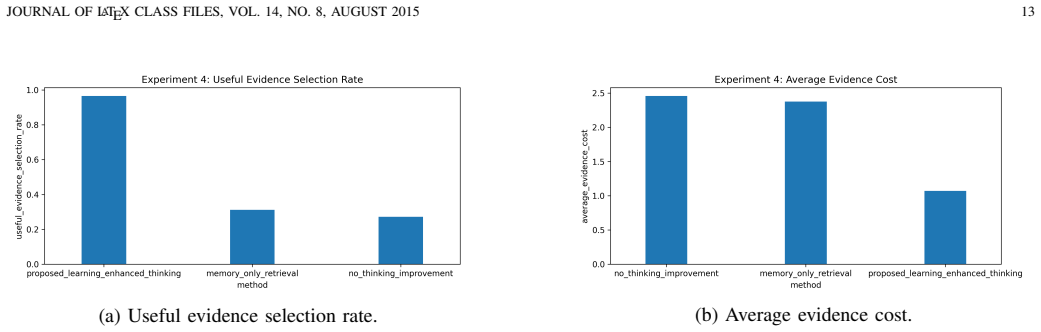
Autonomous robots operating in open and changing environments cannot always rely on predefined inputs, outputs, and action routines. Although existing learning methods enable robots to improve their performance through environmental interaction, the objects of learning are often fixed in advance, such as input features, recognition outputs, network structures, task goals, or action sequences. This limits their ability to adapt when new features, new categories, or more efficient task routines appear during long-term operation. To address this problem, this paper proposes a thinking-learning interaction model for autonomous robots. The core idea is that thinking guides learning by identifying potential changes, selecting useful evidence, organizing training materials, and planning verification actions, while learning promotes thinking by updating task knowledge, feature-selection experience, action strategies, and future reasoning processes. Based on this bidirectional mechanism, the robot can gradually move beyond predefined learning settings and adapt its recognition relations and action relations through continuous interaction with the environment. Specifically, the proposed model supports adaptive input feature discovery, output category expansion, learning model update, and action routine reconstruction. Experimental results show that the proposed model improves the final recognition accuracy from 0.419 to 0.845 in feature adaptation, achieves higher new-category formation accuracy and model-update success rate, and reduces the average action length from 13.0 to 4.0 in action routine reconstruction. In learning-enhanced thinking, the useful evidence selection rate increases from 0.272 to 0.965, indicating that learning results can effectively improve future evidence selection and reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a thinking-learning interaction model for autonomous robots operating in open environments. The core claim is that a bidirectional mechanism—where thinking guides learning by identifying changes, selecting evidence, organizing training materials, and planning verifications, while learning promotes thinking by updating knowledge, features, strategies, and reasoning—enables the robot to transcend predefined learning objects (input features, output categories, network structures, task goals, action sequences). This supports adaptive feature discovery, category expansion, model updates, and action routine reconstruction. Experiments report recognition accuracy rising from 0.419 to 0.845, higher new-category and model-update success, action length dropping from 13.0 to 4.0, and evidence selection rate improving from 0.272 to 0.965.
Significance. If the bidirectional mechanism can be realized without reintroducing hidden predefined structures, the work would address a genuine limitation in current robot learning approaches that fix learning objects in advance, potentially enabling more flexible long-term adaptation. The conceptual framing and reported quantitative gains are promising, but the absence of any derivation, initialization procedure, or falsifiable account of the zero-structure case limits the result's immediate technical impact.
major comments (2)
- [Abstract] Abstract: The central claim that the model enables adaptation 'without any predefined structures' is not supported by any account of how the thinking component is initialized or bootstrapped; the bidirectional description remains at the level of high-level functions (identify changes, select evidence, organize materials) with no mechanism shown for avoiding implicit priors such as feature detectors or category templates.
- [Abstract] Abstract (experimental results paragraph): The reported improvements (accuracy 0.419→0.845, action length 13→4, evidence rate 0.272→0.965) are presented without baselines, error bars, dataset descriptions, or statistical tests, so it is impossible to determine whether they test the zero-structure case or merely reflect performance under retained scaffolding.
minor comments (1)
- [Abstract] The abstract uses several near-synonyms ('recognition relations', 'action relations', 'input feature discovery', 'output category expansion') without clarifying whether these are distinct or overlapping constructs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments and indicate planned changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the model enables adaptation 'without any predefined structures' is not supported by any account of how the thinking component is initialized or bootstrapped; the bidirectional description remains at the level of high-level functions (identify changes, select evidence, organize materials) with no mechanism shown for avoiding implicit priors such as feature detectors or category templates.
