Signs Beat Floats: Low-Rank Double-Binary Adaptation for On-Device Fine-Tuning
Pith reviewed 2026-06-30 15:47 UTC · model grok-4.3
The pith
LoRDBA replaces floating-point LoRA factors with binary sign carriers and channel-wise scales for on-device adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
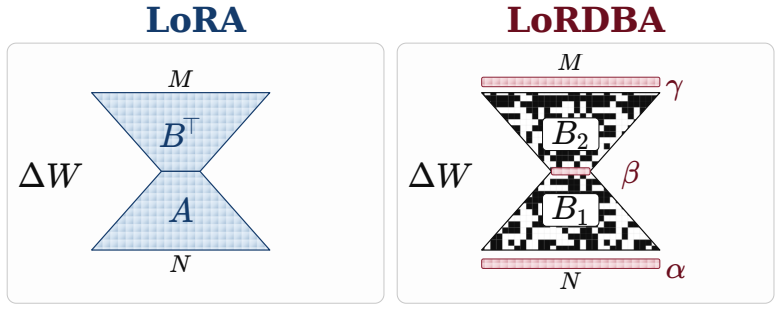
LoRDBA converts the pair of low-rank matrices in a LoRA adapter into binary sign carriers together with lightweight channel-wise scale vectors, so the adapter update is realized through sign-accumulation matrix multiplications rather than dense floating-point operations; a supporting finite-sample bound shows that reconstruction quality is governed by the residual-to-magnitude ratio of the original factors.
What carries the argument
Double-binary adapter: binary sign carriers for the low-rank factors paired with channel-wise magnitude scales
If this is right
- Adapter storage drops by more than a factor of ten relative to fp16 LoRA at matched rank.
- Unmerged adapter-mode prefill latency rises by at most 8 percent at rank 16.
- Training memory overhead stays around 1.6 times that of fp16 LoRA.
- Downstream quality exceeds low-bit baselines at equal model size and reaches fp16 LoRA levels in selected regimes.
Where Pith is reading between the lines
- Smaller adapters make frequent hot-swapping or over-the-air distribution of task-specific updates far more practical on memory-constrained devices.
- The sign-accumulation pattern may map directly onto integer or bitwise hardware units already present in many edge chips.
- The same residual-to-magnitude analysis could be applied to other low-rank parameter-efficient methods to predict when sign compression will succeed.
- Testing the method on models where the learned factors exhibit higher residual ratios would map the practical operating envelope.
Load-bearing premise
The residual-to-magnitude ratio of the original LoRA factors stays low enough that binary signs plus per-channel scales preserve the necessary update information.
What would settle it
Run the same fine-tuning task but select a regime or initialization where the residual-to-magnitude ratio of the learned LoRA factors is deliberately high and measure whether LoRDBA then falls behind fp16 LoRA on downstream accuracy or reconstruction error.
Figures
read the original abstract
On-device adaptation of large language models commonly keeps a quantized base model frozen while training and deploying a small, task-specific LoRA adapter. In the unmerged adapter-mode setting, however, the adapter is more than a compact storage module; it introduces an additional dense floating-point branch, maintains a trainable state for local updates, and acts as a unit of communication and hot-swapping.We introduce LoRDBA, a LoRA-compatible adapter that replaces both low-rank factors with binary sign carriers while representing magnitudes through lightweight, channel-wise scales, converting the dense adapter branch into two sign-accumulation matrix multiplications interleaved with channel-wise scaling. A finite-sample analysis shows that reconstruction quality is governed by the residual-to-magnitude ratio of the original LoRA factors. In adapter-mode experiments, LoRDBA outperforms low-bit baselines at matched model sizes while matching fp16 LoRA quality in selected regimes. The unmerged adapter incurs at most 8% prefill latency overhead at matched rank r=16 despite an over 10x reduction in adapter footprint, with moderate training memory overhead of approximately 1.6x that of fp16 LoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoRDBA, a LoRA-compatible adapter that replaces both low-rank factors with binary sign carriers and represents magnitudes via lightweight channel-wise scales. This converts the adapter into sign-accumulation matrix multiplications interleaved with scaling. A finite-sample analysis is claimed to show that reconstruction quality is governed by the residual-to-magnitude ratio of the original LoRA factors. In adapter-mode experiments, LoRDBA is reported to outperform low-bit baselines at matched sizes while matching fp16 LoRA quality in selected regimes, with at most 8% prefill latency overhead at r=16, over 10x footprint reduction, and ~1.6x training memory overhead relative to fp16 LoRA.
