Rubato: Transcribing Piano Music with Timestamps
Pith reviewed 2026-06-30 14:07 UTC · model grok-4.3
The pith
Rubato transcribes piano audio into timestamped sheet music more accurately than cascade methods by using a new polyphonic representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
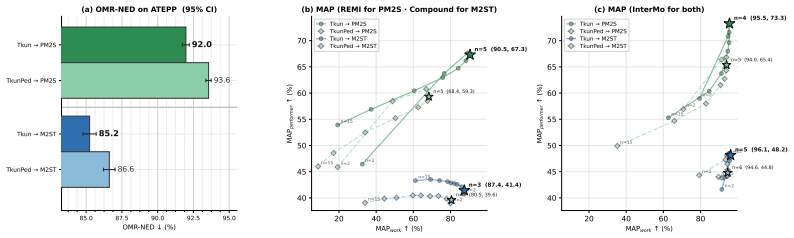
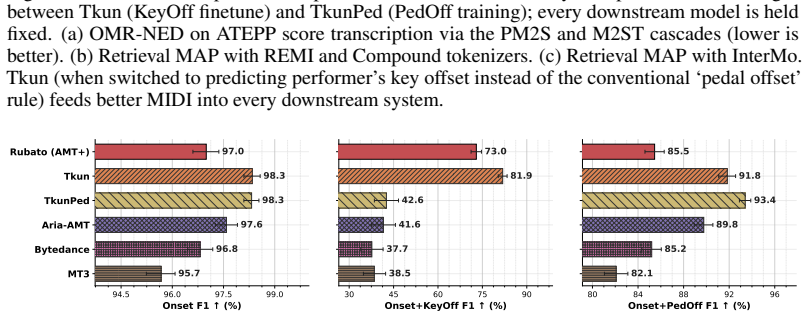
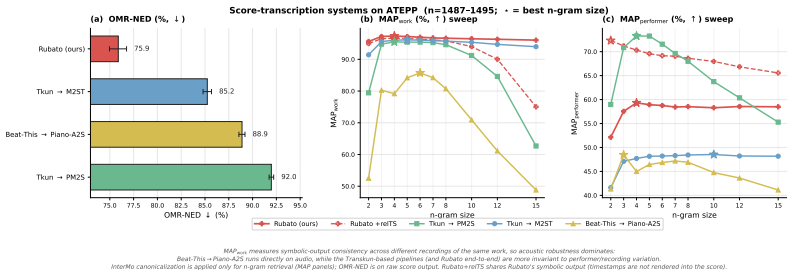
Rubato produces timestamped piano sheet music from audio with higher notational accuracy than the best existing approaches based on cascades. Even when the cascade is given ground-truth MIDI instead of audio, Rubato performs better, suggesting that the ceiling of existing approaches is primarily representational, not acoustic.
What carries the argument
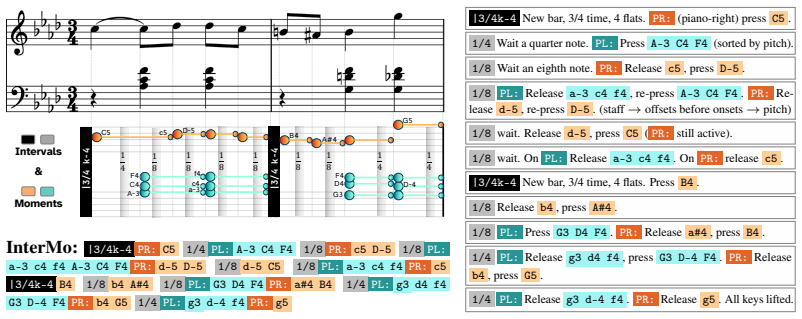
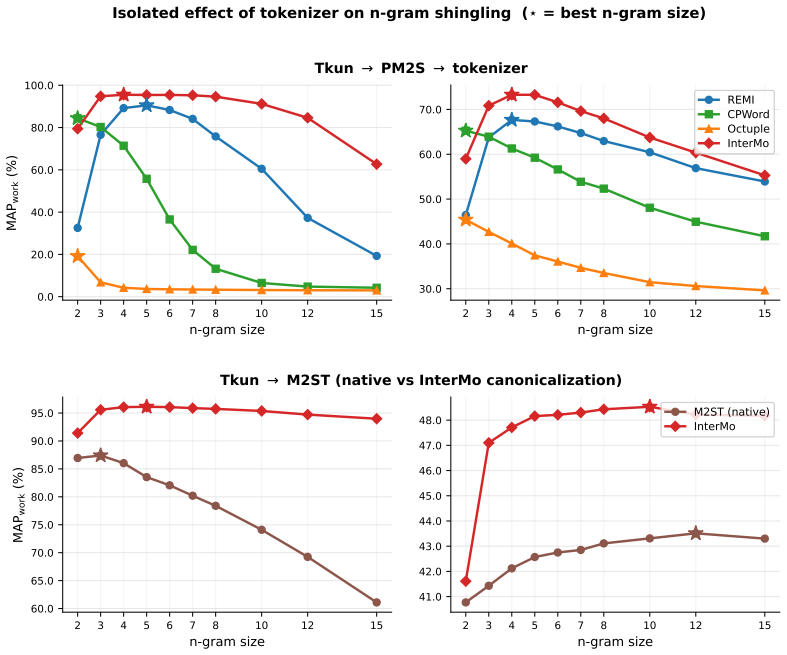
InterMo, a new textual representation for polyphonic music compatible with sequence-to-sequence training, used in a prompt-conditioned encoder-decoder model trained on multiple related tasks.
