EvoCode-Bench: Evaluating Coding Agents in Multi-Turn Iterative Interactions
Pith reviewed 2026-06-30 16:19 UTC · model grok-4.3
The pith
Single-round success rates for coding agents overestimate their ability to maintain codebases across changing requirements by 22-40 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
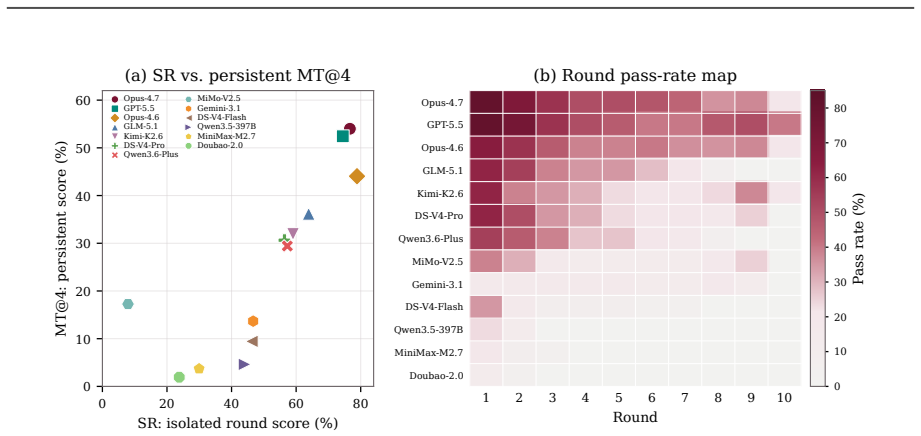
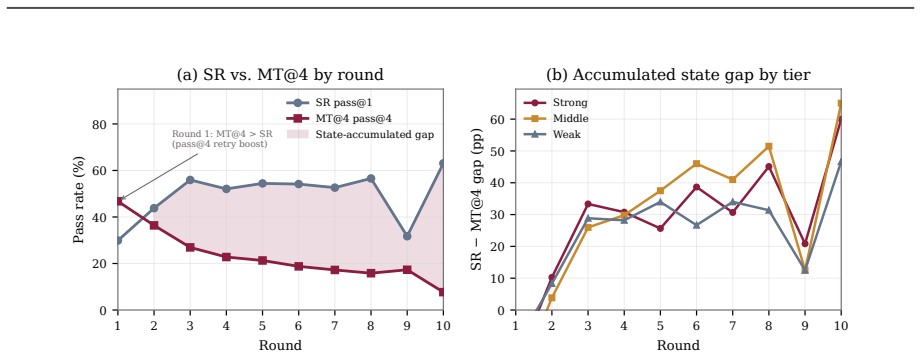
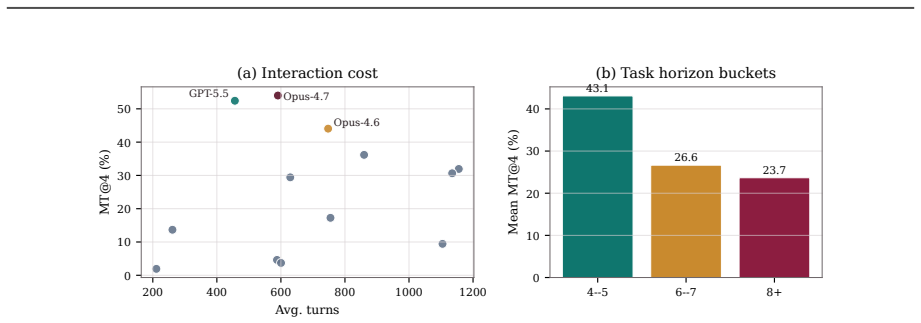
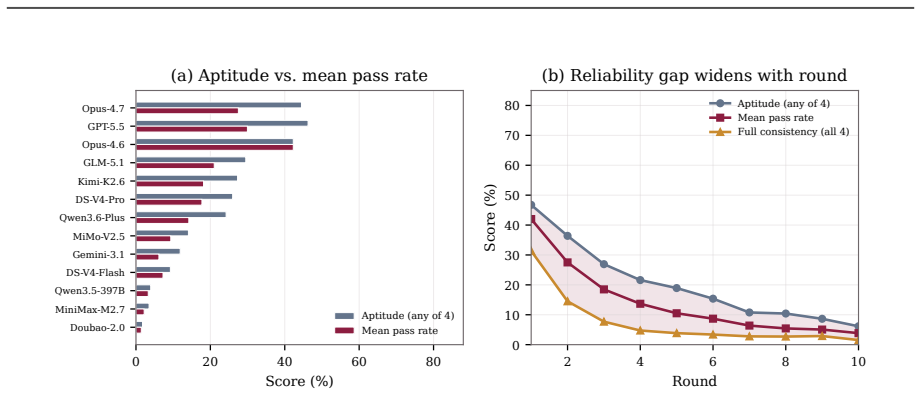
The central claim is that most coding agents perform substantially worse when required to iteratively update and maintain a codebase across multiple rounds with evolving requirements compared to single-round evaluations from a completed state, as measured by the gap between SR and MT@4 on EvoCode-Bench's 26 tasks.
