A World Model of Radiologist Reading for Medical Image Representation Learning
Pith reviewed 2026-06-30 18:53 UTC · model grok-4.3
The pith
A world model trained on radiologist fixation sequences produces image features that achieve state-of-the-art diagnostic accuracy without gaze data at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
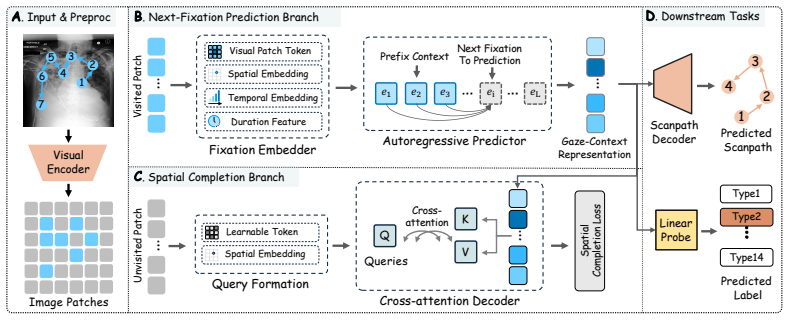
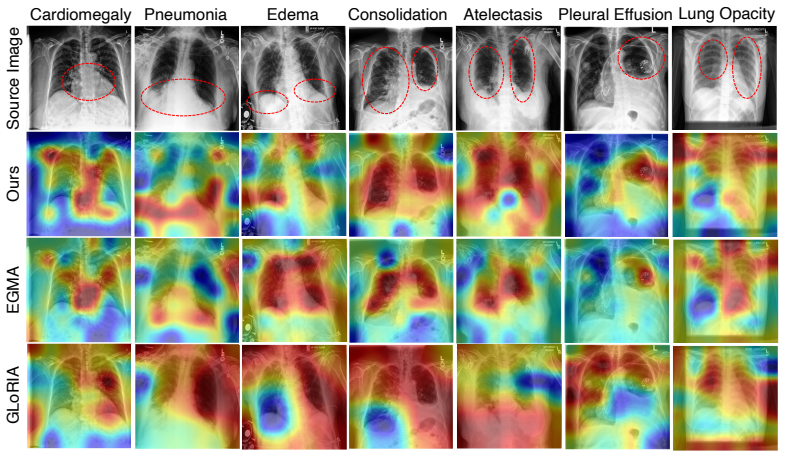
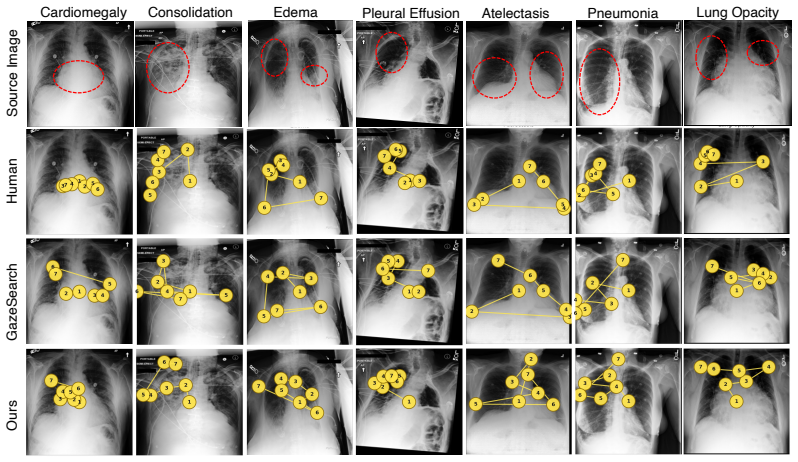
GazeWorld treats the image as a world and the radiologist's fixation sequence as a trajectory through it. It autoregressively predicts the latent representation of the next fixated patch from all previously visited ones and adds a spatial-completion branch for unvisited regions. At inference the model generates a sequence of patch representations from the image alone without real gaze data. Frozen GazeWorld features achieve state-of-the-art diagnostic accuracy across all nine supervised settings on CheXpert, RSNA Pneumonia, and SIIM-ACR Pneumothorax, the highest zero-shot accuracy on the same three benchmarks, and allow a generic decoder to outperform the purpose-built LogitGaze-Med by over
What carries the argument
GazeWorld, a world model that autoregressively predicts the latent representation of the next fixated patch from prior fixations together with a spatial-completion branch for unvisited image regions.
If this is right
- Frozen features from the model reach state-of-the-art accuracy in every supervised diagnostic setting tested on the three chest X-ray benchmarks.
- The same frozen features deliver the highest zero-shot accuracy on those benchmarks.
- A generic decoder trained on the features outperforms a specialized gaze-prediction model on the GazeSearch benchmark by over 16% ScanMatch and 22% SED.
- Modeling the process of expert image reading supplies a viable pretraining paradigm for medical imaging AI.
Where Pith is reading between the lines
- Expert visual search patterns appear to encode diagnostic information that is not fully captured by image labels or standard self-supervision alone.
- The method could allow existing clinical gaze recordings to serve as a source of supervision that reduces reliance on new manual annotations.
- Similar trajectory-based world models might be tested on other modalities where expert attention traces exist, such as digital pathology slides.
Load-bearing premise
The assumption that autoregressively predicting next-fixation patch representations from prior ones plus spatial completion produces diagnostic knowledge that transfers when real gaze data is unavailable at inference.
What would settle it
Training an otherwise identical model without the autoregressive next-fixation prediction and spatial-completion objectives and observing whether the resulting features still match or exceed the reported diagnostic accuracies on CheXpert, RSNA Pneumonia, and SIIM-ACR Pneumothorax.
