Iterative Refinement Neural Operators are Learned Fixed-Point Solvers: A Principled Approach to Spectral Bias Mitigation
Pith reviewed 2026-06-30 17:01 UTC · model grok-4.3
The pith
Adding a learned refinement module turns neural operators into fixed-point solvers that converge and cut high-frequency errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
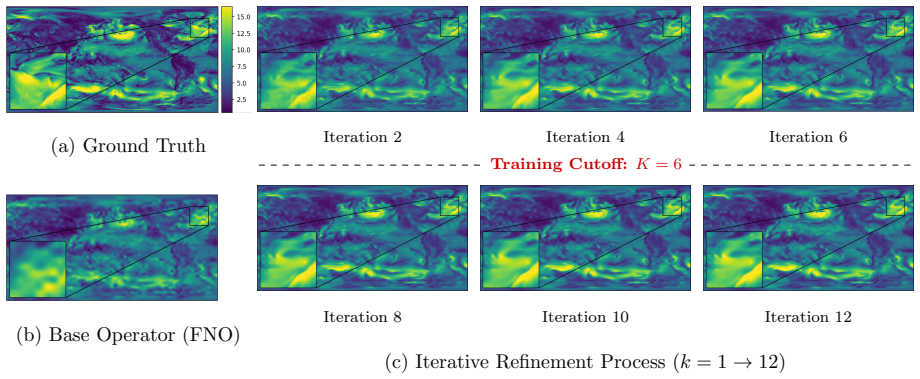
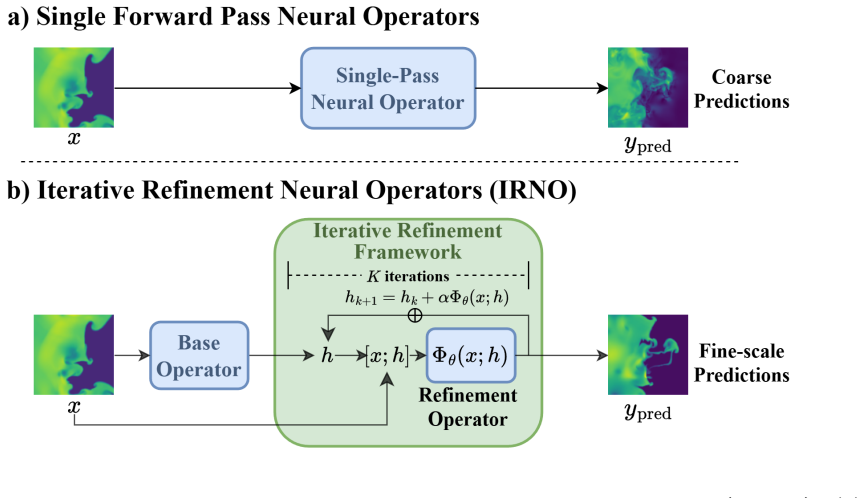
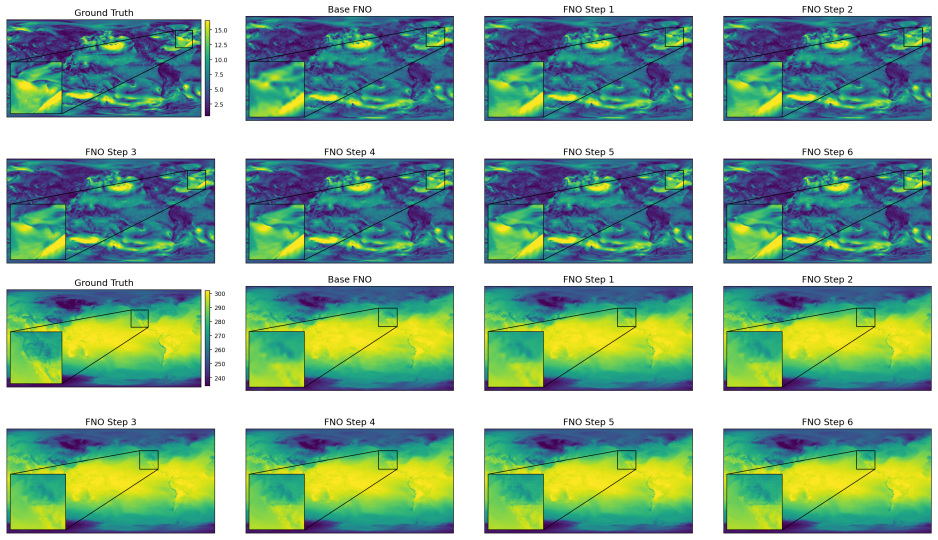
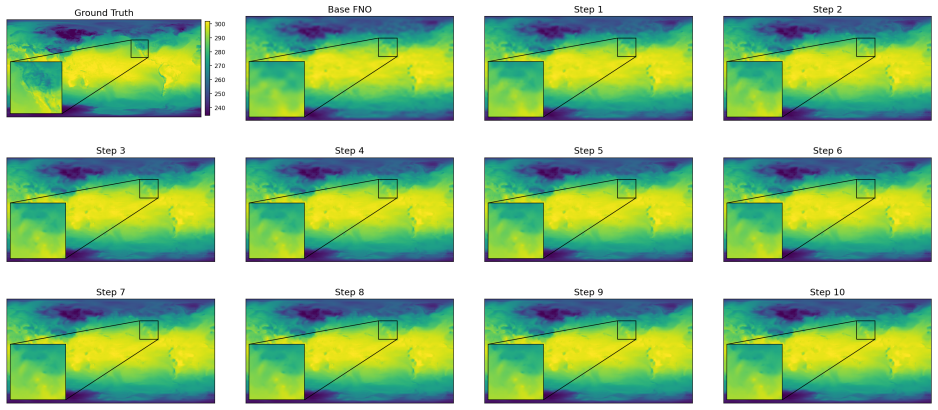
The Iterative Refinement Neural Operator augments any pre-trained neural operator with a learned refinement module that is applied iteratively through fixed-point iteration. The prediction is formed as a coarse initialization plus successive residual corrections. Under local assumptions the induced operator is a contraction mapping and therefore converges to a unique fixed point. A progressive spectral loss is introduced that increases the penalty on high-frequency components at each refinement step during training.
