Discovering Lexical Gaps Using Embeddings from Multilingual LLMs
Pith reviewed 2026-06-30 13:58 UTC · model grok-4.3
The pith
Embeddings from bilingual LLMs flag lexical gaps through weaker cross-lingual alignment in most tested spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
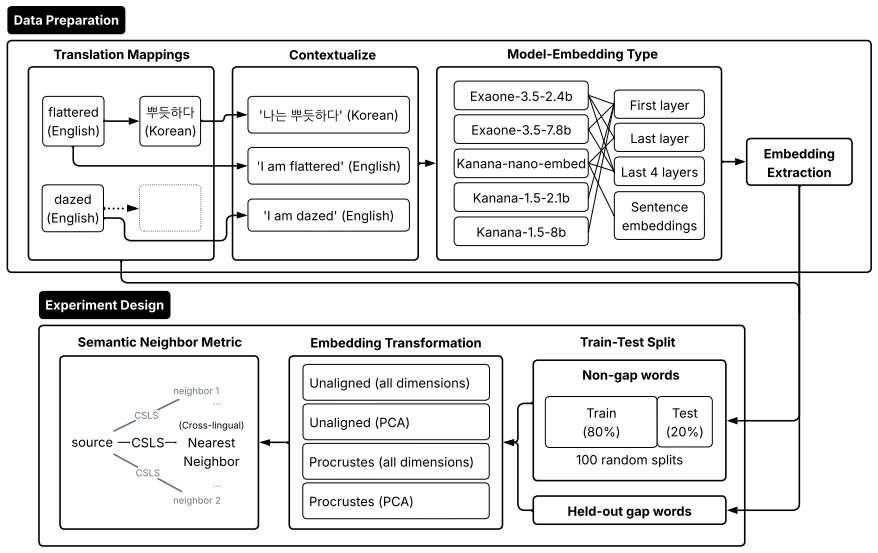
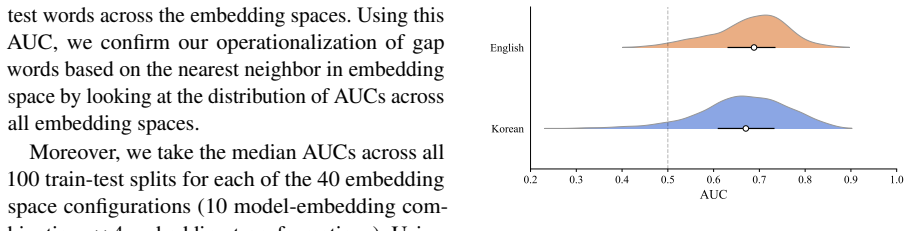
