Verified SHAP: Provable Bounds for Exact Shapley Values of Neural Networks
Pith reviewed 2026-06-30 16:38 UTC · model grok-4.3
The pith
Neural network verification can recover exact Shapley values by tightening bounds on feature contributions until they match.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
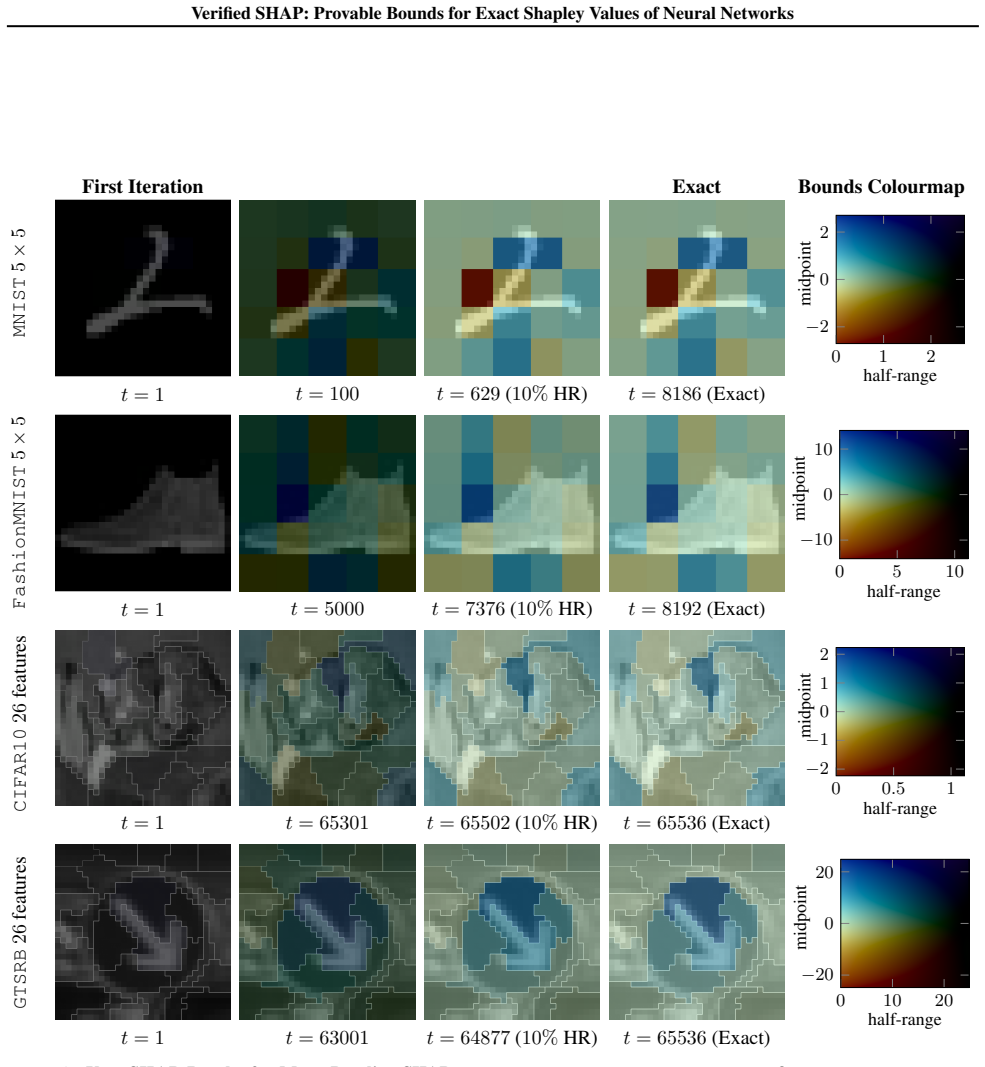
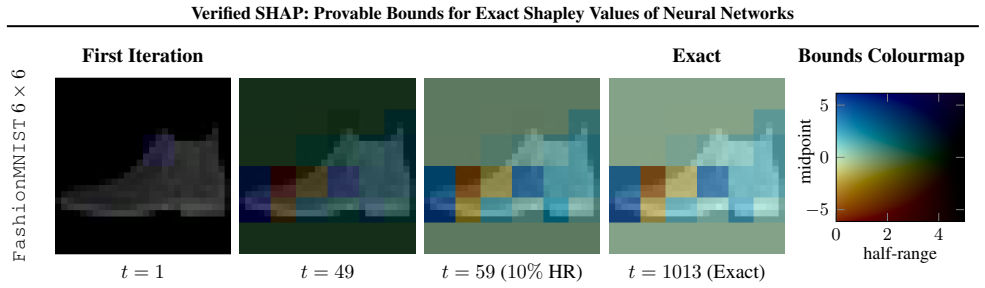
The central claim is that an algorithm can formulate each coalition evaluation in the Shapley formula as a neural-network verification query. Solving these queries yields provably correct lower and upper bounds on the corresponding marginal contributions. The bounds are refined until the interval collapses to a single point, recovering the exact Shapley value for every feature. Experiments confirm that the procedure handles input dimensions far beyond the reach of previous exact SHAP algorithms while still terminating with the true values.
