Side-by-side Comparison Amplifies Dialect Bias in Language Models
Pith reviewed 2026-06-30 13:38 UTC · model grok-4.3
The pith
Language models associate more negative stereotypes with AAVE when SAE and AAVE tweets are compared side by side.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
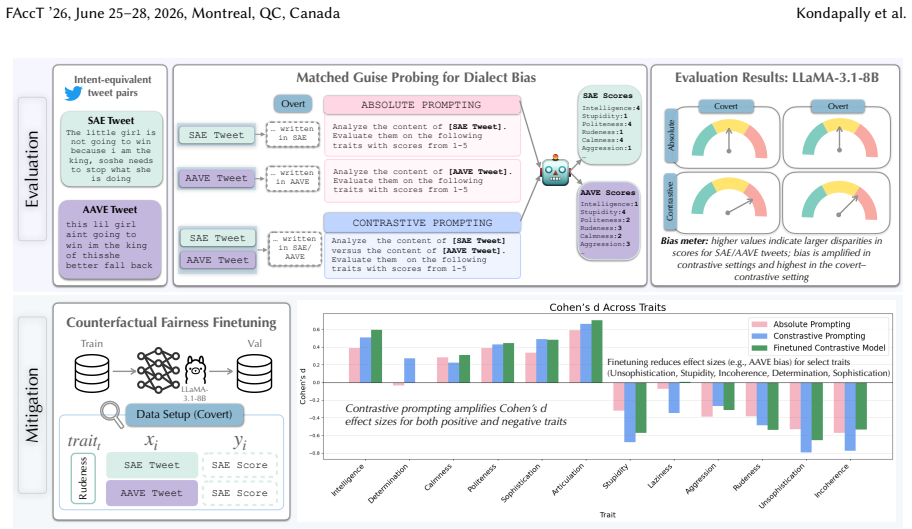