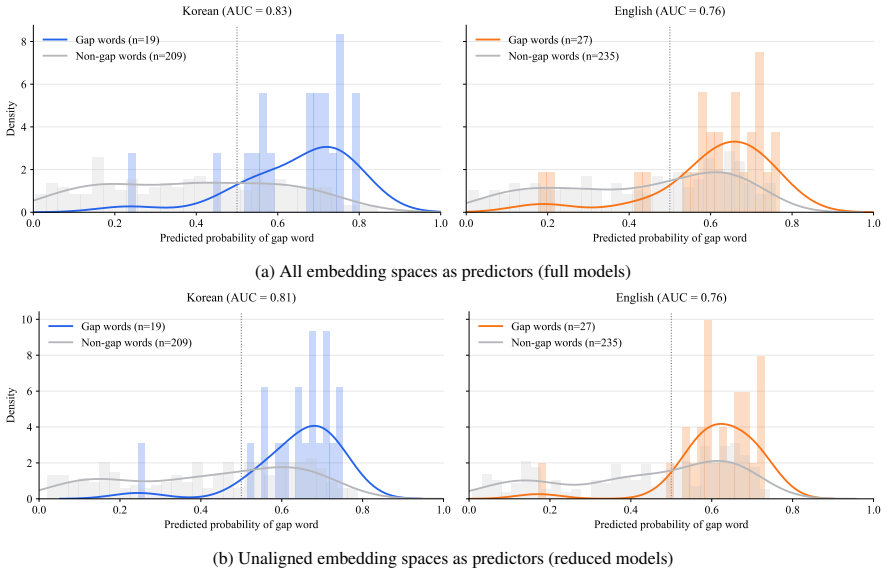
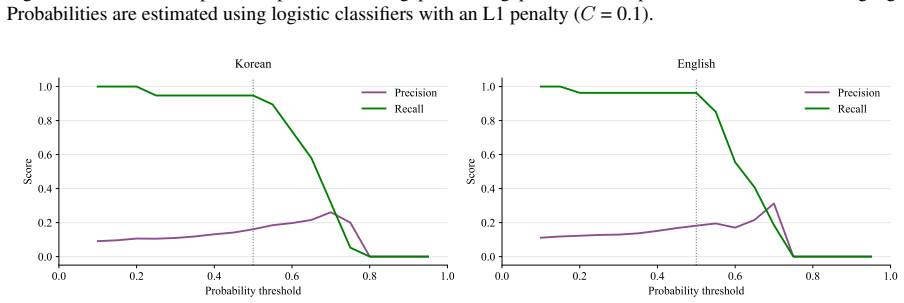
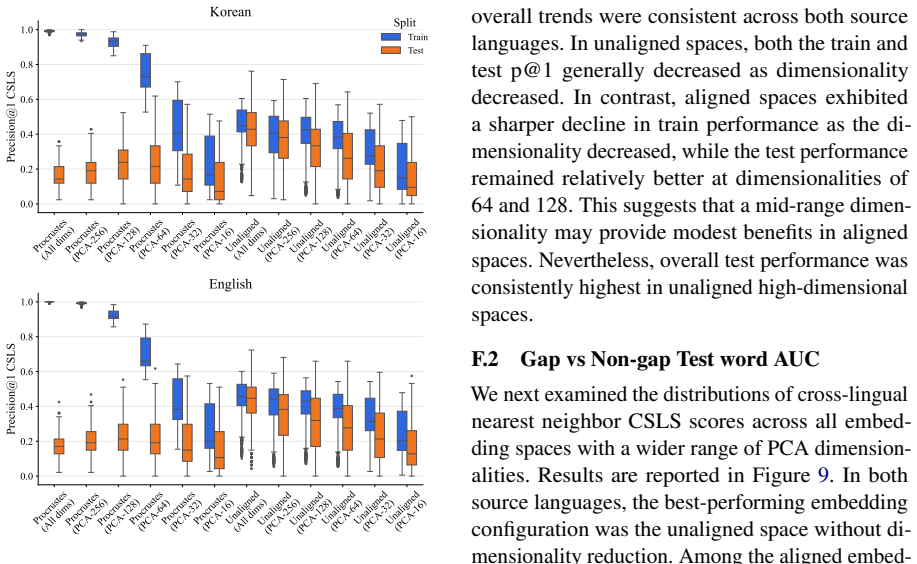
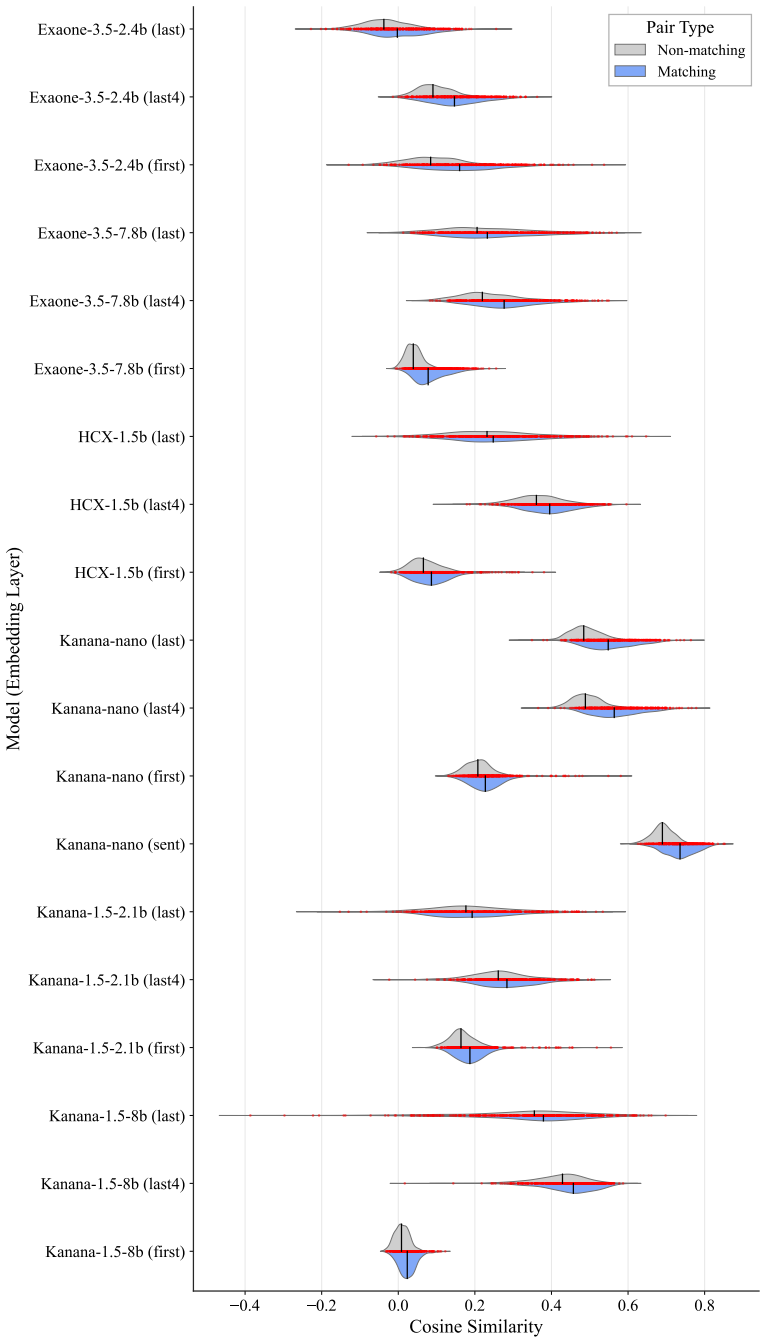
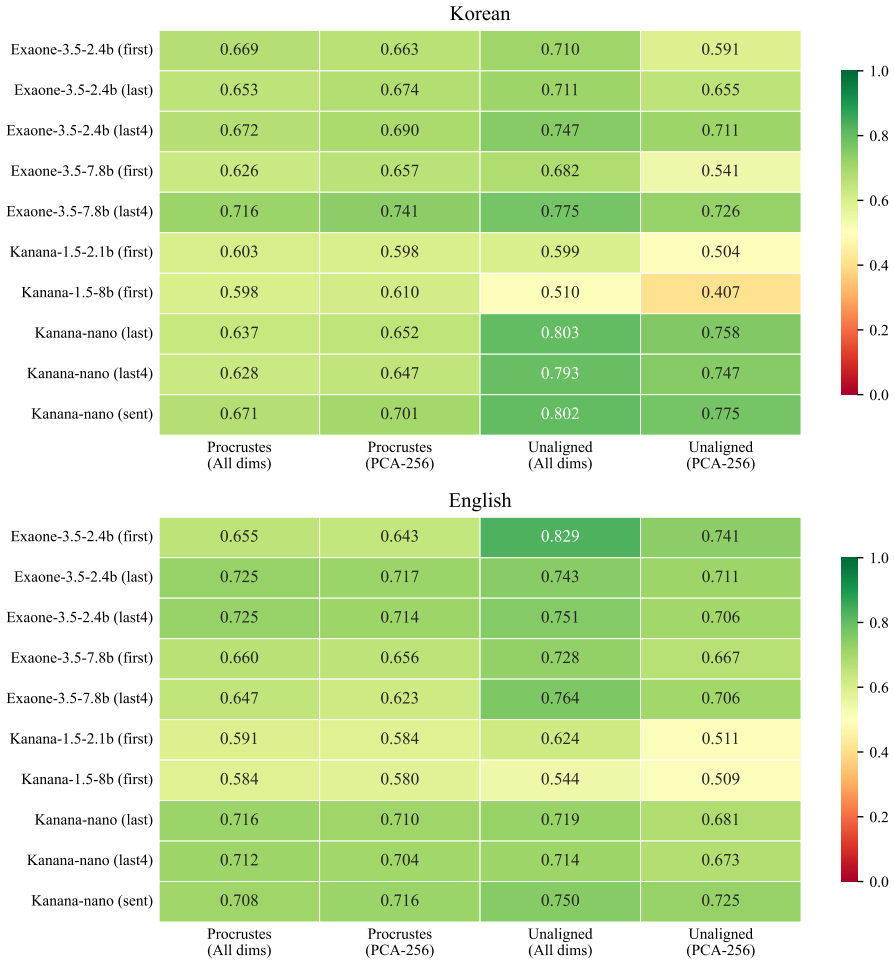
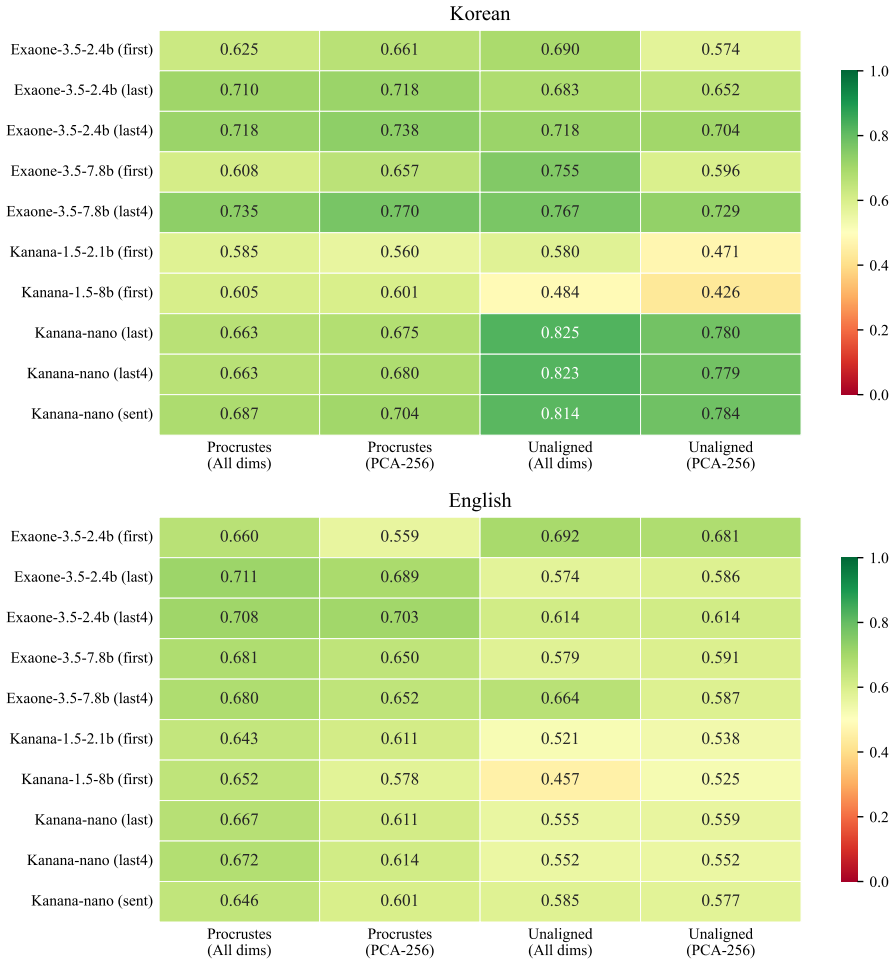
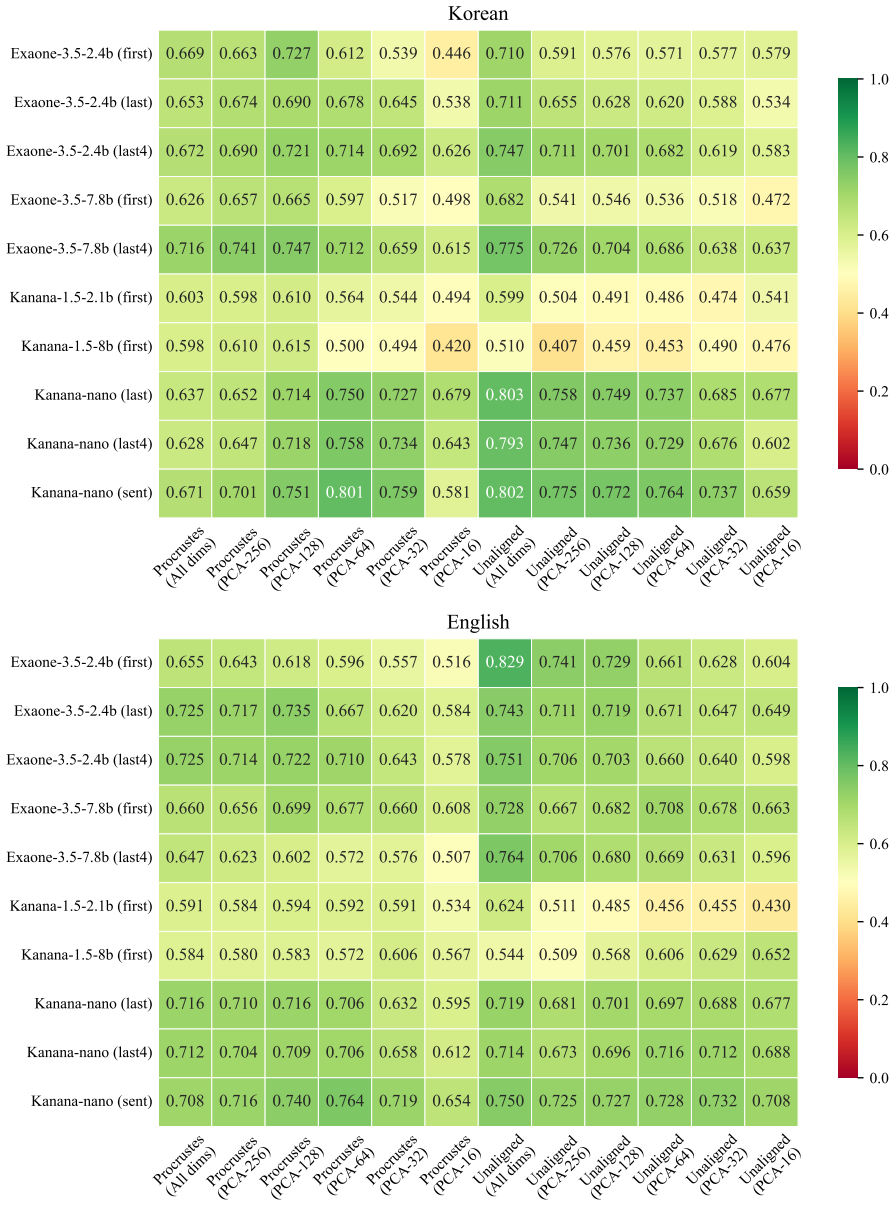
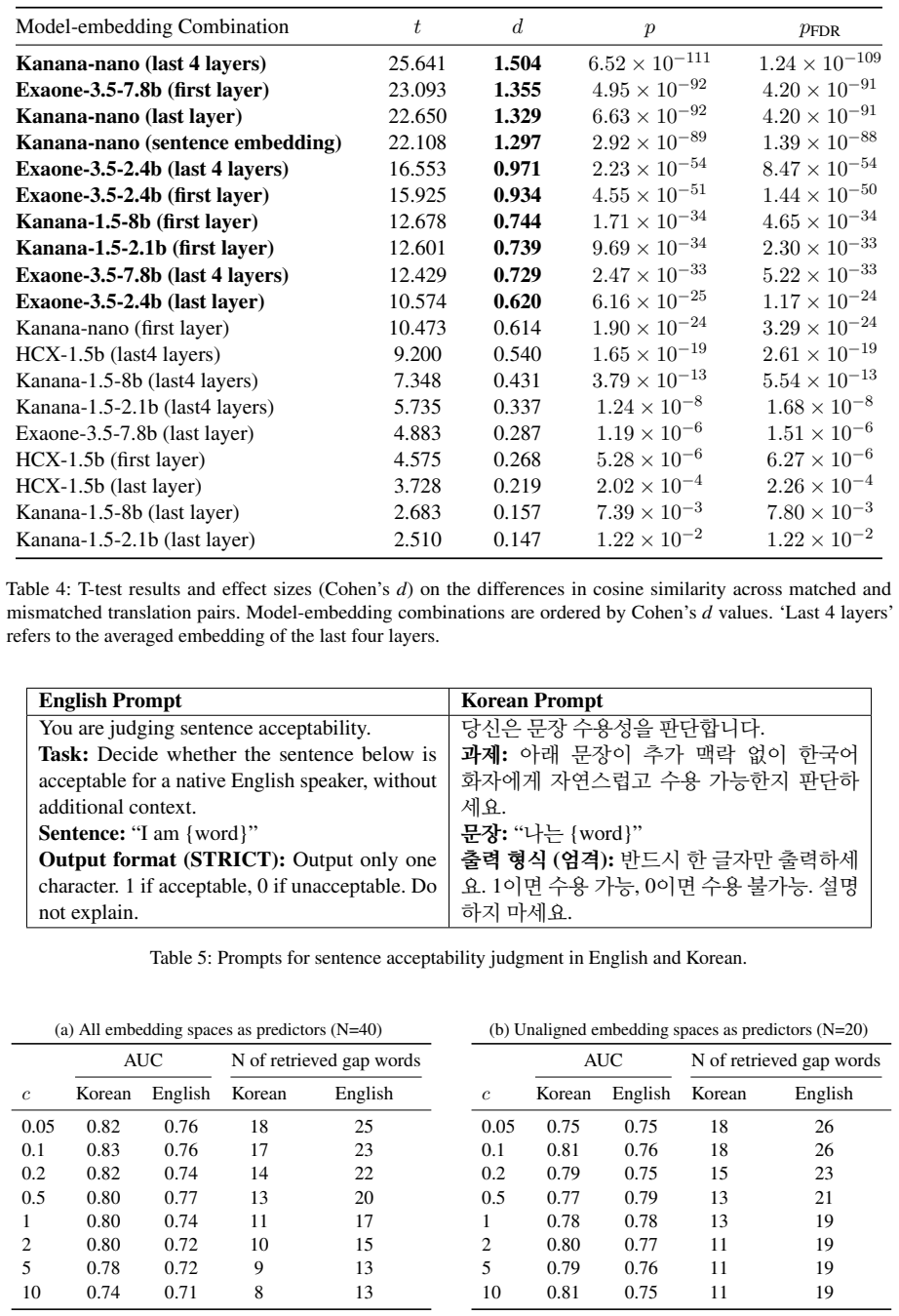
Across 4000 embedding spaces per translation direction, gap words