What carries the argument
The learned refinement module applied repeatedly via fixed-point iteration, together with the progressive spectral loss that raises the weight on high-frequency residuals over steps.
If this is right
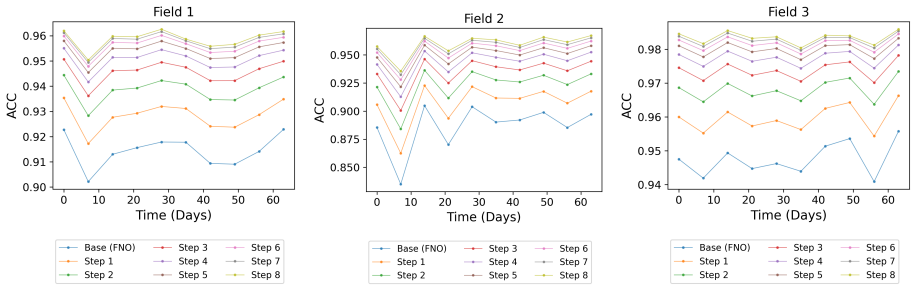
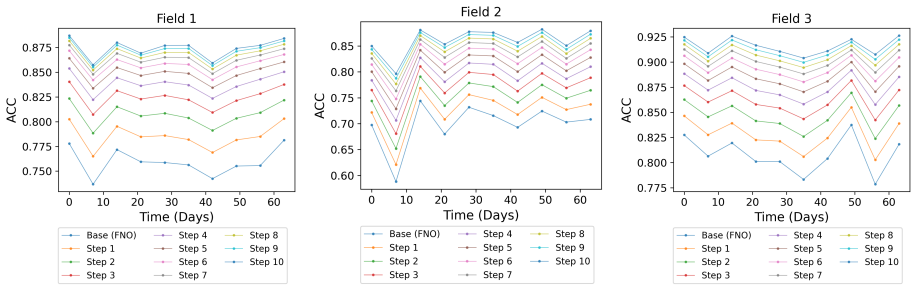
- Error drops consistently on multiple physical systems, reaching a 56.05 percent reduction on turbulent flow.
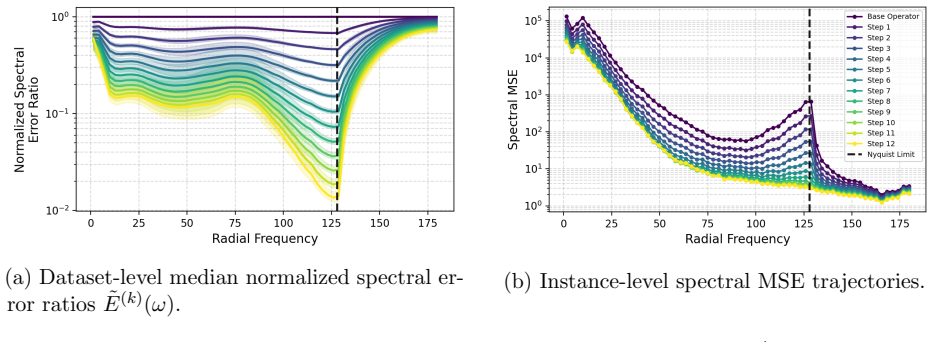
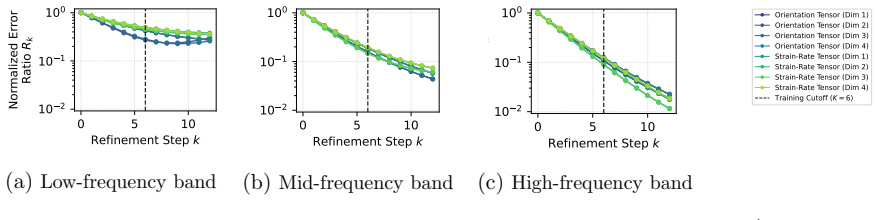
- On Active Matter the normalized error in high frequencies falls to 1.48-2.04 percent of the base operator's error.
