Hybrid Quantum-Classical Machine Learning Algorithms for Multi-Output Time-Series Forecasting at Utility Scale
Pith reviewed 2026-06-30 15:17 UTC · model grok-4.3
The pith
Hybrid quantum-classical models reduce multi-output time-series forecast errors by up to 62 percent compared to classical baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
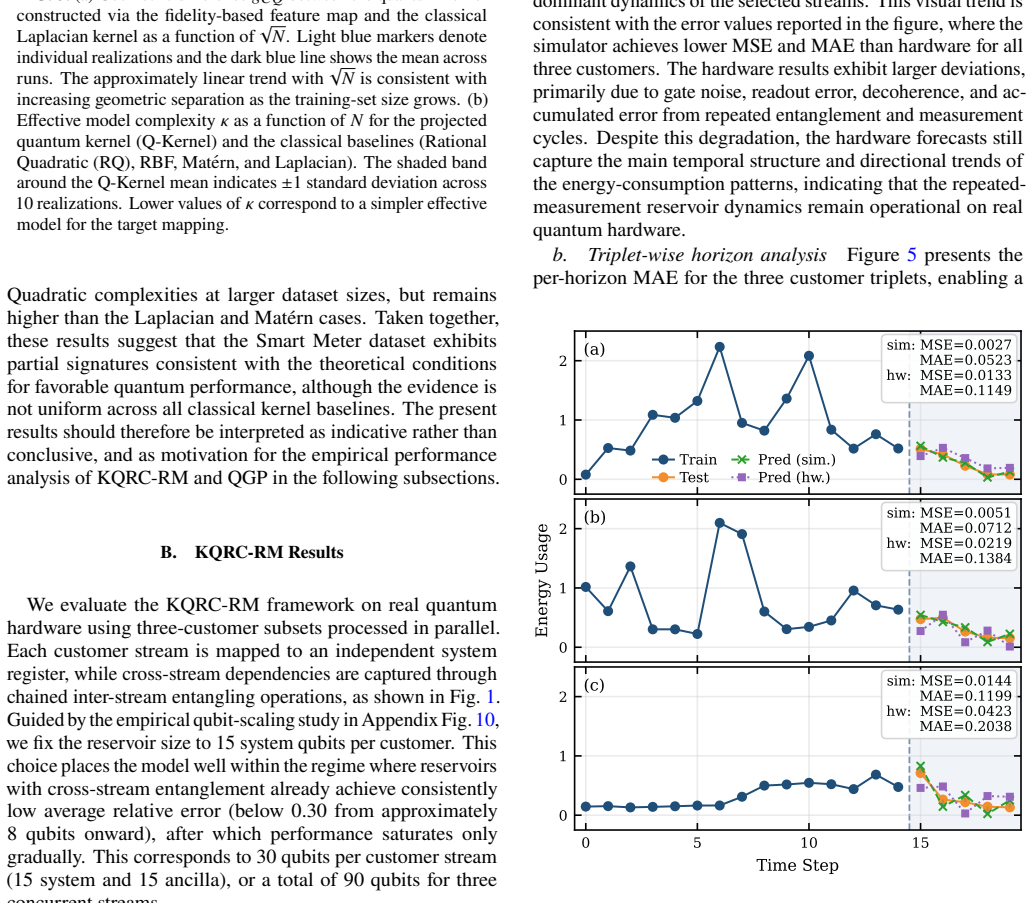
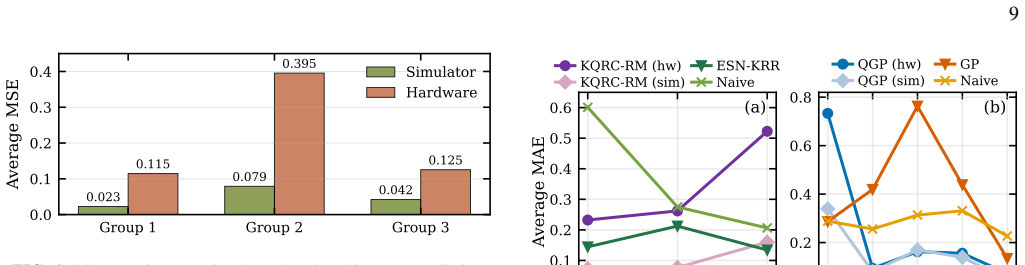
The Kernelized Quantum Reservoir Computing with Repeated Measurement model using 114 qubits reaches an MAE of 0.0811 on an MPS simulator for three-stream inputs and outputs, a 36.92 percent improvement over the classical analog, and an MAE of 0.1524 on hardware. The Projected Quantum Kernel Gaussian Process model on a 100-qubit topology-aware circuit predicts 100 multi-output values and lowers average MAE relative to the classical GP baseline by 62.01 percent on the simulator and 40.37 percent on hardware, with 49 percent of outputs falling in the high-accuracy regime below 0.15 MAE.