display weaker nearest-neighbor similarity than non-gap words in the great majority of cases. Classifiers built on unaligned spaces achieve AUCs of 0.81 and 0.76 while recovering 18 of 19 Korean gaps and 26 of 27 English gaps.
What carries the argument
Nearest-neighbor semantic similarity in the target-language embedding space, compared between gap words and non-gap words.
If this is right
- Lexical gap detection becomes possible without human judgments or fixed taxonomies.
- Machine translation systems could automatically flag missing vocabulary for specific language pairs.
- Cross-lingual transfer models can be adjusted for systematic lexical differences between languages.
- Multilingual lexical resources can be expanded in a scalable, data-driven manner.
Where Pith is reading between the lines
- The same nearest-neighbor test could be applied to any language pair that has bilingual LLMs available.
- Repeated low-similarity words across domains might point to gaps that vary by context or register.
- Future embedding improvements would likely raise the separation accuracy beyond the reported AUCs.
Load-bearing premise
The nearest neighbor in the target embedding space is a good proxy for a translation equivalent, and lower similarity mainly reflects the absence of a lexical equivalent rather than polysemy or data mismatch.
What would settle it
A collection of confirmed lexical gap words that consistently receive high nearest-neighbor similarity scores across the majority of the 4000 embedding spaces.