Significance. If the finite-sample analysis and empirical claims hold, the method could meaningfully reduce adapter storage and communication costs for on-device LLM adaptation while preserving quality, which addresses a practical bottleneck in edge deployment. The conversion to sign-accumulation operations offers a concrete path toward lower-bit dense branches without full quantization of the adapter.
major comments (2)
- [Abstract / finite-sample analysis] The finite-sample analysis (referenced in the abstract) is load-bearing for the central claim that binary sign carriers plus channel-wise scales preserve sufficient update information. The manuscript supplies neither the derivation steps nor any bound or empirical distribution of the residual-to-magnitude ratio across LoRA updates, so it is impossible to determine the regimes in which the approximation error remains controlled.
- [Abstract / experimental results] The strongest experimental claim (outperformance over low-bit baselines and fp16 LoRA parity at r=16) is stated without supporting data, error bars, task details, or tables in the provided text. This leaves the quality and latency claims (8% overhead, 10x footprint reduction) unverified and prevents assessment of whether the reconstruction guarantee translates to the reported results.
minor comments (2)
- [Method description] Clarify the exact procedure for computing and quantizing the channel-wise scales during both training and inference, including any additional storage or computation they introduce.
- [Experiments] The abstract states results for 'selected regimes' without defining the selection criteria or reporting negative cases; include a broader set of tasks and failure modes in the experiments section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for greater transparency on the finite-sample analysis and experimental support. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / finite-sample analysis] The finite-sample analysis (referenced in the abstract) is load-bearing for the central claim that binary sign carriers plus channel-wise scales preserve sufficient update information. The manuscript supplies neither the derivation steps nor any bound or empirical distribution of the residual-to-magnitude ratio across LoRA updates, so it is impossible to determine the regimes in which the approximation error remains controlled.
Authors: We agree the derivation and supporting bounds are insufficiently detailed in the current version. Section 3 sketches the finite-sample argument but omits the full steps and any empirical distribution of the residual-to-magnitude ratio. In revision we will expand Section 3 with the complete derivation, explicit bounds on reconstruction error, and histograms/plots of the ratio computed on the LoRA factors from our training runs. This will directly address the regimes in which the approximation remains controlled. revision: yes
-
Referee: [Abstract / experimental results] The strongest experimental claim (outperformance over low-bit baselines and fp16 LoRA parity at r=16) is stated without supporting data, error bars, task details, or tables in the provided text. This leaves the quality and latency claims (8% overhead, 10x footprint reduction) unverified and prevents assessment of whether the reconstruction guarantee translates to the reported results.
