Private Adaptive Covariance Estimation via Gaussian Graphical Models
Pith reviewed 2026-06-30 15:18 UTC · model grok-4.3
The pith
PACE-GGM adaptively measures only poorly approximated covariance entries with the Gaussian mechanism and reconstructs the matrix as a Gaussian graphical model to lower private estimation error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an iterative procedure which selects poorly approximated entries, perturbs them with the Gaussian mechanism, and reconstructs the remaining entries via a maximum-entropy objective that induces a Gaussian graphical model structure yields lower estimation error than non-adaptive baselines when separate per-variable bounds are supplied.
What carries the argument
Adaptive selection of poorly approximated entries combined with maximum-entropy reconstruction that produces a Gaussian graphical model.
If this is right
- Estimation error decreases relative to the non-adaptive Gaussian mechanism on diverse real datasets.
- Gains are largest in high-dimensional regimes and low-to-moderate privacy budgets.
- Per-variable bounds allow the privacy budget to be spent more efficiently on informative entries.
- The reconstruction step produces a Gaussian graphical model whose sparsity pattern reflects conditional independencies preserved under privacy.
Where Pith is reading between the lines
- The induced graphical-model structure could supply interpretable conditional-independence information even under privacy constraints.
- The same adaptive-plus-reconstruction pattern might apply to private estimation of other structured matrices such as precision or correlation matrices.
- Theoretical error bounds could be derived by analyzing how quickly the selection process identifies the most informative entries.
- Practitioners facing high-dimensional private data might obtain usable covariance estimates in regimes where full-matrix perturbation fails.
Load-bearing premise
The modeler supplies separate bounds for each variable so that individual entries can be measured with less noise than the full matrix.