- The same error ratios hold when the iteration count exceeds the number of steps seen during training.
- Low- and mid-frequency errors also decrease, to 27.72-36.10 percent and 5.07-6.68 percent of the base error respectively.
Where Pith is reading between the lines
- The fixed-point view may let practitioners combine the learned module with classical numerical correctors inside a single solver loop.
- The same refinement construction could be tried on other single-pass models that exhibit frequency-dependent accuracy loss.
- Checking whether the contraction property holds for random initial guesses rather than the network's own coarse output would test robustness outside the paper's local assumptions.
Load-bearing premise
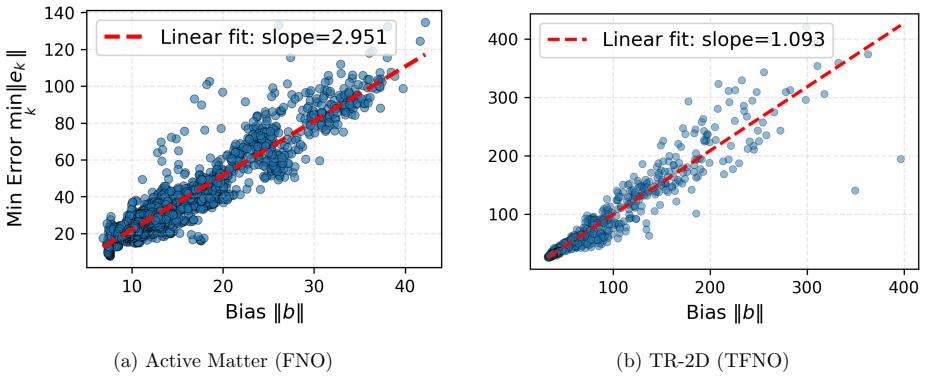
The local conditions that make the refinement operator a contraction mapping are satisfied for the trained networks and target systems.
What would settle it
A test case in which repeated application of the refinement module either diverges or leaves high-frequency error unchanged or larger than the base operator on a held-out physical system.
Figures

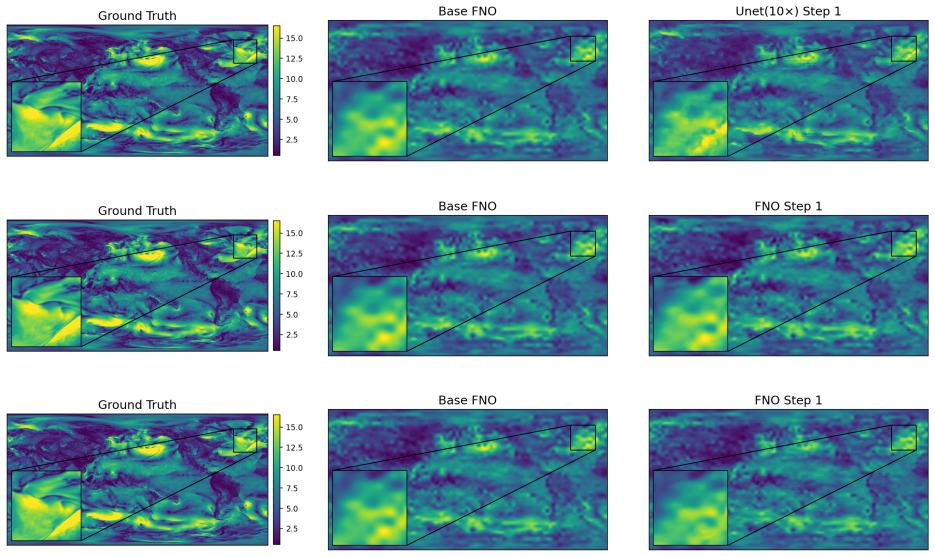
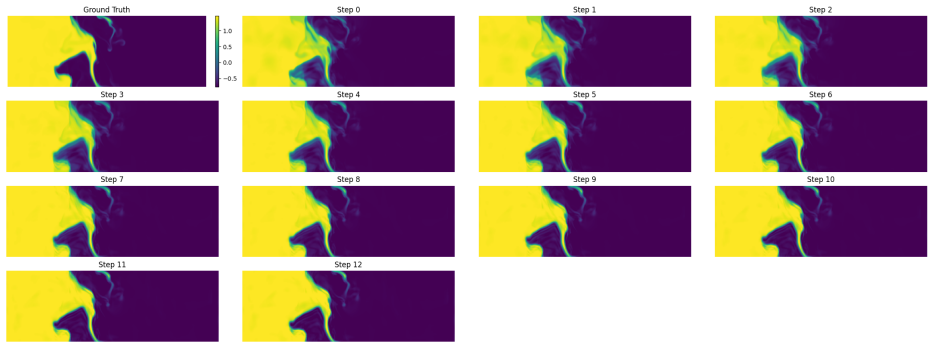
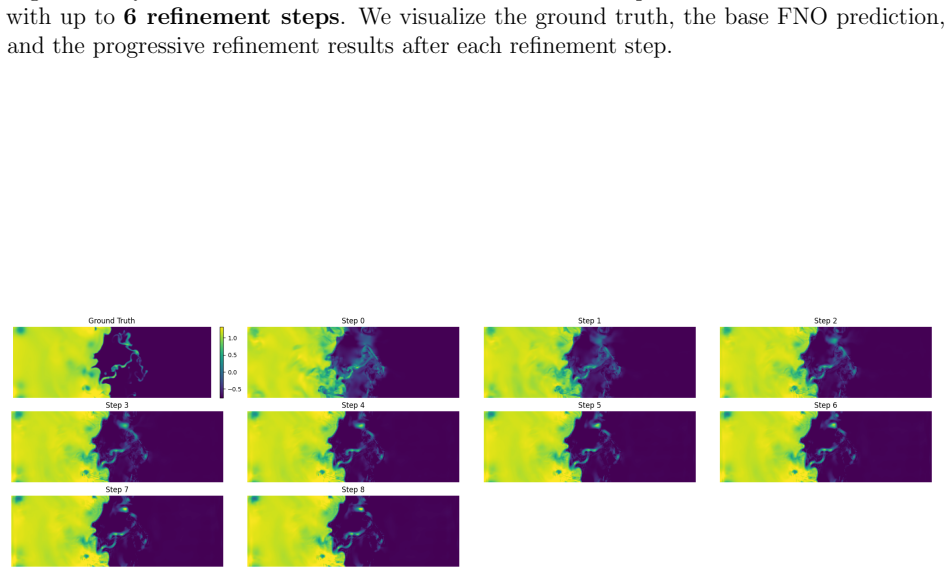
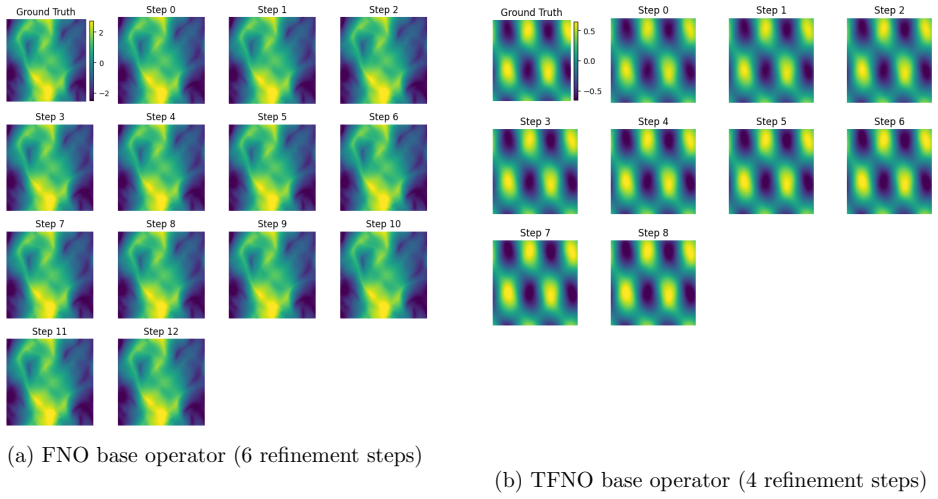
read the original abstract
Neural operators serve as fast, data-driven surrogates for scientific modeling but typically rely on a monolithic, single-pass inference procedure that struggles to resolve high-frequency details, a limitation known as spectral bias. We introduce the Iterative Refinement Neural Operator (IRNO), which augments pre-trained operators with a learned refinement module iteratively applied via fixed-point iteration. IRNO