GIBLy: Improving 3D Semantic Segmentation through an Architecture-Agnostic Lightweight Geometric Inductive Bias Layer
Pith reviewed 2026-06-30 15:33 UTC · model grok-4.3
The pith
GIBLy adds a lightweight layer to any 3D segmentation architecture that supplies features aligned with simple geometric shapes to raise accuracy at low cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
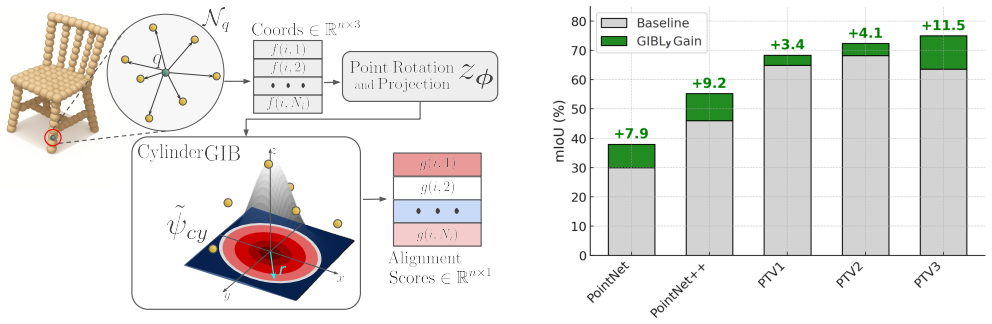
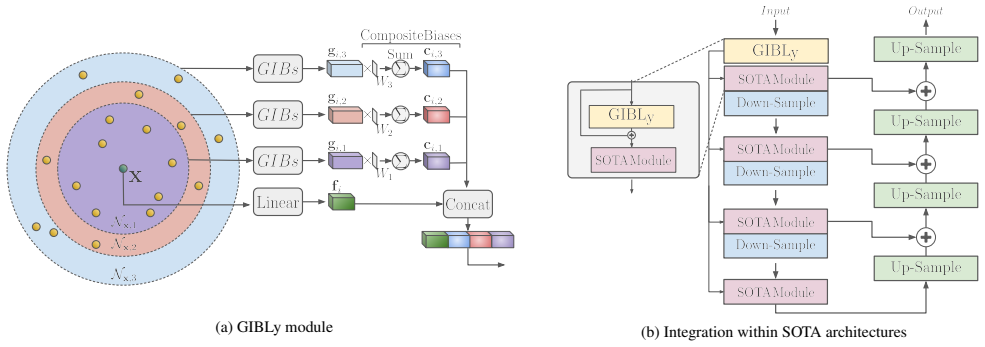
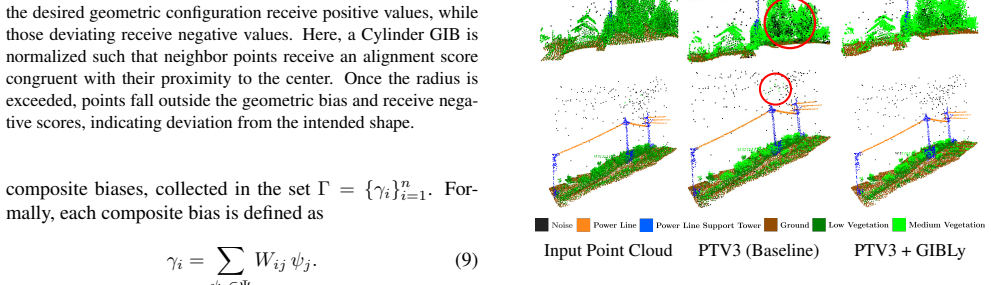
GIBLy is a lightweight geometric inductive bias layer that integrates learnable geometric priors into 3D segmentation pipelines. It enhances existing architectures by providing features aligned with simple geometric shapes that improve segmentation performance with minimal computational overhead. Validation across multiple benchmarks shows consistent performance gains, including up to 11.5 percent mIoU on TS40K with PTV3 while adding only 58K extra parameters.
What carries the argument
The GIBLy layer, which supplies features aligned with simple geometric shapes to the model backbone.
If this is right
- The same layer produces gains when attached to MLP-based, convolution-based, and transformer-based backbones.
