EVA: Accelerating LLM Decoding via an Efficient Vector Quantization Architecture
Pith reviewed 2026-06-30 14:31 UTC · model grok-4.3
The pith
EVA accelerates LLM decoding up to 11.17 times by computing direct dot products with the weight codebook and using structured lookups to avoid memory conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
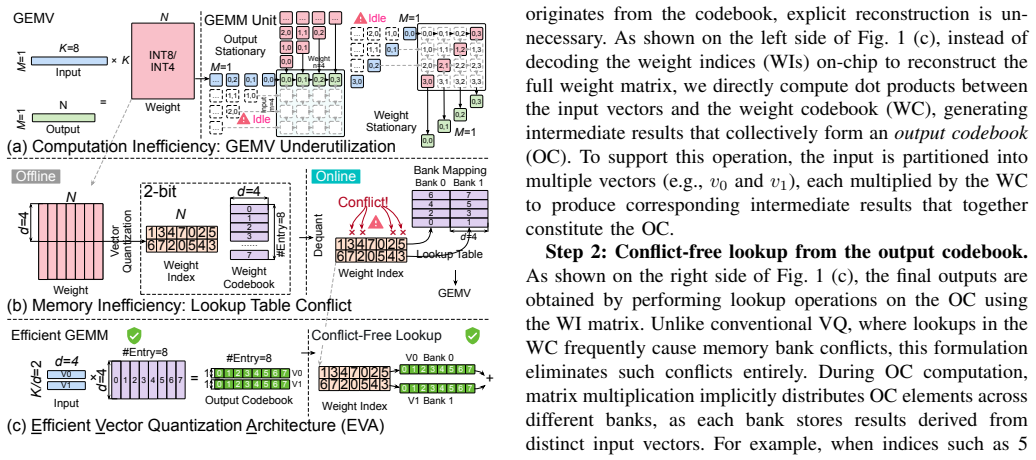
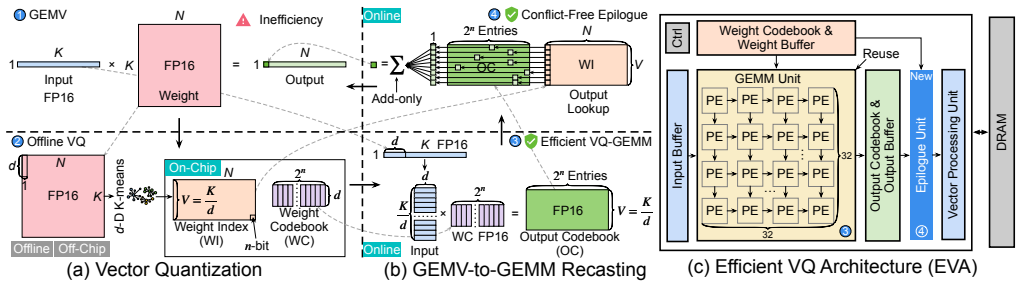
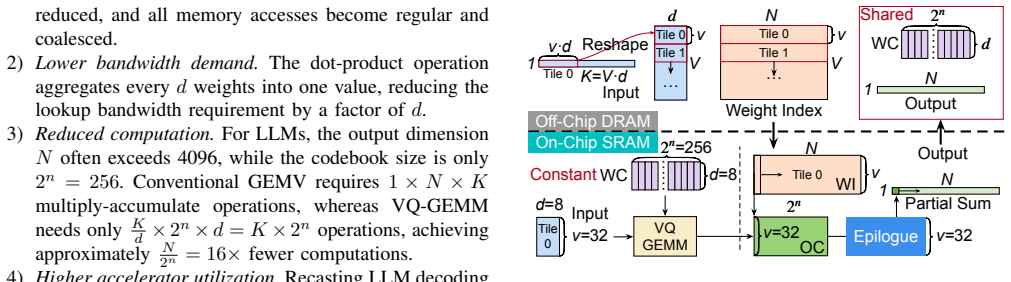
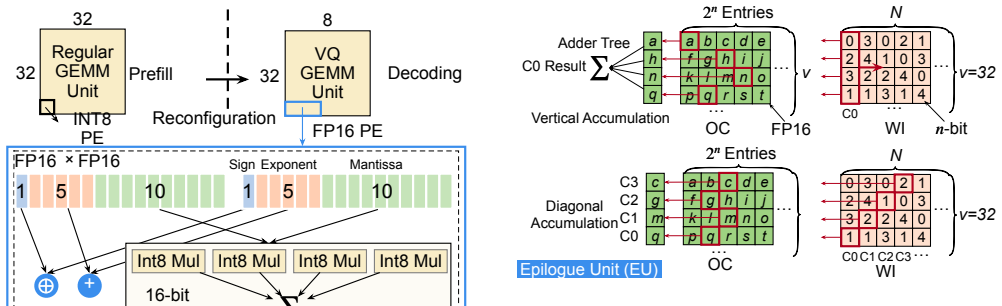
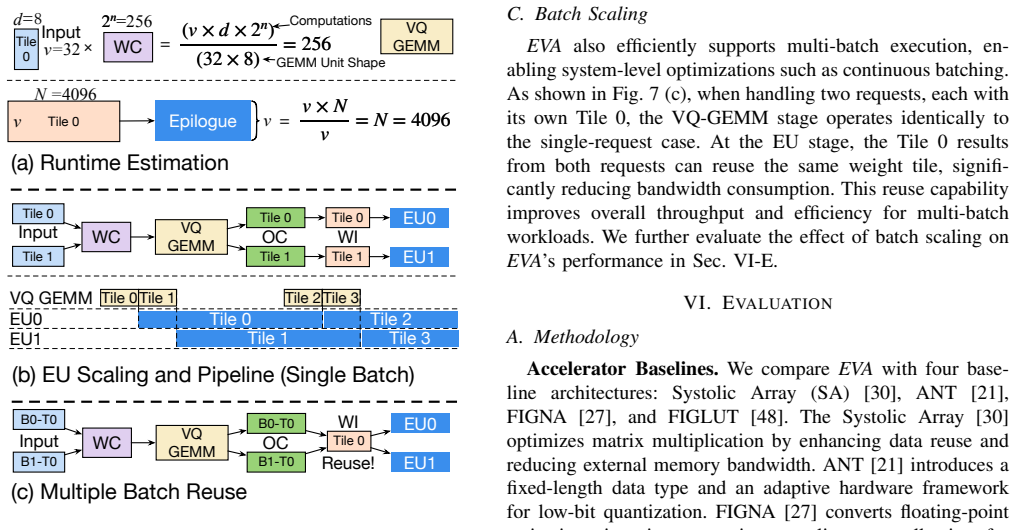
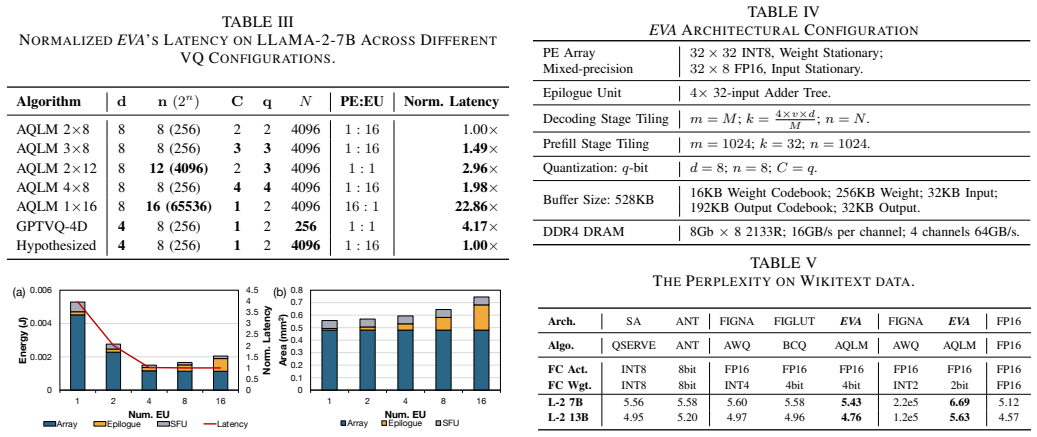
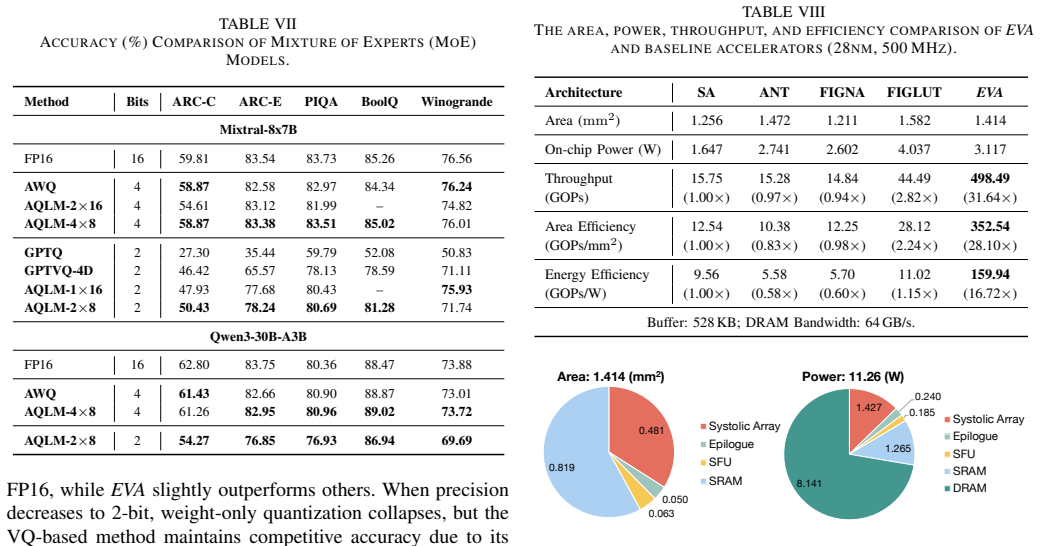
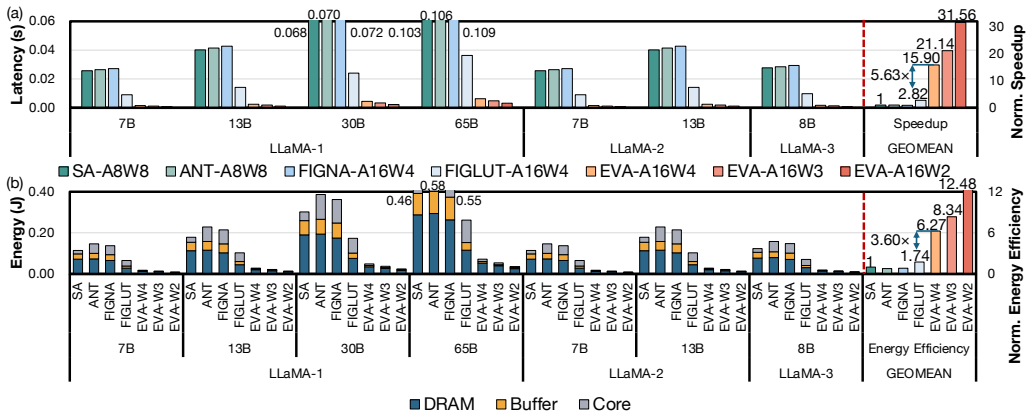
EVA builds on vector quantization by performing direct dot products between input vectors and the weight codebook, which transforms LLM decoding from GEMV-like to GEMM computation, then executes structured lookups from an intermediate output buffer to eliminate memory bank conflicts. The architecture remains compatible with standard prefill execution and delivers up to 11.17× speedup and 7.17× higher energy efficiency over state-of-the-art lookup-based designs while preserving arithmetic precision.
What carries the argument
Direct input-codebook dot product computation followed by structured lookups from an intermediate output buffer.
Load-bearing premise