What carries the argument
Coupled quantum reservoirs with ancilla-assisted repeated measurement and kernelized readouts in the first model, together with projected kernels built from local reduced-state statistics in the second model.
If this is right
- The 114-qubit reservoir model delivers a 36.92 percent MAE reduction on simulator for three-stream forecasting.
- The 100-qubit projected-kernel Gaussian process achieves a 62.01 percent average MAE reduction on simulator and 40.37 percent on hardware.
- 49 percent of the 100 predicted outputs fall below 0.15 MAE under the projected-kernel model.
- Both frameworks remain feasible on current superconducting processors at the 100-qubit scale.
- The methods jointly capture temporal dynamics and cross-stream correlations in multi-output series.
Where Pith is reading between the lines
- The same projected-kernel construction could be tested on other multi-variate forecasting domains such as traffic or weather series.
- Hardware performance gaps might narrow if circuit depths are reduced while preserving the local reduced-state statistics.
- The repeated-measurement readout technique may combine with other reservoir architectures beyond the coupled design shown here.
- Scaling the number of streams beyond 100 could clarify at what point the quantum advantage saturates or grows.
Load-bearing premise
The classical baseline models receive equivalent hyperparameter optimization and data preprocessing as the quantum models.
What would settle it
Re-running the classical baselines with additional hyperparameter search effort or higher-capacity architectures until their MAE matches or exceeds the quantum results on the same dataset splits.
Figures


read the original abstract
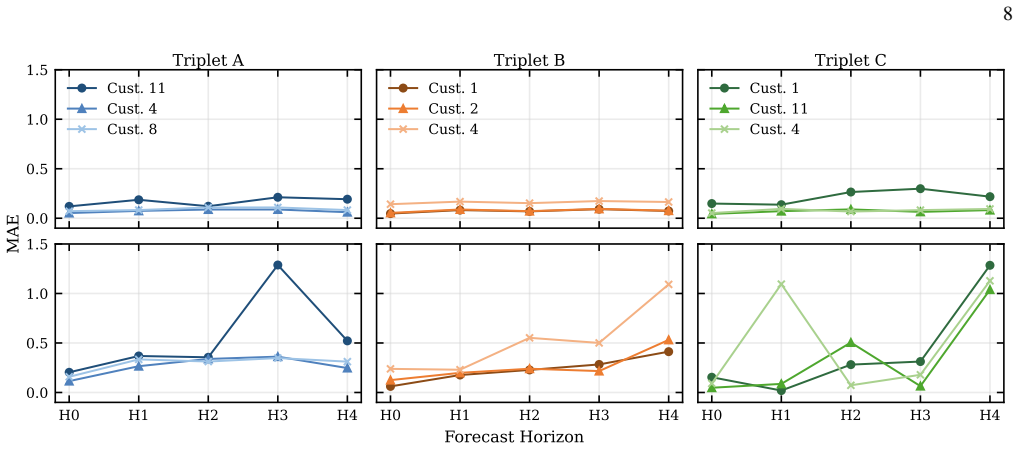
Multi-output time-series forecasting in energy systems is challenging because of nonlinear dynamics, multi-scale seasonality, and strong dependencies across correlated series. In this work, we investigate two hybrid quantum-classical frameworks for multi-stream time-series forecasting on a real Smart Meter dataset comprising 103 household electricity consumption time-series, with experiments executed on the $ibm\_marrakesh$ superconducting quantum processor. The first model, Kernelized Quantum Reservoir Computing with Repeated Measurement (KQRC-RM), combines coupled quantum reservoirs, ancilla-assisted repeated measurement, and kernelized readouts to model temporal dynamics and cross-stream correlations jointly. For a 3-stream time-series input and output, the KQRC-RM model using 114 qubits achieves an MAE of 0.0811 on MPS simulator (36.92\% improvement over its classical analog) whereas performance degrades to an MAE of 0.1524 on hardware. The second, a Projected Quantum Kernel Gaussian Process (QGP), replaces fidelity-based kernels with projected kernels constructed from local reduced-state statistics. Using a topology-aware 100-qubit QGP model to predict 100 multi-output time-series values, we observe 49\% of time-series outputs achieve high-accuracy predictions (MAE $<0.15$), with an average MAE of $0.082$ for this low-error group. The medium-error regime (MAE $0.15$-$0.35$) has an average MAE of $0.229$, while the high-error regime (MAE $>0.35$) has an average MAE of $0.664$. Overall, this reduces the average MAE relative to the classical GP baseline by 62.01\% on MPS simulator and 40.37\% on hardware. Together, these results demonstrate the feasibility of hybrid quantum machine learning for multi-input, multi-output time-series forecasting at the 100+ qubit scale on NISQ devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces two hybrid quantum-classical models for multi-output time-series forecasting on a 103-household smart-meter electricity dataset: Kernelized Quantum Reservoir Computing with Repeated Measurement (KQRC-RM) using up to 114 qubits and Projected Quantum Kernel Gaussian Process (QGP) using 100 qubits. Experiments are performed on an MPS simulator and the ibm_marrakesh superconducting processor. The paper reports concrete MAE values (e.g., 0.0811 for 3-stream KQRC-RM on simulator, 0.1524 on hardware; average MAE 0.082 for a low-error subset of QGP outputs) together with percentage improvements over unspecified classical analogs (36.92 % for KQRC-RM; 62.01 % simulator / 40.37 % hardware for QGP).