What would settle it
On a high-dimensional real-world dataset and low-to-moderate privacy budget, if the adaptive method produces estimation error no lower than the standard Gaussian mechanism applied to the entire matrix, the performance advantage would be refuted.
Figures
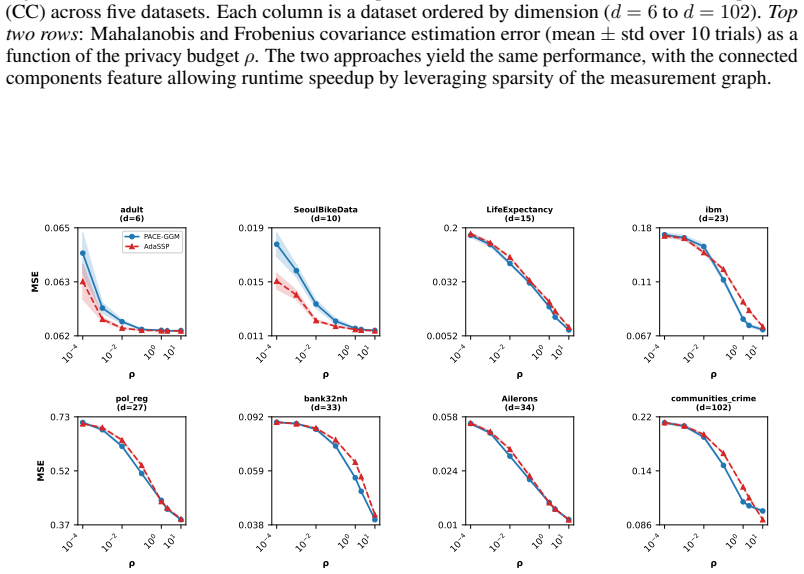
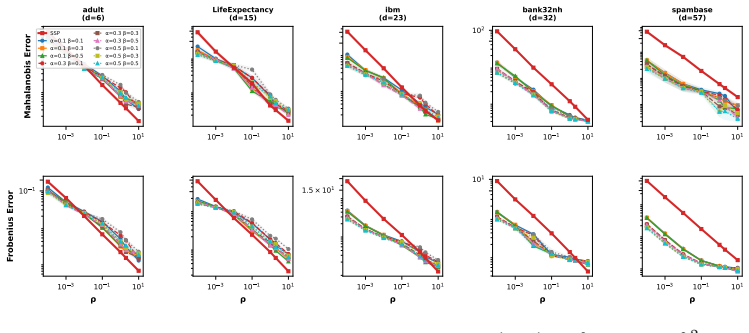
read the original abstract
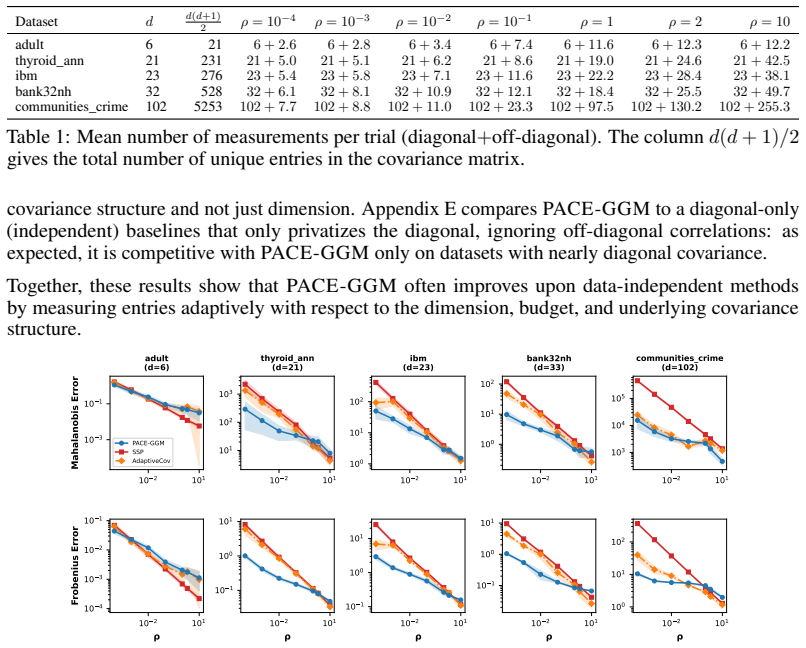
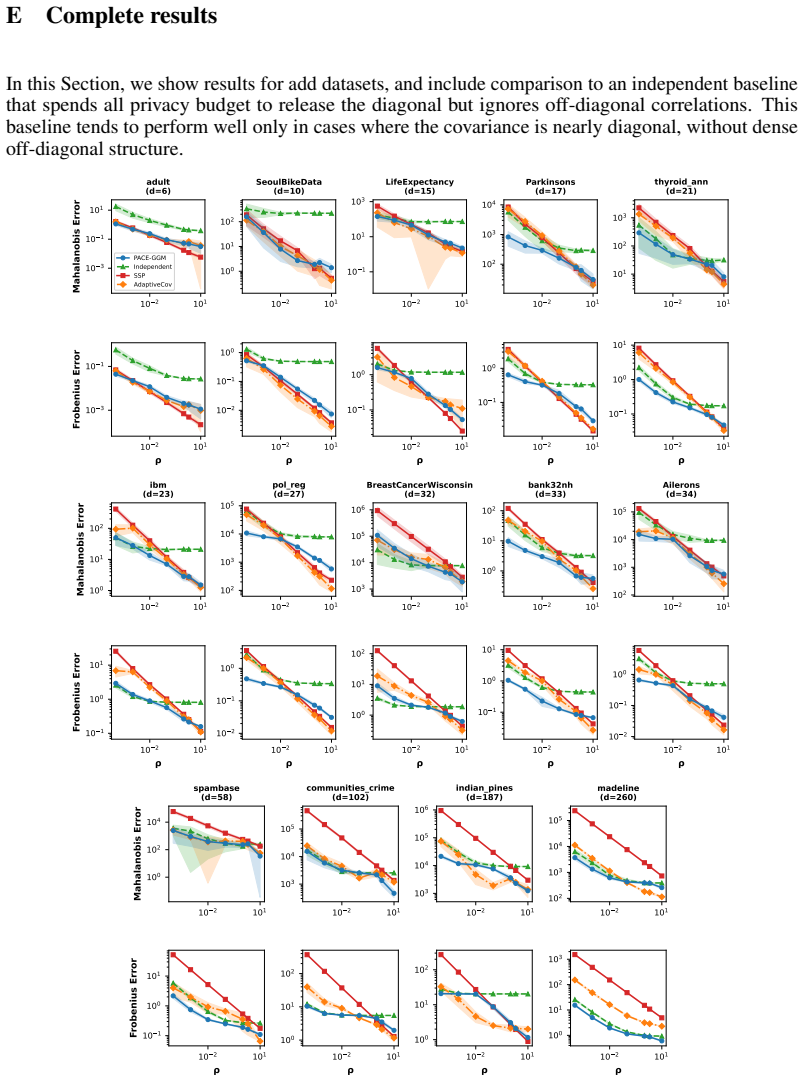
We propose PACE-GGM, a data-adaptive differentially private method for covariance estimation that concentrates its privacy budget on the most informative entries of the empirical covariance matrix, rather than perturbing all entries. This applies in the natural setting where the modeler supplies separate bounds for each variable, so that individual entries can be measured with less noise than the full matrix. In each round, our method selects a poorly approximated entry, measures it using the Gaussian mechanism, and then reconstructs a full covariance matrix using a maximum-entropy reconstruction objective, leading to a Gaussian graphical model structure. Experiments on diverse real-world datasets demonstrate consistent improvements in estimation error with respect to the Gaussian mechanism and other baselines, particularly in high-dimensional and low-to-moderate privacy regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PACE-GGM, a data-adaptive differentially private covariance estimation procedure that iteratively selects poorly approximated entries of the empirical covariance matrix (using per-variable bounds to allow lower noise per entry), applies the Gaussian mechanism to those entries, and reconstructs a full covariance via a maximum-entropy objective that yields a Gaussian graphical model. It claims that this concentrates the privacy budget on informative entries and yields consistent reductions in estimation error versus the non-adaptive Gaussian mechanism and other baselines on real-world datasets, especially in high-dimensional and low-to-moderate privacy regimes.