Direct input-codebook dot products combined with structured lookups from an intermediate output buffer will eliminate memory bank conflicts and maintain precision without introducing new hardware bottlenecks or overheads.
What would settle it
A cycle-accurate hardware simulation or FPGA prototype run on real LLM decoding workloads that shows whether measured speedup falls below 5× or arithmetic precision deviates from the original model when memory conflicts or new overheads appear.
Figures

read the original abstract
Large Language Models (LLMs) have achieved impressive performance across diverse domains but remain inefficient during the autoregressive decoding phase. Unlike the prefill stage, which employs compute-bound GEMM operations, decoding executes a sequence of small GEMV-like computations that are memory-bound and underutilize modern accelerators. Weight-only vector quantization (VQ) has emerged as an effective compression technique that clusters model weights into a shared codebook and replaces the original weight matrix with low-precision indices, enabling 2-bit-level weight compression. While this approach substantially reduces model size and memory bandwidth, it still suffers from two critical inefficiencies: the low utilization of GEMV computation and frequent memory conflicts during codebook lookups. This paper presents EVA, an efficient vector-quantization-based architecture that addresses both computational and memory bottlenecks in LLM decoding. EVA builds on a simple yet effective insight that combines input-codebook computation with conflict-free memory access. Instead of reconstructing quantized weights from indices, EVA directly performs dot products between input vectors and the weight codebook, transforming LLM decoding from GEMV to GEMM computation. It then performs structured lookups from an intermediate output buffer, eliminating memory bank conflicts. We further design a hardware-software co-optimized architecture specialized for LLM decoding while remaining compatible with conventional prefill execution. Evaluations show that EVA achieves up to 11.17$\times$ speedup and 7.17$\times$ higher energy efficiency compared with the SOTA lookup-based architecture, while preserving arithmetic precision after vector quantization. Our code is available at https://github.com/dbw6/Eva.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the EVA architecture for accelerating autoregressive LLM decoding under weight-only vector quantization. It replaces weight reconstruction with direct input-codebook dot products (converting memory-bound GEMV to GEMM) followed by structured index-driven lookups from an intermediate output buffer to eliminate memory bank conflicts. The design is claimed to remain compatible with conventional prefill execution. Evaluations are reported to deliver up to 11.17× speedup and 7.17× energy-efficiency gains versus the SOTA lookup-based accelerator while preserving arithmetic precision; open-source code is provided.