Significance. If the classical baselines receive equivalent hyperparameter optimization, preprocessing, and capacity matching, the results would constitute a concrete demonstration that hybrid quantum models can be executed at the 100-qubit scale on real hardware for a utility-relevant forecasting task. The work supplies explicit qubit counts, hardware run details, and regime-specific MAE breakdowns that could be reproduced or extended.
major comments (2)
- [Abstract] Abstract: the headline performance claims rest on MAE reductions of 36.92 % (KQRC-RM) and 62.01 % / 40.37 % (QGP) relative to a 'classical analog' and 'classical GP baseline' whose architectures, hyperparameter search protocols, regularization, multi-output handling, and effective capacity are never described. Because these deltas are the sole quantitative evidence offered for quantum advantage, the absence of this information is load-bearing; modest under-tuning of a classical GP on seasonal data routinely yields 30-60 % MAE gaps.
- [Abstract] Abstract: no error bars, statistical significance tests, cross-validation details, or hyperparameter-search budgets are supplied for either the quantum or classical models. The specific MAE figures (0.0811, 0.1524, 0.082, etc.) therefore cannot be evaluated for robustness.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance claims rest on MAE reductions of 36.92 % (KQRC-RM) and 62.01 % / 40.37 % (QGP) relative to a 'classical analog' and 'classical GP baseline' whose architectures, hyperparameter search protocols, regularization, multi-output handling, and effective capacity are never described. Because these deltas are the sole quantitative evidence offered for quantum advantage, the absence of this information is load-bearing; modest under-tuning of a classical GP on seasonal data routinely yields 30-60 % MAE gaps.
Authors: The referee correctly identifies that the abstract does not detail the classical baselines. In the main text (Sections 2 and 3), we describe the classical analog as a classical kernelized reservoir computer with reservoir dimension matched to the quantum case (114 units) and the same kernel readout, and the classical GP as a standard multi-output GP with RBF kernel optimized over the same hyperparameter grid. However, to make the abstract self-contained and address the concern about potential under-tuning, we will revise the abstract to include a concise description of these classical models and the capacity-matching procedure used for fair comparison. This revision will be made. revision: yes
-
Referee: [Abstract] Abstract: no error bars, statistical significance tests, cross-validation details, or hyperparameter-search budgets are supplied for either the quantum or classical models. The specific MAE figures (0.0811, 0.1524, 0.082, etc.) therefore cannot be evaluated for robustness.
Authors: We agree that the abstract lacks these statistical details, which are important for evaluating robustness. The full manuscript reports results from 5-fold cross-validation across the dataset splits and multiple independent runs (with standard deviations provided in the supplementary material for the simulator and hardware experiments). To improve the abstract, we will add error bars to the reported MAE values and include a brief mention of the cross-validation and equivalent hyperparameter search budgets for quantum and classical models. This will allow readers to better assess the reliability of the reported improvements. revision: yes
Circularity Check
No significant circularity in claimed results
full rationale
The paper reports empirical MAE metrics and percentage improvements for KQRC-RM and QGP models versus classical baselines on a real dataset. No mathematical derivation chain, first-principles result, or predictive equation is presented that reduces by construction to its own inputs, fitted parameters, or self-citations. The comparisons are framed as experimental outcomes rather than derived quantities, and the provided text contains no self-definitional structures, ansatzes smuggled via citation, or uniqueness theorems that would trigger the enumerated circularity patterns. The central claims remain independent of the listed circularity mechanisms.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Measurement-enabled online quantum processing with amplitude encoding
A new protocol for online amplitude-encoded quantum reservoir computing is proposed that uses mid-circuit measurement and reset to implement partial-trace dynamics and indirect measurements for observables.