- Consistent accuracy lifts appear across several standard 3D semantic segmentation datasets.
- The added cost stays low at roughly 58K parameters regardless of the host architecture.
- The supplied features remain aligned with human-interpretable geometric shapes.
Where Pith is reading between the lines
- Smaller overall models could reach performance levels that currently require much larger networks in 3D tasks.
- The same plug-in approach may transfer to other 3D problems such as object detection or instance segmentation.
- The human-interpretable geometric features could support post-hoc inspection of model decisions on point clouds.
Load-bearing premise
The observed performance gains are produced by the geometric inductive bias rather than by the simple addition of new parameters or altered training dynamics.
What would settle it
Replace the geometric parameters inside GIBLy with random values of the same count, retrain the same backbones, and check whether the reported mIoU gains on TS40K and other benchmarks disappear.
Figures

read the original abstract
In 3D scene understanding, deep learning models rely on large models and extensive training to capture basic geometric structures that are present in the 3D data. However, existing methods lack explicit mechanisms to incorporate geometric information, such as learnable primitive shapes, often necessitating large models and more training data which in turn increases cost and can limit generalization. We introduce GIBLy, a lightweight geometric inductive bias layer that integrates learnable geometric priors into 3D segmentation pipelines. GIBLy enhances existing architectures -- whether MLP-based, convolution-based, or transformer-based -- by providing features aligned with simple geometric shapes (and thus human-interpretable) that improve segmentation performance with minimal computational overhead. We validate our approach across multiple 3D semantic segmentation benchmarks, demonstrating consistent performance gains, including up to +11.5% mIoU on TS40K with PTV3, while adding only 58K extra parameters. Our results highlight the benefit of explicitly encoding geometric structure to support accurate and efficient 3D scene understanding, with a lightweight add-on layer
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GIBLy, a lightweight add-on layer that injects learnable geometric priors (aligned with simple shapes) into existing 3D semantic segmentation architectures (MLP-, CNN-, or transformer-based). It claims consistent mIoU gains across benchmarks, including +11.5% on TS40K with PTV3, while adding only 58K parameters and negligible compute, by providing human-interpretable geometric features that reduce reliance on large models or extra data.
Significance. If the reported gains are shown to stem specifically from the geometric inductive bias (rather than added capacity), the method would offer a practical, architecture-agnostic way to encode basic 3D structure in segmentation pipelines. This could support more efficient training and better generalization on geometric scenes, with the small parameter count making it easy to adopt as a plug-in module.
major comments (2)
- [Experiments] Experiments section (and abstract): the central attribution of mIoU gains (e.g., +11.5% on TS40K with PTV3) to the geometric inductive bias is not isolated from the effect of inserting any 58K-parameter module. No ablation compares GIBLy against a parameter-matched non-geometric control (random features, plain MLP, or frozen weights) at the identical insertion point, nor reports architecture-specific retuning ablations. This leaves open whether the improvement arises from the learnable priors or from optimization dynamics of the added capacity.
- [Method and Results] § on method and results: the claim that GIBLy is 'architecture-agnostic' and integrates 'cleanly' into arbitrary backbones lacks evidence on whether insertion requires per-architecture hyperparameter retuning or produces hidden conflicts in feature scales or gradient flow. Without such checks the generality assertion remains untested.
minor comments (2)
- [Abstract] Abstract and §1: performance numbers are stated without reference to exact baselines, data splits, number of runs, or statistical significance; adding these details would strengthen the claims even if the ablations above are the primary concern.
- [Method] Notation: the description of 'learnable geometric priors' and how they are aligned with 'simple geometric shapes' would benefit from an explicit equation or diagram showing the prior parameterization and the feature-alignment operation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major point below and will revise the manuscript accordingly to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Experiments] the central attribution of mIoU gains to the geometric inductive bias is not isolated from the effect of inserting any 58K-parameter module. No ablation compares GIBLy against a parameter-matched non-geometric control.