Authors: The abstract summarizes results whose supporting data, error bars, task specifications, and tables appear in Sections 4–5 of the full manuscript. Because the referee’s copy appears to have contained only the abstract, we will revise the abstract to include explicit forward references to those sections and will add a short results summary table in the abstract itself if space permits. The underlying numbers (including the 8 % prefill overhead and >10× footprint reduction at r=16) remain unchanged. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The abstract claims a finite-sample analysis governs reconstruction quality via the residual-to-magnitude ratio but supplies neither equations nor a derivation. No self-definitional steps, fitted inputs renamed as predictions, self-citation load-bearing arguments, or other enumerated circular patterns appear in the provided text. Central claims rest on experimental comparisons rather than a closed loop reducing to inputs by construction, rendering the work self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantization error propagation: Revisiting layer-wise post-training quantization
Yamato Arai and Yuma Ichikawa. Quantization error propagation: Revisiting layer-wise post-training quantization. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[2]
Attouch, J
H. Attouch, J. Bolte, P. Redont, and A. Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the K urdyka-- ojasiewicz inequality. Mathematics of Operations Research, 35 0 (2): 0 438--457, 2010
2010
-
[3]
Attouch, J
H. Attouch, J. Bolte, and B. F. Svaiter. Convergence of descent methods for semi-algebraic and tame problems: Proximal algorithms, forward--backward splitting, and regularized G auss-- S eidel methods. Mathematical Programming, 137 0 (1--2): 0 91--129, 2013
2013
-
[4]
gemlite : Cuda kernels for low-bit matrix multiplication, 2023
Hicham Badri and Appu Shaji. gemlite : Cuda kernels for low-bit matrix multiplication, 2023. https://github.com/mobiusml/gemlite
2023
-
[5]
Bolte, A
J. Bolte, A. Daniilidis, and A. Lewis. The ojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM Journal on Optimization, 17 0 (4): 0 1205--1223, 2007
2007
-
[6]
Distributed optimization and statistical learning via the alternating direction method of multipliers
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3 0 (1): 0 1--122, 2011
2011
-
[7]
Two sparse matrices are better than one: Sparsifying neural networks with double sparse factorization
Vladim \'i r Bo z a and Vladim \'i r Macko. Two sparse matrices are better than one: Sparsifying neural networks with double sparse factorization. In International Conference on Learning Representations (ICLR), 2025 a
2025
-
[8]
Addition is almost all you need: Compressing large language models with double binary factorization
Vladim \'i r Bo z a and Vladim \'i r Macko. Addition is almost all you need: Compressing large language models with double binary factorization. In International Conference on Machine Learning (ICML), 2025 b
2025
-
[9]
Punica : Multi-tenant LoRA serving
Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. Punica : Multi-tenant LoRA serving. In Proceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[10]
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or -1 . arXiv preprint arXiv:1602.02830, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
QLoRA : Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA : Efficient finetuning of quantized llms. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ : Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
A framework for few-shot language model evaluation
Leo Gao, Jonathan Tow, Stella Biderman, et al. A framework for few-shot language model evaluation. https://github.com/EleutherAI/lm-evaluation-harness, 2023
2023
-
[14]
LoRA+ : Efficient low rank adaptation of large models
Soufiane Hayou, Nikhil Ghosh, and Bin Yu. LoRA+ : Efficient low rank adaptation of large models. In International Conference on Machine Learning (ICML), 2024
2024
-
[15]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[16]
Controlling continuous relaxation for combinatorial optimization
Yuma Ichikawa. Controlling continuous relaxation for combinatorial optimization. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[17]
Optimization by parallel quasi-quantum annealing with gradient-based sampling
Yuma Ichikawa and Yamato Arai. Optimization by parallel quasi-quantum annealing with gradient-based sampling. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
LPCD : Unified framework from layer-wise to submodule quantization
Yuma Ichikawa, Yudai Fujimoto, and Akira Sakai. LPCD : Unified framework from layer-wise to submodule quantization. arXiv preprint arXiv:2512.01546, 2025 a
-
[19]
More than bits: Multi-envelope double binary factorization for extreme quantization
