EvoSci: A Bio-Inspired Multi-Agent Framework for the Evolution of Scientific Discovery
Pith reviewed 2026-06-30 17:36 UTC · model grok-4.3
The pith
A bio-inspired multi-agent framework with knowledge graphs and evolutionary feedback generates higher-quality research ideas than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
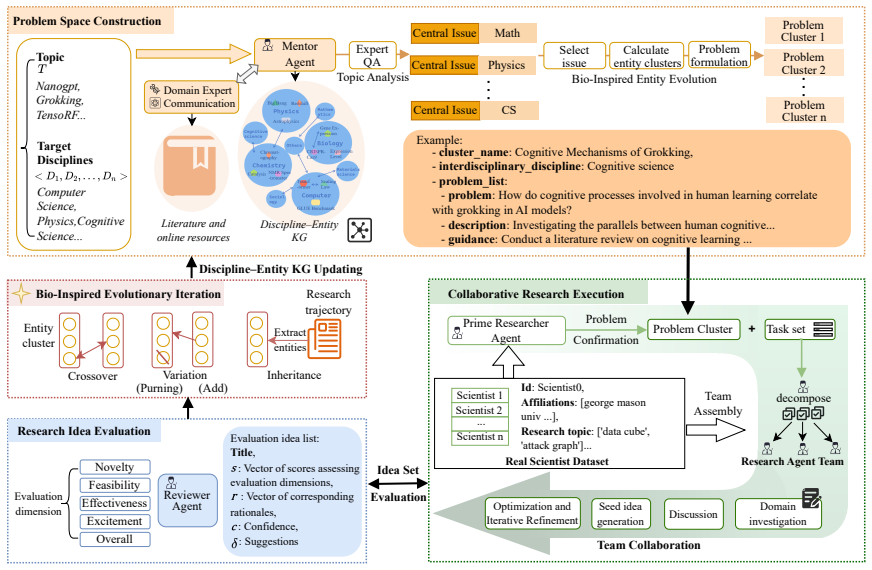
EvoSci is a multi-agent scientific collaboration framework that integrates bio-inspired evolution with knowledge graph modeling. It deploys role-based agents (mentor, researcher, reviewer) that use collaborative reasoning, shared memory, and evolutionary feedback to iteratively generate, evaluate, and refine research ideas, producing results that outperform baselines on real-world topics in LLM-based structured peer-review and comparative ranking.
What carries the argument
The multi-agent system with bio-inspired evolution and knowledge graph modeling, which carries iterative idea refinement through role-based collaboration and feedback loops.
If this is right
- EvoSci improves both the coherence and creativity of ideas generated through scientific exploration.
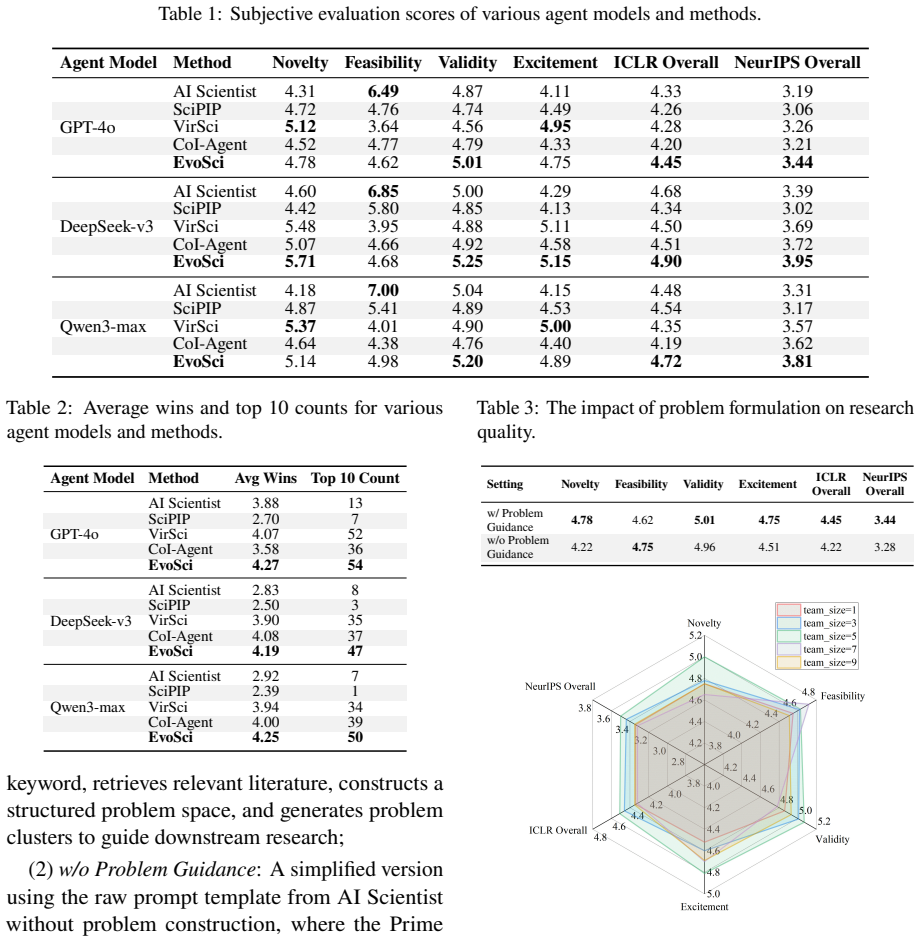
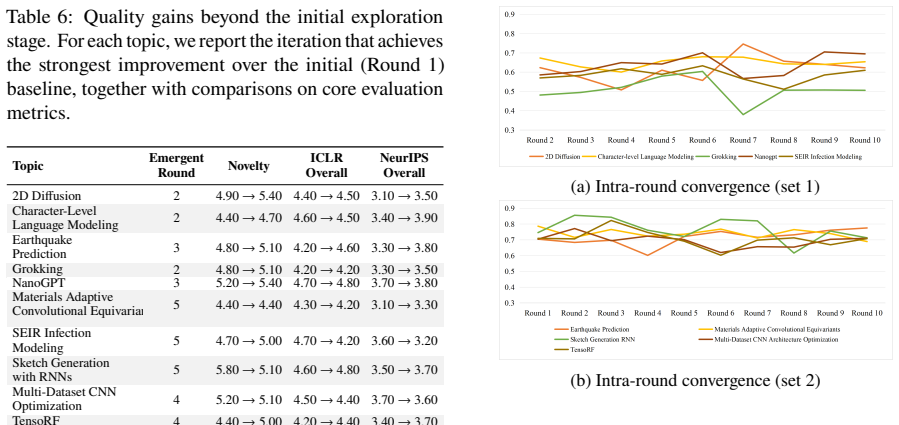
- The framework achieves the highest overall peer-review score of 4.90 and a Top-10 ranking of 54 in comparative evaluations.
- It demonstrates superiority over strong baselines in both idea generation and continuous discovery on real research topics.
- The combination of evolutionary feedback and shared memory supports ongoing refinement across multiple agent roles.
Where Pith is reading between the lines
- The approach could extend to domains outside the tested topics if the knowledge-graph component scales without added human curation.
- Replacing or supplementing LLM reviewers with human input might change the observed performance gap.
- The evolutionary mechanism might produce longer idea chains if the shared memory size is increased beyond current experiments.
