Empirical Analysis and Detection of Hallucinations in LLM-Generated Bug Report Summaries
Pith reviewed 2026-06-30 14:58 UTC · model grok-4.3
The pith
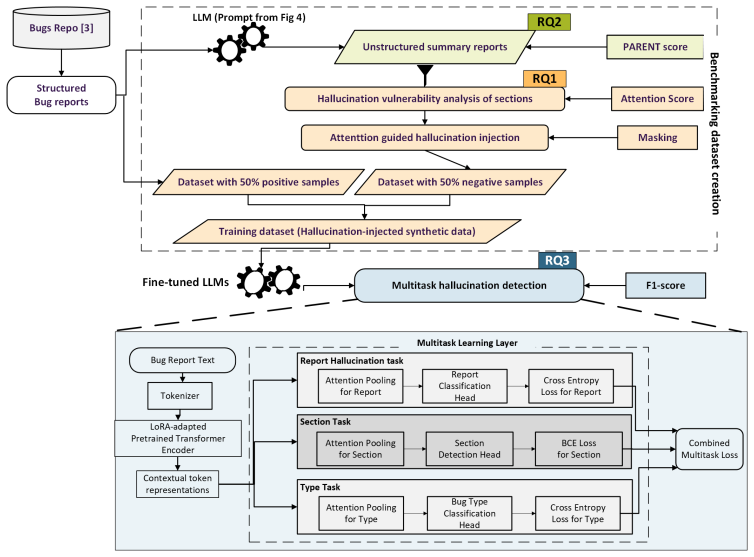
A section-aware model jointly detects whether LLM bug summaries contain hallucinations, which sections are affected, and what type of error occurred.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a section-aware hallucination detection approach, which jointly predicts report-level presence of hallucinations, identifies the affected sections, and classifies hallucination types, delivers strong performance on a benchmark built from structured bug reports.
What carries the argument
The section-aware detection model that performs joint prediction over report-level hallucination, section identification, and hallucination-type classification.
If this is right
- Detection performance improves when the model accounts for the distinct sections of a bug report rather than treating the entire summary as one block.
- Common hallucination patterns identified in the analysis point to specific failure modes that future LLM summarizers can target.
- The three-task joint prediction setup can be applied to other structured technical documents that require section-level reliability checks.
- Higher detection scores at report, section, and type levels support more trustworthy use of LLMs inside software maintenance workflows.
Where Pith is reading between the lines
- If the synthetic benchmark approximates real cases, the same joint-prediction architecture could be retrained on other domains such as API documentation or test-case descriptions.
- Failure-mode analysis in the paper suggests that section boundaries themselves may act as natural checkpoints for reducing hallucination risk during generation.
- Extending the approach to streaming or incremental summaries would require only modest changes to the section-aware input encoding.
Load-bearing premise
The controlled synthetic hallucination injection produces a benchmark representative of the hallucinations that LLMs generate in real structured bug report summaries.
What would settle it
Running the trained detector on fresh LLM-generated summaries drawn directly from real bug reports that contain no synthetic injections would show whether the reported performance numbers hold outside the constructed benchmark.