Authors: We agree that the current experiments do not include a parameter-matched non-geometric control (e.g., random features or plain MLP) at the identical insertion point. This is a valid concern for isolating the geometric prior's contribution. In the revised manuscript we will add such ablations across the reported backbones and datasets, along with frozen-weight controls, to directly address whether gains arise from the geometric alignment rather than added capacity. revision: yes
-
Referee: [Method and Results] the claim that GIBLy is 'architecture-agnostic' and integrates 'cleanly' lacks evidence on whether insertion requires per-architecture hyperparameter retuning or produces hidden conflicts in feature scales or gradient flow.
Authors: Our experiments already demonstrate integration into MLP-, CNN-, and transformer-based models with consistent gains using the same default hyperparameters and insertion strategy. However, we did not explicitly analyze retuning requirements or potential scale/gradient issues. We will add a dedicated subsection with gradient-norm statistics, feature-scale comparisons before/after insertion, and a note on whether any architecture-specific adjustments were needed, to better substantiate the agnostic claim. revision: yes
Circularity Check
No circularity: additive layer with empirical validation, no derivations or self-referential reductions
full rationale
The paper presents GIBLy as an architecture-agnostic additive layer that injects learnable geometric priors into existing 3D segmentation backbones (MLP, conv, transformer). No equations, uniqueness theorems, or derivation chains appear in the provided text that would reduce the reported mIoU gains or feature alignments to quantities defined by the method's own fitted parameters. Performance claims rest on benchmark experiments rather than any self-definitional or fitted-input-called-prediction structure. Self-citations, if present, are not load-bearing for the central claim, which remains an independent empirical proposal rather than a closed loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable geometric priors
axioms (1)
- domain assumption Features aligned with simple geometric shapes improve 3D semantic segmentation when added to existing models
Reference graph
Works this paper leans on
-
[1]
3d seman- tic parsing of large-scale indoor spaces
Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d seman- tic parsing of large-scale indoor spaces. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1534–1543, 2016. 2, 6, 7
2016
-
[2]
A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000. 3
2000
-
[3]
Se- mantickitti: A dataset for semantic scene understanding of lidar sequences
Jens Behley, Martin Garbade, Andres Milioto, Jan Quen- zel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. Se- mantickitti: A dataset for semantic scene understanding of lidar sequences. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9297–9307,
-
[4]
Geometry-informed neural networks.arXiv preprint arXiv:2402.14009, 2024
Arturs Berzins, Andreas Radler, Eric V olkmann, Sebas- tian Sanokowski, Sepp Hochreiter, and Johannes Brandstet- ter. Geometry-informed neural networks.arXiv preprint arXiv:2402.14009, 2024. 3
-
[5]
Geneonet: A new machine learning paradigm based on group equivariant non-expansive operators
Giovanni Bocchi, Patrizio Frosini, Alessandra Micheletti, Alessandro Pedretti, Carmen Gratteri, Filippo Lunghini, An- drea Rosario Beccari, and Carmine Talarico. Geneonet: A new machine learning paradigm based on group equivariant non-expansive operators. an application to protein pocket de- tection.arXiv preprint arXiv:2202.00451, 2022. 3
-
[6]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 2, 6, 7
2020
-
[7]
Non- parametric boundary geometry in physics informed deep learning.Advances in Neural Information Processing Sys- tems, 36, 2024
Scott Cameron, Arnu Pretorius, and Stephen Roberts. Non- parametric boundary geometry in physics informed deep learning.Advances in Neural Information Processing Sys- tems, 36, 2024. 3
2024
-
[8]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3075–3084,
-
[9]
Inductive Bias of Deep Convolutional Networks through Pooling Geometry
Nadav Cohen and Amnon Shashua. Inductive bias of deep convolutional networks through pooling geometry.arXiv preprint arXiv:1605.06743, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 2, 6, 7