Yuma Ichikawa, Yoshihiko Fujisawa, Yudai Fujimoto, Akira Sakai, and Katsuki Fujisawa. More than bits: Multi-envelope double binary factorization for extreme quantization. arXiv preprint arXiv:2512.24545, 2025 b
-
[20]
arXiv preprint arXiv:2510.10693 (2025)
Yuma Ichikawa, Shuhei Kashiwamura, and Ayaka Sakata. High-dimensional learning dynamics of quantized models with straight-through estimator. arXiv preprint arXiv:2510.10693, 2025 c
-
[21]
OneComp : One-line revolution for generative AI model compression
Yuma Ichikawa, Keiji Kimura, Akihiro Yoshida, Yudai Fujimoto, Hiroki Tokura, Yamato Arai, Yoshiyuki Ishii, Yusei Kawakami, Genki Shikada, Achille Jacquemond, Yoshihiko Fujisawa, Katsuki Fujisawa, Takumi Honda, and Akira Sakai. OneComp : One-line revolution for generative AI model compression. arXiv preprint arXiv:2603.28845, 2026
-
[22]
Kopiczko, Tijmen Blankevoort, and Yuki M
Dawid J. Kopiczko, Tijmen Blankevoort, and Yuki M. Asano. VeRA : Vector-based random matrix adaptation. In International Conference on Learning Representations (ICLR), 2024
2024
-
[23]
Extremely low bit neural network: Squeeze the last bit out with ADMM
Cong Leng, Zesheng Dou, Hao Li, Shenghuo Zhu, and Rong Jin. Extremely low bit neural network: Squeeze the last bit out with ADMM . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[24]
LoftQ : LoRA -fine-tuning-aware quantization for large language models
Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, and Tuo Zhao. LoftQ : LoRA -fine-tuning-aware quantization for large language models. In International Conference on Learning Representations (ICLR), 2024
2024
-
[25]
AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration. Proceedings of Machine Learning and Systems, 6, 2024
2024
-
[26]
Lee, Song Han, Tri Dao, and Tianle Cai
James Liu, Guangxuan Xiao, Kai Li, Jason D. Lee, Song Han, Tri Dao, and Tianle Cai. BitDelta : Your fine-tune may only be worth one bit. In Advances in Neural Information Processing Systems (NeurIPS), 2024 a
2024
-
[27]
DoRA : Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA : Weight-decomposed low-rank adaptation. International Conference on Machine Learning (ICML), 2024 b
2024
-
[28]
ReActNet : Towards precise binary neural network with generalized activation functions
Zechun Liu, Zhiqiang Shen, Marios Savvides, and Kwang-Ting Cheng. ReActNet : Towards precise binary neural network with generalized activation functions. In European Conference on Computer Vision (ECCV), 2020
2020
-
[29]
PiSSA : Principal singular values and singular vectors adaptation of large language models
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. PiSSA : Principal singular values and singular vectors adaptation of large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[30]
LoRAQuant : Mixed-precision quantization of LoRA to ultra-low bits
Amir Reza Mirzaei, Yuqiao Wen, Yanshuai Cao, and Lili Mou. LoRAQuant : Mixed-precision quantization of LoRA to ultra-low bits. arXiv preprint arXiv:2510.26690, 2025
-
[31]
XNOR-Net : I magenet classification using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. XNOR-Net : I magenet classification using binary convolutional neural networks. In European Conference on Computer Vision (ECCV), 2016
2016
-
[32]
S-LoRA : Serving thousands of concurrent LoRA adapters
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph Gonzalez, and Ion Stoica. S-LoRA : Serving thousands of concurrent LoRA adapters. In Proceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[33]
Douglas-- R achford splitting and ADMM for nonconvex optimization: Tight convergence results
Andreas Themelis and Panagiotis Patrinos. Douglas-- R achford splitting and ADMM for nonconvex optimization: Tight convergence results. SIAM Journal on Optimization, 30 0 (1): 0 149--181, 2020
2020
-
[34]
High-Dimensional Probability: An Introduction with Applications in Data Science
Roman Vershynin. High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, 2018
2018
-
[35]
BitNet: Scaling 1-bit Transformers for Large Language Models
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. BitNet : Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Global convergence of ADMM in nonconvex nonsmooth optimization
Yu Wang, Wotao Yin, and Jinshan Zeng. Global convergence of ADMM in nonconvex nonsmooth optimization. Journal of Scientific Computing, 78 0 (1): 0 29--63, 2019
2019
-
[37]
QA-LoRA : Quantization-aware low-rank adaptation of large language models
Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, and Qi Tian. QA-LoRA : Quantization-aware low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2024 a
2024
-
[38]
OneBit : Towards extremely low-bit large language models
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. OneBit : Towards extremely low-bit large language models. arXiv preprint arXiv:2402.11295, 2024 b
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.