Load-bearing premise
LLM-generated peer-review scores reliably and unbiasedly measure the quality and novelty of scientific ideas regardless of how those ideas were produced.
What would settle it
An independent panel of human domain experts re-ranks the same set of generated ideas from EvoSci and the baselines and finds no advantage or a reversal for EvoSci.
Figures

















read the original abstract
Large language models (LLMs), have shown strong potential in scientific discovery, yet existing methods still face substantial challenges in the design of research workflows and multi-role collaboration mechanisms. To mitigate these issues, we propose EvoSci, a multi-agent scientific collaboration framework, which integrates bio-inspired evolution with knowledge graph modeling. To iteratively generate, evaluate, and refine research ideas, EvoSci incorporates multiple role-based agents, including mentor, researcher, and reviewer. By combining collaborative reasoning, shared memory, and evolutionary feedback, EvoSci significantly enhances the coherence and creativity of scientific exploration. Experiments on real-world research topics demonstrate that EvoSci significantly outperforms strong baselines in LLM-based structured peer-review and comparative ranking evaluations, achieving the highest overall peer-review score (ICLR 4.90) and top ranking (Top-10 = 54). These results suggest its superiority in both scientific idea generation and continuous discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvoSci, a multi-agent framework that combines bio-inspired evolutionary mechanisms with knowledge-graph modeling and role-based agents (mentor, researcher, reviewer) to iteratively generate, evaluate, and refine scientific research ideas. It reports that the system outperforms strong baselines on real-world topics when measured by LLM-based structured peer review, achieving the highest overall score (ICLR 4.90) and top ranking (Top-10 = 54).