2017
-
[11]
Inductive biases for deep learning of higher-level cognition.Proceedings of the Royal Society A, 478(2266):20210068, 2022
Anirudh Goyal and Yoshua Bengio. Inductive biases for deep learning of higher-level cognition.Proceedings of the Royal Society A, 478(2266):20210068, 2022. 3
2022
-
[12]
Flex-convolution: Million-scale point-cloud learning beyond grid-worlds
Fabian Groh, Patrick Wieschollek, and Hendrik PA Lensch. Flex-convolution: Million-scale point-cloud learning beyond grid-worlds. InAsian Conference on Computer Vision, pages 105–122. Springer, 2018. 2
2018
-
[13]
Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12,
Rana Hanocka, Amir Hertz, Noa Fish, Raja Giryes, Shachar Fleishman, and Daniel Cohen-Or. Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12,
-
[14]
Monte carlo convolution for learning on non-uniformly sampled point clouds.ACM Transactions On Graphics (TOG), 37(6):1–12, 2018
Pedro Hermosilla, Tobias Ritschel, Pere-Pau V ´azquez, `Alvar Vinacua, and Timo Ropinski. Monte carlo convolution for learning on non-uniformly sampled point clouds.ACM Transactions On Graphics (TOG), 37(6):1–12, 2018. 2
2018
-
[15]
Rethinking range view representation for lidar segmentation
Lingdong Kong, Youquan Liu, Runnan Chen, Yuexin Ma, Xinge Zhu, Yikang Li, Yuenan Hou, Yu Qiao, and Ziwei Liu. Rethinking range view representation for lidar segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 228–240, 2023. 2
2023
-
[16]
Stratified trans- former for 3d point cloud segmentation
Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, and Jiaya Jia. Stratified trans- former for 3d point cloud segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8500–8509, 2022. 1, 2
2022
-
[17]
Spherical transformer for lidar-based 3d recognition
Xin Lai, Yukang Chen, Fanbin Lu, Jianhui Liu, and Jiaya Jia. Spherical transformer for lidar-based 3d recognition. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17545–17555, 2023. 2
2023
-
[18]
Pointpillars: Fast encoders for object detection from point clouds
Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12697–12705, 2019. 2
2019
-
[19]
Diogo Lavado, Cl ´audia Soares, Alessandra Micheletti, Gio- vanni Bocchi, Alex Coronati, Manuel Silva, and Patrizio Frosini. Low-resource white-box semantic segmentation of supporting towers on 3d point clouds via signature shape identification.arXiv preprint arXiv:2306.07809, 2023. 3
-
[20]
Scene-net v2: Interpretable multiclass 3d scene understand- ing with geometric priors.PROCEEDINGS OF MACHINE LEARNING RESEARCH, 251:222–232, 2024
Diogo Lavado, Cl ´audia Soares, Alessandra Micheletti, et al. Scene-net v2: Interpretable multiclass 3d scene understand- ing with geometric priors.PROCEEDINGS OF MACHINE LEARNING RESEARCH, 251:222–232, 2024. 3
2024
-
[21]
Learning under noisy labels, spurious points, and diverse structures: Ts40k, a 3d point cloud dataset of rural terrain and electrical trans- mission systems
Diogo Lavado, Ricardo Santos, Andr ´e Coelho, Jo˜ao Santos, Alessandra Micheletti, and Claudia Soares. Learning under noisy labels, spurious points, and diverse structures: Ts40k, a 3d point cloud dataset of rural terrain and electrical trans- mission systems. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7326–7336. IE...
2025
-
[22]
Towards under- standing inductive bias in transformers: A view from infinity
Itay Lavie, Guy Gur-Ari, and Zohar Ringel. Towards under- standing inductive bias in transformers: A view from infinity. InProceedings of the 41st International Conference on Ma- chine Learning, pages 26043–26069. PMLR, 2024. 3 9
2024
-
[23]
Deep projective 3d semantic segmentation
Felix J ¨aremo Lawin, Martin Danelljan, Patrik Tosteberg, Goutam Bhat, Fahad Shahbaz Khan, and Michael Felsberg. Deep projective 3d semantic segmentation. InComputer Analysis of Images and Patterns: 17th International Confer- ence, CAIP 2017, Ystad, Sweden, August 22-24, 2017, Pro- ceedings, Part I 17, pages 95–107. Springer, 2017. 2
2017
-
[24]
Pointgrid: A deep network for 3d shape understanding
Truc Le and Ye Duan. Pointgrid: A deep network for 3d shape understanding. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9204– 9214, 2018. 2
2018
-
[25]
Octree guided cnn with spherical kernels for 3d point clouds
