Benchmarking Patent Embeddings: A Multi-Task Evaluation of 22 Models Across Retrieval, Classification, and Clustering
Pith reviewed 2026-06-30 14:03 UTC · model grok-4.3
The pith
Optimal fine-tuning for patent embeddings depends on the target task and training landscape
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
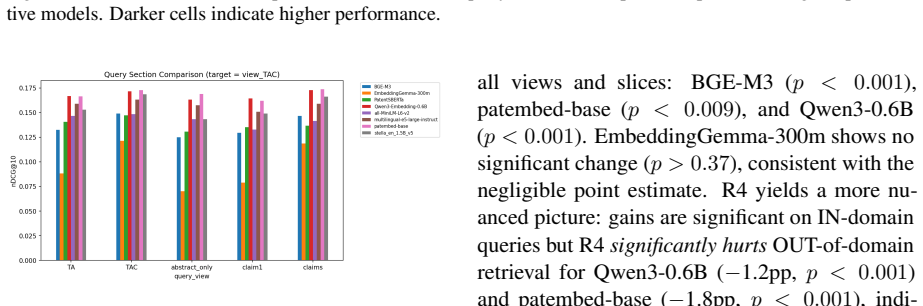
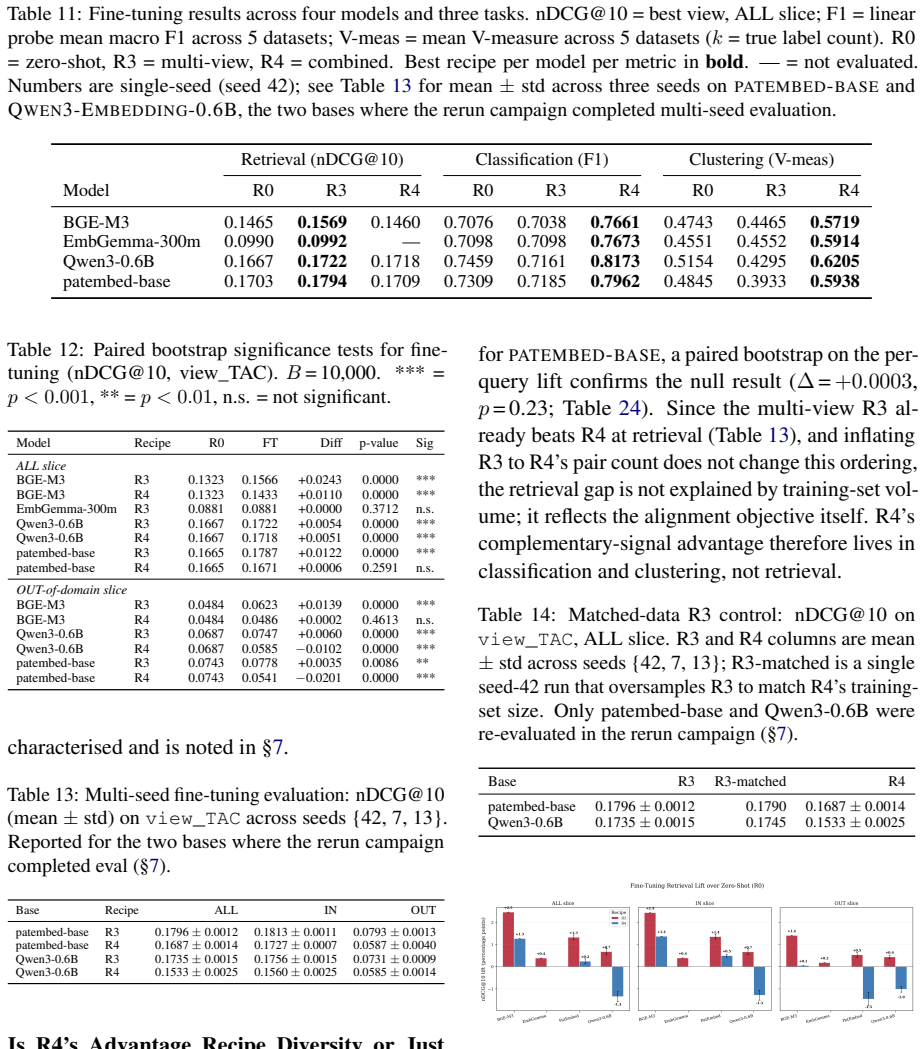
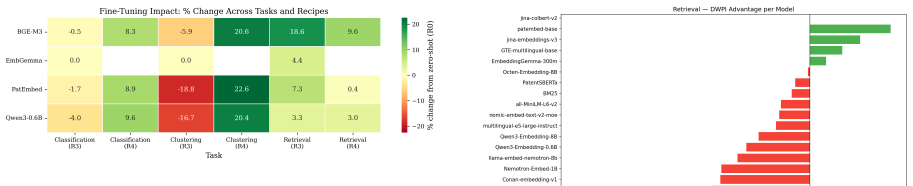
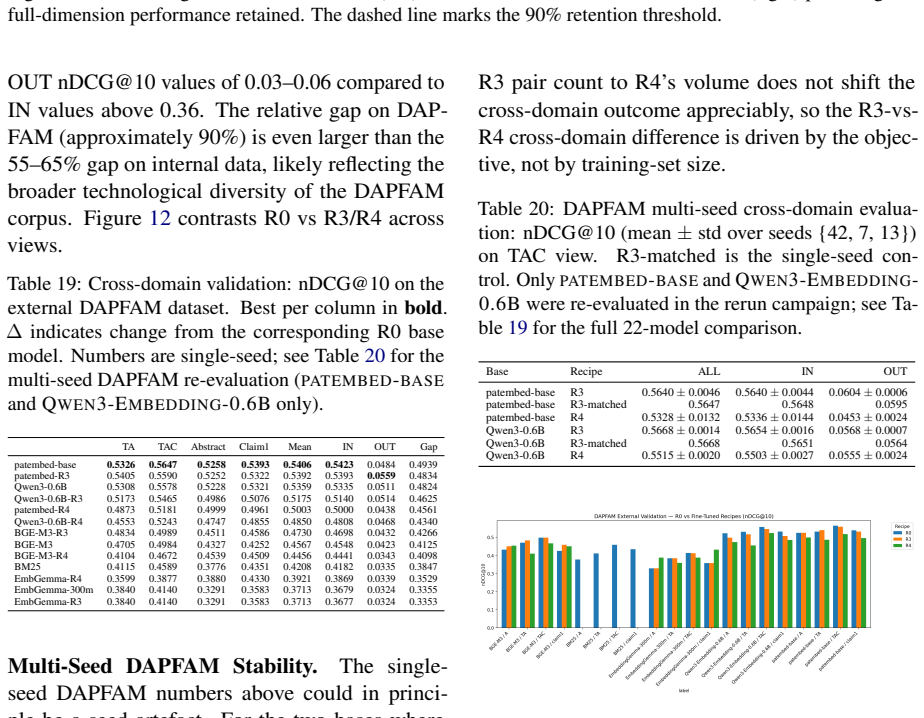
The optimal fine-tuning recipe depends on the downstream task: cross-sectional alignment (recipe R3) provides the largest improvements to retrieval performance (+7.1% nDCG@10), whereas a combined signal recipe (recipe R4) is better suited to classification (+7.1 F1) and clustering (+10.9 V-measure); single-landscape fine-tuning significantly degrades cross-domain retrieval for 5 of 8 model-recipe combinations on the DAPFAM corpus.
What carries the argument
Multi-task benchmark comparing four fine-tuning recipes (including cross-sectional alignment R3 and combined signal R4) across retrieval, classification, and clustering on two patent corpora
If this is right
- Practitioners should select cross-sectional alignment fine-tuning when the goal is information retrieval from patents.
