D2-V2X: Depth-Driven Cooperative V2X Reasoning for Autonomous Driving
Pith reviewed 2026-06-30 15:37 UTC · model grok-4.3
The pith
Aligning cooperative 3D LiDAR with vision-language models raises occluded hazard recall to 24.4 percent and cuts spatial error by 77 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
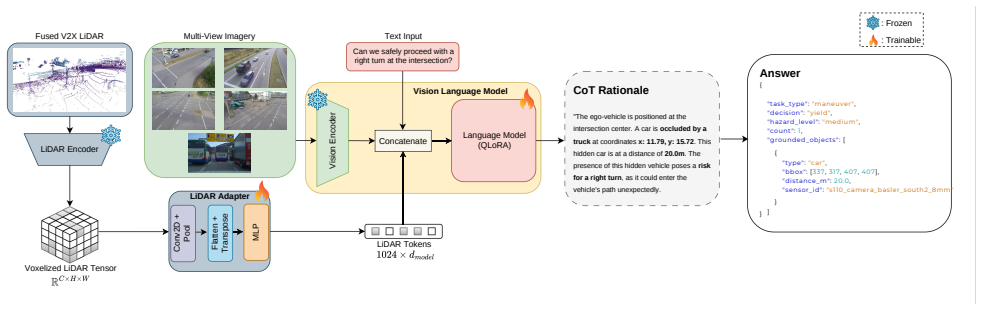
Grounding VLMs in cooperative LiDAR through latent-space alignment, combined with enforced natural-language Chain-of-Thought rationales before structured outputs, produces 24.4 percent recall on occluded hazards where zero-shot models achieve near zero, reduces spatial estimation error on visible objects by 77 percent, and yields a 53.5 F1 decision-making score, while identifying 3D-to-2D projection as the remaining architectural bottleneck.
What carries the argument
The D2-V2X Question-Rationale-Answer benchmark together with the 3D LiDAR feature alignment method that inserts explicit spatial reasoning via natural-language Chain-of-Thought steps.
If this is right
- V2X sensor fusion can supply the missing spatial context that single-vehicle VLMs lack.
- Decision-making performance reaches a functional F1-score of 53.5 under the aligned setup.
- 3D-to-2D projection remains the primary limit on further gains in current VLM designs.
- The 8500-triplet benchmark supplies a concrete testbed for measuring future cooperative-reasoning improvements.
Where Pith is reading between the lines
- The same alignment technique could be tested on other sensor types such as radar if equivalent feature projections are defined.
- Communication latency in real V2X networks may reduce the reported gains unless the model is made robust to delayed or partial LiDAR streams.
- The benchmark could serve as an evaluation suite for non-VLM multimodal architectures that also process 3D point clouds.
Load-bearing premise
Requiring natural language Chain-of-Thought rationales before JSON outputs forces the model to articulate spatial relations explicitly rather than relying on dataset patterns.
What would settle it
Train an otherwise identical model that receives the same LiDAR alignment but skips the Chain-of-Thought step and measure whether occluded-hazard recall stays near 24.4 percent or drops to near zero.
Figures


read the original abstract
Single-vehicle Vision-Language Models (VLMs) are fundamentally constrained by sensor occlusions. While Vehicle-to-Everything (V2X) systems mitigate this, current benchmarks lack the cooperative reasoning required for resolving ambiguities in complex environments. We introduce D2-V2X, a spatially-aware Question-Rationale-Answer (QRA) benchmark featuring 8,500 triplets derived from multimodal vehicle and infrastructure sensors. We additionally establish a baseline that aligns 3D LiDAR features with the VLM's latent space. By enforcing natural language Chain-of-Thought rationales prior to structured JSON outputs, our model is forced to explicitly articulate spatial relations. Our experiments demonstrate that grounding VLMs in cooperative LiDAR achieves 24.4% recall in identifying occluded hazards compared to near-zero in zero-shot models and reduces spatial estimation error for visible objects by 77% compared to the zero-shot baseline. While the model achieves a functional decision-making F1-score of 53.5, we identify 3D-to-2D projection as a fundamental bottleneck in current VLM architectures, establishing a new baseline for future innovation. Data, code, and trained models available at https://github.com/KevinRichard1/D2-V2X
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the D2-V2X QRA benchmark consisting of 8,500 triplets from multimodal V2X sensors and proposes a baseline that aligns 3D LiDAR features into a VLM latent space while enforcing natural-language Chain-of-Thought rationales before structured JSON outputs. It reports that this grounding yields 24.4% recall on occluded hazards (vs. near-zero for zero-shot VLMs) and a 77% reduction in spatial estimation error for visible objects, with an overall decision-making F1 of 53.5, while identifying 3D-to-2D projection as a remaining bottleneck. Data, code, and models are released.