decomposes the prediction into a coarse initialization followed by successive residual corrections, paralleling classical numerical solvers. Under local assumptions, we establish contraction of the induced operator, ensuring convergence to a unique fixed point. To explicitly target high-frequency errors, we propose a progressive spectral loss that adaptively increases penalty on high-frequency components over refinement steps during training. Across physical systems, IRNO consistently lowers error, with up to 56.05% improvement on turbulent flow. On Active Matter, spectral analysis reveals that, relative to base operator, the normalized error ratios decrease to 27.72-36.10% in low-, 5.07-6.68% in mid-, and 1.48-2.04% in high-frequencies, remaining stable beyond the trained iteration count. Code is available at https://github.com/xiaotianliu-dartmouth/Iterative_Refinement_Neural_Operator
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Iterative Refinement Neural Operator (IRNO) that augments a pre-trained neural operator with a learned refinement module applied iteratively as a fixed-point iteration. It decomposes the solution into a coarse initialization plus successive residual corrections. Under unspecified local assumptions, the authors prove that the induced operator is contractive and therefore converges to a unique fixed point. A progressive spectral loss is introduced that increases the penalty on high-frequency components across refinement steps. Experiments on turbulent flow and Active Matter report error reductions (up to 56.05 % on turbulent flow) and show that normalized high-frequency error ratios drop to 1.48–2.04 % while remaining stable past the training horizon. Reproducible code is released.