Significance. If the differential privacy guarantee can be established for the adaptive selection step, the method would offer a practical way to improve utility in private covariance estimation by avoiding uniform noise across all entries when per-variable sensitivity bounds are available. Reproducible experiments with quantitative error metrics, dataset sizes, and ablation details would strengthen the empirical case; the current abstract supplies none of these.
major comments (1)
- [Method description (abstract and §3)] The iterative selection of the 'poorly approximated entry' necessarily depends on the current approximation state, which is a function of prior noisy measurements and the private data. Standard composition theorems require either a non-adaptive sequence or an explicit privacy mechanism (e.g., exponential mechanism or public proxy) for the selection step; the provided description supplies neither, so the claimed end-to-end differential privacy guarantee is not secured.
minor comments (1)
- [Abstract] The abstract asserts 'consistent improvements' and 'diverse real-world datasets' but reports no quantitative error values, error bars, dataset dimensions, privacy budgets, or ablation results; these details are required to evaluate the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key gap in the privacy analysis of the adaptive selection procedure. We address the major comment below.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The iterative selection of the 'poorly approximated entry' necessarily depends on the current approximation state, which is a function of prior noisy measurements and the private data. Standard composition theorems require either a non-adaptive sequence or an explicit privacy mechanism (e.g., exponential mechanism or public proxy) for the selection step; the provided description supplies neither, so the claimed end-to-end differential privacy guarantee is not secured.
