Causal Physics Steering in Video World Models via Concept Activation Vectors
Pith reviewed 2026-06-30 14:10 UTC · model grok-4.3
The pith
Physical expectations in VideoMAE can be shifted at inference by injecting a linear-probe weight vector into hidden states at middle layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
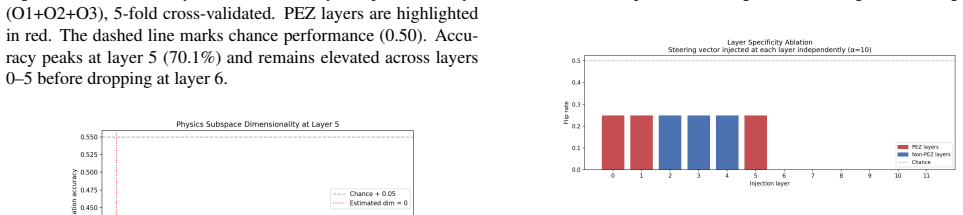
The authors establish that the weight vector of a linear probe at the Physics Emergence Zone functions as a Concept Activation Vector whose injection into hidden states during inference produces a reliable, sign-dependent shift in the model's physical-plausibility judgments on IntPhys; the same intervention produces no measurable effect when applied outside that zone, and different intuitive-physics principles occupy distinct directions within the same representation space.
What carries the argument
The Physics Emergence Zone (PEZ), the group of middle transformer layers in VideoMAE where physical plausibility is represented separately from other visual features; its linear-probe weight vector is used as a Concept Activation Vector that is added to hidden states at inference time.
If this is right
- Physical plausibility judgments shift in either direction according to the sign of the injected vector.
- The effect is confined to the Physics Emergence Zone and absent elsewhere in the network.
- Physics representations remain separate from motion-direction representations under the same intervention.
- Distinct intuitive physics principles occupy distinct directions inside the PEZ representation space.
Where Pith is reading between the lines
- The same injection technique could be applied to other localized concept zones if they exist in the model.
- Multiple CAVs for different physics principles could be combined at inference to create compound physical scenarios.
- The approach might generalize to other video world models that exhibit layer-wise separation of physical features.
Load-bearing premise
The weight vector learned by the linear probe on PEZ activations acts as a faithful causal Concept Activation Vector that selectively changes physics judgments without side effects on other representations.
What would settle it
If CAV injection at the PEZ layers produces no change in IntPhys plausibility scores, or produces the same change when applied to layers outside the PEZ.
Figures

read the original abstract
Video world models learn representations of physical dynamics, but controlling their physical expectations at inference time remains an open problem. Recent interpretability work identified a Physics Emergence Zone (PEZ), a group of middle transformer layers in VideoMAE where physical plausibility is represented separately from other visual features. However, it remained unclear whether this structure could be used to directly control the model's physics reasoning. We present physics steering, a training-free method that uses the weight vector of a linear probe at a PEZ layer as a Concept Activation Vector (CAV) and injects it into hidden states during inference. This shifts the model's physical expectations without changing any model weights. On the IntPhys benchmark, this intervention reliably shifts the model's plausibility judgment in either direction, depending on the steering sign. The effect appears only when the intervention is applied within the Physics Emergence Zone, suggesting that the relevant physics representation is localized there. We further find that physics is encoded separately from motion direction, and that different intuitive physics principles occupy distinct directions within this representation space. Together, these results show that physical reasoning in VideoMAE is not only readable, but also directly steerable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that physical reasoning in VideoMAE is directly steerable at inference time via a training-free method: the weight vector of a linear probe trained on activations in the identified Physics Emergence Zone (PEZ) middle layers is used as a Concept Activation Vector (CAV) and injected into hidden states. This produces sign-dependent shifts in plausibility judgments on the IntPhys benchmark, with the effect localized to PEZ layers; physics representations are reported as orthogonal to motion direction and as occupying distinct directions for different intuitive physics principles.
Significance. If the selectivity of the CAV intervention holds, the result would be significant for interpretability and control in video world models, demonstrating that localized representations of physical dynamics can be read and causally manipulated without weight updates or retraining. The training-free nature of the method, its empirical test on an external benchmark (IntPhys), and the reported separation of physics from motion are concrete strengths that would support broader use in controllable world models.
major comments (2)
- [Abstract] Abstract and results on IntPhys: the central claim that the linear-probe weight vector functions as a 'faithful and causal' CAV whose injection 'selectively alters physics judgments without unintended side effects' is load-bearing, yet the reported evidence (directional shifts, PEZ localization, orthogonality to motion) does not include quantitative controls showing invariance of other representation axes such as object identity, texture statistics, or reconstruction fidelity under the same intervention.
- [Abstract] Abstract: while the effect is stated to appear 'only when the intervention is applied within the Physics Emergence Zone,' no ablation or comparison is described that quantifies whether the same-magnitude injection outside PEZ produces comparable or null effects on non-physics outputs, which is required to establish that the observed judgment change is concept-specific rather than a generic hidden-state perturbation.
minor comments (2)
- [Abstract] The acronym PEZ is introduced without an inline definition in the abstract; a brief parenthetical expansion on first use would improve readability.