What carries the argument
The reduction of Shapley coalition marginals to neural-network verification problems that return certified bounds on the network output.
If this is right
- Exact Shapley values become computable for neural networks whose feature count exceeds the limits of prior exact methods.
- Statistical approximation techniques can now be benchmarked against ground-truth values on larger instances.
- Certified bounds remain available even when exact values are still out of reach, supporting safety arguments that rely on contribution ranges.
- The same verification machinery can be reused for related attribution scores that also require summing over coalitions.
Where Pith is reading between the lines
- The same bounding technique could be applied to other additive feature-attribution schemes that share the coalition structure of Shapley values.
- Hybrid pipelines might use the certified bounds to decide when a cheaper approximation is already sufficiently accurate.
- The method opens a path to certified fairness audits that treat exact feature contributions as the reference quantity.
Load-bearing premise
Existing verification engines can be applied to the sub-networks and queries that arise from Shapley coalition evaluations without prohibitive cost or loss of tightness.
What would settle it
On a small network whose exact Shapley values are known by exhaustive enumeration, the algorithm's bounds fail to converge to those known values after repeated refinement.
Figures

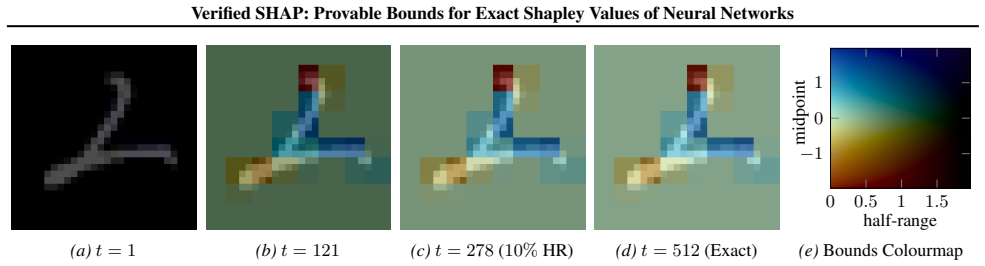

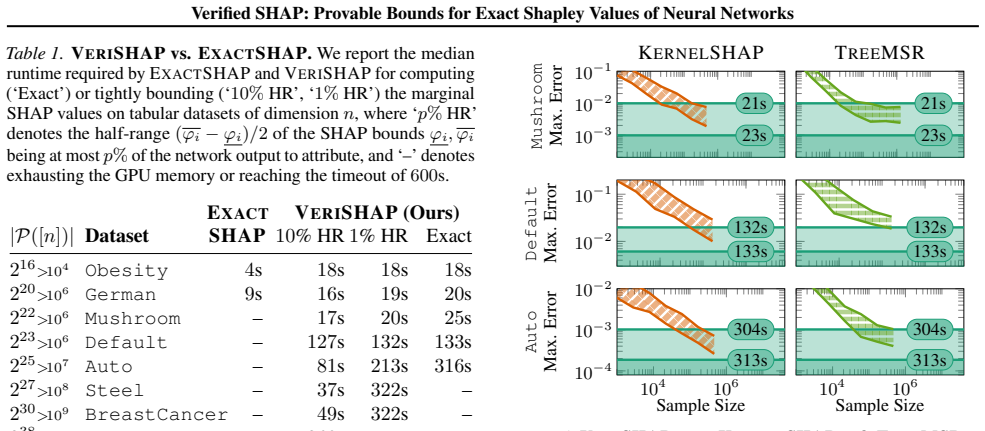
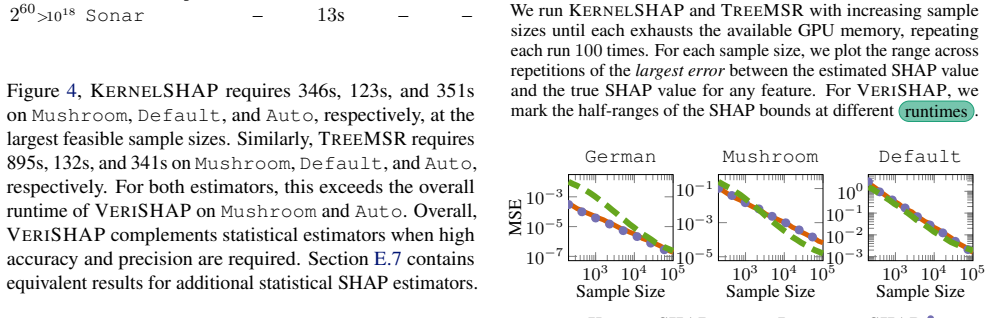
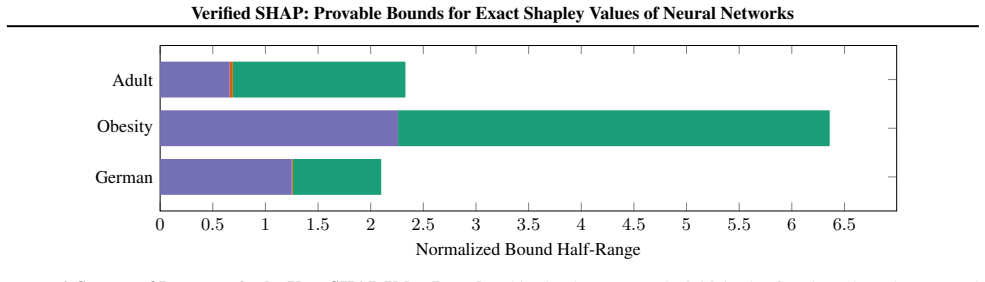
read the original abstract
Shapley additive explanations (SHAP) are widely recognised as computationally intractable for neural networks, since they induce an exponential search space over the input features. In this work, we take a first step towards scaling exact SHAP computation to larger search spaces by introducing an algorithm that leverages recent advances in neural network verification to compute arbitrarily tight exact lower and upper bounds on SHAP values for neural networks, ultimately recovering the exact SHAP