Figures




read the original abstract
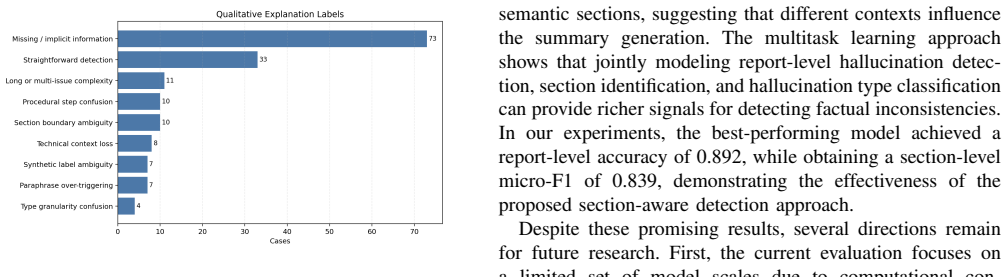
Large Language Models (LLMs) are increasingly used to generate summaries of software bug reports, including sections such as Steps-to-Reproduce (S2R), Actual Behavior (AB), and Expected Behavior (EB). However, these models frequently produce hallucinations that can be convincing but unsupported by the source report. This can mislead developers and reduce trust in automated maintenance tools. Existing hallucination detection approaches typically evaluate outputs at the full-response level and do not consider the structure of technical documents. An initial exploratory study on 80 structured bug report summaries found that approximately 47.9% contained missing information, while 12.3% included fabricated content, highlighting the need for systematic hallucination analysis in bug report summarization. In this work, we empirically investigate hallucinations in LLM-generated bug report summaries from a section-aware perspective. Using the BugsRepo dataset, derived from Mozilla OSS projects, we introduce controlled synthetic hallucination injection to construct a benchmark for training and evaluation. We propose a section-aware hallucination detection approach that jointly predicts whether a summary contains hallucinated content, identifies affected sections, and classifies hallucination types. Experimental results across multiple pretrained language models show that the proposed approach achieves strong performance across all tasks, with the best model obtaining 0.89 report-level Macro-F1, 0.83 section-level Macro-F1, and 0.84 hallucination-type Macro-F1. We further analyze common hallucination patterns and model failure modes to better understand limitations of current LLM-generated bug report summaries. The findings highlight the importance of section-aware hallucination analysis for improving the reliability of LLM-assisted bug report summarization in software maintenance workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations are common in LLM-generated structured bug report summaries (exploratory study on 80 examples: 47.9% missing information, 12.3% fabricated), constructs a benchmark by controlled synthetic hallucination injection into the BugsRepo dataset, and proposes a section-aware multi-task detector that jointly predicts report-level hallucination presence, affected sections, and hallucination types. It reports strong performance across pretrained language models, with the best achieving 0.89 report-level Macro-F1, 0.83 section-level Macro-F1, and 0.84 hallucination-type Macro-F1, plus analysis of patterns and failure modes.
Significance. If the synthetic benchmark is representative, the work would offer a practical, structure-aware method for detecting hallucinations in a high-stakes software engineering task, with the joint prediction formulation and explicit pattern analysis as clear strengths. The empirical focus on bug reports is timely for LLM-assisted maintenance tools.
major comments (2)
- [Abstract / Methodology] Abstract and methodology section on benchmark construction: the headline Macro-F1 scores (0.89/0.83/0.84) are obtained exclusively on synthetically injected hallucinations. The exploratory study reports specific percentages for missing and fabricated content, yet no calibration, side-by-side frequency comparison, human realism ratings, or ablation on injection parameters is described to show that the synthetic distribution matches the section placement, linguistic features, or type frequencies of hallucinations actually emitted by the evaluated LLMs on real bug reports.
- [Experimental results] Experimental results section: the abstract states specific F1 scores across multiple pretrained language models but provides no details on the models, baselines, injection methodology parameters, dataset splits, or statistical significance tests. Without these, it is impossible to assess whether the reported performance is robust or reproducible.
minor comments (2)
- [Model description] The description of the three prediction tasks would benefit from an explicit equation or diagram showing how the joint loss is formulated.
- [Related work] Related work could more explicitly contrast the proposed section-aware approach with prior full-response hallucination detectors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our approach and committing to revisions where appropriate to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract / Methodology] Abstract and methodology section on benchmark construction: the headline Macro-F1 scores (0.89/0.83/0.84) are obtained exclusively on synthetically injected hallucinations. The exploratory study reports specific percentages for missing and fabricated content, yet no calibration, side-by-side frequency comparison, human realism ratings, or ablation on injection parameters is described to show that the synthetic distribution matches the section placement, linguistic features, or type frequencies of hallucinations actually emitted by the evaluated LLMs on real bug reports.