Significance. If the reported superiority were shown to reflect genuine gains in idea quality rather than artifacts of the evaluation process, the work would contribute a concrete multi-agent architecture for automated scientific ideation. The integration of evolutionary feedback loops with shared memory is a plausible direction for improving coherence in LLM-driven discovery pipelines.
major comments (2)
- [Abstract / Experimental evaluation] Abstract (experiments paragraph): the headline result (ICLR 4.90, Top-10 = 54) is obtained exclusively via LLM-based structured peer-review and ranking. The manuscript supplies no description of baseline implementations, prompt templates used by the evaluator, statistical significance tests, or controls that isolate generation-process effects from evaluator bias, rendering the superiority claim impossible to assess.
- [Experimental evaluation] Evaluation design (experiments section): because both idea generation and scoring are performed by LLMs of the same general class, the comparison is not independent. No human-expert correlation, inter-evaluator agreement statistics, or external benchmark (e.g., blinded human review or citation-based proxies) is reported, so the metric does not establish that EvoSci produces higher-quality scientific ideas.
minor comments (1)
- [Abstract] The abstract states that EvoSci 'significantly outperforms strong baselines' without naming the baselines or the datasets of real-world research topics; these details should be supplied in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our evaluation methodology. We address each major point below and outline planned revisions to improve transparency.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] Abstract (experiments paragraph): the headline result (ICLR 4.90, Top-10 = 54) is obtained exclusively via LLM-based structured peer-review and ranking. The manuscript supplies no description of baseline implementations, prompt templates used by the evaluator, statistical significance tests, or controls that isolate generation-process effects from evaluator bias, rendering the superiority claim impossible to assess.
Authors: We agree that the manuscript lacks these details. In the revised version we will expand the experiments section to describe the baseline implementations, provide the exact prompt templates used by the evaluator LLM, report statistical significance tests with p-values, and include controls such as cross-model evaluation to help isolate generation effects from evaluator bias. revision: yes
-
Referee: [Experimental evaluation] Evaluation design (experiments section): because both idea generation and scoring are performed by LLMs of the same general class, the comparison is not independent. No human-expert correlation, inter-evaluator agreement statistics, or external benchmark (e.g., blinded human review or citation-based proxies) is reported, so the metric does not establish that EvoSci produces higher-quality scientific ideas.
Authors: We acknowledge the lack of independence when using LLMs from the same class for generation and scoring. The revised manuscript will add an explicit limitations discussion on this point and frame human validation as important future work. Because no human-expert evaluations, correlation analyses, or blinded reviews were performed in the original study, we cannot supply those statistics. revision: partial
- Human-expert correlation statistics, inter-evaluator agreement measures, or results from blinded human review, as these were not collected in the reported experiments.
Circularity Check
No significant circularity; empirical claims rest on external LLM evaluation metric without reduction to inputs.
full rationale
The paper describes a multi-agent framework (EvoSci) for idea generation and reports empirical outperformance on LLM-based peer-review scores and rankings. No equations, fitted parameters, or derivation steps are present in the abstract or described text that reduce the reported results (ICLR 4.90, Top-10=54) to the framework inputs by construction. The evaluation is presented as an independent experimental protocol rather than a self-definitional or self-cited load-bearing step. No self-citation chains, ansatzes, or renamings are invoked to justify the central result. The metric, while LLM-based, is treated as an external benchmark for the purpose of this analysis and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can reliably simulate distinct scientific roles and produce coherent collaborative reasoning via shared memory.
- domain assumption Evolutionary feedback loops improve idea quality in a measurable way.
Forward citations
Cited by 1 Pith paper
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
Reference graph
Works this paper leans on
-
[1]
Agent ai: Surveying the horizons of multi- modal interaction.arXiv preprint arXiv:2401.03568. Kevin C. Elliott. 2012. Epistemic and methodological iteration in scientificresearch.Studies inHistoryand Philosophy of Science Part A, 43(2):376–382. Mohamed Amine Ferrag, Norbert Tihanyi, and Mer- ouane Debbah. 2025. Reasoning beyond limits: Advances and open p...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[2]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACMTransactionsonInformationSystems, 43(2):1–55. Peter Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi Mishra, Bod- hisattwa Prasad Majumder, Daniel S Weld, and Pe- ter Clark. 2025. Codescientist: End-to-end semi- aut...