What carries the argument
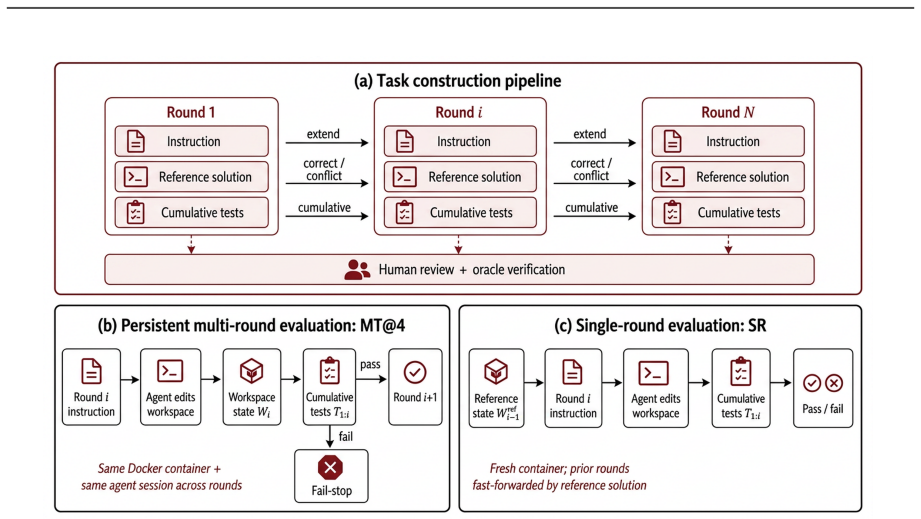
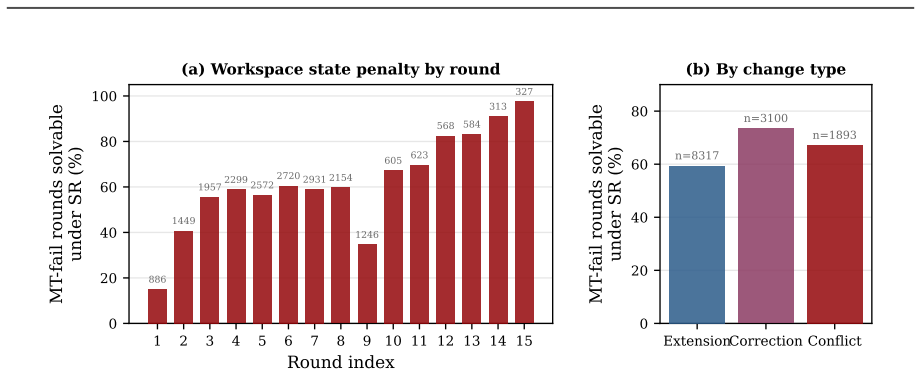
EvoCode-Bench, consisting of 26 stateful coding tasks evaluated over 5-15 rounds each using cumulative executable tests that verify both new and prior requirements.
If this is right
- Agent rankings based on single-round performance do not reliably predict performance in persistent multi-turn settings.