Authors: The exploratory study on 80 real LLM-generated summaries was intended only to motivate the prevalence of hallucinations (47.9% missing, 12.3% fabricated), while the synthetic injection on BugsRepo was chosen to enable controlled ground-truth labels at scale for training and evaluation. We did not include explicit calibration, human realism ratings, or frequency matching because the primary contribution is the section-aware joint detection method rather than a claim of distributional equivalence. We agree this is a limitation and will revise the methodology section to add: (1) explicit injection parameters and ablation results, (2) a qualitative comparison of synthetic vs. observed real hallucination patterns, and (3) discussion of why full calibration was not performed. This will be marked as a limitation in the revised version. revision: yes
-
Referee: [Experimental results] Experimental results section: the abstract states specific F1 scores across multiple pretrained language models but provides no details on the models, baselines, injection methodology parameters, dataset splits, or statistical significance tests. Without these, it is impossible to assess whether the reported performance is robust or reproducible.
Authors: The full manuscript's experimental results section does specify the pretrained language models evaluated, the BugsRepo dataset splits, and the controlled injection procedure. However, we acknowledge that the abstract is too terse and that additional details on baselines, exact hyper-parameters, and statistical significance testing are missing or insufficiently prominent. We will expand the experimental setup and results subsections to include: model names and sizes, baseline comparisons, injection parameter values, train/validation/test splits, and any significance tests performed. These additions will make the results fully reproducible. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper is an empirical classification study. It constructs a benchmark by injecting synthetic hallucinations into the BugsRepo dataset, trains section-aware detectors on pretrained language models, and reports standard Macro-F1 scores on held-out data. No mathematical derivations, equations, or predictions are present that could reduce to fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The reported performance numbers (0.89/0.83/0.84) are direct experimental outcomes on the constructed test set and do not tautologically follow from the paper's own definitions or prior self-references. The validity concern about synthetic vs. real hallucinations is a question of benchmark representativeness, not circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InSemEval, 2024
Leveraging synthetic data for llm hallucination detection. InSemEval, 2024
2024
-
[2]
Shamsu Abdullahi et al. The rise of hallucination in large lan- guage models: systematic reviews, performance analysis and chal- lenges.Cluster Computing, 29(2):124, Feb 2026.doi:10.1007/ s10586-025-05891-z
2026
-
[3]
Can we enhance bug report quality using llms?: An empirical study of llm-based bug report generation
Jagrit Acharya and Gouri Ginde. Bugsrepo: A comprehensive curated dataset of bug reports, comments and contributors information from bugzilla. InProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering, EASE ’25, page 986–993, New York, NY , USA, 2025. Association for Computing Machinery.doi:10.1145/3756681.3756994
-
[4]
Can we enhance bug report quality using llms?: An empirical study of llm-based bug report generation
Jagrit Acharya and Gouri Ginde. Can we enhance bug report quality using llms?: An empirical study of llm-based bug report generation. In Proceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering, EASE ’25, page 994–1003, New York, NY , USA, 2025. Association for Computing Machinery.doi: 10.1145/3756681.3756995
-
[5]
A coefficient of agreement for nominal scales
Jacob Cohen. A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1):37–46, 1960. arXiv:https://doi.org/10.1177/001316446002000104, doi:10.1177/001316446002000104
-
[6]
Handling divergent reference texts when eval- uating table-to-text generation
Bhuwan Dhingra et al. Handling divergent reference texts when eval- uating table-to-text generation. In Anna Korhonen, David Traum, and Llu´ıs M`arquez, editors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4884–4895, Florence, Italy, July 2019. Association for Computational Linguistics. URL: https://aclant...