Load-bearing premise
The InterMo representation enables better performance than cascades by being compatible with sequence-to-sequence training even when input is perfect MIDI.
What would settle it
A new cascade system that achieves equal or higher notational accuracy than Rubato when given ground-truth MIDI would show that the representational limit is not the main factor.
Figures

read the original abstract
We consider the conversion of musical recordings into human-readable sheet music annotated with timestamps. Such output lets a listener clearly visualize rubato (temporally expressive playing), a learner diagnose ensemble precision and timing choices against the written music, and a musicology scholar compare performance styles across recordings of the same work. We introduce (1) a prompt-conditioned encoder-decoder model, named Rubato, trained to output (2) a new textual representation for polyphonic music, named InterMo, which we designed for compatibility with sequence-to-sequence training. Our experiments demonstrate that Rubato produces timestamped piano sheet music from audio with higher notational accuracy than the best existing approaches, which are based on cascades. We find that even if the cascade is given ground-truth MIDI instead of audio, Rubato performs better, suggesting that the ceiling of existing approaches is primarily representational, not acoustic. Further, because Rubato is trained on several related tasks (with prompts), it competes with or outperforms the best single-task systems on related but simpler tasks like MIDI note grounding and beat/downbeat detection. A demo is available at https://nctamer.github.io/rubato-transcription .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Rubato, a prompt-conditioned encoder-decoder model trained to output a new textual representation InterMo for polyphonic piano music. It claims superior notational accuracy for timestamped sheet music from audio compared to cascade methods, and that it outperforms even cascades given ground-truth MIDI input, implying the performance ceiling of existing approaches is representational rather than acoustic. The model also competes on related tasks such as MIDI note grounding and beat/downbeat detection due to multi-task prompt training.
Significance. If the central empirical claims hold after addressing baseline details, the work would provide evidence that sequence-to-sequence models with custom representations can surpass cascaded pipelines in music transcription, with practical value for visualizing rubato and performance analysis. The multi-task prompt conditioning enabling competitive performance on simpler subtasks is a clear strength.
major comments (1)
- [Experiments (GT-MIDI comparison)] GT-MIDI cascade comparison (experiments section): the manuscript must specify the exact MIDI-to-timestamped-sheet pipeline used for the ground-truth MIDI baseline, including whether it is a trained model, off-the-shelf converter, or rule-based system, and whether it is subject to the same output format constraints as InterMo. Without this, the claim that Rubato's advantage demonstrates a representational (rather than acoustic) ceiling cannot be isolated from possible baseline weakness.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the major point on the GT-MIDI cascade comparison below and will revise the manuscript accordingly to improve experimental clarity.
read point-by-point responses
-
Referee: [Experiments (GT-MIDI comparison)] GT-MIDI cascade comparison (experiments section): the manuscript must specify the exact MIDI-to-timestamped-sheet pipeline used for the ground-truth MIDI baseline, including whether it is a trained model, off-the-shelf converter, or rule-based system, and whether it is subject to the same output format constraints as InterMo. Without this, the claim that Rubato's advantage demonstrates a representational (rather than acoustic) ceiling cannot be isolated from possible baseline weakness.
Authors: We agree that additional detail on the GT-MIDI cascade is required. The current manuscript does not fully specify the MIDI-to-timestamped-sheet conversion pipeline used for this baseline. In the revised version we will explicitly describe the pipeline (including its type and output-format constraints) so that the comparison isolates representational differences as intended. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external comparisons
full rationale
The paper introduces Rubato as a prompt-conditioned encoder-decoder trained on the new InterMo representation and validates its claims through direct empirical comparisons to cascade baselines, including a ground-truth MIDI input condition. These evaluations rely on held-out test performance metrics rather than any self-referential fitting where a parameter is tuned on data and then presented as a prediction of a closely related quantity. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to force the central representational claim. The derivation chain consists of standard supervised sequence-to-sequence training followed by independent benchmarking, making the results self-contained against external methods.