Significance. If the reported speedups and energy gains are substantiated by detailed hardware measurements that confirm the absence of new bottlenecks, the work would offer a practical contribution to specialized accelerators for quantized LLM inference. The open code release supports reproducibility.
major comments (2)
- [Abstract and §4 (Evaluation)] Abstract and §4 (Evaluation): the headline claims of 11.17× speedup and 7.17× energy efficiency rest on the assertion that input-codebook GEMM plus structured buffer lookups remove bank conflicts without material control or buffering overhead. No cycle-level breakdown, stall analysis, or sensitivity study on intermediate-buffer size/address-generation logic is supplied, leaving the central hardware assumption unverified.
- [§3 (Architecture)] §3 (Architecture): the transformation from GEMV to GEMM via direct codebook dot products is described at a high level, but the manuscript does not quantify the additional GEMM tiling or prefill-compatibility overheads for small decoding batches, which directly affects whether net gains over prior lookup accelerators are preserved.
minor comments (2)
- The abstract states that arithmetic precision is preserved after vector quantization, but the manuscript should explicitly state the bit-widths, codebook sizes, and any rounding or accumulation-precision details used in the GEMM step.
- Figure captions and table headers in the evaluation section would benefit from clearer labeling of the exact models, sequence lengths, and hardware parameters corresponding to the reported speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. Below we address each major comment point by point. We will make revisions to strengthen the hardware analysis as suggested.
read point-by-point responses
-
Referee: [Abstract and §4 (Evaluation)] Abstract and §4 (Evaluation): the headline claims of 11.17× speedup and 7.17× energy efficiency rest on the assertion that input-codebook GEMM plus structured buffer lookups remove bank conflicts without material control or buffering overhead. No cycle-level breakdown, stall analysis, or sensitivity study on intermediate-buffer size/address-generation logic is supplied, leaving the central hardware assumption unverified.
Authors: We agree with the referee that providing a cycle-level breakdown would better substantiate our claims. Although our reported speedups are derived from a detailed cycle-accurate simulation model that includes control logic and buffering, we did not include an explicit breakdown or sensitivity study in the manuscript. We will revise §4 to include stall analysis, cycle breakdowns, and sensitivity studies on the intermediate-buffer size and address-generation logic. revision: yes
-
Referee: [§3 (Architecture)] §3 (Architecture): the transformation from GEMV to GEMM via direct codebook dot products is described at a high level, but the manuscript does not quantify the additional GEMM tiling or prefill-compatibility overheads for small decoding batches, which directly affects whether net gains over prior lookup accelerators are preserved.
Authors: The comment is valid; the current §3 focuses on the core insight without detailed overhead quantification for edge cases like small batches. In the revision, we will add analysis and measurements quantifying the GEMM tiling overheads and prefill compatibility costs for small decoding batches, showing that the net performance gains remain significant. revision: yes
Circularity Check
No circularity: engineering architecture proposal with no derivation chain
full rationale
The paper is an engineering architecture proposal for LLM decoding hardware. It contains no mathematical derivation, no equations that reduce to inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. Performance claims (speedup, energy efficiency) are presented as outcomes of the proposed design and simulation/evaluation, not as tautological results of prior steps within the paper. The work is therefore self-contained with no circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
EVA architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
A. Agrawal, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, and R. Ramjee, “Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills,”arXiv preprint arXiv:2308.16369, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Cacti 7: New tools for interconnect exploration in innovative off-chip memories,