- Practitioners should select combined signal fine-tuning when the goal is classification or clustering of patents.
- Models fine-tuned on one patent landscape cannot be assumed to retain retrieval performance on other landscapes.
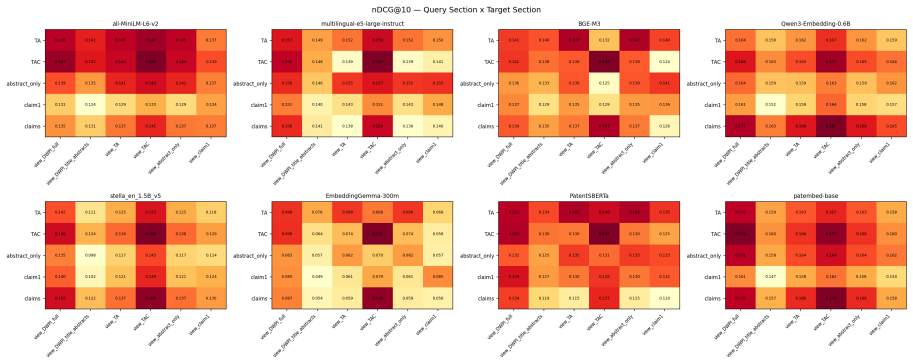
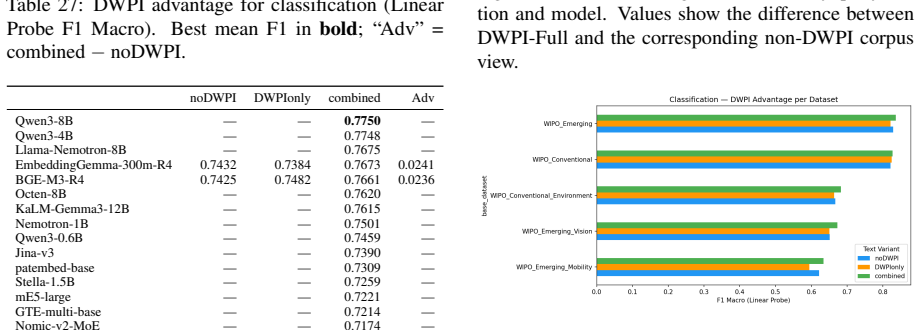
- Title plus abstract plus claims is the preferred text view for patent embedding models.
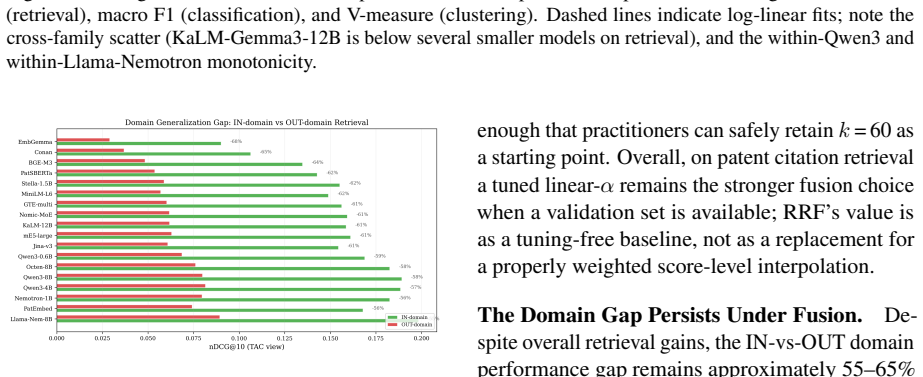
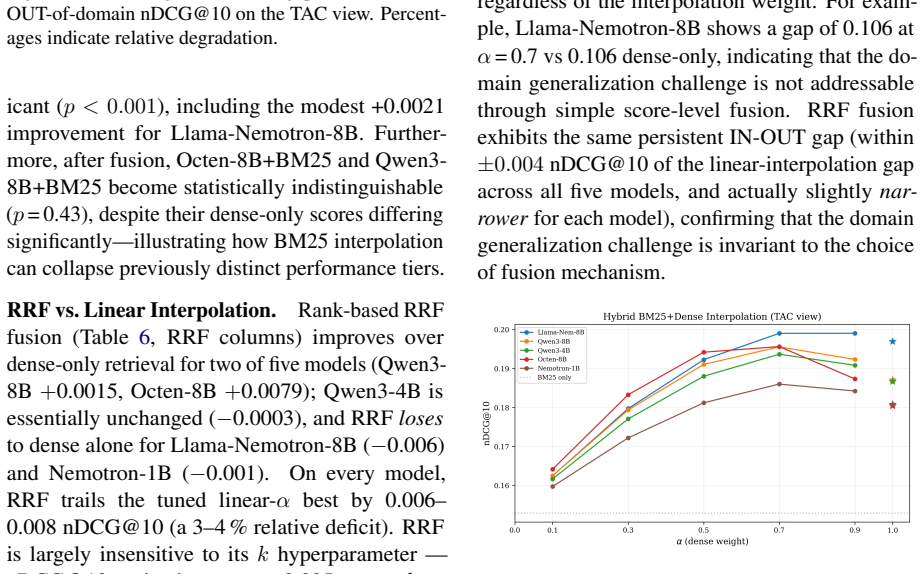
- Hybrid BM25-dense fusion does not close the 55-65% in-domain versus out-of-domain performance gap.
Where Pith is reading between the lines
- Patent search systems may need separate embedding models for retrieval versus classification or clustering uses.
- Training data drawn from multiple patent landscapes could reduce the observed cross-domain degradation.
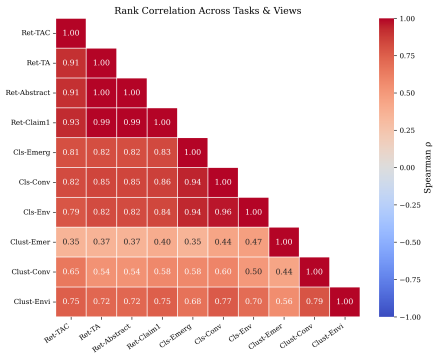
- The consistent within-family scaling but erratic cross-family scaling suggests further tests of parameter scaling on patent data.
Load-bearing premise
The WIPO assistive technology patents and DAPFAM dataset together with the chosen tasks and metrics are representative of patent embedding behavior in general.
What would settle it
Finding that one single fine-tuning recipe ranks first on retrieval, classification, and clustering across multiple independent patent datasets would falsify the claim that the optimal recipe depends on the task.