-
[7]
Large language models for software engineering: Survey and open problems
Angela Fan et al. Large language models for software engineering: Survey and open problems. In2023 IEEE/ACM International Confer- ence on Software Engineering: Future of Software Engineering (ICSE- F oSE), pages 31–53, 2023.doi:10.1109/ICSE-FoSE59343. 2023.00008
-
[8]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K
Sen Fang et al. Representthemall: A universal learning representation of bug reports. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 602–614, 2023.doi:10.1109/ ICSE48619.2023.00060
-
[9]
Cuiyun Gao, David Lo, et al. A systematic literature review of code hallucinations in llms: Characterization, mitigation methods, challenges, and future directions for reliable ai, 2025. URL: https://arxiv.org/abs/ 2511.00776,arXiv:2511.00776
-
[10]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
2024
-
[11]
Analyzing and predicting effort associated with finding and fixing software faults
Maggie Hamill and Katerina Goseva-Popstojanova. Analyzing and predicting effort associated with finding and fixing software faults. Information and Software Technology, 87:1–18, 2017. URL: https: //www.sciencedirect.com/science/article/pii/S0950584917300290,doi: 10.1016/j.infsof.2017.01.002
-
[12]
Waka Ito, Yui Obara, Miyu Sato, and Kimio Kuramitsu. Hallucination detection on code generation with selfcheckgpt.Journal of Information Processing, 33:487–493, 2025.doi:10.2197/ipsjjip.33.487
-
[13]
Survey of Hallucination in Natural Language Generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12), March 2023.doi:10.1145/3571730
-
[14]
He Jiang, Najam Nazar, et al. Prst: A pagerank-based summariza- tion technique for summarizing bug reports with duplicates.Inter- national Journal of Software Engineering and Knowledge Engineer- ing, 27(06):869–896, 2017.arXiv:https://doi.org/10.1142/ S0218194017500322,doi:10.1142/S0218194017500322
-
[15]
Magne Jorgensen and Martin Shepperd. A systematic review of software development cost estimation studies.IEEE Transactions on Software En- gineering, 33(1):33–53, 2007.doi:10.1109/TSE.2007.256943
-
[16]
Lie to me: Knowledge graphs for robust hallucination self-detection in llms, 2025
Sahil Kale and Antonio Luca Alfeo. Lie to me: Knowledge graphs for robust hallucination self-detection in llms, 2025. URL: https://arxiv.org/ abs/2512.23547,arXiv:2512.23547
-
[17]
The cost of poor software quality in the us: A 2022 report
Herb Krasner. The cost of poor software quality in the us: A 2022 report. Technical report, Consortium for Informa- tion & Software Quality, 2022. URL: https://www.it-cisq.org/ the-cost-of-poor-quality-software-in-the-us-a-2022-report/
2022
-
[18]
How can I parse a JSON string in Python and extract a nested field?
Arjun Krishna, Erick Galinkin, Leon Derczynski, and Jeffrey Martin. Importing phantoms: Measuring llm package hallucination vulnerabili- ties, 01 2025.doi:10.48550/arXiv.2501.19012
-
[19]
ROUGE: A package for automatic evaluation of sum- maries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of sum- maries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL: https://aclanthology.org/W04-1013/
2004
-
[20]
Chunhua Liu et al. Hallucinations in code change to natural language generation: Prevalence and evaluation of detection metrics. InProceed- ings of the 14th International Joint Conference on Natural Language Processing, pages 2538–2560, Mumbai, India, December 2025. The Asian Federation of Natural Language Processing and The Association for Computational ...
-
[21]
Fang Liu, Yang Liu, Lin Shi, Zhen Yang, Li Zhang, Xiaoli Lian, Zhongqi Li, and Yuchi Ma. Beyond functional correctness: Exploring hallucina- tions in llm-generated code.IEEE Transactions on Software Engineer- ing, 52:1037–1055, 2024.doi:10.1109/tse.2026.3657432
-
[22]
Modelling the ‘hurried’ bug report reading process to summarize bug reports
Rafael Lotufo, Zeeshan Malik, and Krzysztof Czarnecki. Modelling the ‘hurried’ bug report reading process to summarize bug reports. Empirical Software Engineering, 20(2):516–548, Apr 2015.doi: 10.1007/s10664-014-9311-2
-
[23]
ETF: An entity tracing framework for hallucination detection in code summaries
Kishan Maharaj, , Pushpak Bhattacharyya, et al. ETF: An entity tracing framework for hallucination detection in code summaries. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 30639– 30652, Vienna,...