values. We demonstrate that our approach scales to orders of magnitude larger search spaces than state-of-the-art exact methods. This provides an important first step towards exact SHAP computation and establishes a principled cornerstone for evaluating statistical approximation methods on larger search spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Verified SHAP, an algorithm that applies recent neural network verification advances to compute arbitrarily tight lower and upper bounds on Shapley values for neural networks. By tightening these bounds sufficiently, the method recovers exact SHAP values and is claimed to scale to search spaces orders of magnitude larger than prior exact methods, providing a foundation for evaluating statistical approximations on bigger instances.
Significance. If the scaling and exact-recovery claims hold, the work is significant because exact SHAP computation has been intractable for neural networks due to the exponential coalition space; verification-based bounding offers a principled route to exact values without enumeration. The approach directly leverages external verification progress rather than inventing new parameters or self-referential definitions, which strengthens its potential as a cornerstone for XAI evaluation.
major comments (1)
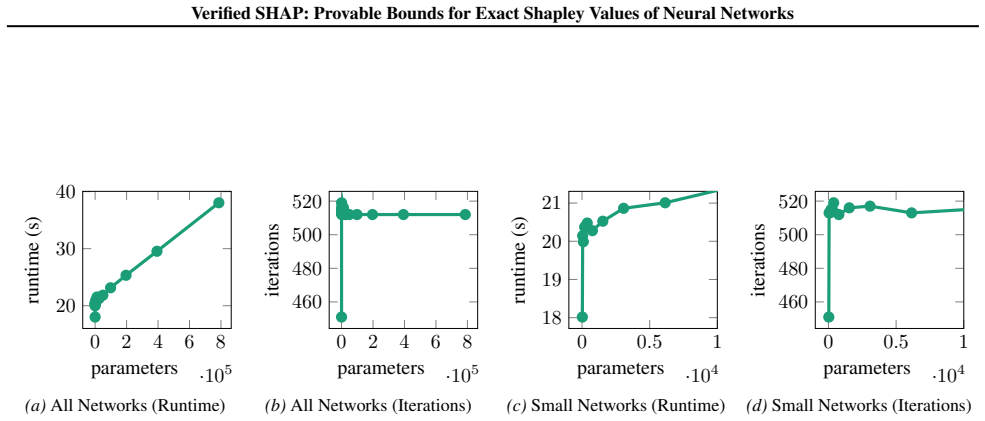
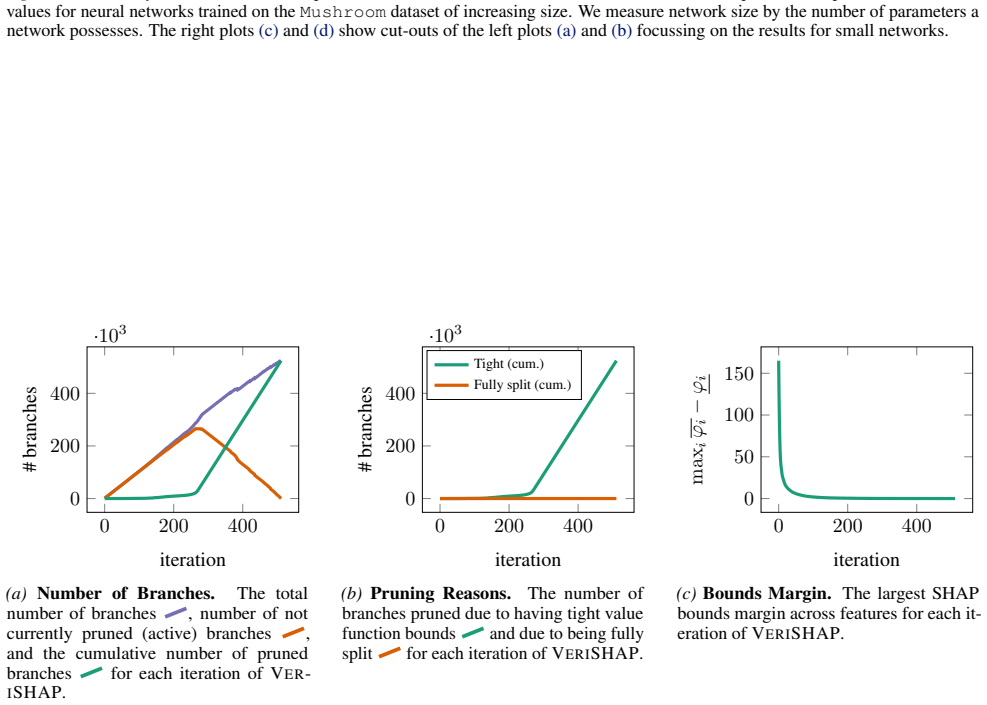
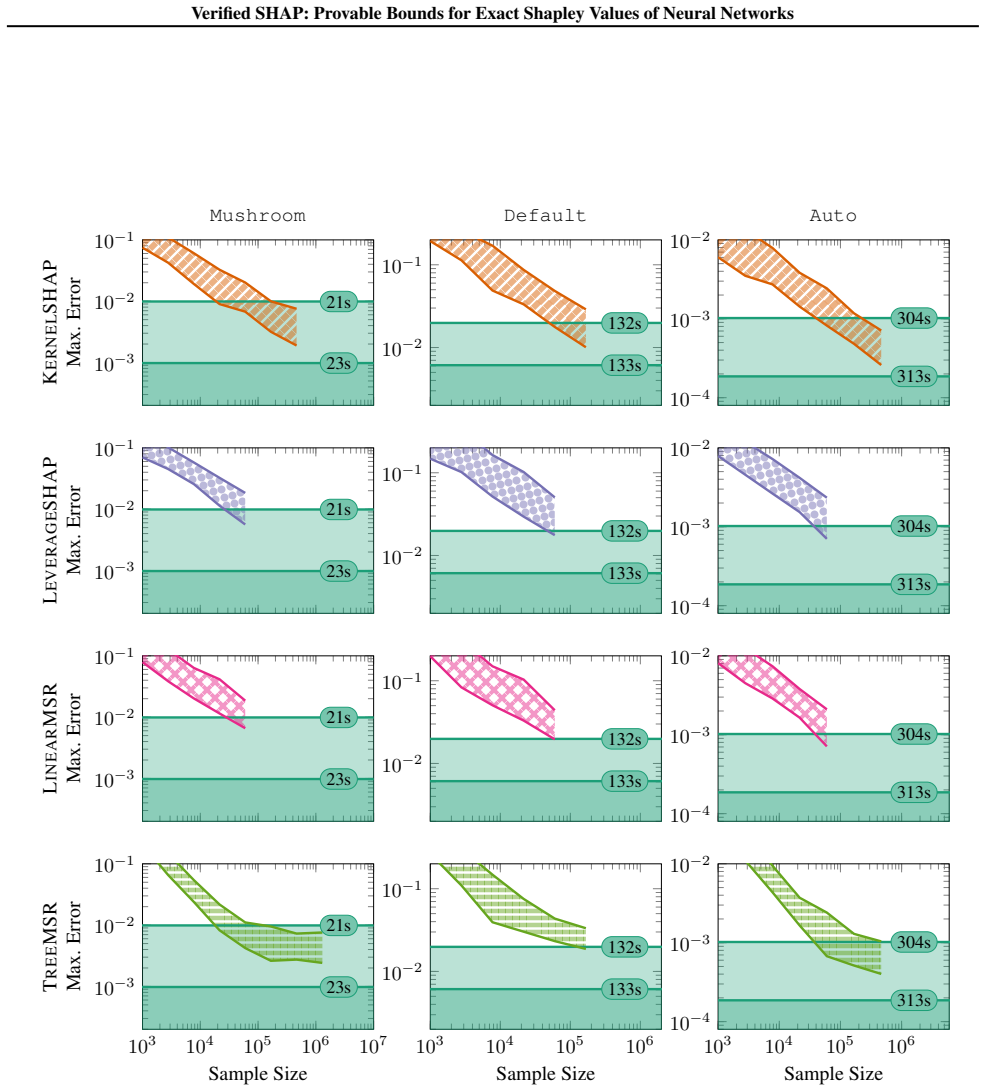
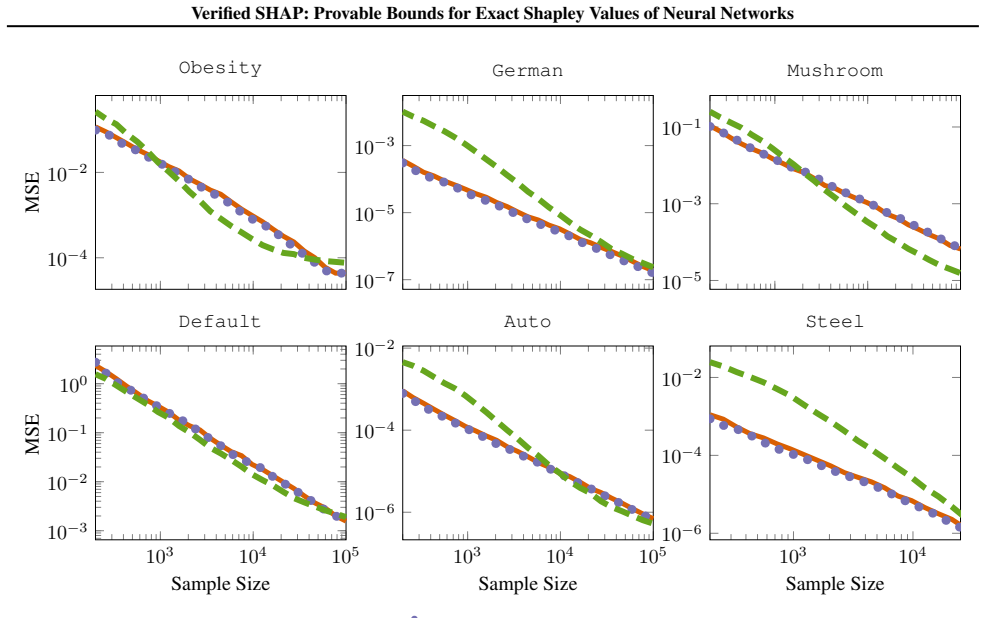
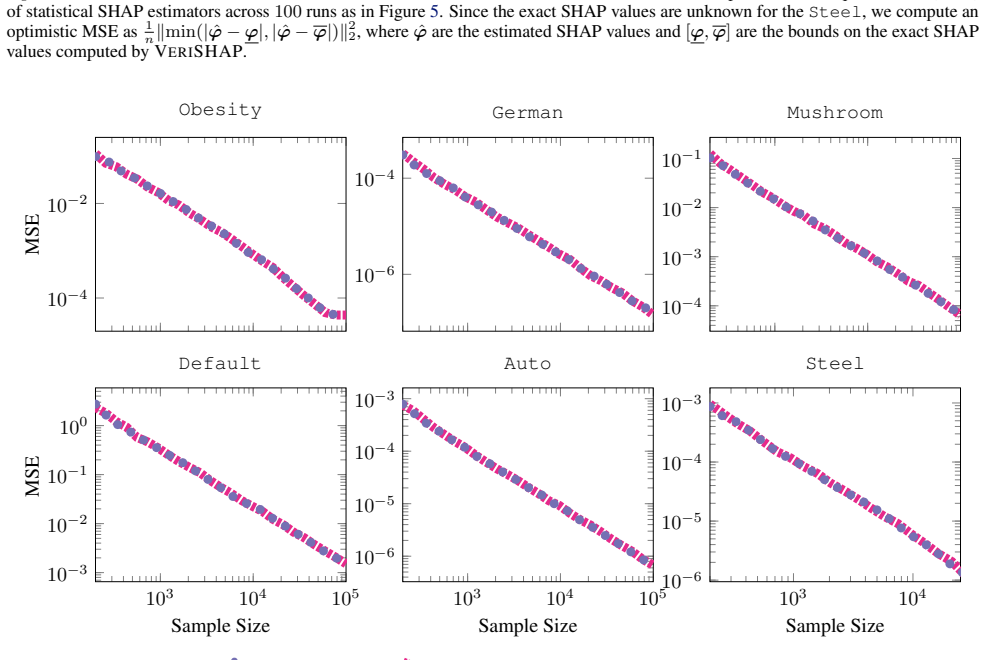
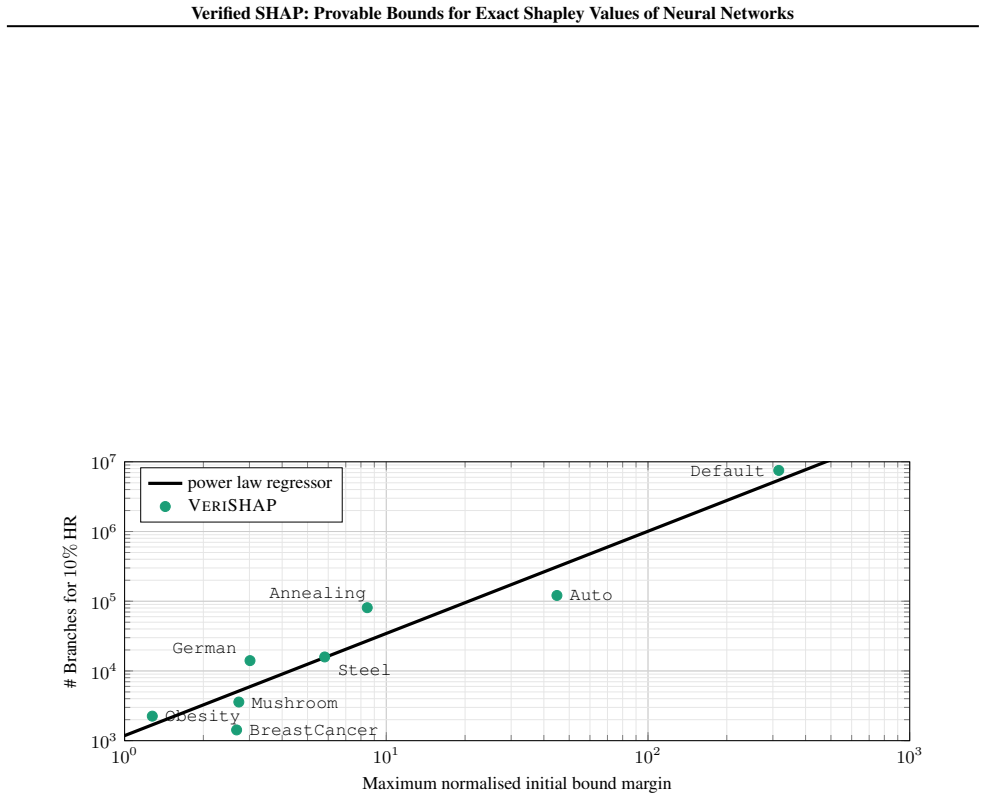
- [Abstract and §4 (experiments)] The central claim requires that verification engines can be applied to the exponentially many coalition-specific queries (marginal contributions f(x_S ∪ {i}) − f(x_S) under input masks) while maintaining tightness sufficient to recover exact values and without prohibitive cost. The manuscript must supply concrete benchmarks (network widths/depths, feature counts, verification timeouts, and bound gaps) showing that coalition encodings do not introduce disjunctions that cause looseness on ReLU networks, as this assumption is load-bearing for both the 'arbitrarily tight' recovery and the reported scaling advantage.
minor comments (1)
- [Abstract] The abstract states that the method 'demonstrates' scaling but provides no quantitative details on network sizes, runtimes, or tightness metrics; moving a concise summary of the key experimental parameters into the abstract would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the emphasis on substantiating the central claims with concrete experimental details. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and §4 (experiments)] The central claim requires that verification engines can be applied to the exponentially many coalition-specific queries (marginal contributions f(x_S ∪ {i}) − f(x_S) under input masks) while maintaining tightness sufficient to recover exact values and without prohibitive cost. The manuscript must supply concrete benchmarks (network widths/depths, feature counts, verification timeouts, and bound gaps) showing that coalition encodings do not introduce disjunctions that cause looseness on ReLU networks, as this assumption is load-bearing for both the 'arbitrarily tight' recovery and the reported scaling advantage.