Figures


read the original abstract
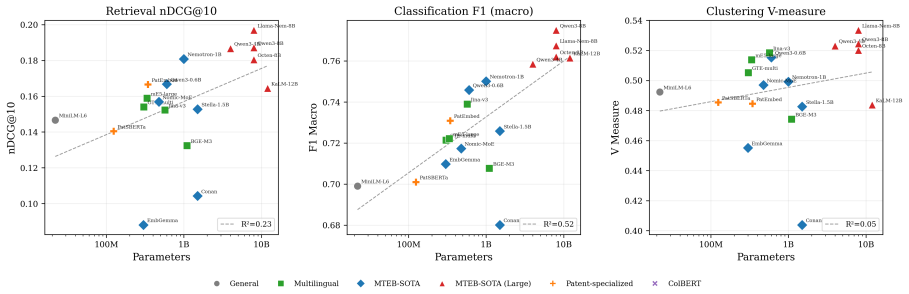
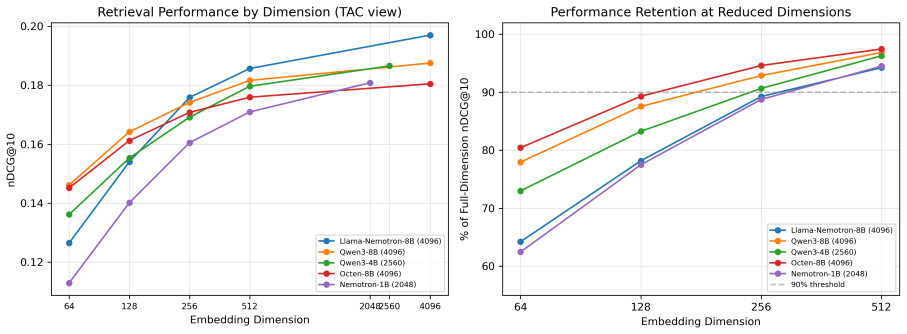
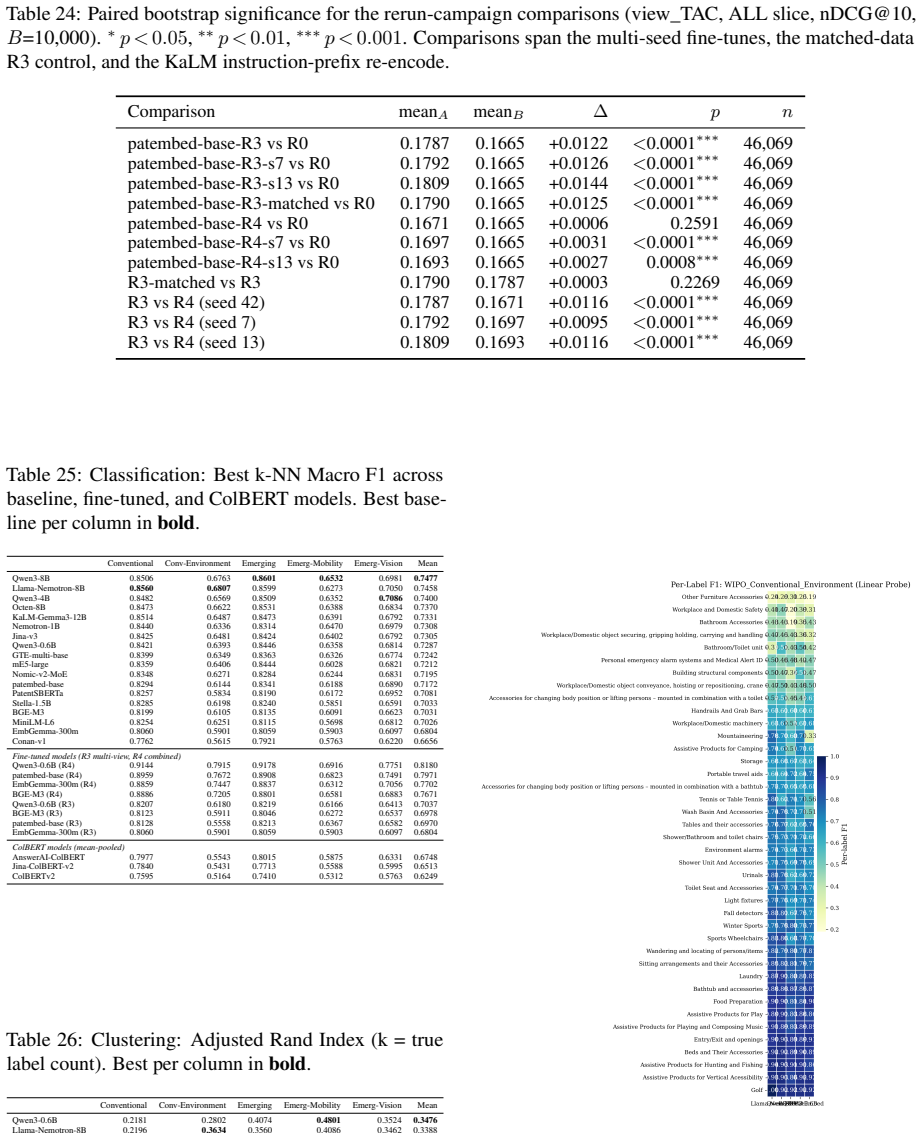
Two questions regarding practitioners' use of patent embeddings arise: (i) Does one fine-tuning recipe suffice for all downstream applications? (ii) Is fine-tuning on one patent landscape sufficient for downstream application on other landscapes? By evaluating 22 pre-trained embedding models (ranging from 22M to 12B parameters) on three tasks -- information retrieval, classification, and clustering -- on 113,148 WIPO patents for assistive technology (46,069 citation queries) and on an external DAPFAM dataset, we find that two results cast doubt on the prevailing wisdom. (i) The optimal fine-tuning recipe depends on the downstream task: cross-sectional alignment (recipe R3) provides the largest improvements to retrieval performance (+7.1% nDCG@10), whereas a combined signal recipe (recipe R4) is better suited to classification (+7.1 F1) and clustering (+10.9 V-measure); a matched data control confirms that differences in training dataset size are not a contributing factor. (ii) Single-landscape fine-tuning hampers cross-landscape information retrieval: fine-tuning on one landscape significantly degrades cross-domain retrieval for 5 of 8 model-recipe combinations on the DAPFAM corpus, with the stronger zero-shot models suffering most. While within-family scaling is consistent (Qwen3 0.6B->4B->8B; Llama-Nemotron 1B->8B), cross-family scaling is erratic; the 12B KaLM-Gemma3 is ranked 8th on TAC retrieval performance, following prefix modification. Title+Abstract+Claims is the ubiquitous best text view, and all models suffer from a 55-65% gap between IN and OUT-of-domain performance which cannot be mitigated by hybrid BM25-dense fusion. Code and evaluation