Significance. If the contraction result can be made operational, the work supplies a principled, architecture-agnostic route to spectral-bias mitigation that parallels classical iterative solvers. The explicit framing as learned fixed-point iteration, the progressive loss design, and the public code release are concrete strengths that would allow the community to test the method on additional PDEs.
major comments (2)
- [§3] §3 (Contraction Mapping): The local assumptions required for the refinement operator to be contractive (Lipschitz constant of the learned residual map <1, domain restrictions, regularity of the base operator) are invoked but never stated explicitly or bounded; without these the convergence theorem is not falsifiable and the advertised stability beyond the training horizon cannot be verified.
- [§5] §5 (Experiments on turbulent flow and Active Matter): No post-hoc numerical diagnostic is reported that checks whether the contraction condition actually holds on the test trajectories; the claim that error ratios remain stable at iteration counts exceeding those seen in training therefore rests on an unverified premise.
minor comments (1)
- [§4] Notation for the progressive spectral loss (Eq. (X)) should include an explicit schedule for the frequency-weighting parameter so that the training procedure is fully reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the positive assessment of the work's significance. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Contraction Mapping): The local assumptions required for the refinement operator to be contractive (Lipschitz constant of the learned residual map <1, domain restrictions, regularity of the base operator) are invoked but never stated explicitly or bounded; without these the convergence theorem is not falsifiable and the advertised stability beyond the training horizon cannot be verified.
Authors: We agree that the local assumptions underlying the contraction result were not stated with sufficient explicitness or bounds in the original manuscript. In the revised version we will add a dedicated subsection that precisely enumerates the assumptions (Lipschitz constant of the residual map strictly less than one on a suitable ball, domain restrictions, and regularity of the base operator), together with any available quantitative bounds derived from the training procedure. This will make the theorem directly falsifiable and will clarify the conditions under which the observed stability beyond the training horizon is expected to hold. revision: yes
-
Referee: [§5] §5 (Experiments on turbulent flow and Active Matter): No post-hoc numerical diagnostic is reported that checks whether the contraction condition actually holds on the test trajectories; the claim that error ratios remain stable at iteration counts exceeding those seen in training therefore rests on an unverified premise.
Authors: We acknowledge that an explicit numerical check of the contraction condition on held-out test trajectories is currently absent. In the revised manuscript we will insert a new diagnostic subsection that reports an empirical estimate of the Lipschitz constant of the learned refinement operator evaluated on the test sets for both turbulent flow and active-matter problems. This will directly verify whether the contraction premise holds out of sample and thereby substantiate the stability claims. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces IRNO by augmenting a base neural operator with a learned refinement module and applies the classical contraction mapping theorem under local assumptions to prove convergence to a unique fixed point. The progressive spectral loss is presented as an explicit training design choice that increases high-frequency penalties over iterations. No equation or claim reduces a reported prediction or fixed-point result to a fitted parameter by construction, and no load-bearing step depends on a self-citation chain. The derivation remains self-contained as a methodological proposal whose central guarantees rest on standard analysis rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
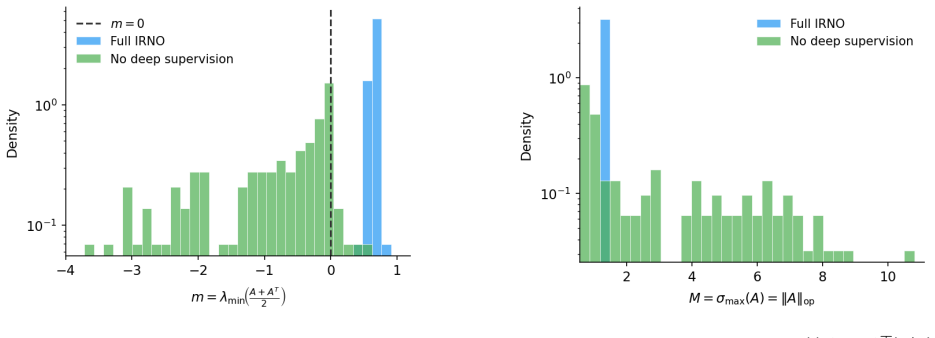
- domain assumption Local assumptions ensure the induced refinement operator is a contraction mapping
Reference graph
Works this paper leans on
-
[1]
doi: 10.1088/0004-637x/765/1/39
ISSN 1538-4357. doi: 10.1088/0004-637x/765/1/39. URL http://dx.doi.org/10.1088/0004-637X/765/1/39. Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[2]
Yuchen Fan, Jiahui Yu, and Thomas S Huang
doi: 10.52202/079017-0201. Yuchen Fan, Jiahui Yu, and Thomas S Huang. Wide-activated deep residual networks based restoration for bpg-compressed images. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition Workshops, pages 2621–2624,
-
[3]
doi: 10.1088/1361-6420/aa9a90. URLhttps://doi. org/10.1088/1361-6420/aa9a90. Sheikh Md Shakeel Hassan, Arthur Feeney, Akash Dhruv, Jihoon Kim, Youngjoon Suh, Jaiyoung Ryu, Yoonjin Won, and Aparna Chandramowlishwaran. Bubbleml: A multi- phase multiphysics dataset and benchmarks for machine learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, ...