Huan Lei, Naveed Akhtar, and Ajmal Mian. Octree guided cnn with spherical kernels for 3d point clouds. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9631–9640, 2019. 2
2019
-
[26]
Spherical kernel for efficient graph convolution on 3d point clouds.IEEE transactions on pattern analysis and machine intelligence, 43(10):3664–3680, 2020
Huan Lei, Naveed Akhtar, and Ajmal Mian. Spherical kernel for efficient graph convolution on 3d point clouds.IEEE transactions on pattern analysis and machine intelligence, 43(10):3664–3680, 2020. 2
2020
-
[27]
Pointcnn: Convolution on x-transformed points.Advances in neural information processing systems, 31, 2018
Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points.Advances in neural information processing systems, 31, 2018. 1, 2, 4
2018
-
[28]
Geometry-informed neural operator for large-scale 3d pdes.Advances in Neural Information Processing Systems, 36, 2024
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Mohammad Amin Nabian, Maxi- milian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry-informed neural operator for large-scale 3d pdes.Advances in Neural Information Processing Systems, 36, 2024. 3
2024
-
[29]
Learning to segment 3d point clouds in 2d image space
Yecheng Lyu, Xinming Huang, and Ziming Zhang. Learning to segment 3d point clouds in 2d image space. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12255–12264, 2020. 2
2020
-
[30]
V oxnet: A 3d con- volutional neural network for real-time object recognition
Daniel Maturana and Sebastian Scherer. V oxnet: A 3d con- volutional neural network for real-time object recognition. In2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 922–928. IEEE, 2015. 1, 2
2015
-
[31]
Vv-net: V oxel vae net with group convolutions for point cloud segmentation
Hsien-Yu Meng, Lin Gao, Yu-Kun Lai, and Dinesh Manocha. Vv-net: V oxel vae net with group convolutions for point cloud segmentation. InProceedings of the IEEE/CVF international conference on computer vision, pages 8500– 8508, 2019. 1, 2
2019
-
[32]
Geometry aware physics in- formed neural network surrogate for solving navier–stokes equation (gapinn).Advanced Modeling and Simulation in Engineering Sciences, 9(1):8, 2022
Jan Oldenburg, Finja Borowski, Alper ¨Oner, Klaus-Peter Schmitz, and Michael Stiehm. Geometry aware physics in- formed neural network surrogate for solving navier–stokes equation (gapinn).Advanced Modeling and Simulation in Engineering Sciences, 9(1):8, 2022. 3
2022
-
[33]
Fast point transformer
Chunghyun Park, Yoonwoo Jeong, Minsu Cho, and Jae- sik Park. Fast point transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16949–16958, 2022. 2
2022
-
[34]
Oa-cnns: Omni- adaptive sparse cnns for 3d semantic segmentation
Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Heng- shuang Zhao, Zhuotao Tian, and Jiaya Jia. Oa-cnns: Omni- adaptive sparse cnns for 3d semantic segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21305–21315, 2024. 1, 2
2024
-
[35]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[36]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 1, 2, 6, 7
2017
-
[37]
Dynamic edge- conditioned filters in convolutional neural networks on graphs
Martin Simonovsky and Nikos Komodakis. Dynamic edge- conditioned filters in convolutional neural networks on graphs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3693–3702, 2017. 2
2017
-
[38]
Multi-view convolutional neural networks for 3d shape recognition
Hang Su, Subhransu Maji, Evangelos Kalogerakis, and Erik Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. InProceedings of the IEEE in- ternational conference on computer vision, pages 945–953,
-
[39]
Canonical capsules: Self-supervised cap- sules in canonical pose.Advances in Neural information processing systems, 34:24993–25005, 2021
Weiwei Sun, Andrea Tagliasacchi, Boyang Deng, Sara Sabour, Soroosh Yazdani, Geoffrey E Hinton, and Kwang Moo Yi. Canonical capsules: Self-supervised cap- sules in canonical pose.Advances in Neural information processing systems, 34:24993–25005, 2021. 3
2021
-
[40]
Kpconv: Flexible and deformable convolution for point clouds
Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J Guibas. Kpconv: Flexible and deformable convolution for point clouds. InProceedings of the IEEE/CVF international conference on computer vision, pages 6411–6420, 2019. 1, 2, 6, 7
2019
-