Axiom & Free-Parameter Ledger
invented entities (1)
-
InterMo
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Beat this! Accurate beat tracking without DBN postprocessing
Francesco Foscarin, Jan Schlüter, and Gerhard Widmer. Beat this! Accurate beat tracking without DBN postprocessing. InProceedings of the 25th International Society for Music Information Retrieval Conference, 2024.doi:10.48550/arXiv.2407.21658
-
[2]
Scoring time intervals using non-hierarchical transformer for automatic piano transcription
Yujia Yan and Zhiyao Duan. Scoring time intervals using non-hierarchical transformer for automatic piano transcription. InProc. International Society for Music Information Retrieval Conference (ISMIR), 2024.doi:10.5281/zenodo.14877493
-
[3]
Musically aware automatic piano transcription using synthetic pretraining
Louis Bradshaw, Simon Colton, Alexander Spangher, and Stella Biderman. Musically aware automatic piano transcription using synthetic pretraining. Technical report, EleutherAI, 2024
2024
-
[4]
Qiuqiang Kong, Bochen Li, Xuchen Song, Yuan Wan, and Yuxuan Wang. High- resolution piano transcription with pedals by regressing onset and offset times.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3707–3717, 2021. doi:10.1109/TASLP.2021.3121991
-
[5]
Josh Gardner, Ian Simon, Ethan Manilow, Curtis Hawthorne, and Jesse Engel. MT3: Multi- task multitrack music transcription. InInternational Conference on Learning Representations (ICLR), 2022.doi:10.48550/arXiv.2111.03017
-
[6]
Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse H. Engel, and Douglas Eck. Enabling factorized piano music modeling and generation with the MAESTRO dataset. InInternational Conference on Learning Representations (ICLR), 2019.doi:10.48550/arXiv.1810.12247
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.12247 2019
-
[7]
Performance MIDI- to-score conversion by neural beat tracking
Lele Liu, Qiuqiang Kong, Veronica Morfi, and Emmanouil Benetos. Performance MIDI- to-score conversion by neural beat tracking. InProceedings of the 23rd International Society for Music Information Retrieval Conference (ISMIR), Bengaluru, India, 2022. doi:10.5281/zenodo.7316682
-
[8]
End-to-end piano performance-MIDI to score conversion with transformers
Tim Beyer and Angela Dai. End-to-end piano performance-MIDI to score conversion with transformers. InProceedings of the International Society for Music Information Retrieval Conference (ISMIR), pages 319–326, 2024.doi:10.48550/arXiv.2410.00210
-
[9]
Bridging piano transcription and rendering via disentangled score content and style
Wei Zeng, Junchuan Zhao, and Ye Wang. Bridging piano transcription and rendering via disentangled score content and style. InInternational Conference on Learning Representations, 2026
2026
-
[10]
Silvan David Peter, Carlos Eduardo Cancino-Chacón, Francesco Foscarin, Andrew Philip McLeod, Florian Henkel, Emmanouil Karystinaios, and Gerhard Widmer. Automatic note-level score-to-performance alignments in the ASAP dataset.Transactions of the International Society for Music Information Retrieval, 6(1):27–42, 2023.doi:10.5334/tismir.149
-
[11]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023. doi:10.48550/arXiv.2212.04356
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04356 2023
-
[12]
Word level timestamp generation for automatic speech recognition and translation
Ke Hu, Krishna Puvvada, Elena Rastorgueva, Zhehuai Chen, He Huang, Shuoyang Ding, Kunal Dhawan, Hainan Xu, Jagadeesh Balam, and Boris Ginsburg. Word level timestamp generation for automatic speech recognition and translation. InProc. Interspeech 2025, pages 2565–2569, 2025.doi:10.21437/Interspeech.2025-869. 10
-
[13]
Order Matters: Sequence to sequence for sets
Oriol Vinyals, Samy Bengio, and Manjunath Kudlur. Order matters: Sequence to se- quence for sets. InInternational Conference on Learning Representations (ICLR), 2016. doi:10.48550/arXiv.1511.06391
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1511.06391 2016
-
[14]
Symphony generation with permutation invariant language model
Jiafeng Liu, Yuanliang Dong, Zehua Cheng, Xinran Zhang, Xiaobing Li, Feng Yu, and Maosong Sun. Symphony generation with permutation invariant language model. InPro- ceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2022.doi:10.48550/arXiv.2205.05448
-
[15]
Jongmin Jung, Dongmin Kim, Sihun Lee, Seola Cho, Hyungjoon Soh, Irmak Bukey, Chris Donahue, and Dasaem Jeong. U-MusT: A unified framework for cross-modal translation of score images, symbolic music, and performance audio.IEEE Transactions on Audio, Speech and Language Processing, 34:1876–1891, 2026.doi:10.1109/TASLPRO.2025.3648794
-
[16]
LSTM networks can perform dynamic counting
Mirac Suzgun, Yonatan Belinkov, Stuart Shieber, and Sebastian Gehrmann. LSTM networks can perform dynamic counting. In Jason Eisner, Matthias Gallé, Jeffrey Heinz, Ariadna Quattoni, and Guillaume Rabusseau, editors,Proceedings of the Workshop on Deep Learning and Formal Languages: Building Bridges, pages 44–54, Florence, August 2019. Association for Compu...