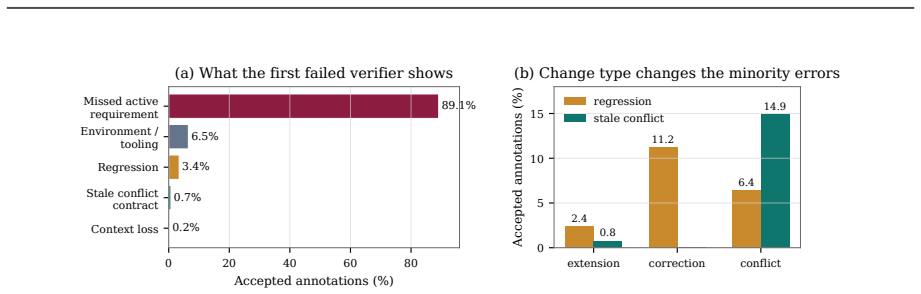
- Stronger agents survive longer rounds but still encounter specification-tracking and regression failures.
- Aggregate success rates decline sharply after initial rounds, dropping below half of round-1 levels by round 5.
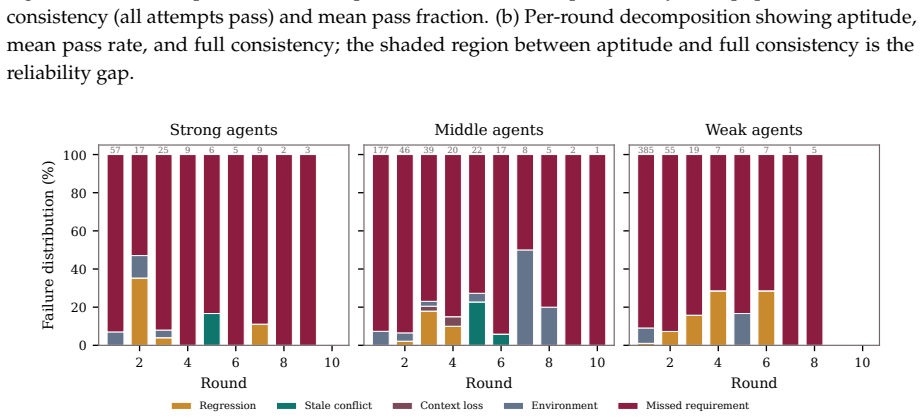
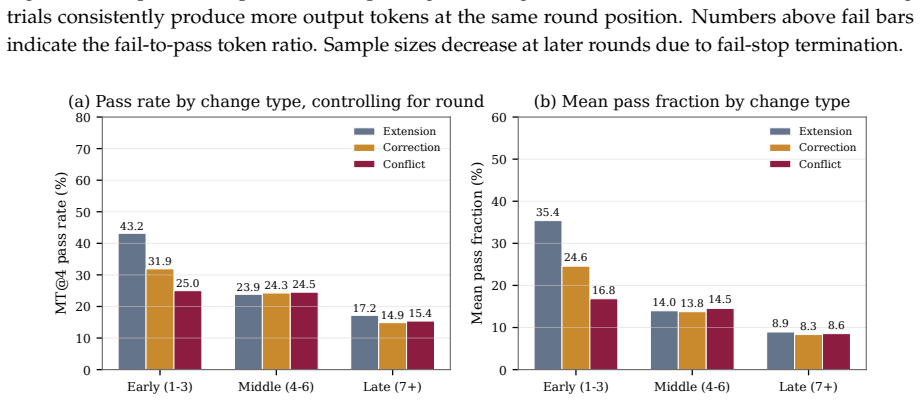
- Weaker agents fail predominantly in early rounds while the benchmark exposes later-stage issues in capable agents.
Where Pith is reading between the lines
- Training or prompting strategies focused on single completions may not generalize to real iterative workflows.
- Real-world deployment of coding agents may require additional mechanisms for state persistence and change tracking beyond current capabilities.
- The released benchmark data and Harbor infrastructure enable development of agents optimized for multi-turn consistency.
Load-bearing premise
The 26 tasks and their cumulative executable tests are assumed to be representative of real iterative development and to expose general failure modes rather than artifacts of task selection or test design.
What would settle it
Evaluating the same agents on a substantially larger or differently constructed set of multi-turn tasks and finding no significant gap between SR and MT@4 scores, or no ranking changes, would falsify the overestimation claim.