[41]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 1, 2
2017
-
[42]
Graph attention convolution for point cloud se- mantic segmentation
Lei Wang, Yuchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud se- mantic segmentation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 10296–10305, 2019. 2
2019
-
[43]
Octformer: Octree-based transformers for 3d point clouds.ACM Transactions on Graphics (TOG), 42(4):1–11, 2023
Peng-Shuai Wang. Octformer: Octree-based transformers for 3d point clouds.ACM Transactions on Graphics (TOG), 42(4):1–11, 2023. 1, 2
2023
-
[44]
O-cnn: Octree-based convolutional neu- ral networks for 3d shape analysis.ACM Transactions On Graphics (TOG), 36(4):1–11, 2017
Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-cnn: Octree-based convolutional neu- ral networks for 3d shape analysis.ACM Transactions On Graphics (TOG), 36(4):1–11, 2017. 2
2017
-
[45]
Deep parametric continu- ous convolutional neural networks
Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep parametric continu- ous convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2589–2597, 2018. 2
2018
-
[46]
Theoretical analysis of the induc- tive biases in deep convolutional networks.Advances in Neu- ral Information Processing Systems, 36:74289–74338, 2023
Zihao Wang and Lei Wu. Theoretical analysis of the induc- tive biases in deep convolutional networks.Advances in Neu- ral Information Processing Systems, 36:74289–74338, 2023. 3
2023
-
[47]
Pointconv: Deep convolutional networks on 3d point clouds
Wenxuan Wu, Zhongang Qi, and Li Fuxin. Pointconv: Deep convolutional networks on 3d point clouds. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 9621–9630, 2019. 1, 2, 4
2019
-
[48]
Point transformer v2: Grouped vector atten- tion and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point transformer v2: Grouped vector atten- tion and partition-based pooling. InNeurIPS, 2022. 1, 2, 6, 7 10
2022
-
[49]
Point transformer v3: Simpler faster stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4840–4851, 2024. 1, 2, 6, 7, 8
2024
-
[50]
Permutation equivariance of trans- formers and its applications
Hengyuan Xu, Liyao Xiang, Hangyu Ye, Dixi Yao, Pengzhi Chu, and Baochun Li. Permutation equivariance of trans- formers and its applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5987–5996, 2024. 3
2024
-
[51]
Spidercnn: Deep learning on point sets with parameterized convolutional filters
Yifan Xu, Tianqi Fan, Mingye Xu, Long Zeng, and Yu Qiao. Spidercnn: Deep learning on point sets with parameterized convolutional filters. InProceedings of the European con- ference on computer vision (ECCV), pages 87–102, 2018. 2, 4
2018
-
[52]
$SE(3)$ equivariant convolution and transformer in ray space
Yinshuang Xu, Jiahui Lei, and Kostas Daniilidis. $SE(3)$ equivariant convolution and transformer in ray space. In Thirty-seventh Conference on Neural Information Process- ing Systems, 2023. 3
2023
-
[53]
Learning relationships for multi- view 3d object recognition
Ze Yang and Liwei Wang. Learning relationships for multi- view 3d object recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 7505– 7514, 2019. 2
2019
-
[54]
Input-level inductive biases for 3d reconstruction
Wang Yifan, Carl Doersch, Relja Arandjelovi ´c, Joao Car- reira, and Andrew Zisserman. Input-level inductive biases for 3d reconstruction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6176–6186, 2022. 3
2022
-
[55]
Polarnet: An improved grid representation for online lidar point clouds se- mantic segmentation
Yang Zhang, Zixiang Zhou, Philip David, Xiangyu Yue, Ze- rong Xi, Boqing Gong, and Hassan Foroosh. Polarnet: An improved grid representation for online lidar point clouds se- mantic segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9601–9610, 2020. 2
2020
-
[56]
Point transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021. 1, 2, 6, 7
2021
-
[57]
Cylindrical and asymmetrical 3d convolution networks for lidar-based perception.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(10):6807–6822, 2021
Xinge Zhu, Hui Zhou, Tai Wang, Fangzhou Hong, Wei Li, Yuexin Ma, Hongsheng Li, Ruigang Yang, and Dahua Lin. Cylindrical and asymmetrical 3d convolution networks for lidar-based perception.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(10):6807–6822, 2021. 2 11
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.