framework are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates 22 pre-trained embedding models (22M to 12B parameters) on retrieval, classification, and clustering using 113,148 WIPO assistive technology patents (46,069 citation queries) and the external DAPFAM dataset. It reports that optimal fine-tuning recipe is task-dependent: cross-sectional alignment (R3) yields largest retrieval gains (+7.1% nDCG@10) while combined-signal recipe (R4) is best for classification (+7.1 F1) and clustering (+10.9 V-measure); a matched-data control rules out size confounds. Single-landscape fine-tuning degrades cross-domain retrieval for 5 of 8 model-recipe pairs on DAPFAM, with stronger zero-shot models affected most. Title+Abstract+Claims is best text view; within-family scaling is consistent but cross-family erratic; a 55-65% in/out-domain gap persists despite BM25-dense fusion. Code and framework are public.
Significance. If the empirical results hold, the work supplies actionable, task-specific guidance for patent embedding fine-tuning and cautions against single-landscape training, challenging prevailing assumptions in patent IR. The matched-data control and public code release are clear strengths that aid reproducibility and verification. The findings could shape practitioner choices and future benchmarking. The narrow technological focus of both corpora, however, constrains how far the task-dependence and cross-landscape degradation claims can be generalized.
major comments (2)
- [Abstract] Abstract: the reported improvements (+7.1% nDCG@10, +7.1 F1, +10.9 V-measure) are presented without statistical significance tests, confidence intervals, or variance estimates across the 46k queries. This information is required to substantiate that recipe optimality truly varies by task rather than reflecting sampling variation.