R. Balasubramonian, A. B. Kahng, N. Muralimanohar, A. Shafiee, and V . Srinivas, “Cacti 7: New tools for interconnect exploration in innovative off-chip memories,”ACM Transactions on Architecture and Code Optimization (TACO), vol. 14, no. 2, pp. 1–25, 2017
2017
-
[4]
Piqa: Reasoning about physical commonsense in natural language,
Y . Bisk, R. Zellers, J. Gao, Y . Choiet al., “Piqa: Reasoning about physical commonsense in natural language,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 7432– 7439
2020
-
[5]
Multiplying matrices without multiplying,
D. Blalock and J. Guttag, “Multiplying matrices without multiplying,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 992–1004
2021
-
[6]
Ecco: Improving memory bandwidth and capacity for llms via entropy-aware cache compression,
F. Cheng, C. Guo, C. Wei, J. Zhang, C. Zhou, E. Hanson, J. Zhang, X. Liu, H. Li, and Y . Chen, “Ecco: Improving memory bandwidth and capacity for llms via entropy-aware cache compression,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 793–807
2025
-
[7]
Nvidia a100 tensor core gpu: Performance and innovation,
J. Choquette, W. Gandhi, O. Giroux, N. Stam, and R. Krashinsky, “Nvidia a100 tensor core gpu: Performance and innovation,”IEEE Micro, vol. 41, no. 2, pp. 29–35, 2021
2021
-
[8]
Boolq: Exploring the surprising difficulty of natural yes/no questions,
C. Clark, K. Lee, M.-W. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova, “Boolq: Exploring the surprising difficulty of natural yes/no questions,” inProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), 2019, pp. 2924–2936
2019
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,”arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
A discourse-aware attention model for abstractive sum- marization of long documents,
A. Cohan, F. Dernoncourt, D. S. Kim, T. Bui, S. Kim, W. Chang, and N. Goharian, “A discourse-aware attention model for abstractive sum- marization of long documents,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 2018, pp. 615–621
2018
-
[12]
Conover, M
M. Conover, M. Hayes, A. Mathur, J. Xie, J. Wan, S. Shah, A. Ghodsi, P. Wendell, M. Zaharia, and R. Xin. (2023) Free dolly: Introducing the world’s first truly open instruction-tuned llm. [Online]. Available: https://www.databricks.com/blog/2023/04/12/ dolly-first-open-commercially-viable-instruction-tuned-llm
2023
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”CoRR, vol. abs/2501.12948, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[14]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,”CoRR, vol. abs/1810.04805, 2018. [Online]. Available: http://arxiv.org/abs/ 1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Extreme compression of large language models via additive quantization,
V . Egiazarian, A. Panferov, D. Kuznedelev, E. Frantar, A. Babenko, and D. Alistarh, “Extreme compression of large language models via additive quantization,” 2024
2024
-
[16]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: accurate post-training quantization for generative pre-trained transformers,” CoRR, vol. abs/2210.17323, 2022. [Online]. Available: https://doi.org/ 10.48550/arXiv.2210.17323
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.17323 2022
-
[17]
Github copilot,
GitHub, “Github copilot,” https://github.com/features/copilot, 2025, ac- cessed: 2025-11-17
2025
-
[18]
Carvq: Corrective adaptor with group residual vector quantization for llm embedding compression,
D. Gou, S. Byun, N. Malpeddi, G. De Micheli, P. Vaste, J. Song, and W. S. Chung, “Carvq: Corrective adaptor with group residual vector quantization for llm embedding compression,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 18 594–18 604
2025
-
[19]
Olive: Accelerating large language models via hardware- friendly outlier-victim pair quantization,
C. Guo, J. Tang, W. Hu, J. Leng, C. Zhang, F. Yang, Y . Liu, M. Guo, and Y . Zhu, “Olive: Accelerating large language models via hardware- friendly outlier-victim pair quantization,” inProceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1–15
2023
-
[20]
Transitive array: An efficient gemm accelerator with result reuse,
C. Guo, C. Wei, J. Tang, B. Duan, S. Han, H. Li, and Y . Chen, “Transitive array: An efficient gemm accelerator with result reuse,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 990–1004
2025
-
[21]
Ant: Exploiting adaptive numerical data type for low-bit deep neural network quantization,
C. Guo, C. Zhang, J. Leng, Z. Liu, F. Yang, Y . Liu, M. Guo, and Y . Zhu, “Ant: Exploiting adaptive numerical data type for low-bit deep neural network quantization,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2022, pp. 1414– 1433
2022
-