Authors: We agree that the manuscript description does not supply an explicit privacy mechanism for the iterative selection step, and that standard composition therefore does not immediately apply. In the revised manuscript we will augment §3 with an exponential mechanism that selects the next entry to measure, using a score function based on the current approximation error (computed from already-released noisy entries and the public per-variable bounds). The privacy parameter of this mechanism will be allocated from the overall budget; the subsequent Gaussian mechanism releases will then be composed with it in the usual way. We will also add a formal theorem stating the end-to-end (ε,δ)-DP guarantee under this construction. This change directly remedies the gap noted by the referee. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The provided abstract and text describe an algorithmic procedure (PACE-GGM) that selects entries, applies the Gaussian mechanism, and performs max-entropy reconstruction to obtain a GGM. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear. The central claim is empirical improvement on real-world datasets, which rests on external evaluation rather than any self-referential reduction. Standard DP primitives are invoked without the paper re-deriving them from its own outputs. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository, 2020
Seoul Bike Sharing Demand. UCI Machine Learning Repository, 2020. DOI: https://doi.org/10.24432/C5F62R
-
[2]
Alabi, A
D. Alabi, A. McMillan, J. Sarathy, and A. Smith. Differentially private simple linear regression. arXiv preprint arXiv:2009.xxxx, 2020. URLhttps://arxiv.org/abs/2009.xxxx
2009
-
[3]
Differentially private query release through adaptive projection
Sergul Aydore, William Brown, Michael Kearns, Krishnaram Kenthapadi, Luca Melis, Aaron Roth, and Ankit Siva. Differentially private query release through adaptive projection. In International Conference on Machine Learning, pages 457–467. PMLR, 2021
2021
-
[4]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[5]
Coinpress: Practical private mean and covariance estimation.Advances in Neural Information Processing Systems, 33: 14475–14485, 2020
Sourav Biswas, Yihe Dong, Gautam Kamath, and Jonathan Ullman. Coinpress: Practical private mean and covariance estimation.Advances in Neural Information Processing Systems, 33: 14475–14485, 2020
2020
-
[6]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge university press, 2004
2004
-
[7]
Concentrated differential privacy: Simplifications, extensions, and lower bounds
Mark Bun and Thomas Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. InTheory of Cryptography Conference, pages 635–658. Springer, 2016
2016
-
[8]
A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Mathematical programming, 95(2):329–357, 2003
Samuel Burer and Renato DC Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Mathematical programming, 95(2):329–357, 2003
2003
-
[9]
Data synthesis via differentially private markov random fields.Proceedings of the VLDB Endowment, 14(11):2190–2202, 2021
Kuntai Cai, Xiaoyu Lei, Jianxin Wei, and Xiaokui Xiao. Data synthesis via differentially private markov random fields.Proceedings of the VLDB Endowment, 14(11):2190–2202, 2021
2021
-
[10]
Wiley-Interscience, New York, 1991
Thomas M Cover and Joy A Thomas.Elements of Information Theory. Wiley-Interscience, New York, 1991
1991
-
[11]
Covariance selection for nonchordal graphs via chordal embedding.Optimization Methods and Software, 23(4):501–520, 2008
Joachim Dahl, Lieven Vandenberghe, and Vwani Roychowdhury. Covariance selection for nonchordal graphs via chordal embedding.Optimization Methods and Software, 23(4):501–520, 2008
2008
-
[12]
Covariance selection.Biometrics, pages 157–175, 1972
Arthur P Dempster. Covariance selection.Biometrics, pages 157–175, 1972
1972
-
[13]
Differentially private covariance revisited.Advances in Neural Information Processing Systems, 35:850–861, 2022
Wei Dong, Yuting Liang, and Ke Yi. Differentially private covariance revisited.Advances in Neural Information Processing Systems, 35:850–861, 2022
2022
-
[14]
Analyze gauss: optimal bounds for privacy-preserving principal component analysis
Cynthia Dwork, Kunal Talwar, Abhradeep Thakurta, and Li Zhang. Analyze gauss: optimal bounds for privacy-preserving principal component analysis. InProceedings of the forty-sixth annual ACM symposium on Theory of computing, pages 11–20, 2014
2014
-
[15]
Fast private adaptive query answering for large data domains.arXiv preprint arXiv:2602.05674, 2026