Figures
read the original abstract
Lexical gaps are words that do not exist in certain languages. They pose challenges for building multilingual lexical resources, for machine translation, and for cross-lingual transfer. Existing lexical gap detection relies on human judgments or fixed conceptual taxonomies. We propose a data-driven framework for identifying cross-lingual lexical gaps. We extracted contextualized embeddings from Korean-English bilingual LLMs for Korean-to-English and English-to-Korean translation pairs. Combinations of LLMs, embedding types, dimensionality, and orthogonal transformations across 100 train-test splits yielded 4000 distinct embedding spaces in each source language. In each space, we computed the semantic similarity between each source word and its nearest neighbor in the target language, and compared their distribution for gap words versus non-gap words. In 94% (Korean-to-English) and 97% (English-to-Korean) of embedding spaces, gap words showed weaker cross-lingual semantic alignment than non-gap words. Logistic classifiers trained on unaligned embedding spaces can reliably separate gap words from non-gap words, achieving AUCs of 0.81 (Korean-to-English) and 0.76 (English-to-Korean) and retrieving 18/19 Korean and 26/27 English gap words. This approach provides a language-agnostic and taxonomy-free method for scalable lexical gap identification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lexical gaps can be identified in a data-driven, taxonomy-free manner by extracting contextualized embeddings from Korean-English bilingual LLMs, generating 4000 embedding spaces via combinations of models, embedding types, dimensions, and transformations over 100 train-test splits, and showing that gap words exhibit reliably lower nearest-neighbor cosine similarity to the target language than non-gap words in 94% (K→E) and 97% (E→K) of spaces; logistic classifiers on unaligned spaces achieve AUCs of 0.81/0.76 and recover 18/19 and 26/27 gap words.
Significance. If robust after addressing potential confounds, the approach would supply a scalable, language-agnostic alternative to human judgment or fixed taxonomies for detecting lexical gaps, with direct utility for multilingual lexicon construction and cross-lingual transfer; the use of many embedding spaces provides a form of robustness check that is a strength.
major comments (2)
- [Methods/Experimental Setup] Methods/Experimental Setup (description of nearest-neighbor computation and gap/non-gap comparison): the claim that lower NN similarity specifically indicates a lexical gap is not supported by controls for frequency, polysemy, or domain mismatch in LLM pretraining data; these factors are known to depress cosine similarity and are plausibly correlated with the small fixed sets of 19/27 pre-labeled gaps, so the separability (and the 94–97% consistency) could be driven by them rather than the gap property.
- [Results] Results (AUC and retrieval numbers): with only 19 Korean and 27 English gap words and no reported matching or stratification of non-gap words on frequency or sense distribution, the logistic classifier AUCs of 0.81/0.76 and the near-perfect retrieval rates rest on an untested assumption that the NN proxy isolates the lexical-gap signal; a sensitivity analysis or matched control set is needed to establish that the result is not an artifact of the labeling procedure.
minor comments (2)
- [Abstract/Methods] The abstract and methods description should explicitly state how the 19/27 gap words were selected and how the non-gap comparison set was constructed (random sample? frequency-matched?).
- [Results] No error bars, confidence intervals, or statistical significance tests are mentioned for the 94%/97% consistency figures across the 4000 spaces.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on potential confounds and the need for stronger validation of the lexical-gap signal. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods/Experimental Setup] Methods/Experimental Setup (description of nearest-neighbor computation and gap/non-gap comparison): the claim that lower NN similarity specifically indicates a lexical gap is not supported by controls for frequency, polysemy, or domain mismatch in LLM pretraining data; these factors are known to depress cosine similarity and are plausibly correlated with the small fixed sets of 19/27 pre-labeled gaps, so the separability (and the 94–97% consistency) could be driven by them rather than the gap property.
Authors: We agree that frequency, polysemy, and domain mismatch are known to affect cosine similarity and were not explicitly controlled in the original analysis. The consistency across 4000 spaces provides some robustness, but does not substitute for direct controls. In revision we will add a sensitivity analysis that constructs frequency-matched and sense-count-matched non-gap sets (using available corpus statistics) and recompute both the consistency percentages and classifier AUCs on the matched subsets; we will also discuss domain mismatch in the pretraining corpora as a remaining limitation. revision: yes
-
Referee: [Results] Results (AUC and retrieval numbers): with only 19 Korean and 27 English gap words and no reported matching or stratification of non-gap words on frequency or sense distribution, the logistic classifier AUCs of 0.81/0.76 and the near-perfect retrieval rates rest on an untested assumption that the NN proxy isolates the lexical-gap signal; a sensitivity analysis or matched control set is needed to establish that the result is not an artifact of the labeling procedure.
