Beyond Final Answers: Auditing Trajectory-Level Hallucinations in Multi-Agent Industrial Workflows
Pith reviewed 2026-06-30 15:34 UTC · model grok-4.3
The pith
Trajectory-aware detection outperforms post-hoc verification for hallucinations in multi-agent workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
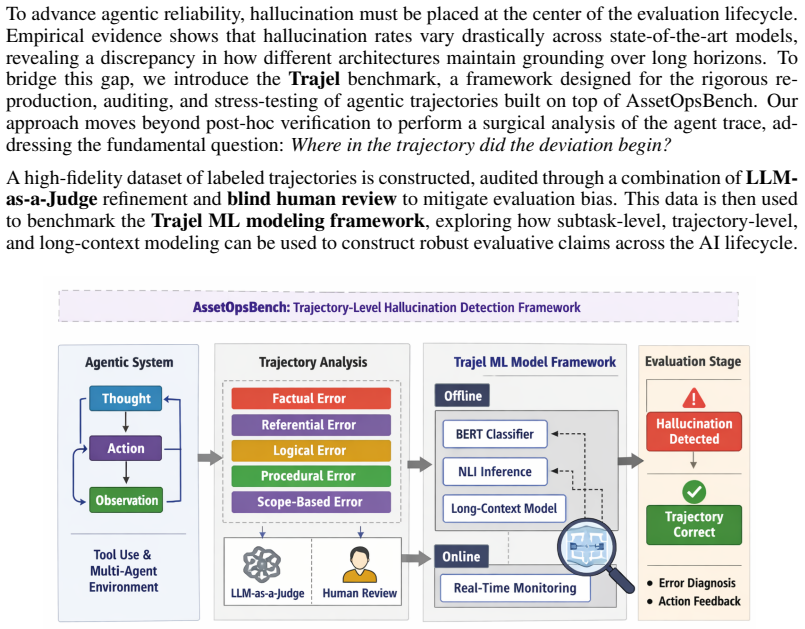
Trajel provides a five-type hallucination taxonomy applied to expert-annotated agent traces from AssetOpsBench, revealing that existing benchmarks miss the most common failure modes, that nearly half of hallucinated trajectories involve multiple types at once, and that automated detectors with high binary accuracy still misclassify the subtlest types, while trajectory-aware detection significantly outperforms standard post-hoc verification.
What carries the argument
The five-type hallucination taxonomy (factual, referential, logical, procedural, and scope-based) applied to intermediate Thought-Action-Observation steps in multi-agent traces.
If this is right
- Existing final-answer benchmarks miss the most common failure modes in agent trajectories.
- Nearly half of hallucinated trajectories contain multiple hallucination types at the same time.
- Detectors that reach high binary accuracy still misclassify the subtlest hallucination types.
- Taxonomy-grounded trajectory evaluation is necessary for safer agentic deployment.
Where Pith is reading between the lines
- Detection systems may need to output sets of concurrent error types rather than single-category labels.
- Live industrial deployments could embed trajectory monitors to interrupt processes before errors propagate.
- The same taxonomy and overlap pattern could be tested on non-industrial multi-agent traces to check domain specificity.
Load-bearing premise
Expert annotations on AssetOpsBench traces accurately capture real-world hallucination types and the five-type taxonomy is both exhaustive and mutually exclusive for industrial multi-agent workflows.
What would settle it
Independent experts re-annotate a sample of trajectories and produce low agreement with the original five-type labels, or new multi-agent workflows are run through the detectors and trajectory-aware methods show no gain over post-hoc verification.