- [Abstract] The abstract refers to 'different intuitive physics principles' occupying 'distinct directions' but does not name the specific principles or report the quantitative measure (e.g., cosine similarity or classification accuracy) used to establish distinctness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to demonstrate selectivity of the CAV intervention. We address the two major comments point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and results on IntPhys: the central claim that the linear-probe weight vector functions as a 'faithful and causal' CAV whose injection 'selectively alters physics judgments without unintended side effects' is load-bearing, yet the reported evidence (directional shifts, PEZ localization, orthogonality to motion) does not include quantitative controls showing invariance of other representation axes such as object identity, texture statistics, or reconstruction fidelity under the same intervention.
Authors: We agree that explicit invariance tests on additional axes would strengthen the selectivity claim. The manuscript already reports orthogonality to motion direction and distinct directions for different physics principles. In revision we will add quantitative controls: we will measure the effect of the same-magnitude intervention on linear probes for object identity and texture statistics, as well as on reconstruction fidelity, to document that these axes remain largely invariant. revision: yes
-
Referee: [Abstract] Abstract: while the effect is stated to appear 'only when the intervention is applied within the Physics Emergence Zone,' no ablation or comparison is described that quantifies whether the same-magnitude injection outside PEZ produces comparable or null effects on non-physics outputs, which is required to establish that the observed judgment change is concept-specific rather than a generic hidden-state perturbation.
Authors: We will revise to include the requested ablation. We will apply the identical-magnitude CAV injection at matched non-PEZ layers and report its effect (or lack thereof) on non-physics outputs such as object classification accuracy and motion direction probes, thereby quantifying that the physics-specific shift is localized rather than a generic perturbation. revision: yes
Circularity Check
No circularity; result is an empirical intervention on an external benchmark
full rationale
The paper's central result is obtained by training a linear probe on PEZ-layer activations, extracting its weight vector as a CAV, injecting the vector (with sign flip) into hidden states at inference time, and measuring directional shifts on the held-out IntPhys benchmark. No equation or derivation reduces the reported steering effect to a fitted parameter by construction; the intervention is tested for localization to PEZ, orthogonality to motion, and separation of physics principles, all via external evaluation. Prior identification of PEZ is treated as background and does not enter the steering procedure as a self-referential constraint. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on transformer activations can identify directions corresponding to high-level concepts such as physical plausibility
invented entities (1)
-
Physics Emergence Zone (PEZ)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structPix2Pix: Learning to follow image editing instructions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[3]
Video generation models as world simula- tors
Tim Brooks et al. Video generation models as world simula- tors. Technical report, OpenAI, 2024. 2
2024
-
[4]
Embodied intelligence via learning and evolution
Agrim Gupta, Silvio Savarese, Surya Ganguli, and Li Fei- Fei. Embodied intelligence via learning and evolution. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[5]
Mastering Atari with discrete world models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering Atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021. 1, 2
2021
-
[6]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Peter Corke. GAIA-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Interpreting physics in video world models.Blog post, 2024
Sonia Joseph, Jack Lindsey, and Jack Lindsey. Interpreting physics in video world models.Blog post, 2024. 1, 2, 3, 6
2024
-
[8]
The Kinetics Human Action Video Dataset
Will Kay et al. The Kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Inter- pretability beyond classification with TCA V
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Inter- pretability beyond classification with TCA V. InInterna- tional Conference on Machine Learning (ICML), 2018. 1, 2
2018
-
[10]
Inference-time intervention: Elicit- ing truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Vi ´egas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Elicit- ing truthful answers from a language model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2
2023
-
[11]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Jack Lindsey and David Bau. Sparse feature circuits: Dis- covering and editing interpretable causal graphs in language models.arXiv preprint arXiv:2403.19647, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Trans- formers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and Franc ¸ois Fleuret. Trans- formers are sample-efficient world models. InInternational Conference on Learning Representations (ICLR), 2023. 1
2023
-
[13]
DINOv2: Learning robust visual fea- tures without supervision.Transactions on Machine Learn- ing Research (TMLR), 2024
Maxime Oquab et al. DINOv2: Learning robust visual fea- tures without supervision.Transactions on Machine Learn- ing Research (TMLR), 2024. 6
2024
-
[14]
Piloto, Ari Weinstein, Peter Battaglia, and Matthew Botvinick
Luis S. Piloto, Ari Weinstein, Peter Battaglia, and Matthew Botvinick. Intuitive physics learning in a deep-learning model inspired by developmental psychology.Nature Hu- man Behaviour, 2022. 2
2022
-
[15]
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, V ´eronique Izard, and Emmanuel Dupoux. IntPhys: A framework and benchmark for visual intuition physics.arXiv preprint arXiv:1803.07616, 2019. 2, 3
-
[16]
BERT redis- covers the classical NLP pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT redis- covers the classical NLP pipeline. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2019. 2
2019
-
[17]
VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 1, 4
2022
-
[18]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 2
2017
-
[19]
MotionCtrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Liu, Chun-Wei Zheng, and Enze Xie. MotionCtrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024, 2024. 2
2024
-
[20]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. VideoGPT: Video generation using VQ-V AE and transformers.arXiv preprint arXiv:2104.10157, 2021. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Learning Interactive Real-World Simulators
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Bernhard Sch ¨olkopf, and Pieter Abbeel. Learn- ing interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 1, 2
2023
-
[23]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.