-
[4]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. InProceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR ’16, pages 770–778. IEEE, June
2016
-
[5]
Deep Residual Learning for Image Recognition,
doi: 10.1109/CVPR.2016.90. URLhttp://ieeexplore.ieee.org/document/7780459. Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hirahara, Andr´ as Hor´ anyi, Joaqu´ ın Mu˜ noz- Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730):1999–2049,
-
[6]
doi: https://doi.org/10.1016/ j.neunet.2025.108027
ISSN 0893-6080. doi: https://doi.org/10.1016/ j.neunet.2025.108027. URLhttps://www.sciencedirect.com/science/article/pii/ S0893608025009074. Jean Kossaifi, Nikola Kovachki, Zongyi Li, David Pitt, Miguel Liu-Schiaffini, Valentin Du- ruisseaux, Robert Joseph George, Boris Bonev, Kamyar Azizzadenesheli, Julius Berner, and Anima Anandkumar. A library for lear...
-
[7]
Fourier Neural Operator for Parametric Partial Differential Equations
URLhttps://openreview.net/forum?id=c8P9NQVtmnO. See also arXiv:2010.08895 (2020). Xinliang Liu, Bo Xu, Shuhao Cao, and Lei Zhang. Mitigating spectral bias for the multiscale operator learning.Journal of Computational Physics, 506:112944,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
doi: https://doi.org/10.1016/j.jcp.2024.112944
ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2024.112944. URLhttps://www.sciencedirect.com/ science/article/pii/S0021999124001931. Lu Lu, Pengzhan Jin, Guofei Pang, Zongren Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of opera- tors.Nature Machine Intelligence, 3(3):218–229,
-
[9]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
doi: 10.1038/s42256-021-00302-5. Xihaier Luo, Xiaoning Qian, and Byung-Jun Yoon. Hierarchical neural operator transformer with learnable frequency-aware loss prior for arbitrary-scale super-resolution. InForty-first International Conference on Machine Learning,
-
[10]
ISSN 1364-5021. doi: 10.1098/rspa.2024.0819. URL https://doi.org/10.1098/rspa.2024.0819. Shaoxiang Qin, Fuyuan Lyu, Wenhui Peng, Dingyang Geng, Ju Wang, Xing Tang, Sylvie Leroyer, Naiping Gao, Xue Liu, and Liangzhu Leon Wang. Toward a better understanding of fourier neural operators from a spectral perspective,
-
[11]
URLhttps://arxiv.org/ abs/2404.07200. Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred A. Ham- precht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational Conference on Machine Learning (ICML), volume 97 ofProceedings of Machine Learning Research, pages 5301–5310,
-
[12]
URLhttps://doi.org/10.1214/ 20-EJS1735
doi: 10.1214/20-EJS1735. URLhttps://doi.org/10.1214/ 20-EJS1735. Pu Ren, N. Benjamin Erichson, Junyi Guo, Shashank Subramanian, Omer San, Zarija Lukic, and Michael W. Mahoney. Superbench: A super-resolution benchmark dataset for scien- tific machine learning.Journal of Data-centric Machine Learning Research,
-
[13]
Dataset Certification, Reproducibility Certification
URL https://openreview.net/forum?id=OJ6zUcWldW. Dataset Certification, Reproducibility Certification. Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors,Medical Image Computing and Computer-Assisted Inter...
2015
-
[14]
Frank Werner and Bernd Hofmann
URLhttps: //arxiv.org/abs/2512.05132. Frank Werner and Bernd Hofmann. Convergence analysis of (statistical) inverse problems under conditional stability estimates.Inverse Problems, 36(1):015004, dec
-
[15]
URLhttps://doi.org/10.1088/1361-6420/ab4cd7
doi: 10.1088/1361-6420/ab4cd7. URLhttps://doi.org/10.1088/1361-6420/ab4cd7. 20 R. Wienands and W. Joppich.Practical Fourier Analysis for Multigrid Methods. Numerical Insights. Taylor & Francis,
-
[16]
URLhttps://books.google
ISBN 9781584884927. URLhttps://books.google. com/books?id=IOSux5GxacsC. Zhikai Wu, Shiyang Zhang, Sizhuang He, Sifan Wang, Min Zhu, Anran Jiao, Lu Lu, and David van Dijk. COAST: Intelligent time-adaptive neural operators. In2nd AI for Math Workshop @ ICML 2025,
2025
-
[17]
net/forum?id=6QJZDAIhfk
URLhttps://openreview. net/forum?id=6QJZDAIhfk. 21 A Limitations and Future Work The proposed Iterative Refinement Neural Operator (IRNO) demonstrates stable conver- gence, reduced spectral error, and improved cost–performance trade-offs across multiple physical systems. Several open questions remain that point toward productive directions for future rese...