-
[17]
Counting like transformers: Compiling temporal counting logic into softmax transformers
Andy Yang and David Chiang. Counting like transformers: Compiling temporal counting logic into softmax transformers. InProceedings of the Conference on Language Modeling (COLM), 2024.doi:10.48550/arXiv.2404.04393
-
[18]
Between circuits and Chomsky: Pre-pretraining on formal languages imparts linguistic biases
Michael Y Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen. Between circuits and Chomsky: Pre-pretraining on formal languages imparts linguistic biases. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9691–9709, Vienna, Austria, 2025. doi:10.18653/v1/2025.acl-long.478
-
[19]
Compound word trans- former: Learning to compose full-song music over dynamic directed hypergraphs
Wen-Yi Hsiao, Jen-Yu Liu, Yin-Cheng Yeh, and Yi-Hsuan Yang. Compound word trans- former: Learning to compose full-song music over dynamic directed hypergraphs. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 178–186, 2021. doi:10.1609/aaai.v35i1.16091
-
[20]
Mu- sicBERT: Symbolic music understanding with large-scale pre-training
Mingliang Zeng, Xu Tan, Rui Wang, Zeqian Ju, Tao Qin, and Tie-Yan Liu. Mu- sicBERT: Symbolic music understanding with large-scale pre-training. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 791–800, 2021. doi:10.18653/v1/2021.findings-acl.70
-
[21]
Humdrum and Kern: Selective feature encoding
David Huron. Humdrum and Kern: Selective feature encoding. In Eleanor Selfridge- Field, editor,Beyond MIDI: The Handbook of Musical Codes. MIT Press, 1997. doi:10.5555/275928.275976
-
[22]
The Music Encoding Initiative as a document-encoding framework
Andrew Hankinson, Perry Roland, and Ichiro Fujinaga. The Music Encoding Initiative as a document-encoding framework. InProceedings of the 12th International Society for Music Information Retrieval Conference, 2011.doi:10.5281/zenodo.1417609
-
[23]
Verovio: A library for engraving MEI music notation into SVG
Laurent Pugin, Rodolfo Zitellini, and Perry Roland. Verovio: A library for engraving MEI music notation into SVG. InProceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2014.doi:10.5281/zenodo.1417589
-
[24]
Krishna C. Puvvada, He Huang, Kunal Dhawan, Nithin Palaparthi, Ke Hu, Zhehuai Chen, Jagadeesh Balam, and Boris Ginsburg. Less is more: Accurate speech recognition & translation without web-scale data. InProc. Interspeech 2024, pages 1798–1802, 2024. doi:10.21437/Interspeech.2024-1058
-
[25]
PDMX: A large-scale public domain MusicXML dataset for symbolic music processing
Phillip Long, Zachary Novack, Taylor Berg-Kirkpatrick, and Julian McAuley. PDMX: A large-scale public domain MusicXML dataset for symbolic music processing. InICASSP 2025 – IEEE International Conference on Acoustics, Speech and Signal Processing, pages 1–5. IEEE, 2025.doi:10.1109/ICASSP49660.2025.10890217. 11
-
[26]
ASAP: A dataset of aligned scores and performances for piano transcription
Francesco Foscarin, Andrew McLeod, Philippe Rigaux, Florent Jacquemard, and Masahiko Sakai. ASAP: A dataset of aligned scores and performances for piano transcription. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2020.doi:10.5281/zenodo.4245490
-
[27]
Sageev Oore, Ian Simon, Sander Dieleman, Douglas Eck, and Karen Simonyan. This time with feeling: Learning expressive musical performance.Neural Computing and Applications, 32(4): 955–967, 2020.doi:10.1007/s00521-018-3758-9
-
[28]
Byte pair encoding is suboptimal for language model pretraining
Kaj Bostrom and Greg Durrett. Byte pair encoding is suboptimal for language model pretraining. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4617–4624, 2020.doi:10.18653/v1/2020.findings-emnlp.414
-
[29]
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
Taku Kudo. Subword regularization: Improving neural network translation models with multiple subword candidates.arXiv preprint arXiv:1804.10959, 2018.doi:10.18653/v1/P18-1007