Reference graph
Works this paper leans on
-
[1]
, 𝑥(𝑆) 𝑡 } sampled at discrete timesteps 𝑡=1,2,
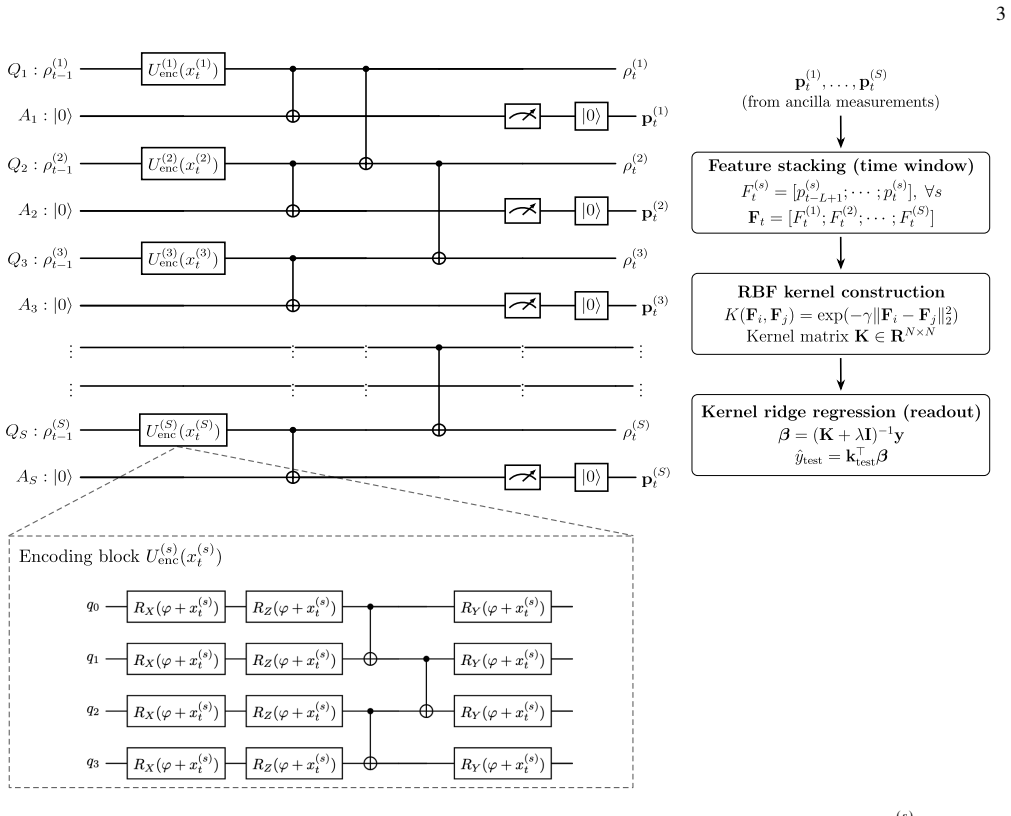
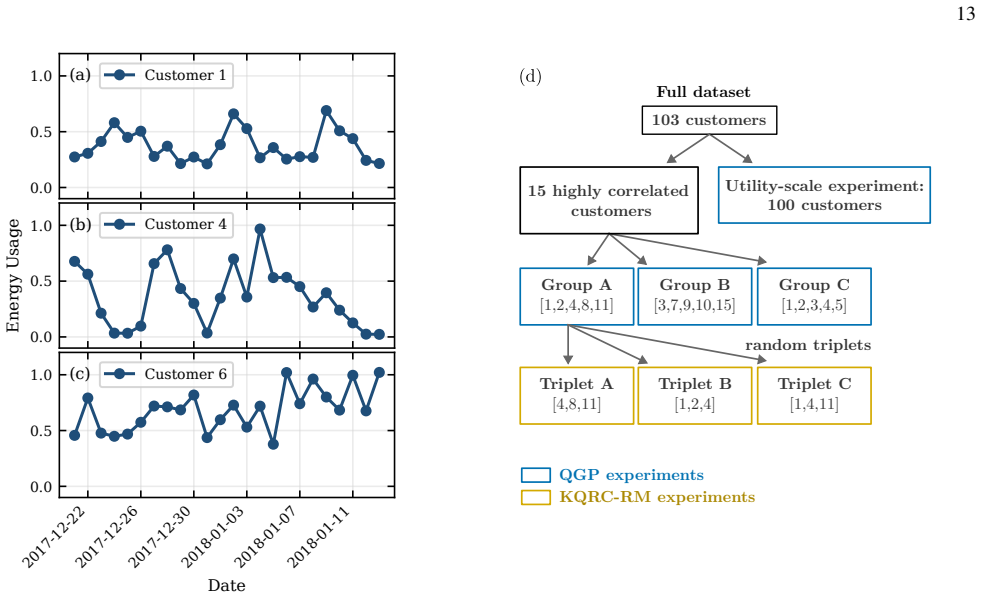
Reservoir Architecture and Encoding We consider 𝑆 correlated time-series {𝑥 (1) 𝑡 , 𝑥 (2) 𝑡 , . . . , 𝑥(𝑆) 𝑡 } sampled at discrete timesteps 𝑡=1,2, . . . , 𝑇 . In our setting, each series corresponds to the energy consumption of a distinct customer, although the framework readily extends to other types of correlated signals (e.g., voltage stability or gen...