2019
-
[18]
More recent approaches have sought to mitigate spectral bias through frequency-specific boosting and scaling mechanisms
was proposed to enable nested feature computation that better captures multiscale solution spaces, by employing a scale-adaptive 22 interaction range and self-attention mechanisms over a hierarchy of levels. More recent approaches have sought to mitigate spectral bias through frequency-specific boosting and scaling mechanisms. SpecBoost was introduced as ...
2024
-
[19]
In most cases, these models are trained asdirect solversthat approximate the solution operator through a single forward evaluation
parameterize mappings in spectral or basis- function spaces, consistent with classical spectral/pseudo-spectral methods. In most cases, these models are trained asdirect solversthat approximate the solution operator through a single forward evaluation. A closer conceptual link to our framework arises in implicit layers, Deep Equilibrium Mod- els (DEQs)Bai...
2019
-
[20]
Case 2.c >0.The function (1−q)r−cr 2 is maximized atr ∗ = 1−q 2c , yielding maximum value (1−q)2 4c
Case 1.c= 0.The right-hand side is (1−q)r, giving the condition ∥b∥ ≤ (1−q)r α . Case 2.c >0.The function (1−q)r−cr 2 is maximized atr ∗ = 1−q 2c , yielding maximum value (1−q)2 4c . Therefore, a validr∈(0, δ] exists whenever ∥b∥ ≤ (1−q) 2 4αc , in which case the two positive roots of (1−q)r−cr 2 =α∥b∥are r± = (1−q)± p (1−q) 2 −4αc∥b∥ 2c , andB r(y) is fo...
2020
-
[21]
The test sets for the corresponding interpolation and ex- trapolation tasks are from 2009 and 2014–2015, respectively
The validation sets for interpolation and extrapolation (look-back) evaluation are drawn from 2012 and 2007, respectively. The test sets for the corresponding interpolation and ex- trapolation tasks are from 2009 and 2014–2015, respectively. All methods are trained and evaluated on the same splits to ensure fair comparison. For visualizations in the main ...
2012
-
[22]
The refinement operator is optimized using AdamW with an initial learning rate of 3×10 −4 and weight decay 1×10 −5
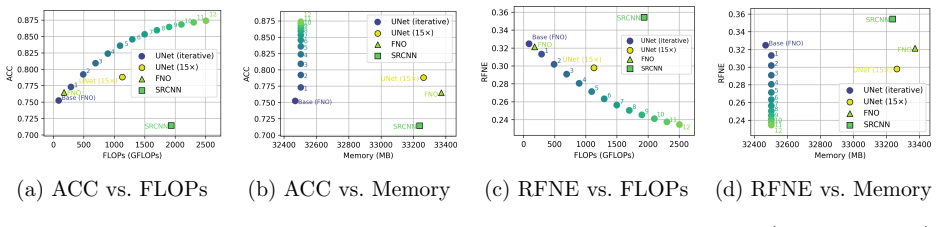
27.6 27.7 6.9 FNO + SRCNN× ×6.6 FNO + UNet (×15)× ×37.3 FNO + FNO× ×9.5 Refinement Operator Training.Algorithm 1 provides the complete training procedure for IRNO, detailing the progressive refinement steps, combined spatial-spectral losses, and fixed-point regularization. The refinement operator is optimized using AdamW with an initial learning rate of 3...