Miguel Fuentes, Brett Mullins, Yingtai Xiao, Daniel Kifer, Cameron Musco, and Daniel Sheldon. Fast private adaptive query answering for large data domains.arXiv preprint arXiv:2602.05674, 2026. 10
-
[16]
Low-rank optimization on the cone of positive semidefinite matrices.SIAM Journal on Optimization, 20(5):2327–2351, 2010
Michel Journée, Francis Bach, P-A Absil, and Rodolphe Sepulchre. Low-rank optimization on the cone of positive semidefinite matrices.SIAM Journal on Optimization, 20(5):2327–2351, 2010
2010
-
[17]
Privately learning high- dimensional distributions
Gautam Kamath, Jerry Li, Vikrant Singhal, and Jonathan Ullman. Privately learning high- dimensional distributions. InConference on Learning Theory, pages 1853–1902. PMLR, 2019
1902
-
[18]
Clarendon Press, 1996
Steffen L Lauritzen.Graphical models, volume 17. Clarendon Press, 1996
1996
-
[19]
Differentially private linear regression with linked data.Harvard Data Science Review, 6(3), 2024
Shurong Lin, Elliot Paquette, and Eric D Kolaczyk. Differentially private linear regression with linked data.Harvard Data Science Review, 6(3), 2024
2024
-
[20]
Iterative methods for private synthetic data: Unifying framework and new methods.Advances in Neural Information Processing Systems, 34:690–702, 2021
Terrance Liu, Giuseppe Vietri, and Steven Z Wu. Iterative methods for private synthetic data: Unifying framework and new methods.Advances in Neural Information Processing Systems, 34:690–702, 2021
2021
-
[21]
Ryan McKenna, Gerome Miklau, Michael Hay, and Ashwin Machanavajjhala. Hdmm: Opti- mizing error of high-dimensional statistical queries under differential privacy.arXiv preprint arXiv:2106.12118, 2021
-
[22]
Ryan McKenna, Brett Mullins, Daniel Sheldon, and Gerome Miklau. Aim: An adaptive and iterative mechanism for differentially private synthetic data.arXiv preprint arXiv:2201.12677, 2022
-
[23]
Mechanism design via differential privacy
Frank McSherry and Kunal Talwar. Mechanism design via differential privacy. InProceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS ’07), pages 94–103. IEEE, 2007. doi: 10.1109/FOCS.2007.41
-
[24]
Life expectancy (who)
Kumar Rajarshi. Life expectancy (who). https://www.kaggle.com/datasets/ kumarajarshi/life-expectancy-who, 2018. Accessed: 2025-01-16
2018
-
[25]
Michael Redmond. Communities and Crime. UCI Machine Learning Repository, 2002. DOI: https://doi.org/10.24432/C53W3X
-
[26]
Differentially private ordinary least squares
Or Sheffet. Differentially private ordinary least squares. InInternational Conference on Machine Learning, pages 3105–3114. PMLR, 2017
2017
-
[27]
Decomposition methods for sparse matrix nearness problems.SIAM Journal on Matrix Analysis and Applications, 36(4):1691–1717, 2015
Yifan Sun and Lieven Vandenberghe. Decomposition methods for sparse matrix nearness problems.SIAM Journal on Matrix Analysis and Applications, 36(4):1691–1717, 2015
2015
-
[28]
Differentially private high dimensional sparse covariance matrix estimation.Theoretical Computer Science, 865:119–130, 2021
Di Wang and Jinhui Xu. Differentially private high dimensional sparse covariance matrix estimation.Theoretical Computer Science, 865:119–130, 2021
2021
-
[29]
Yu-Xiang Wang. Revisiting differentially private linear regression: optimal and adaptive prediction & estimation in unbounded domain.arXiv preprint arXiv:1803.02596, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Fully-adaptive composition in differential privacy
Justin Whitehouse, Aaditya Ramdas, Ryan Rogers, and Steven Wu. Fully-adaptive composition in differential privacy. InInternational conference on machine learning, pages 36990–37007. PMLR, 2023
2023
-
[31]
William Wolberg, Olvi Mangasarian, Nick Street, and W. Street. Breast Cancer Wisconsin (Diagnostic). UCI Machine Learning Repository, 1993
1993
- [32]
-
[33]
Privsyn: Differentially private data synthesis
Zhikun Zhang, Tianhao Wang, Jean Honorio, Ninghui Li, Michael Backes, Shibo He, Jiming Chen, and Yang Zhang. Privsyn: Differentially private data synthesis. 2021. arXiv preprint, available athttps://arxiv.org/abs/2107.10874. 11 A Sensitivity analysis In this Appendix, we derive the sensitivity bounds for the matrixΣ(X) = 1 n Pn i=1 x(i)x(i)T under ℓ2 and ...
-
[34]
PSD-completable
For diagonal entries j=k, we instead have |v2 j −u 2 j | ≤C 2, sincev 2 j , u2 j ∈[0, C 2]. Therefore, for all entries, ∆Σjk = C2 n . •ℓ ∞-ball assumption.If we assume∥v∥ ∞ ≤Band∥u∥ ∞ ≤B, then |vjvk −u juk| ≤ |v jvk|+|u juk| ≤B 2 +B 2 = 2B2, and the inequalities are tight whenv j =v k =u j =−u k =B, so ∆Σjk = 2B2 n . B Proofs and analysis for the reconstr...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.