Authors: We agree that the manuscript should provide more granular experimental evidence to support the claims of arbitrary tightness and scaling. In the revised version we will expand §4 with additional tables and text that report: (i) explicit network widths and depths for all evaluated models, (ii) feature counts ranging from the small instances used by prior exact methods up to the larger spaces claimed, (iii) per-query verification timeouts and total runtime, and (iv) the numerical bound gaps (upper minus lower) achieved on the marginal-contribution queries before exact recovery. We will also add a dedicated paragraph on the coalition-encoding construction, showing that the input-masking formulation introduces no new disjunctive constraints beyond the existing ReLU activations; the verifier therefore inherits the same tightness guarantees as standard ReLU verification, which we will illustrate with both a short formal argument and empirical bound-gap statistics confirming that gaps close to machine precision within the reported budgets. revision: yes
Circularity Check
No circularity; derivation applies external verification to SHAP queries
full rationale
The paper's central algorithm applies existing neural network verification engines to compute bounds on marginal contributions within the SHAP formula, recovering exact values when bounds become tight. No equations redefine SHAP in terms of the verification outputs, no fitted parameters are relabeled as predictions, and no load-bearing steps reduce to self-citations or author-specific uniqueness theorems. The method is self-contained against external benchmarks because it treats verification advances as independent primitives rather than deriving them from the SHAP application itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural network verification tools can produce arbitrarily tight bounds on the output of sub-queries corresponding to feature coalitions in SHAP computation.
Reference graph
Works this paper leans on
-
[1]
URL https://doi.org /10.1609/aaai.v36i5.20484
AAAI Press, 2022. URL https://doi.org /10.1609/aaai.v36i5.20484. Baniecki, H., Muschalik, M., Fumagalli, F., Hammer, B., H¨ullermeier, E., and Biecek, P. Explaining similarity in vision-language encoders with weighted Banzhaf inter- actions.CoRR, abs/2508.05430, 2025. URL https: //doi.org/10.48550/arXiv.2508.05430. Barcel´o, P., Cominetti, R., and Morgado...
-
[2]
URL https://openreview.net/forum?i d=nOfSWmPYL5. Becker, B. and Kohavi, R. Adult. UCI Machine Learning Repository, 1996. URL https://doi.org /10.24432/C5XW20. Biradar, G., Izza, Y ., Lobo, E. A., Viswanathan, V ., and Zick, Y . Axiomatic aggregations of abductive explanations. In AAAI, pp. 11096–11104. AAAI Press, 2024. URL http s://doi.org/10.1609/aaai.v...
-
[3]
URL https://proceedings.m lr.press/v202/chen23s.html
PMLR, 2023. URL https://proceedings.m lr.press/v202/chen23s.html. Chen, Y ., Hua, F., Jin, Y ., and Zhang, E. Z. BGPQ: A heap-based priority queue design for GPUs. InICPP, pp. 9:1–9:10. ACM, 2021. URL https://doi.org /10.1145/3472456.3472463. Chiu, H., Chen, H., Zhang, H., and Zhang, R. Y . SDP- CROWN: Efficient bound propagation for neural network verifi...
-
[4]
Fernandes, K., Vinagre, P., and Cortez, P
URL https://openreview.net/forum?i d=ky7vVlBQBY. Fernandes, K., Vinagre, P., and Cortez, P. A pro- active intelligent decision support system for predict- ing the popularity of online news. InEPIA, volume 9273 ofLecture Notes in Computer Science, pp. 535–546. Springer, 2015. URL https://doi.org /10.1007/978-3-319-23485-4 53. Ferrari, C., M ¨uller, M. N., ...
-
[5]
URL https://openreview.net/forum?i d=l amHf1oaK. Fryer, D. V ., Str¨umke, I., and Nguyen, H. D. Shapley values for feature selection: The good, the bad, and the axioms. IEEE Access, 9:144352–144360, 2021. URL https: //doi.org/10.1109/ACCESS.2021.3119110. Fumagalli, F., Muschalik, M., Kolpaczki, P., H ¨uller- meier, E., and Hammer, B. SHAP-IQ: Unified appr...