Figures

read the original abstract
Radiologist eye-tracking data provide a rich record of how experts search, compare, and accumulate evidence during image reading; yet, existing methods exploit this signal only partially, either as a static spatial prior or as an auxiliary prediction target decoupled from diagnosis. We propose GazeWorld, a medical imaging world model that treats the image as the world and the radiologist's fixation sequence as a trajectory through it. GazeWorld autoregressively predicts the latent representation of the next fixated patch from all previously visited ones, while a spatial-completion branch covers unvisited regions. At inference, GazeWorld generates a sequence of patch representations from the image alone without requiring real gaze data. Frozen GazeWorld features achieve state-of-the-art diagnostic accuracy across all nine supervised settings on CheXpert, RSNA Pneumonia, and SIIM-ACR Pneumothorax, as well as the highest zero-shot accuracy on all three benchmarks. On the GazeSearch benchmark, a generic decoder trained on the same frozen features outperforms the purpose-built LogitGaze-Med by over 16\% in ScanMatch and 22\% in SED, despite not being explicitly trained to predict gaze. GazeWorld demonstrates that modeling how experts read, not just what they conclude, offers a promising pretraining paradigm for medical imaging AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GazeWorld, a medical imaging world model that treats the image as the world and radiologist fixation sequences as trajectories through it. The model autoregressively predicts the latent representation of the next fixated patch from all previously visited ones, augmented by a spatial-completion branch for unvisited regions. At inference, it generates patch representations from the image alone without real gaze data. Frozen GazeWorld features are reported to achieve state-of-the-art diagnostic accuracy across all nine supervised settings on CheXpert, RSNA Pneumonia, and SIIM-ACR Pneumothorax, the highest zero-shot accuracy on the same benchmarks, and to outperform the purpose-built LogitGaze-Med by over 16% in ScanMatch and 22% in SED on the GazeSearch benchmark when used with a generic decoder.
Significance. If the empirical claims hold after verification of methods and controls, the work would demonstrate a viable pretraining paradigm that incorporates expert search behavior into representation learning for medical images, with the practical advantage that gaze data is required only during training.
minor comments (3)
- Abstract: the claim of SOTA across 'all nine supervised settings' lacks explicit identification of the competing methods, exact performance deltas, or statistical significance tests.
- Abstract: no description is given of the backbone architecture, loss formulation, training data splits, or how the autoregressive prediction and spatial-completion objectives are balanced.
- Abstract: the GazeSearch results compare a generic decoder against LogitGaze-Med, but the training regime for the generic decoder (e.g., whether it sees any gaze supervision) is not stated.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for noting the potential significance of a pretraining paradigm that incorporates expert search behavior, with the advantage that gaze data is needed only at training time. We address the major comments below.
Circularity Check
No significant circularity
full rationale
The abstract and provided context contain no equations, derivation steps, or explicit self-citations. The model is described as trained on real gaze sequences to predict latent patch representations autoregressively, then used at inference without gaze data to produce features for downstream tasks. No load-bearing step reduces by construction to its own inputs, no fitted parameter is renamed as a prediction, and no uniqueness theorem or ansatz is imported via self-citation. The derivation chain cannot be inspected for circularity without the full manuscript equations, but the given material shows no evidence of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
Pranav Rajpurkar, Jeremy Irvin, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis Langlotz, Katie Shpanskaya, et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning.arXiv preprint arXiv:1711.05225,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chexagent: Towards a foundation model for chest x-ray interpretation
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. InAAAI 2024 Spring Symposium on Clinical Foundation Models,
2024
-
[3]
A path towards autonomous machine intelligence version 0.9
10 Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62,
2022
-
[4]
Scalable pre-training of large autore- gressive image models.arXiv preprint arXiv:2401.08541,
Alaaeldin El-Nouby, Michal Klein, Shuangfei Zhai, Miguel Angel Bautista, Alexander Toshev, Vaishaal Shankar, Joshua M Susskind, and Armand Joulin. Scalable pre-training of large autore- gressive image models.arXiv preprint arXiv:2401.08541,
-
[5]
Us-jepa: A joint embedding predictive architecture for medical ultrasound
11 Ashwath Radhachandran, Vedrana Ivezi´c, Shreeram Athreya, Ronit Anilkumar, Corey W Arnold, and William Speier. Us-jepa: A joint embedding predictive architecture for medical ultrasound. arXiv preprint arXiv:2602.19322,
-
[6]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3876–3887, 2022b. Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boe...
2022
-
[7]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Simulating human saccadic scanpaths on natural images
Wei Wang, Cheng Chen, Yizhou Wang, Tingting Jiang, Fang Fang, and Yuan Yao. Simulating human saccadic scanpaths on natural images. InCVPR 2011, pages 441–448. IEEE,
2011
-
[9]
A vector-based, multidimensional scanpath similarity measure
Halszka Jarodzka, Kenneth Holmqvist, and Marcus Nystr ¨om. A vector-based, multidimensional scanpath similarity measure. InProceedings of the 2010 symposium on eye-tracking research & applications, pages 211–218,
2010
-
[10]
Reported
A Baseline Protocol Details A.1 Dataset Details MIMIC-EYE.MIMIC-EYE [Hsieh et al., 2023] is an eye-tracking extension of the MIMIC-CXR database [Johnson et al., 2019]. It records radiologist fixation sequences from 3,032 frontal chest radiographs during routine clinical reading sessions using a Tobii Pro Nano eye tracker (sampling rate 60 Hz). Each record...
2023
-
[11]
processes the growing fixation sequence with temporal positional encoding. Three output heads operate on each hidden state ht: (i) a spatial head, implemented as a 196-way softmax over the patch grid; (ii) a duration head that regresses fixation dwell time; and (iii) a termination head. Following the GazeSearch evaluation protocol, the decoder emits 7 fix...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.