-
[24]
Ausum: approach for unsupervised bug report summarization
Senthil Mani, Rose Catherine, Vibha Singhal Sinha, and Avinava Dubey. Ausum: approach for unsupervised bug report summarization. In Proceedings of the ACM SIGSOFT 20th International Symposium on the F oundations of Software Engineering, FSE ’12, New York, NY , USA, 2012. Association for Computing Machinery.doi:10.1145/ 2393596.2393607
-
[25]
On faithfulness and factuality in abstrac- tive summarization
Joshua Maynez et al. On faithfulness and factuality in abstrac- tive summarization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 1906– 1919, Online, July 2020. Association for Computational Linguistics. URL: https://aclanthology.o...
1906
-
[26]
Selfcheck-eval: A multi-module framework for zero-resource hallucination detection in large language models
Diyana Muhammed et al. Selfcheck-eval: A multi-module framework for zero-resource hallucination detection in large language models. 2025. URL: https://api.semanticscholar.org/CorpusID:276107224
2025
-
[28]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceed- ings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, page 311–318, USA, 2002. Association for Computational Linguistics.doi:10.3115/1073083.1073135
-
[29]
Bibek Paudel, Alexander Lyzhov, Preetam Joshi, and Puneet Anand. Hallucinot: Hallucination detection through context and common knowl- edge verification.ArXiv, abs/2504.07069, 2025. URL: https://api. semanticscholar.org/CorpusID:277634150
-
[30]
Yunna Shao and Bangmeng Xiang. Enhancing bug report summaries through knowledge-specific and contrastive learning pre-training.IEEE Access, 12:37653–37662, 2024.doi:10.1109/ACCESS.2024. 3368915
-
[31]
Llm-agents driven automated simulation testing and anal- ysis of small uncrewed aerial systems
Salma Begum Tamanna, Gias Uddin, et al.ChatGPT Inaccuracy Mitigation during Technical Report Understanding: Are We There Yet?, page 2290–2302. IEEE Press, 2025. URL: https://doi.org/10.1109/ ICSE55347.2025.00145
-
[32]
Chakkrit Kla Tantithamthavorn et al. Hallujudge: A reference-free hallucination detection for context misalignment in code review automa- tion.ArXiv, abs/2601.19072, 2026. URL: https://api.semanticscholar. org/CorpusID:285070919
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Marcos Tileria, Santanu Kumar Dash, Profir-Petru P ˆart ¸achi, and Earl T. Barr. Hallucination inspector: A fact-checking judge for api migration,
-
[34]
URL: https://arxiv.org/abs/2604.20202,arXiv:2604.20202
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL: https://arxiv.org/abs/1706.03762,arXiv: 1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Evaluating the usefulness of ir-based fault localization techniques
Qianqian Wang, Chris Parnin, and Alessandro Orso. Evaluating the usefulness of ir-based fault localization techniques. InProceedings of the 2015 international symposium on software testing and analysis, pages 1–11, 2015
2015
-
[37]
A comprehensive review on generative AI for education
Bangmeng Xiang and Yunna Shao. Sumllama: Efficient contrastive representations and fine-tuned adapters for bug report summarization. IEEE Access, 12:78562–78571, 2024.doi:10.1109/ACCESS. 2024.3397326
-
[38]
Yayun Zhang, Yuying Li, Minying Fang, Xing Yuan, and Junwei Du. Brmds: an llm-based multi-dimensional summary generation approach for bug reports.Automated Software Engg., 33(1), September 2025. doi:10.1007/s10515-025-00553-1
-
[39]
Ziyao Zhang, Chong Wang, Yanlin Wang, Ensheng Shi, Yuchi Ma, Wanjun Zhong, Jiachi Chen, Mingzhi Mao, and Zibin Zheng. Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation.Proceedings of the ACM on Software Engineering, 2:481 – 503, 2024.doi:10.1145/3728894
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.