-
[6]
Izza, Y ., Huang, X., Morgado, A., Planes, J., Ignatiev, A., and Marques-Silva, J
URL https://doi.org/10.1609/aaai.v 33i01.33011511. Izza, Y ., Huang, X., Morgado, A., Planes, J., Ignatiev, A., and Marques-Silva, J. Distance-restricted explanations: Theoretical underpinnings & efficient implementation. InKR, 2024. URL https://doi.org/10.24963/k r.2024/45. Jethani, N., Sudarshan, M., Covert, I. C., Lee, S., and Ran- ganath, R. FastSHAP:...
-
[7]
Kotha, S., Brix, C., Kolter, J
URL https://proceedings.mlr.press/v 238/kolpaczki24a.html. Kotha, S., Brix, C., Kolter, J. Z., Dvijotham, K., and Zhang, H. Provably bounding neural network preimages.NeurIPS, 36:80270–80290, 2023. URL http://papers.nips.cc/paper files/paper /2023/hash/fe061ec0ae03c5cf5b5323a2b 9121bfd-Abstract-Conference.html. Krizhevsky, A. Learning multiple layers of f...
2023
-
[8]
URL https://www.cs.toronto.edu/˜kri z/learning-features-2009-TR.pdf. Kumar, I. E., Venkatasubramanian, S., Scheidegger, C., and Friedler, S. A. Problems with Shapley-value-based ex- planations as feature importance measures. InICML, volume 119 ofProceedings of Machine Learning Re- search, pp. 5491–5500. PMLR, 2020. URL http://p roceedings.mlr.press/v119/k...
-
[9]
Amortized Linear-time Exact Shapley Value for Product-Kernel Methods
URL https://proceedings.neurips.c c/paper/2017/hash/8a20a8621978632d76c 43dfd28b67767-Abstract.html. Lundberg, S. M., Erion, G. G., Chen, H., DeGrave, A. J., Prutkin, J. M., Nair, B., Katz, R., Himmelfarb, J., Bansal, N., and Lee, S. From local explanations to global un- derstanding with explainable AI for trees.Nat. Mach. Intell., 2(1):56–67, 2020. URL h...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s42256-019-0138-9 2017
-
[10]
URL https://openreview.net/forum?i d=9tKC0YM8sX. Musco, C. and Witter, R. T. Provably accurate Shapley value estimation via leverage score sampling. InICLR. OpenReview.net, 2025. URL https://openrevie w.net/forum?id=wg3rBImn3O. Mushroom. Mushroom Dataset. UCI Machine Learn- ing Repository, 1981. URL https://doi.org /10.24432/C5959T. Nasr, M., El-Bahnasy, ...
-
[11]
URL https://doi.org/10.1109/ICENC O.2017.8289800. Neubert, P. and Protzel, P. Compact watershed and preempt- ive SLIC: on improving trade-offs of superpixel segment- ation algorithms. InICPR, pp. 996–1001. IEEE Computer Society, 2014. URL https://doi.org/10.1109/I CPR.2014.181. Palechor, F. M. and de la Hoz Manotas, A. Dataset for estimation of obesity le...
-
[12]
Singh, G., Gehr, T., P ¨uschel, M., and Vechev, M
URLhttps://doi.org/10.24432/C5T01Q. Singh, G., Gehr, T., P ¨uschel, M., and Vechev, M. T. An abstract domain for certifying neural networks.Proc. ACM Program. Lang., 3(POPL):41:1–41:30, 2019. URL https://doi.org/10.1145/3290354. Slack, D., Hilgard, S., Jia, E., Singh, S., and Lakka- raju, H. Fooling LIME and SHAP: Adversarial at- tacks on post hoc explana...
-
[13]
URL https://openreview.net/forum?i d=nVZtXBI6LNn. Yang, J. Fast TreeSHAP: Accelerating SHAP value com- putation for trees.CoRR, abs/2109.09847, 2021. URL https://arxiv.org/abs/2109.09847. Yeh, I. and Lien, C. The comparisons of data mining tech- niques for the predictive accuracy of probability of default of credit card clients.Expert Syst. Appl., 36(2):2...
work page doi:10.1016/j.e 2021
-
[14]
Zhang, H., Chen, H., Xiao, C., Gowal, S., Stanforth, R., Li, B., Boning, D
URL https://proceedings.neurips .cc/paper/2018/hash/d04863f100d59b3e b688a11f95b0ae60-Abstract.html. Zhang, H., Chen, H., Xiao, C., Gowal, S., Stanforth, R., Li, B., Boning, D. S., and Hsieh, C. Towards stable and efficient training of verifiably robust neural networks. In ICLR. OpenReview.net, 2020. URL https://openr eview.net/forum?id=Skxuk1rFwB. Zhou, ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.