Significance. If the performance deltas hold after proper controls, the work would provide a useful new benchmark and open-source baseline for cooperative V2X reasoning with VLMs, directly addressing sensor occlusion in autonomous driving. The public release of the 8,500 triplets, code, and trained models is a clear strength that enables reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: The central claim that 'enforcing natural language Chain-of-Thought rationales prior to structured JSON outputs' forces explicit articulation of spatial relations and drives the reported gains (24.4% occluded recall, 77% error reduction) is not supported by any ablation that holds the LiDAR alignment and supervised objective fixed while removing only the rationale step.
- [Abstract] Abstract: The comparison to the zero-shot baseline confounds the effects of (i) LiDAR feature alignment, (ii) supervised fine-tuning on the 8,500 QRA examples, and (iii) the CoT requirement, because the zero-shot model receives neither the benchmark triplets nor the output format; without an ablation that applies the same supervised objective without CoT, the data cannot isolate which component produces the deltas.
minor comments (1)
- [Abstract] Abstract: Training details (loss formulation, optimizer, number of epochs, learning-rate schedule) and statistical significance tests for the 24.4% and 77% figures are not reported, making it impossible to assess variance or reproducibility from the provided text.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for more controlled experiments to isolate the individual contributions of LiDAR alignment, supervised fine-tuning, and the Chain-of-Thought (CoT) rationale step. We agree that the current zero-shot comparison does not fully disentangle these factors and that an ablation removing only the rationale requirement (while holding alignment and supervision fixed) is absent. We address each comment below and will incorporate the requested controls in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'enforcing natural language Chain-of-Thought rationales prior to structured JSON outputs' forces explicit articulation of spatial relations and drives the reported gains (24.4% occluded recall, 77% error reduction) is not supported by any ablation that holds the LiDAR alignment and supervised objective fixed while removing only the rationale step.
Authors: We acknowledge the validity of this observation. The manuscript does not currently contain an ablation that keeps the LiDAR feature alignment and supervised training objective fixed while removing only the natural-language rationale generation step. In the revised manuscript we will add exactly this control: a model variant trained on the same 8,500 QRA triplets but optimized to emit structured JSON directly, without an intermediate rationale. The resulting comparison will quantify the incremental benefit attributable to the CoT requirement. revision: yes
-
Referee: [Abstract] Abstract: The comparison to the zero-shot baseline confounds the effects of (i) LiDAR feature alignment, (ii) supervised fine-tuning on the 8,500 QRA examples, and (iii) the CoT requirement, because the zero-shot model receives neither the benchmark triplets nor the output format; without an ablation that applies the same supervised objective without CoT, the data cannot isolate which component produces the deltas.