-
[3]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
ChatSOP: An SOP-guided MCTS planning framework for controllable LLM dialogue agents. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 17637–17659, Vienna, Austria. Association for Computational Linguistics. YanLiu, MinghuiZhang, BojianXiong, YifanXiao, Yi- nong Sun, Yating Mei, Lon...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
TrieuHTrinh,YuhuaiWu,QuocVLe,HeHe,andThang Luong
Self-driving laboratories for chemistry and materials science.Chemical Reviews, 124(16):9633– 9732. TrieuHTrinh,YuhuaiWu,QuocVLe,HeHe,andThang Luong. 2024. Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482. Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. 2024a. Scimon: Scientific inspiration machines opti- mizedfornovelty....
-
[5]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Towards large reasoning models: A survey of reinforced reasoning with large language models. arXiv preprint arXiv:2501.09686. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shen- gran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
From automation to autonomy: A survey on large language models in scientific discovery.arXiv preprint arXiv:2505.13259. Yizhen Zheng, Huan Yee Koh, Jiaxin Ju, Anh TN Nguyen, Lauren T May, Geoffrey I Webb, and Shirui Pan. 2023. Large language models for scientific synthesis, inference and explanation.arXiv preprint arXiv:2310.07984. Hang Zhou, Yehui Tang, ...
-
[7]
Explain briefly why it is relevant
Pick one distinct discipline from {discipline set} that meaningfully connects with this topic. Explain briefly why it is relevant. If the connection is unclear, you may hypothetically consult an expert from either the core discipline or candidate fields to clarify the most suitable choice
-
[8]
{problem clusters}
Propose 2–3 research clusters that combine ideas or methods from both disciplines. Each cluster should include: - a short title, - 1–2 specific research questions, - and short notes on possible data, theories, or methods. Keep the answer concise and well-structured. Expected output: A structured list of problem clusters: - cluster name: A descriptive name...
-
[9]
Title: The title of the idea you are evaluating
-
[10]
Y ou are encouraged to search for related works online
Novelty Score: Whether the idea is creative and different from existing works on the topic, and brings fresh insights. Y ou are encouraged to search for related works online. Y ou should consider all papers that appeared online prior to July 2025 as existing work when judging the novelty
2025
-
[11]
If you give a low score, you should specify similar related works
Novelty Rationale: Short justification for your score. If you give a low score, you should specify similar related works. (Y our rationale should be at least 2-3 sentences.)
-
[12]
Y ou can assume that we have abundant OpenAI / Anthropic API access, but limited GPU compute
Feasibility Score: How feasible it is to implement and execute this idea as a research project? Specif- ically, how feasible the idea is for a typical CS PhD student to execute within 1-2 months of time. Y ou can assume that we have abundant OpenAI / Anthropic API access, but limited GPU compute
-
[13]
If you give a low score, you should specify what parts are difficult to execute and why
Feasibility Rationale: Short justification for your score. If you give a low score, you should specify what parts are difficult to execute and why. (Y our rationale should be at least 2-3 sentences.)
-
[14]
Expected Effectiveness Score: How likely the proposed idea is going to work well (e.g., better than existing baselines)
-
[15]
(Y our rationale should be at least 2-3 sentences.)
Expected Effectiveness Rationale: Short justification for your score. (Y our rationale should be at least 2-3 sentences.)
-
[16]
Would the idea change the field and be very influential
Excitement Score: How exciting and impactful this idea would be if executed as a full project. Would the idea change the field and be very influential
-
[17]
(Y our rationale should be at least 2-3 sentences.)
Excitement Rationale: Short justification for your score. (Y our rationale should be at least 2-3 sentences.)