Figures


read the original abstract
Large Language Models (LLMs) are increasingly deployed as autonomous agents that reason, use tools, and act over multiple steps. Yet most hallucination benchmarks still evaluate only the final output, missing failures that originate in intermediate Thought-Action-Observation steps. We present Trajel, a dataset and evaluation framework for auditing trajectory-level hallucinations in multi-agent industrial workflows. Trajel introduces a five-type hallucination taxonomy (factual, referential, logical, procedural, and scope-based) over expert-annotated agent traces from AssetOpsBench. We benchmark supervised detection models at the subtask, trajectory, and long-context levels. Our results show that the most common failure modes are missed by existing benchmarks, that nearly half of hallucinated trajectories involve multiple types at once, and that automated detectors with high binary accuracy still misclassify the subtlest types. Trajectory-aware detection significantly outperforms standard post-hoc verification, making taxonomy-grounded evaluation necessary for safer agentic deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Trajel, a dataset and evaluation framework for auditing trajectory-level hallucinations in multi-agent industrial workflows. It proposes a five-type hallucination taxonomy (factual, referential, logical, procedural, and scope-based) based on expert-annotated traces from AssetOpsBench. The authors benchmark supervised detection models at subtask, trajectory, and long-context levels, reporting that trajectory-aware detection outperforms standard post-hoc verification, that nearly half of hallucinated trajectories involve multiple types, and that high binary accuracy detectors misclassify subtle types.
Significance. If the results hold, this work is significant for the field of AI agents as it demonstrates the limitations of final-answer focused hallucination benchmarks and provides a taxonomy and dataset for trajectory-level analysis in industrial settings. The reporting of annotation guidelines, multiple expert reviewers, and overlap statistics is a strength that supports the reliability of the claims. This could lead to improved safety in deployed multi-agent systems.
major comments (2)
- [Dataset creation section] The section describing the dataset creation: While overlap statistics are provided to address multi-type cases and exhaustiveness, the manuscript should report the inter-annotator agreement metric (e.g., Fleiss' kappa or percentage agreement) to allow assessment of annotation reliability, which is load-bearing for the taxonomy and all downstream claims.
- [Evaluation results section] The evaluation results section: The claim that trajectory-aware detection 'significantly outperforms' post-hoc verification requires supporting statistical tests (e.g., p-values or confidence intervals on performance deltas) to be load-bearing; without them the comparative result is harder to interpret.
minor comments (3)
- [Abstract] The abstract would benefit from including the size of the annotated dataset and one or two key quantitative results to allow readers to gauge the scale of the study.
- [Related work] A dedicated related work subsection comparing Trajel to existing agent trajectory or multi-step hallucination benchmarks would better position the contribution.
- [Figures] Figure captions should be self-contained, explicitly defining axes, legends, and what each plotted quantity represents.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation of minor revision. We address the two major comments below.
read point-by-point responses
-
Referee: [Dataset creation section] The section describing the dataset creation: While overlap statistics are provided to address multi-type cases and exhaustiveness, the manuscript should report the inter-annotator agreement metric (e.g., Fleiss' kappa or percentage agreement) to allow assessment of annotation reliability, which is load-bearing for the taxonomy and all downstream claims.
Authors: We agree that an explicit inter-annotator agreement metric strengthens the reliability claims for the taxonomy. In the revised manuscript we will add the percentage agreement across the multiple expert annotators (computed from the existing multi-review process) to the dataset creation section. revision: yes
-
Referee: [Evaluation results section] The evaluation results section: The claim that trajectory-aware detection 'significantly outperforms' post-hoc verification requires supporting statistical tests (e.g., p-values or confidence intervals on performance deltas) to be load-bearing; without them the comparative result is harder to interpret.