Authors: We agree that the zero-shot baseline conflates all three factors. The revised version will therefore include a supervised fine-tuning baseline that uses the identical LiDAR-aligned features and training objective but omits the CoT rationale step (i.e., direct JSON prediction). This additional condition, together with the ablation described above, will allow readers to attribute performance changes more precisely. We note that because the QRA benchmark was constructed with rationales, any supervised model is trained on rationale-containing targets; the new ablation will nevertheless remove the explicit rationale output requirement at both training and inference time. revision: yes
Circularity Check
No circularity: empirical benchmark results stand as direct measurements
full rationale
The paper introduces the QRA benchmark (8,500 triplets) and a baseline aligning LiDAR features into VLM latent space, then reports measured recall (24.4%) and error reduction (77%) against an external zero-shot baseline. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The CoT enforcement is a prompting/training choice whose effect is measured empirically rather than derived by construction from the inputs. Results are self-contained against the external baseline with no reduction to definitions or prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can be aligned with 3D LiDAR features in latent space to improve spatial reasoning
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bev-llm: Leveraging multimodal bev maps for scene captioning in autonomous driving
Felix Brandst ¨atter, Erik Sch ¨utz, Katharina Winter, and Fabian B Flohr. Bev-llm: Leveraging multimodal bev maps for scene captioning in autonomous driving. In2025 IEEE Intelligent V ehicles Symposium (IV), pages 345–350. IEEE,
-
[3]
Rehg, and Chao Zheng
Xu Cao, Tong Zhou, Yunsheng Ma, Wenqian Ye, Can Cui, Kun Tang, Zhipeng Cao, Kaizhao Liang, Ziran Wang, James M. Rehg, and Chao Zheng. Maplm: A real-world large-scale vision-language benchmark for map and traffic scene understanding. InCVPR, pages 21819–21830, 2024. 1, 2
2024
-
[4]
Hsu-kuang Chiu, Ryo Hachiuma, Chien-Yi Wang, Stephen F Smith, Yu-Chiang Frank Wang, and Min-Hung Chen. V2v- llm: Vehicle-to-vehicle cooperative autonomous driving with multi-modal large language models.arXiv preprint arXiv:2502.09980, 2025. 2
-
[5]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. NeurIPS, 36:10088–10115, 2023. 3
2023
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Stride-qa: visual question an- swering dataset for spatiotemporal reasoning in urban driv- ing scenes
Keishi Ishihara, Kento Sasaki, Tsubasa Takahashi, Daiki Sh- iono, and Yu Yamaguchi. Stride-qa: visual question an- swering dataset for spatiotemporal reasoning in urban driv- ing scenes. InAAAI, pages 5257–5266, 2026. 1, 2
2026
-
[8]
V3lma: Visual 3d-enhanced language model for autonomous driving
Jannik L ¨ubberstedt, Esteban Rivera Guerrero, Nico Uhle- mann, and Markus Lienkamp. V3lma: Visual 3d-enhanced language model for autonomous driving. InCVPR, pages 4769–4778, 2025. 2
2025
-
[9]
Vlaad: Vision and language assistant for autonomous driv- ing
SungYeon Park, MinJae Lee, JiHyuk Kang, Hahyeon Choi, Yoonah Park, Juhwan Cho, Adam Lee, and DongKyu Kim. Vlaad: Vision and language assistant for autonomous driv- ing. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 980–987, 2024. 2
2024
-
[10]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In AAAI, pages 4542–4550, 2024. 1, 2
2024
-
[11]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InECCV, pages 256–274. Springer, 2024. 2
2024
-
[12]
Keshu Wu, Pei Li, Yang Zhou, Rui Gan, Junwei You, Yang Cheng, Jingwen Zhu, Steven T Parker, Bin Ran, David A Noyce, et al. V2x-llm: Enhancing v2x integration and un- derstanding in connected vehicle corridors.arXiv preprint arXiv:2503.02239, 2025. 2
-
[13]
V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer
Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming- Hsuan Yang, and Jiaqi Ma. V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer. InECCV,
-
[14]
Center- based 3d object detection and tracking
Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center- based 3d object detection and tracking. InCVPR, pages 11784–11793, 2021. 3
2021
-
[15]
Junwei You, Pei Li, Zhuoyu Jiang, Weizhe Tang, Zilin Huang, Rui Gan, Jiaxi Liu, Yan Zhao, Sikai Chen, and Bin Ran. V2x-qa: A comprehensive reasoning dataset and benchmark for multimodal large language models in au- tonomous driving across ego, infrastructure, and cooperative views.arXiv preprint arXiv:2604.02710, 2026. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Weinberger, and Yoav Artzi
Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text gen- eration with bert. InICLR, 2020. 4
2020
-
[17]
Tumtraf videoqa: Dataset and benchmark for uni- fied spatio-temporal video understanding in traffic scenes
Xingcheng Zhou, Konstantinos Larintzakis, Hao Guo, Wal- ter Zimmer, Mingyu Liu, Hu Cao, Jiajie Zhang, Venkat- narayanan Lakshminarasimhan, Leah Strand, and Alois Knoll. Tumtraf videoqa: Dataset and benchmark for uni- fied spatio-temporal video understanding in traffic scenes. In F orty-second International Conference on Machine Learn- ing, 2025. 2
2025
-
[18]
Tumtraf v2x cooperative perception dataset
Walter Zimmer, Gerhard Arya Wardana, Suren Sritharan, Xingcheng Zhou, Rui Song, and Alois C Knoll. Tumtraf v2x cooperative perception dataset. InCVPR, pages 22668– 22677, 2024. 2, 3
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.