-
[2]
As illustrated in Fig
Cross-Series Entangling Dynamics After encoding, entangling interactions are introduced to model dependencies among the time-series. As illustrated in Fig. 1, these interactions act (i) within each individual series, and (ii) across neighboring series. Let 𝑞𝑠,𝑛 𝑞 −1 denote the tail qubit of series 𝑠 and 𝑞𝑠+1,0 the head qubit of the next series 𝑠+1. Two-qu...
-
[3]
Ancilla-Based Readout and Kernelized Regression Following the reservoir evolution, each system qubit𝑞𝑠,𝑖 is coupled to its paired ancilla 𝑎𝑠,𝑖 through a readout unitary 𝑈SA. The joint system–ancilla state before measurement is ˜𝜌𝑡 =𝑈 SA 𝜌res 𝑡 ⊗ |0· · ·0⟩⟨0· · ·0|anc 𝑈† SA.(5) Only the ancilla qubits are measured, while the system qubits retain coherence ...
-
[4]
,y (𝐷) ] ∈R 𝑁×𝐷 denote the corresponding multi-output training targets, where 𝐷 is the number of outputs
Quantum Gaussian Process For a multi-input, multi-output setting, let 𝑋={x 𝑖 } 𝑁 𝑖=1 denote the training inputs, where each x𝑖 is a multivariate input vector, and 𝑌=[y (1) , . . . ,y (𝐷) ] ∈R 𝑁×𝐷 denote the corresponding multi-output training targets, where 𝐷 is the number of outputs. The test inputs are denoted by𝑋 ∗. We adopt an independent-output Gauss...
-
[5]
Let |𝜓(𝑥)⟩=𝑈 𝜙 (𝑥, 𝜃) |0· · ·0⟩ denote the quantum feature state prepared from input𝑥by the parameterized feature map 𝑈𝜙
Projected Kernel Construction Following the projected quantum kernel construction intro- duced in [12, 13], we compare inputs through local reduced density matrices rather than through full-state fidelities. Let |𝜓(𝑥)⟩=𝑈 𝜙 (𝑥, 𝜃) |0· · ·0⟩ denote the quantum feature state prepared from input𝑥by the parameterized feature map 𝑈𝜙. Let {1,2, . . . , 𝑛 𝑞 } den...
-
[6]
Substituting this expansion into Eq
Measurement-Based Kernel Estimation and Circuit Architecture The projected kernel (18) can be evaluated from measure- ment outcomes by expanding each reduced density matrix into the Pauli basisP 𝑘 ={𝐼, 𝑋, 𝑌 , 𝑍} ⊗𝑘 : 𝜌K (𝑥)= 1 2𝑘 ∑︁ 𝑃∈ P𝑘 ⟨𝑃⟩ 𝑥,K 𝑃,(19) where ⟨𝑃⟩ 𝑥,K is the expectation value of the Pauli operator 𝑃 on subset K for the state encoded by inp...
-
[7]
A native implementation therefore leads to a worst-case complexity of O 𝑁2 · 𝑛𝑞 𝑘 ·4 2𝑘 ,(21) which becomes prohibitive for large𝑘
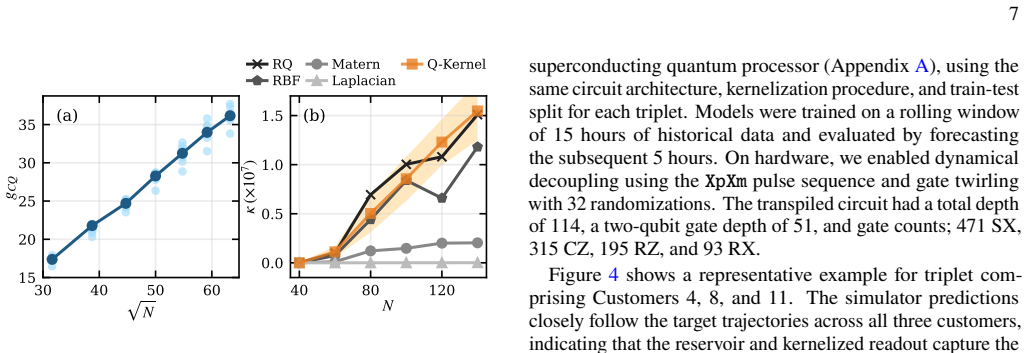
Complexity and Practical Reductions The number of 𝑘-qubit subsets grows as 𝑛𝑞 𝑘 , and for a dataset of 𝑁 samples the full kernel matrix requires O (𝑁2) pairwise evaluations. A native implementation therefore leads to a worst-case complexity of O 𝑁2 · 𝑛𝑞 𝑘 ·4 2𝑘 ,(21) which becomes prohibitive for large𝑘. In practice, the method remains tractable by restri...