- [Abstract] Abstract: the claim that single-landscape fine-tuning significantly degrades cross-landscape retrieval (and thus casts doubt on prevailing wisdom) rests on the WIPO assistive-technology corpus and DAPFAM. Both cover narrow domains with potentially atypical citation graphs and IPC distributions; without replication on additional domains (e.g., chemistry or software patents), the general warning is not yet load-bearing for broad conclusions.
minor comments (1)
- The abstract mentions 'prefix modification' for the 12B KaLM-Gemma3 model without defining the modification or quantifying its effect on the reported ranking.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where revisions are needed to strengthen the manuscript, we indicate our plans explicitly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported improvements (+7.1% nDCG@10, +7.1 F1, +10.9 V-measure) are presented without statistical significance tests, confidence intervals, or variance estimates across the 46k queries. This information is required to substantiate that recipe optimality truly varies by task rather than reflecting sampling variation.
Authors: We agree that statistical significance testing is necessary to substantiate the reported gains and the claim of task-dependent optimality. In the revised version we will add bootstrap confidence intervals (1,000 resamples) and paired t-tests (or Wilcoxon signed-rank where normality assumptions fail) for all headline deltas in both the abstract and the results tables. These will be computed over the 46,069 citation queries and reported alongside the point estimates. revision: yes
-
Referee: [Abstract] Abstract: the claim that single-landscape fine-tuning significantly degrades cross-landscape retrieval (and thus casts doubt on prevailing wisdom) rests on the WIPO assistive-technology corpus and DAPFAM. Both cover narrow domains with potentially atypical citation graphs and IPC distributions; without replication on additional domains (e.g., chemistry or software patents), the general warning is not yet load-bearing for broad conclusions.
Authors: We acknowledge the narrow technological scope of the two corpora and agree that broader replication would increase the load-bearing strength of the cross-landscape degradation claim. The current evidence rests on (a) consistent degradation across 5 of 8 model-recipe pairs on the external DAPFAM set and (b) the 55-65 % in/out-domain gap that persists even under hybrid fusion. In revision we will explicitly qualify the generalizability statement in the abstract and discussion, framing the result as a cautionary finding for the assistive-technology and related domains rather than a universal claim. We also note that the matched-data control and the public code release already allow other researchers to test the same recipes on additional patent corpora. revision: partial
Circularity Check
No circularity: empirical benchmarking on external held-out datasets
full rationale
The paper reports direct performance measurements of 22 models on retrieval (nDCG@10), classification (F1), and clustering (V-measure) tasks using the WIPO assistive-technology patent corpus (113,148 patents, 46,069 queries) and the external DAPFAM dataset. Task-dependent recipe optimality and cross-landscape degradation are stated as observed outcomes of these evaluations, with an explicit matched-data control for training-set size. No equations, predictions, or central claims are shown to reduce by construction to fitted parameters, self-definitions, or self-citation chains. The derivation chain consists entirely of standard empirical benchmarking steps against independent external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption nDCG@10, F1, and V-measure are appropriate and sufficient metrics for the retrieval, classification, and clustering tasks on patent data.
Reference graph
Works this paper leans on
-
[1]
PatenTEB: A comprehensive benchmark for patent text embed- dings.arXiv preprint arXiv:2510.22264. Hamid Bekamiri, Daniel S. Hain, and Roman Jurowet- zki
-
[2]
ArXiv:2402.03216. Clarivate Analytics
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Large language models for patent classification: Strengths, trade-offs, and the long tail effect.arXiv preprint arXiv:2601.23200. European Patent Office
-
[4]
Mainak Ghosh and Sebastian Erhardt
Scaling deep con- trastive learning batch size under memory limited setup.arXiv preprint arXiv:2101.06983. Mainak Ghosh and Sebastian Erhardt
- [5]
-
[6]
K., Guzman, S., Mastrapas, G., Sturua, S., Wang, B., et al
Embedding Gemma: Compact embed- ding models.Google Technical Report. Michael Günther, Jackmin Ong, Isabelle Mohr, Alaed- dine Abdessalem, Tanguy Abel, Mohammad Amin Coni, Nils Smoli ´c, and Bo Wang. 2024a. Jina Embeddings 2: 8192-token general-purpose text embeddings for long documents.arXiv preprint arXiv:2310.19923. Michael Günther et al. 2024b. Jina-Co...