[22]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
M-ant: Efficient low-bit group quantization for llms via mathematically adaptive numerical type,
W. Hu, H. Zhang, C. Guo, Y . Feng, R. Guan, Z. Hua, Z. Liu, Y . Guan, M. Guo, and J. Leng, “M-ant: Efficient low-bit group quantization for llms via mathematically adaptive numerical type,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1112–1126
2025
-
[24]
I- llm: Efficient integer-only inference for fully-quantized low-bit large language models,
X. Hu, Y . Cheng, D. Yang, Z. Yuan, J. Yu, C. Xu, and S. Zhou, “I- llm: Efficient integer-only inference for fully-quantized low-bit large language models,”arXiv preprint arXiv:2405.17849, 2024
-
[25]
Residual quantization with implicit neural codebooks,
I. A. Huijben, M. Douze, M. Muckley, R. J. Van Sloun, and J. Verbeek, “Residual quantization with implicit neural codebooks,”arXiv preprint arXiv:2401.14732, 2024
-
[26]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2704– 2713
2018
-
[27]
Figna: Integer unit-based accelerator design for fp-int gemm preserving numerical accuracy,
J. Jang, Y . Kim, J. Lee, and J.-J. Kim, “Figna: Integer unit-based accelerator design for fp-int gemm preserving numerical accuracy,” in 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2024, pp. 760–773
2024
-
[28]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,”CoRR, vol. abs/2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
[Online]. Available: https://doi.org/10.48550/arXiv.2310.06825
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
-
[30]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressandet al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borcherset al., “In-datacenter performance analysis of a tensor processing unit,” inProceedings of the 44th annual international symposium on computer architecture, 2017, pp. 1–12
2017
-
[32]
I-bert: Integer-only bert quantization,
S. Kim, A. Gholami, Z. Yao, M. W. Mahoney, and K. Keutzer, “I-bert: Integer-only bert quantization,” inInternational conference on machine learning. PMLR, 2021, pp. 5506–5518
2021
-
[33]
Squeezellm: dense-and-sparse quantization,
S. Kim, C. Hooper, A. Gholami, Z. Dong, X. Li, S. Shen, M. W. Ma- honey, and K. Keutzer, “Squeezellm: dense-and-sparse quantization,” in Proceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[34]
Amq: Enabling automl for mixed-precision weight-only quantization of large language models,
S. Lee, S.-t. Woo, J.-g. Jin, C. Lee, and E. Park, “Amq: Enabling automl for mixed-precision weight-only quantization of large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 35 520–35 538
2025
-
[35]
Lut-dla: Lookup table as efficient extreme low-bit deep learning accelerator,
G. Li, S. Ye, C. Chen, Y . Wang, F. Yang, T. Cao, C. Liu, M. M. S. Aly, and M. Yang, “Lut-dla: Lookup table as efficient extreme low-bit deep learning accelerator,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 671–684
2025
-
[36]
Commvq: Commu- tative vector quantization for kv cache compression,
J. Li, Y . Zhang, M. Y . Hassan, T. Chafekar, T. Cai, Z. Ren, P. Guo, F. Karimzadeh, C. Wang, and C. Gan, “Commvq: Commu- tative vector quantization for kv cache compression,”arXiv preprint arXiv:2506.18879, 2025
-
[37]
Dramsim3: A cycle-accurate, thermal-capable DRAM simulator,
S. Li, Z. Yang, D. Reddy, A. Srivastava, and B. L. Jacob, “Dramsim3: A cycle-accurate, thermal-capable DRAM simulator,”IEEE Comput. Archit. Lett., vol. 19, no. 2, pp. 110–113, 2020. [Online]. Available: https://doi.org/10.1109/LCA.2020.2973991
-
[38]
Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,”Proceedings of machine learning and systems, vol. 6, pp. 87–100, 2024
2024
-
[39]
Speechprune: Context-aware token pruning for speech information retrieval,
Y . Lin, Y . Fu, J. Zhang, Y . Liu, J. Zhang, J. Sun, H. Li, Y . Chenet al., “Speechprune: Context-aware token pruning for speech information retrieval,”arXiv preprint arXiv:2412.12009, 2024
-
[40]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,
Y . Lin, H. Tang, S. Yang, Z. Zhang, G. Xiao, C. Gan, and S. Han, “Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,”arXiv preprint arXiv:2405.04532, 2024
-
[41]
Vptq: Extreme low-bit vector post-training quantization for large language models,
Y . Liu, J. Wen, Y . Wang, S. Ye, L. L. Zhang, T. Cao, C. Li, and M. Yang, “Vptq: Extreme low-bit vector post-training quantization for large language models,”arXiv preprint arXiv:2409.17066, 2024
-
[42]
Vq-llm: High-performance code generation for vector quantization augmented llm inference,