Figures

read the original abstract
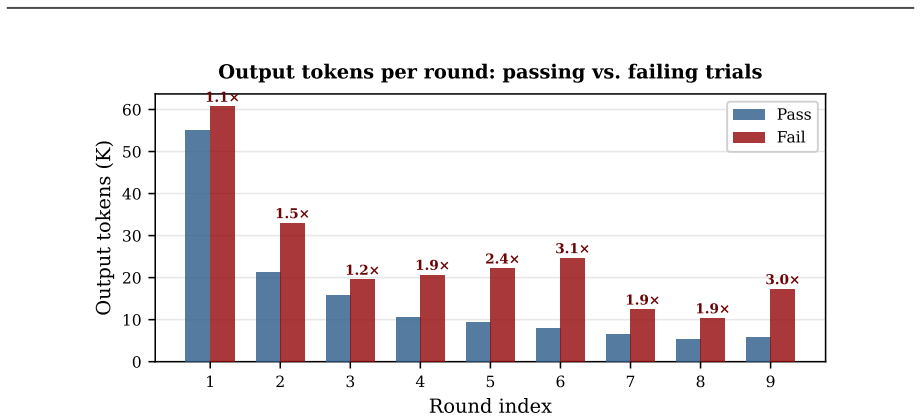
Coding agents are increasingly used as iterative development partners, but most benchmarks still evaluate one specification followed by one final assessment. This leaves out a basic question: can an agent keep its own codebase working as requirements change? We introduce EvoCode-Bench, a benchmark of 26 stateful coding tasks and 227 evaluated rounds. Each task preserves the agent's workspace for 5-15 rounds, states requirements through observable behavior, and uses cumulative executable tests to check new requirements and still-active prior ones. We evaluate 13 coding agents with two metrics: MT@4, a four-attempt fail-stop multi-round score, and SR, a single-round score from a reference-completed prior state. For most agents, SR exceeds MT@4 by 22-40 points. The gap also changes rankings: the highest-SR agent (78.9) ranks only third in persistent execution (44.0 MT@4). Even the strongest agents achieve only about 50% success on multi-turn metrics, and aggregate pass rate drops below half of round-1 performance by round 5. Failure analysis shows tier-dependent behavior: weaker agents fail early, while stronger agents survive long enough to expose specification-tracking and regression failures. We release the benchmark data and Harbor multi-turn infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoCode-Bench, a new benchmark of 26 stateful coding tasks spanning 227 rounds, designed to evaluate coding agents on multi-turn iterative development where requirements evolve while preserving workspace state and using cumulative executable tests. It reports results on 13 agents using two metrics—MT@4 (four-attempt fail-stop multi-round success) and SR (single-round success from a reference state)—claiming that SR exceeds MT@4 by 22-40 points for most agents, that this gap reverses agent rankings (e.g., top SR agent ranks third on MT@4), that even the strongest agents reach only ~50% on multi-turn metrics, and that aggregate pass rates drop below half of round-1 performance by round 5. Failure analysis indicates tier-dependent patterns, with weaker agents failing early and stronger ones exposing specification-tracking and regression issues. The benchmark and Harbor infrastructure are released.
Significance. If the 26 tasks prove representative of real iterative development, the work provides a useful new evaluation framework that exposes limitations in current agents' ability to handle persistent state, evolving specifications, and regressions—limitations not captured by single-turn benchmarks. The release of data and infrastructure is a concrete strength that enables follow-on work.
major comments (1)
- [Abstract and §3 (task/benchmark construction)] The central empirical claims (SR-MT@4 gaps of 22-40 points, ranking reversals, ~50% multi-turn success, pass-rate halving by round 5, and tier-dependent failure modes) rest on the assumption that the 26 tasks and their cumulative tests expose general failure modes rather than artifacts of task selection or test design. No section provides a task-selection protocol, domain coverage, complexity distribution, or construction details for the 227 rounds that would allow assessment of representativeness (e.g., whether tasks were chosen or tests written to highlight multi-turn fragility). This is load-bearing for generalizability.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of task construction details to support claims of generalizability. We address the major comment below and will revise the manuscript to incorporate additional transparency.
read point-by-point responses
-
Referee: [Abstract and §3 (task/benchmark construction)] The central empirical claims (SR-MT@4 gaps of 22-40 points, ranking reversals, ~50% multi-turn success, pass-rate halving by round 5, and tier-dependent failure modes) rest on the assumption that the 26 tasks and their cumulative tests expose general failure modes rather than artifacts of task selection or test design. No section provides a task-selection protocol, domain coverage, complexity distribution, or construction details for the 227 rounds that would allow assessment of representativeness (e.g., whether tasks were chosen or tests written to highlight multi-turn fragility). This is load-bearing for generalizability.