2038
-
[8]
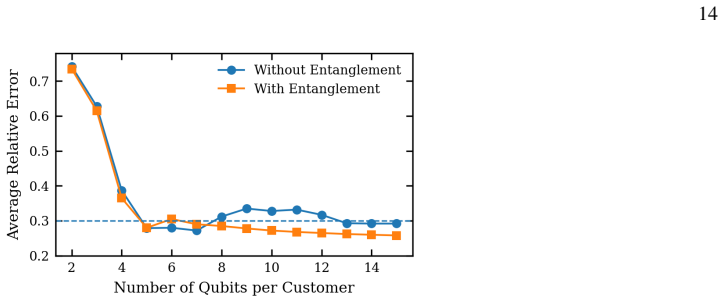
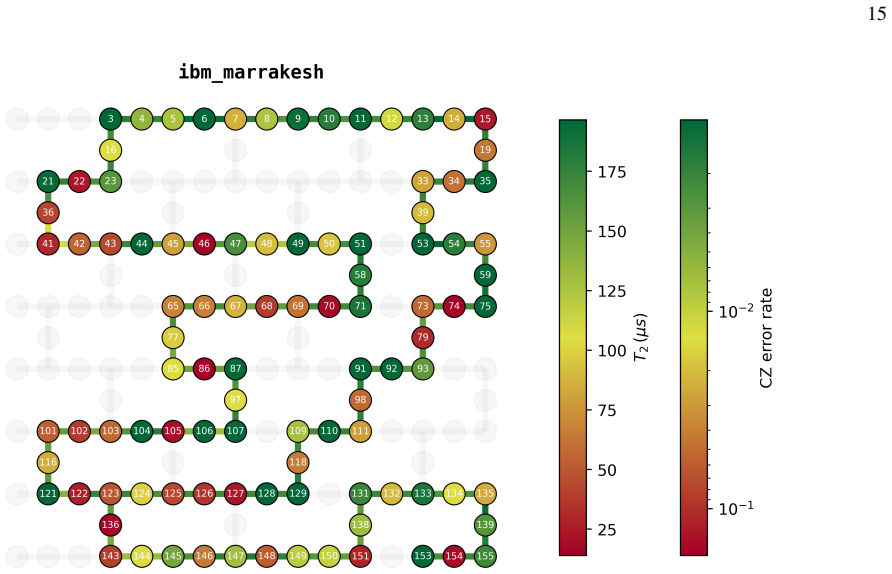
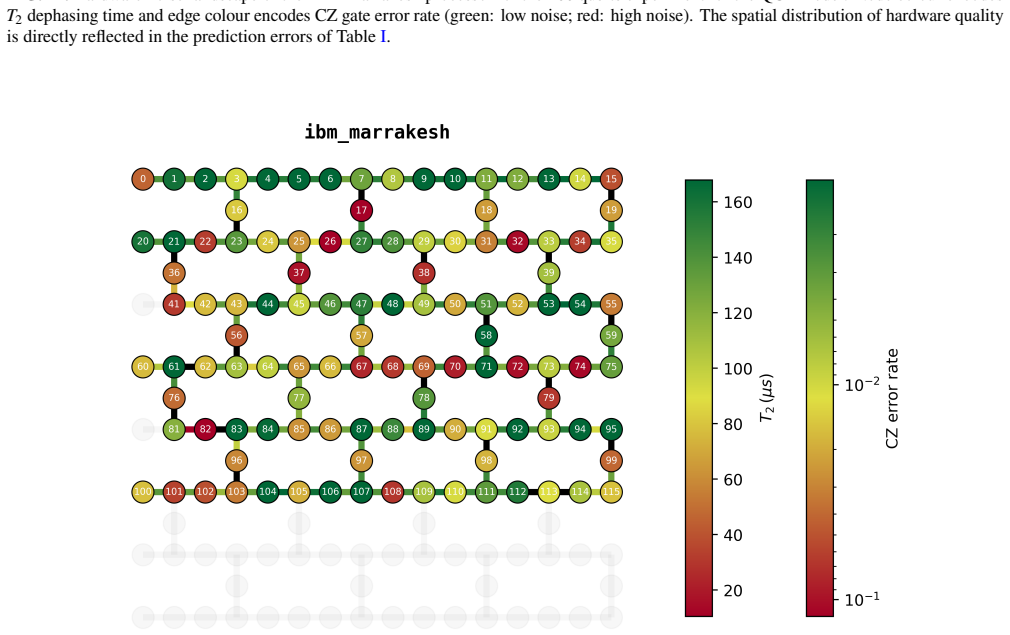
and the bottom strip (physical qubits 121 to 155), where 𝑇2 values fall as low as 14 to 24 𝜇s and CZ error rates reach up to 1.27% account for the majority of the high-error. Taken together, the accuracy-tier distribution is therefore not random: it reflects the heterogeneous noise landscape of the physical device, and the 20% high-error rate is largely a...