Z. Liu, X. Luo, J. Guo, W. Ni, Y . Zhou, Y . Guan, C. Guo, W. Cui, Y . Feng, M. Guoet al., “Vq-llm: High-performance code generation for vector quantization augmented llm inference,” in2025 IEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1496–1509
2025
-
[43]
Pv-tuning: Beyond straight-through estimation for extreme llm compression,
V . Malinovskii, D. Mazur, I. Ilin, D. Kuznedelev, K. Burlachenko, K. Yi, D. Alistarh, and P. Richtarik, “Pv-tuning: Beyond straight-through estimation for extreme llm compression,” 2024
2024
-
[44]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
LUT tensor core: Lookup table enables efficient low-bit LLM inference acceleration,
Z. Mo, L. Wang, J. Wei, Z. Zeng, S. Cao, L. Ma, N. Jing, T. Cao, J. Xue, F. Yang, and M. Yang, “LUT tensor core: Lookup table enables efficient low-bit LLM inference acceleration,”CoRR, vol. abs/2408.06003, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2408.06003
-
[46]
Genai at the edge: Comprehensive survey on empowering edge devices,
M. Navardi, R. Aalishah, Y . Fu, Y . Lin, H. Li, Y . Chen, and T. Mohs- enin, “Genai at the edge: Comprehensive survey on empowering edge devices,” inProceedings of the AAAI Symposium Series, vol. 5, no. 1, 2025, pp. 180–187
2025
-
[47]
Gpt-4 technical report,
OpenAI, “Gpt-4 technical report,” https://cdn.openai.com/papers/gpt-4. pdf, 2023, accessed: 2025-11-16
2023
-
[48]
Codegemm: A codebook-centric approach to efficient gemm in quantized llms,
G. Park, J. Bae, B. Kim, J. Ryu, H. Kim, S. J. Kwon, D. Lee et al., “Codegemm: A codebook-centric approach to efficient gemm in quantized llms,”arXiv preprint arXiv:2512.17970, 2025
-
[49]
Figlut: An energy-efficient accelerator design for fp-int gemm using look-up tables,
G. Park, H. Kwon, J. Kim, J. Bae, B. Park, D. Lee, and Y . Lee, “Figlut: An energy-efficient accelerator design for fp-int gemm using look-up tables,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1098–1111
2025
-
[50]
Splitwise: Efficient generative LLM inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, ´I. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative LLM inference using phase splitting,” in51st ACM/IEEE Annual International Symposium on Computer Architecture, ISCA 2024, Buenos Aires, Argentina, June 29 - July 3, 2024. IEEE, 2024, pp. 118–132. [Online]. Available: https://doi.org/10.1109/IS...
-
[51]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019
2019
-
[52]
Choice of plausible alternatives: An evaluation of commonsense causal reasoning
M. Roemmele, C. A. Bejan, and A. S. Gordon, “Choice of plausible alternatives: An evaluation of commonsense causal reasoning.” inAAAI spring symposium: logical formalizations of commonsense reasoning, 2011, pp. 90–95
2011
-
[53]
Winogrande: An adversarial winograd schema challenge at scale,
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y . Choi, “Winogrande: An adversarial winograd schema challenge at scale,”Communications of the ACM, vol. 64, no. 9, pp. 99–106, 2021
2021
-
[54]
Platinum: Path-adaptable lut-based accelerator tailored for low-bit weight matrix multiplication,
H. Shan, C. Guo, C. Wei, F. Cheng, J. Zhang, H. H. Li, and Y . Chen, “Platinum: Path-adaptable lut-based accelerator tailored for low-bit weight matrix multiplication,” in2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2026, pp. 1449– 1455
2026
-
[55]
L. Team, “The llama 3 herd of models,”CoRR, vol. abs/2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
[Online]. Available: https://doi.org/10.48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[57]
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,”ACM Trans. Des. Autom. Electron. Syst., vol. 29, no. 3, Apr. 2024. [Online]. Available: https://doi.org/10.1145/3643681
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron and et al., “Llama 2: Open foundation and fine-tuned chat models,”CoRR, vol. abs/2307.09288, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2307.09288
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[59]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
A. Tseng, J. Chee, Q. Sun, V . Kuleshov, and C. De Sa, “Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,”arXiv preprint arXiv:2402.04396, 2024
-
[61]
Gptvq: The blessing of dimensionality for llm quantization,
M. Van Baalen, A. Kuzmin, I. Koryakovskiy, M. Nagel, P. Couperus, C. Bastoul, E. Mahurin, T. Blankevoort, and P. Whatmough, “Gptvq: The blessing of dimensionality for llm quantization,”arXiv preprint arXiv:2402.15319, 2024
-
[62]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S...