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p18-1007 2018
-
[30]
DawDreamer: Bridging the gap between digital audio workstations and Python interfaces
David Braun et al. DawDreamer: Bridging the gap between digital audio workstations and Python interfaces. InProceedings of the International Society for Music Information Retrieval Conference (Late-Breaking Demo), 2021
2021
-
[31]
VirtuosoNet: A hierarchical RNN-based system for modeling expressive piano performance
Dasaem Jeong, Taegyun Kwon, Yoojin Kim, Kyogu Lee, and Juhan Nam. VirtuosoNet: A hierarchical RNN-based system for modeling expressive piano performance. InISMIR, pages 908–915, 2019.doi:10.5281/zenodo.3527962
-
[32]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611, 2026.doi:10.48550/arXiv.2601.10611
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.10611 2026
-
[33]
ATEPP: A dataset of automatically transcribed expressive piano perfor- mance
Huan Zhang, Jingjing Tang, Syed Rifat Mahmud Rafee, George Fazekas, Simon Dixon, and Geraint A Wiggins. ATEPP: A dataset of automatically transcribed expressive piano perfor- mance. InProceedings of the 23rd International Society for Music Information Retrieval Con- ference (ISMIR), pages 446–453, Bengaluru, India, 2022.doi:10.5281/zenodo.7342764
-
[34]
Juan C Martinez-Sevilla, Joan Cerveto-Serrano, Noelia Luna, Greg Chapman, Craig Sapp, David Rizo, and Jorge Calvo-Zaragoza. Sheet music benchmark: Standardized optical music recogni- tion evaluation.arXiv preprint arXiv:2506.10488, 2025. doi:10.48550/arXiv.2506.10488
-
[35]
End-to-end real-world polyphonic piano audio-to-score tran- scription with hierarchical decoding
Wei Zeng, Xian He, and Ye Wang. End-to-end real-world polyphonic piano audio-to-score tran- scription with hierarchical decoding. InProceedings of the Thirty-Third International Joint Con- ference on Artificial Intelligence, pages 7788–7795, 2024. doi:10.24963/ijcai.2024/862
-
[36]
On the resemblance and containment of documents
Andrei Z Broder. On the resemblance and containment of documents. InPro- ceedings of the Compression and Complexity of Sequences, pages 21–29. IEEE, 1997. doi:10.1109/SEQUEN.1997.666900
-
[37]
The TREC spoken document retrieval track: A success story
John S Garofolo, Cedric GP Auzanne, and Ellen M V oorhees. The TREC spoken document retrieval track: A success story. InRIAO, volume 6, pages 1–20, 2000
2000
-
[38]
Oguz Araz, Dmitry Bogdanov, and Yuki Mitsufuji
Joan Serrà, R. Oguz Araz, Dmitry Bogdanov, and Yuki Mitsufuji. Supervised con- trastive learning from weakly-labeled audio segments for musical version matching. InProceedings of the International Conference on Machine Learning (ICML), 2025. doi:10.48550/arXiv.2502.16936
-
[39]
CoverHunter: Cover song identification with refined attention and alignments
Feng Liu, Deyi Tuo, Yinan Xu, and Xintong Han. CoverHunter: Cover song identification with refined attention and alignments. InIEEE International Conference on Multimedia and Expo (ICME), 2023.doi:10.1109/ICME55011.2023.00189
-
[40]
Distinctive neurophysiological correlates of sound onset and offset perception in humans.The Journal of Physiology, 2025
Fatima Ali, Gabriela Bury, Adèle Simon, and Jennifer F Linden. Distinctive neurophysiological correlates of sound onset and offset perception in humans.The Journal of Physiology, 2025
2025
-
[41]
Example input audio. Produce only ABC notation
Samuel A Mehr. Core systems of music perception.Trends in Cognitive Sciences, 2025. doi:10.1016/j.tics.2025.05.013. 12 A Gemini Evaluation We evaluate Gemini 3.1 Pro to examine how a frontier audio-language model, without task-specific training, approaches piano score transcription when prompted to produce conventional notation formats. A.1 Output Format ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.