-
[7]
arXiv preprint arXiv:2501.01028
KaLM-Embedding: Superior training data brings a stronger embedding model. arXiv preprint arXiv:2501.01028. Lawrence Hubert and Phipps Arabie
-
[8]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281. Also at Findings of the Association for Computational Linguistics: EMNLP
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
MTEB: Massive Text Embedding Benchmark
MTEB: Massive text embedding benchmark.arXiv preprint arXiv:2210.07316. Zach Nussbaum, John Morris, Brandon Duderstadt, and Andriy Mulyar
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Nomic Embed: Train- ing a reproducible long context text embedder.arXiv preprint arXiv:2402.01613. NVIDIA
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia
Statistical significance, power, and sample sizes: A systematic review of SIGIR and TOIS, 2006–2015.Proceedings of SIGIR. Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia
2006
-
[12]
arXiv preprint arXiv:2112.01488 , year=
Col- BERTv2: Effective and efficient retrieval via lightweight late interaction.arXiv preprint arXiv:2112.01488. Alessandro Sarra et al
-
[13]
Homaira Huda Shomee, Zhu Wang, Sathya N
Comparative analysis of embedding models for patent similarity.arXiv preprint arXiv:2403.16630. Homaira Huda Shomee, Zhu Wang, Sathya N. Ravi, and Sourav Medya
-
[14]
Text embeddings by weakly- supervised contrastive pre-training.arXiv preprint arXiv:2212.03533. Qiyao Wang, Guhong Chen, Hongbo Wang, Huaren Liu, Minghui Zhu, Zhifei Qin, Linwei Li, Yilin Yue, Shiqiang Wang, Jiayan Li, Yihang Wu, Ziqiang Liu, Longze Chen, Run Luo, Liyang Fan, Jiaming Li, Lei Zhang, Kan Xu, Chengming Li, Hamid Alinejad- Rokny, Shiwen Ni, Y...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
IPBench: Benchmarking the knowledge of large lan- guage models in intellectual property.arXiv preprint arXiv:2504.15524. Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[16]
A method comprising steps X, Y , and Z
PatentMind: A multi-aspect reasoning graph for patent similarity evaluation.arXiv preprint arXiv:2505.19347. Dun Zhang, Jiacheng Li, Ziyang Zeng, and Fu- long Wang
-
[17]
You Zuo, Kim Gerdes, Eric Villemonte de La Clerg- erie, and Benoît Sagot
Jasper and Stella: Distilla- tion of SOTA embedding models.arXiv preprint arXiv:2412.19048. You Zuo, Kim Gerdes, Eric Villemonte de La Clerg- erie, and Benoît Sagot
-
[18]
Patent Representation Learning via Self-supervision
Patent representa- tion learning via self-supervision.arXiv preprint arXiv:2511.10657. A Additional Retrieval Results Table 21 reports Recall@10 and Table 22 reports MAP across all models and views. Table 23 re- ports nDCG@10 with 95% bootstrap confidence intervals for the TAC view, ALL slice; the† marker on KaLM-Embedding-Gemma3-12B indicates re- evaluat...
work page internal anchor Pith review Pith/arXiv arXiv 2047
-
[19]
Best base- line per column inbold
0.1809 0.1693 +0.0116<0.0001 ∗∗∗ 46,069 Table 25: Classification: Best k-NN Macro F1 across baseline, fine-tuned, and ColBERT models. Best base- line per column inbold. Conventional Conv-Environment Emerging Emerg-Mobility Emerg-Vision Mean Qwen3-8B 0.8506 0.67630.8601 0.65320.69810.7477Llama-Nemotron-8B0.8560 0.68070.8599 0.6273 0.7050 0.7458Qwen3-4B 0.8...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.