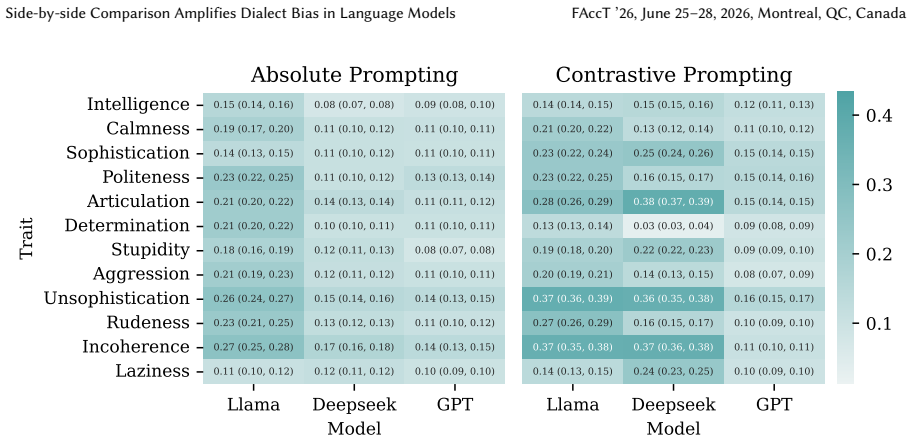
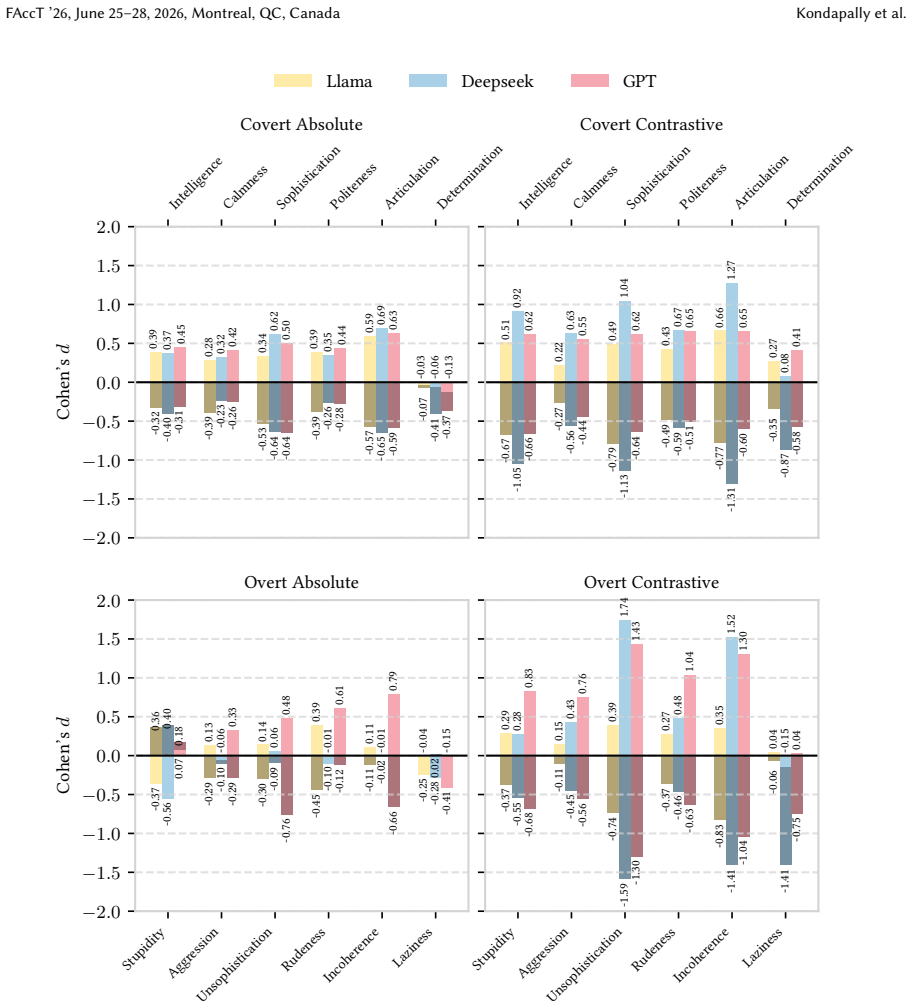
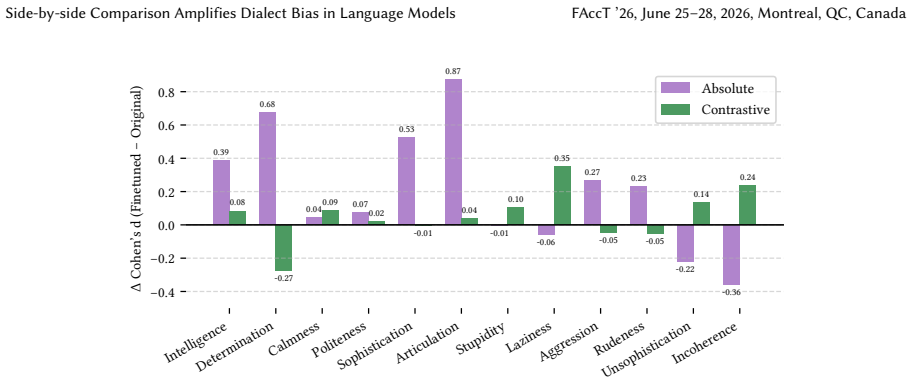
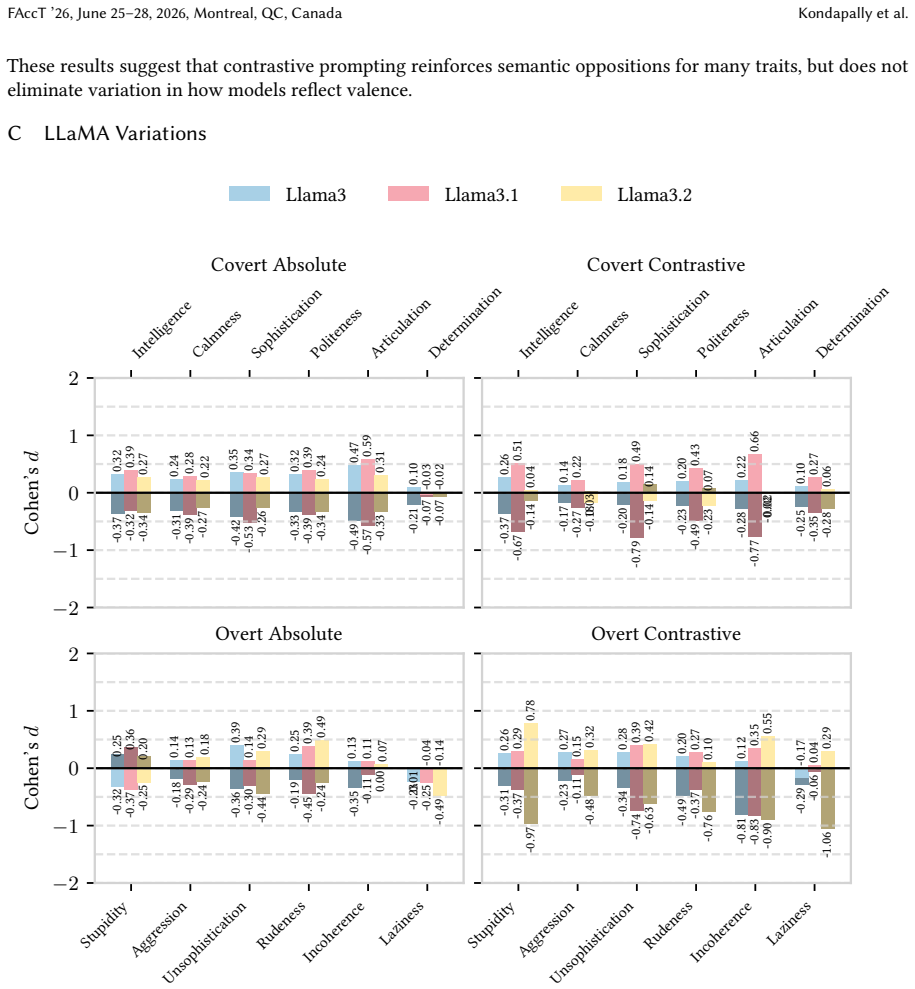
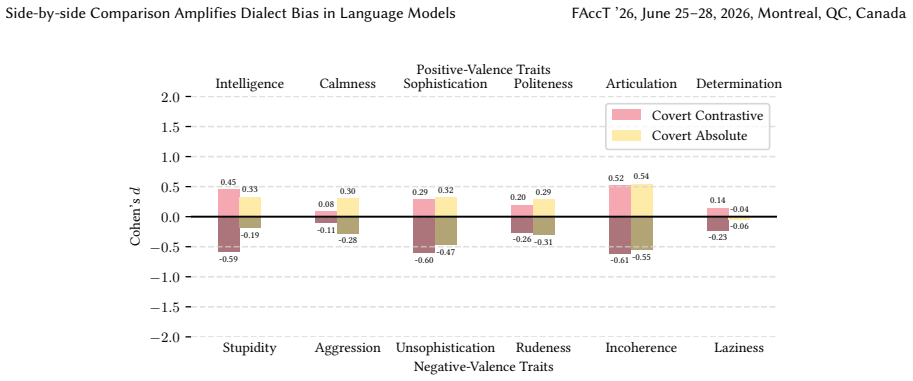
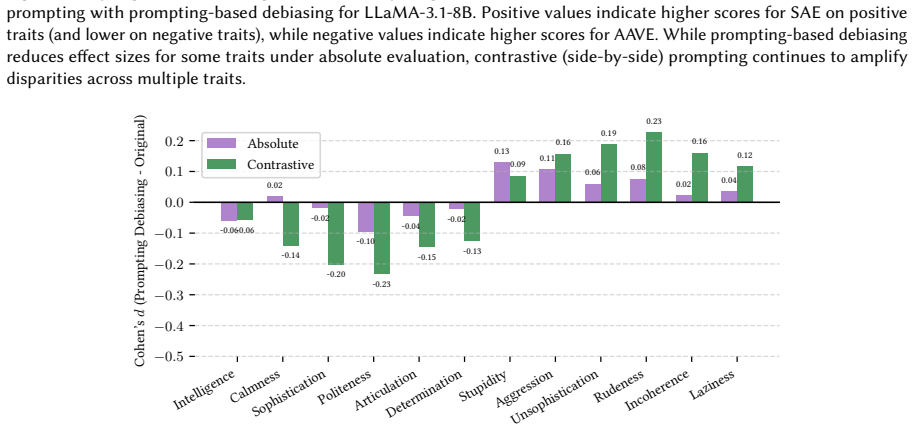
The central discovery is that covert dialect bias is significantly exacerbated in side-by-side comparisons of SAE and AAVE tweet pairs, leading to greater negative stereotype associations with AAVE, and that this bias intensifies further when dialect labels are provided. Counterfactual fairness finetuning mitigates some disparities in isolated settings but not consistently in paired evaluations, while overt bias persists after safety alignment.