Authors: The small fixed sets of pre-labeled gaps (19/27) and lack of stratification are genuine limitations. The reported AUCs and retrieval rates could partly reflect correlated properties rather than the gap property alone. We will therefore include matched-control and sensitivity analyses in the revised manuscript, reporting performance on frequency- and sense-stratified subsets to test whether the lexical-gap signal remains separable after these controls. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical comparisons of nearest-neighbor cosine similarities and logistic classifier performance across 4000 embedding spaces derived from external bilingual LLMs and independent train-test splits. No equations or definitions reduce the reported AUCs, alignment statistics, or retrieval rates to parameters or quantities defined by the target results themselves. The framework uses off-the-shelf LLM embeddings and standard cross-validation without self-referential fitting or load-bearing self-citations that would collapse the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Word Translation Without Parallel Data
Coping with lexical gaps when building aligned multilingual wordnets. InProceedings of the Second International Conference on Language Resources and Evaluation, Athens, Greece. European Language Resources Association. Francis Bond and Ryan Foster. 2013. Linking and ex- tending an open multilingual Wordnet. InProceed- ings of the 51st Annual Meeting of the...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Taelin Karidi, Eitan Grossman, and Omri Abend
European Language Resources Association. Taelin Karidi, Eitan Grossman, and Omri Abend. 2024. Locally measuring cross-lingual lexical alignment: A domain and word level perspective. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15877–15893, Miami, Florida, USA. As- sociation for Computational Linguistics. Hadi Khalilia, Gá...
2024
-
[3]
untranslatable
Multilingual, not multicultural: Uncovering the cultural empathy gap in LLMs through a compara- tive empathetic dialogue benchmark. InProceedings of the 14th International Joint Conference on Nat- ural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 791–809, Mumbai, India. The ...
2024
-
[4]
Anna Wierzbicka
Cultural influences on word meanings revealed through large-scale semantic alignment.Nature Hu- man Behaviour, 4(10):1029–1038. Anna Wierzbicka. 1992. Defining emotion concepts. Cognitive Science, 16(4):539–581. Anna Wierzbicka. 1997.Understanding Cultures Through Their Key Words: English, Russian, Polish, German, and Japanese. New York: Oxford Univer- si...
1992
-
[5]
HyperCLOVA X technical report.Preprint at https://arxiv.org/abs/2404.01954(2024)
Hyperclova x technical report.arXiv preprint arXiv:2404.01954. Ae-Sun Yoon, Soon-Hee Hwang, Eun-Ryoung Lee, and Hyuk-Chul Kwon. 2009. Construction of korean wordnet.Journal of KIISE: Software and Applica- tions, 36(1):92–108. George Kingsley Zipf. 2016.Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books. A Lim...
-
[6]
First, prepare separate monolingual resources or multilingual resources with comprehensive lexical coverage in each language within the same domain
-
[7]
Second, select the MLLMs and extract differ- ent layers (first, last, the average of the last 4 layers) or sentence embeddings (if avail- able) from each MLLM. If multiple MLLMs are available, and if the translation mappings between words in different languages are available, select the top-performing model- embedding combinations based on how well each e...
-
[8]
If the translation mappings are available, select only 1 target word per source word to ensure clean mappings
Third, obtain the embeddings of each word. If the translation mappings are available, select only 1 target word per source word to ensure clean mappings
-
[9]
Fourth, for each model-embedding combina- tion, go through train-test splits and perform dimensionality reduction (e.g., PCA) using the embeddings from two languages (source and target) in the train set
-
[10]
In each of the resulting embedding spaces (e.g., 100 random seeds for train-test splits × 10 model-embedding combinations × 2 em- bedding transformations), compute the CSLS score between each source word and its near- est neighbor in the target language
-
[11]
Build logistic classifiers (with LOOCV) us- ing each target word’s median CSLS scores across random seeds per each embedding con- figuration as predictors
-
[12]
Using the estimated probability (gappiness threshold), retrieve words with an estimated probability of 0.5 or higher
-
[13]
Only the words with probabilities over 0.5 need to go through the additional manual inspection
Recruit bilingual experts speaking both the source and target languages to identify lexical gaps among the retrieved word sets. Only the words with probabilities over 0.5 need to go through the additional manual inspection. Pol- ysemous or compound words require special targeted inspection. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.