2026
-
[23]
Two complementary strategies can protect against divergence
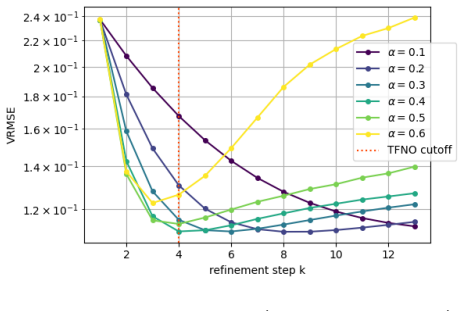
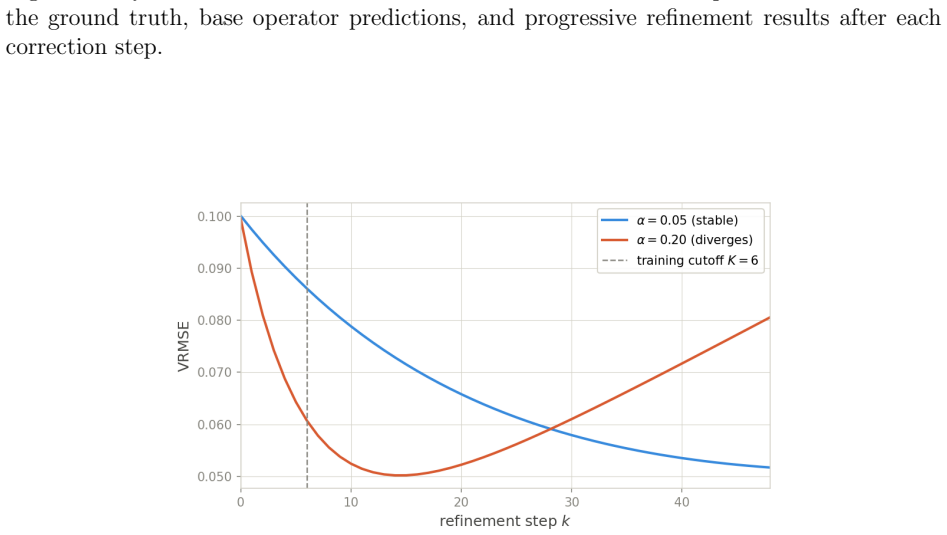
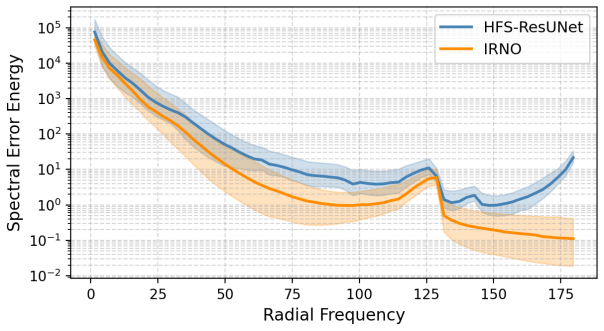
Withα= 0.05, refinement remains stable throughout without divergence. Two complementary strategies can protect against divergence. First, step-size scheduling reducesαaskincreases. Second, adaptive stopping halts iteration when∥Φ θ(x, hk)∥falls below a user-defined threshold tied to the bias level α∥b∥/(1−q) from Corollary 3.3. HFS-ResUNet and IRNO Comple...
1946
-
[24]
IRNO.Table 20 compares F-Adapter [Zhang et al., 2026] and IRNO (FNO base) on Active Matter
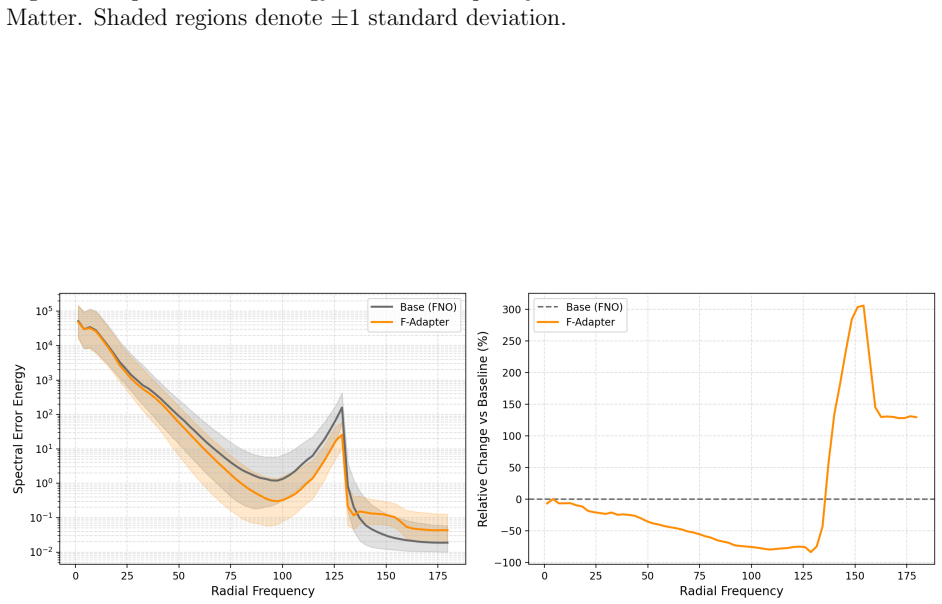
BatchNorm (ours) 0.1102 53.52% 0.1042 56.05% LayerNorm 0.1038 56.61% 0.0988 58.70% GroupNorm 0.1031 57.46% 0.1006 58.50% F-Adapter vs. IRNO.Table 20 compares F-Adapter [Zhang et al., 2026] and IRNO (FNO base) on Active Matter. F-Adapter targets minimal-parameter adaptation, achieving 2.31% VRMSE reduction with gains concentrated in mid- and high-frequency...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.