-
[9]
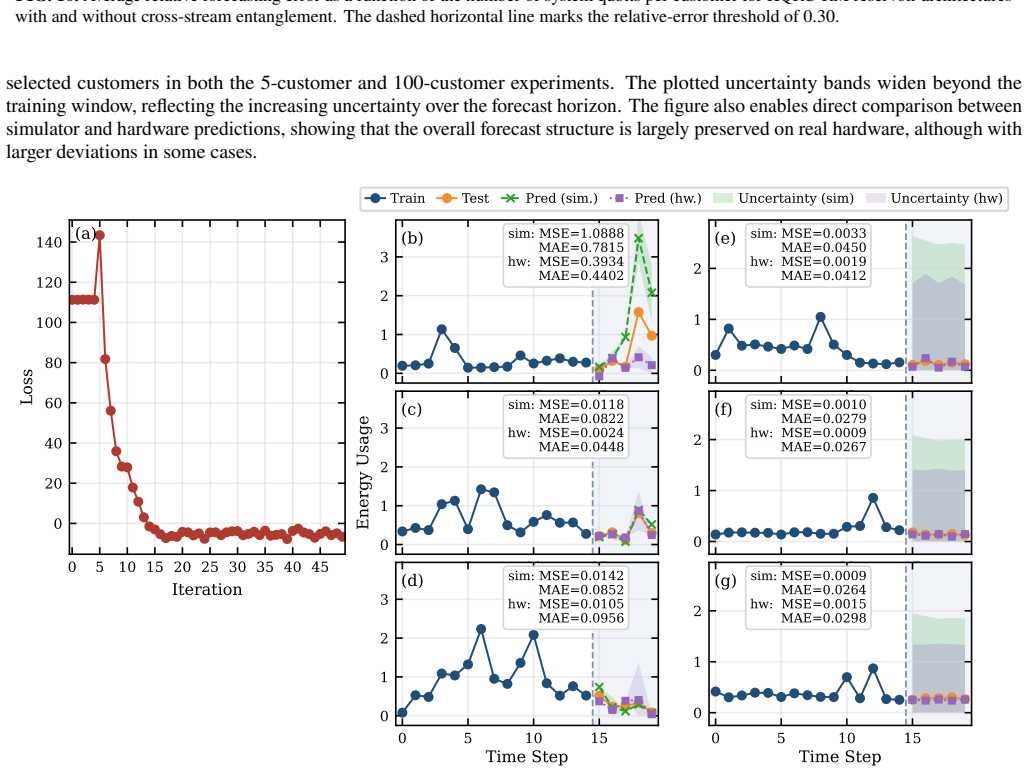
The evaluation is repeated over five realizations corresponding to different train–test windows, and the results shown in Fig
using a rolling-window dataset with 15 hours of training 10 data followed by a 5-hour forecast horizon per customer. The evaluation is repeated over five realizations corresponding to different train–test windows, and the results shown in Fig. 7(a) give the average MAE per customer across these realizations. We additionally include the na¨ıve persistence ...