Authors: We agree that the current manuscript lacks sufficient detail on task selection and construction, which limits readers' ability to evaluate representativeness. In the revised version, we will expand §3 with a new subsection that includes: (1) the task-selection protocol (criteria for choosing the 26 tasks and ensuring stateful iterative development scenarios), (2) domain coverage and complexity distribution (e.g., programming domains, lines of code, number of requirements per task), and (3) construction details for the 227 rounds, including how cumulative tests were authored to check both new and prior requirements while minimizing design artifacts. These additions will directly address concerns about whether observed gaps and failure modes reflect general agent limitations or benchmark-specific choices. The released benchmark data will also be accompanied by this expanded documentation. revision: yes
Circularity Check
No circularity: direct empirical measurements on newly introduced benchmark
full rationale
The paper defines 26 new stateful tasks, 227 rounds, and two metrics (MT@4, SR) then reports raw success rates, ranking shifts, and failure patterns from running 13 agents. These are direct observations against the introduced corpus; no equations, fitted parameters, self-citations, or prior results are invoked to derive the headline numbers. The central claims reduce only to the benchmark execution itself, which is externally falsifiable by re-running the released tasks and agents.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LemonHarness Technical Report
LemonHarness constrains LLM agent state changes to a defined workspace, supplies callable rule knowledge, and adds time awareness, yielding 84.49% and 86.52% accuracy on Terminal-Bench 2.0 with two GPT-5 backbones.
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=VTF8yNQM66. Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. MT-eval: A multi-turn capabilities evaluation benchmark for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 20153–20177,...
-
[2]
URLhttps://arxiv.org/abs/2601.11868. OpenAI. Codex. Product documentation, 2026. URLhttps://openai.com/codex. Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.850 2026
-
[3]
The highest number below 100 that does not contain the digit 9 is 95
OpenReview.net, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ 63fef0802863f47775c3563e18cbba17-Abstract-Conference.html. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P . Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. LMSYS-chat-1m: A large-scale real-w...
-
[4]
No algorithm names, data structure choices, or file organization prescriptions appear in instructions
Describe behavior, not implementation.Instructions specify what the system should do in terms of observable behavior, not how to achieve it. No algorithm names, data structure choices, or file organization prescriptions appear in instructions. This lets different agents reach equivalent behavioral goals through different implementation paths
-
[5]
They never inspect source code structure, function names, or file organization
Test behavioral requirements, not implementation details.Verification scripts check the system’s external behavior through actual execution: running commands, sending inputs, and checking outputs. They never inspect source code structure, function names, or file organization. This makes the same test suite valid across arbitrary implementation paths
-
[6]
They can only assume the agent passed the behavioral tests of all prior rounds
Round-independent testing.Round i’s tests cannot assume the agent used the same code structure as the reference solution in rounds 1 throughi− 1. They can only assume the agent passed the behavioral tests of all prior rounds. This handles divergent implementation paths in multi-turn evaluation. These principles are enforced at every stage of the pipeline:...
-
[7]
They check for alternative valid inter- pretations that the tests might not distinguish and for edge cases that the cumulative tests might miss
Answer correctness verification.Independent reviewers verify that the reference solution for each round produces the behavior specified by the instructions. They check for alternative valid inter- pretations that the tests might not distinguish and for edge cases that the cumulative tests might miss
-
[8]
They also verify that no test checks stale requirements that have been superseded by later rounds, which would cause otherwise correct implementations to fail
Test-specification alignment audit.Reviewers verify that every test assertion traces back to a current specification, either newly introduced in the current round or persisting from a previous round. They also verify that no test checks stale requirements that have been superseded by later rounds, which would cause otherwise correct implementations to fail
-
[9]
Shortcut analysis.Reviewers attempt to identify implementation strategies that would pass all tests without satisfying the task requirements. This includes checking for overly specific test inputs that allow hardcoding, test orderings that leak information, and behavioral checks that are too loose to distinguish correct from incorrect implementations. Tas...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.