Authors: We acknowledge that the abstract states the model enables adaptation beyond predefined learning objects but provides only a high-level description of the bidirectional mechanism without detailing initialization or a concrete procedure for avoiding implicit priors. The manuscript frames the contribution as gradual transcendence of fixed settings through interaction rather than a fully zero-structure starting state. We will revise the abstract to clarify this scope and reduce the strength of the 'without any predefined structures' phrasing. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): The reported improvements (accuracy 0.419→0.845, action length 13→4, evidence rate 0.272→0.965) are presented without baselines, error bars, dataset descriptions, or statistical tests, so it is impossible to determine whether they test the zero-structure case or merely reflect performance under retained scaffolding.
Authors: We agree that the abstract reports numerical gains without accompanying methodological details such as baselines, error bars, dataset descriptions, or statistical tests. The full manuscript contains experimental protocols and comparisons against fixed-object baselines, but these are not referenced in the abstract. We will revise the abstract to include brief context on the experimental setup and the nature of the comparisons while noting that full statistical details appear in the main text. revision: yes
- Absence of a derivation, explicit initialization procedure, or falsifiable account of a zero-structure case that avoids all implicit priors such as feature detectors or category templates
Circularity Check
No significant circularity; conceptual proposal without derivations or self-referential reductions
full rationale
The paper describes a bidirectional thinking-learning model as a conceptual framework for autonomous robot adaptation, supported by experimental outcomes (e.g., accuracy improvements from 0.419 to 0.845). No equations, parameter fits, or derivation chains are present that would reduce any claimed prediction or result to its own inputs by construction. The core claims rest on the proposed mechanism itself rather than on fitted inputs renamed as predictions, self-citations, or imported uniqueness theorems. This is a standard non-circular outcome for a high-level architectural proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llm-driven adaptive autonomous robot navigation via multimodal fusion for diverse environ- ments,
X. Liu, A. Farid, R. Ukyoh, T. Amano, H. Rizk, and H. Yamaguchi, “Llm-driven adaptive autonomous robot navigation via multimodal fusion for diverse environ- ments,” in2025 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2025, pp. 2361–2368
2025
-
[2]
Agentic llm-based robotic systems for real-world applications: a review on their agenticness and ethics,
E. K. Raptis, A. C. Kapoutsis, and E. B. Kosmatopou- los, “Agentic llm-based robotic systems for real-world applications: a review on their agenticness and ethics,” Frontiers in Robotics and AI, vol. 12, p. 1605405, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 14
2025
-
[3]
Continual lifelong learning with neural networks: A review,
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,”Neural networks, vol. 113, pp. 54– 71, 2019
2019
-
[4]
A contin- ual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A contin- ual learning survey: Defying forgetting in classification tasks,”IEEE transactions on pattern analysis and ma- chine intelligence, vol. 44, no. 7, pp. 3366–3385, 2021
2021
-
[5]
Towards open world object detection,
K. Joseph, S. Khan, F. S. Khan, and V . N. Balasub- ramanian, “Towards open world object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5830–5840
2021
-
[6]
S. Mirchandani, S. Belkhale, J. Hejna, E. Choi, M. S. Islam, and D. Sadigh, “So you think you can scale up autonomous robot data collection?”arXiv preprint arXiv:2411.01813, 2024
-
[7]
M. Ahn, D. Dwibedi, C. Finn, M. G. Arenas, K. Gopalakrishnan, K. Hausman, B. Ichter, A. Irpan, N. Joshi, R. Julianet al., “Autort: Embodied foundation models for large scale orchestration of robotic agents,” arXiv preprint arXiv:2401.12963, 2024
-
[8]
A comprehensive overview of large language models,
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. An- war, M. Usman, N. Akhtar, N. Barnes, and A. Mian, “A comprehensive overview of large language models,” ACM Transactions on Intelligent Systems and Technol- ogy, vol. 16, no. 5, pp. 1–72, 2025
2025
-
[9]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Her- zog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julianet al., “Do as i can, not as i say: Grounding language in robotic affordances,” inConference on robot learning. PMLR, 2023, pp. 287–318
2023
-
[10]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International conference on robotics and automation (ICRA). IEEE, 2023, pp. 9493–9500
2023
-
[11]
A survey on integration of large language models with intelligent robots,
Y . Kim, D. Kim, J. Choi, J. Park, N. Oh, and D. Park, “A survey on integration of large language models with intelligent robots,”Intelligent Service Robotics, vol. 17, no. 5, pp. 1091–1107, 2024
2024
-
[12]
Large language models for robotics: Opportunities, challenges, and perspectives,
J. Wang, E. Shi, H. Hu, C. Ma, Y . Liu, X. Wang, Y . Yao, X. Liu, B. Ge, and S. Zhang, “Large language models for robotics: Opportunities, challenges, and perspectives,” Journal of Automation and Intelligence, vol. 4, no. 1, pp. 52–64, 2025
2025
-
[13]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[14]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open- ended embodied agent with large language models,” arXiv preprint arXiv:2305.16291, 2023. PLACE PHOTO HERE Hong Sureceived the MS and PhD degrees, in 2006 and 2022, respectively, from Sichuan Univer- sity, Chengdu, China. He is currently a researcher...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.