-
[10]
Weron, International Journal of Forecasting30, 1030 (2014)
R. Weron, International Journal of Forecasting30, 1030 (2014)
2014
-
[11]
G. E. P. Box, G. M. Jenkins, G. C. Reinsel, and G. M. Ljung, Time Series Analysis: Forecasting and Control, 5th ed. (Wiley, 2015)
2015
-
[12]
Hong and S
T. Hong and S. Fan, International Journal of Forecasting32, 914 (2016)
2016
-
[13]
Ahmed and L
O. Ahmed and L. Magri, Physical Review Research6, 043082 (2024). 11
2024
-
[14]
S. L. Ju ´arez-Osorio, M. A. Rivera-Ruiz, A. Mendez-Vazquez, E. Rodriguez-Tello, and J. M. L´opez-Romero, Physica Scripta 100, 106009 (2025)
2025
-
[15]
Fujii and K
K. Fujii and K. Nakajima, Physical Review Applied8, 024030 (2017)
2017
-
[16]
Nakajima, M
K. Nakajima, M. Negoro, K. Fujii, and M. Kitagawa, Physical Review Applied11, 034021 (2019)
2019
-
[17]
Y. Chen, K. Fujii, and K. Nakajima, Frontiers in Physics9(2021)
2021
-
[18]
T. Yasuda, Y. Suzuki, T. Kubota, K. Nakajima, Q. Gao, W. Zhang, S. Shimono, H. I. Nurdin, and N. Yamamoto, Quantum reservoir computing with repeated measurements on superconducting devices (2023), arXiv:2310.06706
-
[19]
Schuld and N
M. Schuld and N. Killoran, Physical Review Letters122, 040504 (2019)
2019
-
[20]
Havl´ıˇcek, A
V. Havl´ıˇcek, A. D. C´orcoles, K. Temme, A. W. Harrow, A. Kan- dala, J. M. Chow, and J. M. Gambetta, Nature567, 209 (2019)
2019
- [21]
-
[23]
Rapp and M
F. Rapp and M. Roth, Quantum Machine Intelligence5, 43 (2023)
2023
-
[24]
D. A. Kreplin, M. Willmann, J. Schnabel, F. Rapp, M. Hagel¨ uken, and M. Roth, IEEE Software42, 10.1109/ms.2025.3527736 (2025)
-
[25]
[Online]
sQUlearn Contributors, squlearn.kernel.ml.QGPR, sQUlearn Documentation. [Online]. Available: https: //squlearn.github.io/modules/generated/squlearn. kernel.ml.QGPR.html, accessed: 27-Feb-2026
2026
-
[26]
Kutvonen, F
A. Kutvonen, F. Matteini, H. Sepp¨anen, T. Ala-Nissila, and K. H. Johansson, Scientific Reports (2020)
2020
- [27]
-
[28]
C. E. Rasmussen and C. K. I. Williams,Gaussian Processes for Machine Learning(MIT Press, 2006)
2006
-
[29]
E. V. Bonilla, K. Chai, and C. Williams, inAdvances in Neural Information Processing Systems, Vol. 20 (Curran Associates, Inc., 2007)
2007
-
[30]
M. A. ´Alvarez, L. Rosasco, and N. D. Lawrence,Kernels for Vector-Valued Functions: A Review, Vol. 4 (Now Publishers Inc., 2012)
2012
-
[31]
Rapp and M
F. Rapp and M. Roth, Quantum Machine Intelligence6, 5 (2024)
2024
- [32]
-
[33]
Farooq, C
A. Farooq, C. A. Galvis-Florez, and S. S¨arkk¨a, Physical Review A109, 052410 (2024)
2024
-
[34]
X. Guo, J. Dai, and R. V. Krems, Machine Learning: Science and Technology5, 035081 (2024)
2024
-
[35]
Agliardi, G
G. Agliardi, G. Cortiana, A. Dekusar, K. Ghosh, N. Mohseni, C. O’Meara, V. Valls, K. Yogaraj, and S. Zhuk, npj Quantum Information (2025)
2025
-
[36]
P ´erez-Salinas, A
A. P ´erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Quantum4, 226 (2020)
2020
-
[37]
Schuld, V
M. Schuld, V. Bergholm, C. Gogolin, J. Izaac, and N. Killoran, Physical Review A99, 032331 (2019)
2019
- [38]
-
[39]
Crawford, B
O. Crawford, B. van Straaten, D. Wang, T. Parks, E. Campbell, and S. Brierley, Quantum5, 385 (2021)
2021
-
[40]
Huang, M
H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Nature communications12, 2631 (2021)
2021
-
[42]
C. K. Williams and C. E. Rasmussen,Gaussian processes for machine learning, Vol. 2 (MIT press Cambridge, MA, 2006)
2006
-
[43]
echo state
H. Jaeger,The “echo state” approach to analysing and training recurrent neural networks, Tech. Rep. GMD Report 148 (German National Research Center for Information Technology, 2001)
2001
-
[44]
Nakajima and I
K. Nakajima and I. Fischer,Reservoir Computing: Theory, Physical Implementations, and Applications(Springer, 2021)
2021
-
[45]
C. Sun, M. Song, D. Cai, B. Zhang, S. Hong, and H. Li, IEEE Transactions on Artificial Intelligence5(2024)
2024
-
[46]
Saunders, A
C. Saunders, A. Gammerman, and V. Vovk, inProceedings of the 15th International Conference on Machine Learning(Morgan Kaufmann Publishers Inc., 1998)
1998
-
[47]
Sch¨olkopf and A
B. Sch¨olkopf and A. J. Smola,Learning with Kernels(MIT Press, 2002)
2002
-
[48]
D. C. McKay, C. J. Wood, S. Sheldon, J. M. Chow, and J. M. Gambetta, Physical Review A96, 022330 (2017). 12 Appendix A: Hardware Platform All quantum hardware experiments reported in this work were executed on ibm marrakesh (Heron r2), a 156-qubit superconducting quantum processor based on transmon qubits. At the time of execution, the device exhibited me...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.