2017
-
[63]
BitNet: Scaling 1-bit Transformers for Large Language Models
H. Wang, S. Ma, L. Dong, S. Huang, H. Wang, L. Ma, F. Yang, R. Wang, Y . Wu, and F. Wei, “Bitnet: Scaling 1-bit transformers for large language models,”arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Dobi-svd: Differentiable svd for llm compression and some new perspectives,
Q. Wang*, J. Ke*, M. Tomizuka, K. Keutzer, and C. Xu, “Dobi-svd: Differentiable svd for llm compression and some new perspectives,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[65]
Angles don’t lie: Unlocking training-efficient rl through the model’s own signals,
Q. Wang, J. Ke, H. Ye, Y . Lin, Y . Fu, J. Zhang, K. Keutzer, C. Xu, and Y . Chen, “Angles don’t lie: Unlocking training-efficient rl through the model’s own signals,”arXiv preprint arXiv:2506.02281, 2025
-
[66]
Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spik- ing neural networks,
C. Wei, B. Duan, C. Guo, J. Zhang, Q. Song, H. Li, and Y . Chen, “Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spik- ing neural networks,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 930–943
2025
-
[67]
Prosperity: Accelerating spiking neural networks via product sparsity,
C. Wei, C. Guo, F. Cheng, S. Li, H. F. Yang, H. H. Li, and Y . Chen, “Prosperity: Accelerating spiking neural networks via product sparsity,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 806–820
2025
-
[68]
Focus: A streaming concentration architecture for efficient vision-language models,
C. Wei, C. Guo, J. Zhang, H. Shan, Y . Xu, Z. Zhang, Y . Liu, Q. Wang, C. Zhou, H. H. Liet al., “Focus: A streaming concentration architecture for efficient vision-language models,” in2026 IEEE International Sym- posium on High Performance Computer Architecture (HPCA). IEEE, 2026, pp. 1–18
2026
-
[69]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” inInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, a...
2023
-
[70]
38 087–38 099
PMLR, 2023, pp. 38 087–38 099. [Online]. Available: https: //proceedings.mlr.press/v202/xiao23c.html
2023
-
[71]
Llm. 265: Video codecs are secretly tensor codecs,
C. Xu, Y . Wu, X. Yang, B. Chen, M. Lentz, D. Zhuo, and L. W. Wills, “Llm. 265: Video codecs are secretly tensor codecs,” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture®, 2025, pp. 445–460
2025
-
[72]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Zeroquant: Efficient and affordable post-training quantization for large- scale transformers,
Z. Yao, R. Yazdani Aminabadi, M. Zhang, X. Wu, C. Li, and Y . He, “Zeroquant: Efficient and affordable post-training quantization for large- scale transformers,”Advances in neural information processing systems, vol. 35, pp. 27 168–27 183, 2022
2022
-
[74]
Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization,
H. You, Y . Guo, Y . Fu, W. Zhou, H. Shi, X. Zhang, S. Kundu, A. Yazdanbakhsh, and Y . C. Lin, “Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization,”Advances in Neural Information Processing Systems, vol. 37, pp. 24 822–24 848, 2024
2024
-
[75]
Orca: A distributed serving system for transformer-based generative models,
G. Yu, J. S. Jeong, G. Kim, S. Kim, and B. Chun, “Orca: A distributed serving system for transformer-based generative models,” in16th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2022, Carlsbad, CA, USA, July 11-13, 2022, M. K. Aguilera and H. Weatherspoon, Eds. USENIX Association, 2022, pp. 521–
2022
-
[76]
Available: https://www.usenix.org/conference/osdi22/ presentation/yu
[Online]. Available: https://www.usenix.org/conference/osdi22/ presentation/yu
-
[77]
Gobo: Quan- tizing attention-based nlp models for low latency and energy efficient inference,
A. H. Zadeh, I. Edo, O. M. Awad, and A. Moshovos, “Gobo: Quan- tizing attention-based nlp models for low latency and energy efficient inference,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 811–824
2020
-
[78]
T. Zhang, J. Yi, Z. Xu, and A. Shrivastava, “Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization, 2024b,”URL https://arxiv. org/abs/2405.03917. APPENDIX A. Abstract Our artifact contains (1) a hardware simulator that re- produces all hardware evaluation results (Figures 8–14 and Tables III, VIII–IX) from theEV...
-
[79]
The artifact sources are also archived at Zenodo: https://doi.org/10.5281/zenodo.19433707
How to access:The source code is publicly available at: https://github.com/dbw6/Eva.git. The artifact sources are also archived at Zenodo: https://doi.org/10.5281/zenodo.19433707. Pretrained weights for all evaluated models (LLaMA-2-7B, LLaMA-2-13B, Mixtral-8x7B, and Qwen3-30B-A3B) and datasets are available at: https://huggingface.co/collections/ dbw6/eva
-
[80]
No GPU is required; all simulations run on the CPU
Hardware dependencies:Hardware Simulator:Any x86-64 machine with at least 16 GB of RAM and 10 GB of free disk space. No GPU is required; all simulations run on the CPU. Internet access is required for the first run to download Hugging Face models and datasets. Algorithm Evaluation:An NVIDIA GPU with at least 24 GB VRAM (A100-80GB recommended), CUDA 12.x, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.