Authors: We acknowledge that statistical support is needed to make the comparative claim load-bearing. In the revised evaluation results section we will report p-values (via paired bootstrap or McNemar tests) and/or confidence intervals on the performance deltas between trajectory-aware and post-hoc detectors. revision: yes
Circularity Check
No significant circularity identified
full rationale
This is an empirical dataset creation and benchmarking study. The central claims rest on new expert annotations of AssetOpsBench traces using a newly introduced five-type taxonomy (factual, referential, logical, procedural, scope-based), with reported guidelines, multiple reviewers, and overlap statistics. No equations, fitted parameters, or derivations appear that reduce to prior results by construction. No self-citation chains or ansatzes are load-bearing for the taxonomy or evaluation results. The derivation chain is self-contained against the new annotations and benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
five-type hallucination taxonomy (factual, referential, logical, procedural, scope-based)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Abd Elrahman Amer and Magdi Amer. Using multi-agent architecture to mitigate the risk of llm hallucinations.arXiv preprint arXiv:2507.01446, 2025
-
[3]
Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
2026
-
[4]
Mirage: Assessing hallucination in multimodal reasoning chains of mllm.Advances in Neural Information Processing Systems, 38:122910–122955, 2026
Bowen Dong, Minheng Ni, Zitong Huang, Guanglei Yang, Wangmeng Zuo, and Lei Zhang. Mirage: Assessing hallucination in multimodal reasoning chains of mllm.Advances in Neural Information Processing Systems, 38:122910–122955, 2026
2026
-
[5]
Pengfei He, Zhenwei Dai, Bing He, Hui Liu, Xianfeng Tang, Hanqing Lu, Juanhui Li, Ji- ayuan Ding, Subhabrata Mukherjee, Suhang Wang, et al. Traject-bench: A trajectory-aware benchmark for evaluating agentic tool use.arXiv preprint arXiv:2510.04550, 2025
-
[6]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computa- tional linguistics (volume 1: long papers), pages 3214–3252, 2022
2022
-
[7]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations, volume 2024, pages 52989–53046, 2024
2024
-
[8]
Yarrabothula, Roman Vaculin, Natalia Martinez, Fearghal O’Donncha, and Jayant Kalagnanam
Dhaval Patel, Shuxin Lin, James Rayfield, Nianjun Zhou, Chathurangi Shyalika, Surya- narayana R Yarrabothula, Roman Vaculin, Natalia Martinez, Fearghal O’donncha, and Jayant Kalagnanam. Assetopsbench: Benchmarking ai agents for task automation in industrial asset operations and maintenance.arXiv preprint arXiv:2506.03828, 2025
-
[9]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[10]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. Cognitive mirage: A review of hallucinations in large language models.arXiv preprint arXiv:2309.06794, 2023
-
[12]
Weichen Zhang, Yiyou Sun, Pohao Huang, Jiayue Pu, Heyue Lin, and Dawn Song. Mirage- bench: Llm agent is hallucinating and where to find them.arXiv preprint arXiv:2507.21017, 2025
-
[13]
Toolbehonest: A multi-level hallucination diagnostic benchmark for tool-augmented large language models
Yuxiang Zhang, Jing Chen, Junjie Wang, Yaxin Liu, Cheng Yang, Chufan Shi, Xinyu Zhu, Zi- hao Lin, Hanwen Wan, Yujiu Yang, et al. Toolbehonest: A multi-level hallucination diagnostic benchmark for tool-augmented large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11388–11422, 2024
2024
-
[14]
uid": "Model_7_Q_509
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, vol- ume 2024, pages 15585–15606, 2024. 11 A Sample Trajectory Figure 2 shows a representative h...
2024
-
[15]
Factual: Fabricates or outputs incorrect information not supported by the context or data
-
[16]
Referential: Refers to entities, systems, or tools that do not exist
-
[17]
Logical: Reaches conclusions that contradict prior reasoning or known facts
-
[18]
Procedural: Skips necessary steps, stops early, or claims success without completing the required reasoning chain
-
[19]
hallucinations
Scope: Answers a different question or changes the target of the task. ### Examples Hallucination (True): - The prompt is about Chiller 6, but the agent queries Chiller 9. - The agent outputs a result for a non-existent sensor. - The agent internally identifies 32C but outputs 52C. - The agent calls a tool that does not exist. - The agent prematurely clai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.