-
[18]
Overall Score: Overall score: Apart from the above, you should also give an overall score for the idea on a scale of 1 - 10 as defined below (Major AI conferences in the descriptions below refer to top-tier NLP/AI conferences such as ACL, COLM, NeurIPS, ICLR, and ICML.):
-
[19]
Critically flawed, trivial, or wrong, would be a waste of students’ time to work on it
-
[20]
Strong rejection for major AI conferences
-
[21]
Clear rejection for major AI conferences
-
[22]
Ok but not good enough, rejection for major AI conferences
-
[23]
Decent idea but has some weaknesses or not exciting enough, marginally below the acceptance threshold of major AI conferences
-
[24]
Marginally above the acceptance threshold of major AI conferences
-
[25]
Good idea, would be accepted by major AI conferences
-
[26]
Top 50% of all published ideas on this topic at major AI conferences, clear accept
-
[27]
Top 15% of all published ideas on this topic at major AI conferences, strong accept
-
[28]
Top 5% of all published ideas on this topic at major AI conferences, will be a seminal paper
-
[29]
(Y our rationale should be at least 2-3 sentences.)
Overall Rationale: Y ou should also provide a rationale for your overall score. (Y our rationale should be at least 2-3 sentences.)
-
[30]
Confidence: Additionally, we ask for your confidence in your review on a scale of 1 to 5
-
[31]
suggestion: your suggestion for improving this idea Figure 17: System prompt for the evaluation task. Iterative Refinement Description: After receiving [{feedback}] from the evaluator, you must revise the research idea, ensuring that each modification is well-supported and enhances feasibility, novelty, or interdisciplinary value. The revised idea should ...
-
[32]
Ensure that the essential concept remains intact and that no drastic changes are made to the overall approach
Review the Original Idea: Understand its structure and core content. Ensure that the essential concept remains intact and that no drastic changes are made to the overall approach
-
[33]
Revise the Research Question or Background: Modify the research question or background descrip- tion based on the evaluator’s feedback to make the research more focused, innovative, or relevant to the current research landscape
-
[34]
Adjust the Research Methodology: Modify or expand the original methodology as needed, incor- porating new techniques, tools, theories, or interdisciplinary perspectives based on the evaluator’s sug- gestions
-
[35]
Refine the Experimental Design: If the evaluator suggests changes to the experimental setup or methodology, ensure that the revised plan is clearer, more feasible, and effectively tests the research hypothesis
-
[36]
Incorporate Additional Literature or Theoretical Support: Introduce relevant studies or theories, particularly those that strengthen interdisciplinary connections, to reinforce the research foundation in response to the evaluator’s feedback
-
[37]
Each modification should have a clear rationale and contribute to the advancement of the research
Ensure Consistency and Logical Flow: The revised idea should align with the evaluator’s feedback while maintaining a clear and coherent structure. Each modification should have a clear rationale and contribute to the advancement of the research
-
[38]
Update the Experiment Plan and Test Cases: Modify the experimental steps and test cases to align with the updated methodology, ensuring they effectively validate the revised research hypothesis and demonstrate improvements
-
[39]
{topic}” within the fixed discipline “{discipline}
Evaluate the Impact of the Modifications: Ensure that the revised approach improves the research in terms of novelty, feasibility, and alignment with the research problem, effectively addressing the evaluator’s concerns. Expected output: - name: A concise lowercase identifier using underscores (e.g., adaptive graph learning). - title: A descriptive and pu...
-
[40]
This is not the place to critique the paper; the authors should generally agree with a well-written summary
Summary: Briefly summarize the paper and its main contributions. This is not the place to critique the paper; the authors should generally agree with a well-written summary
-
[41]
Strengths and Weaknesses: Provide a thorough assessment of the strengths and weaknesses of the paper, considering the following dimensions: - Originality: Are the tasks, methods, or perspectives novel? Is the work a novel or meaningful combi- nation of existing techniques? Is it clear how this work differs from prior research? - Quality: Is the submission...
-
[42]
Focus on issues where an author response could change your assessment, clarify confusion, or address limitations
Questions: List clear and specific questions or suggestions for the authors. Focus on issues where an author response could change your assessment, clarify confusion, or address limitations
-
[43]
Ethical Concerns: Indicate whether the paper raises ethical concerns that require further review
-
[44]
Summary”: “
Overall Score: Provide an overall score according to the following scale: - 10: Award Quality – Technically flawless with groundbreaking impact and exceptional evaluation. - 9: Very Strong Accept – Technically flawless with groundbreaking impact in at least one area. - 8: Strong Accept – Technically strong with novel ideas and excellent impact. - 7: Accep...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.