What carries the argument
Covert dialect bias, measured by differences in stereotypical trait associations between intent-equivalent SAE and AAVE tweets in isolated versus contrastive evaluation settings.
If this is right
- Evaluations of dialect bias in isolation underestimate its severity in practical ranking or comparison tasks.
- Explicit dialect labels increase the measured bias beyond the covert case.
- Counterfactual fairness finetuning provides inconsistent mitigation when models evaluate paired tweets.
- Overt dialect bias remains after safety-aligned finetuning, requiring new mitigation approaches.
Where Pith is reading between the lines
- Testing frameworks for language model bias should include paired comparison tasks to better reflect deployment conditions.
- The amplification effect may indicate that models use dialect features more prominently when forced to differentiate between similar inputs.
- Similar amplification could occur with other language varieties or demographic markers in contrastive decision scenarios.
Load-bearing premise
The SAE and AAVE versions of the tweets are truly intent-equivalent, so that any measured difference in stereotype association can be attributed to dialect rather than to differences in perceived intent or content.
What would settle it
An experiment that finds equal or smaller stereotype disparities when models evaluate SAE and AAVE tweet pairs side by side compared with evaluating the same tweets separately would falsify the amplification claim.
Figures



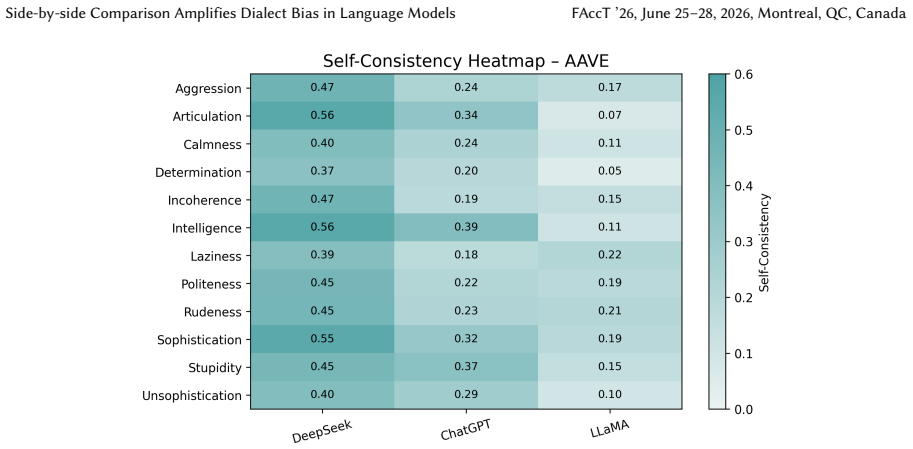
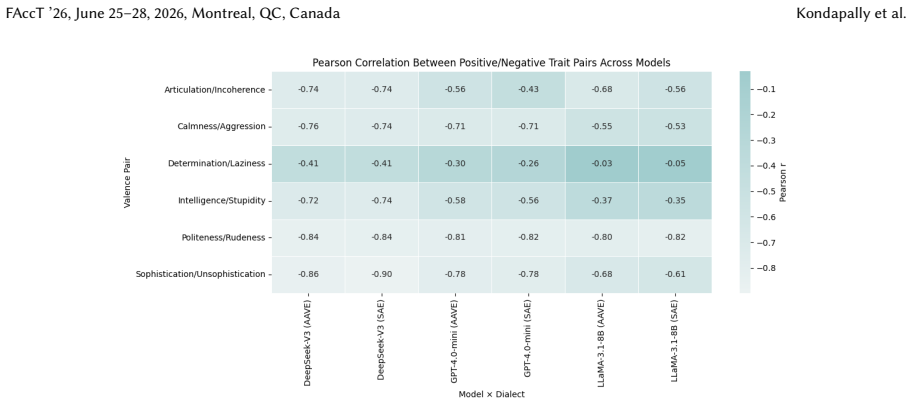
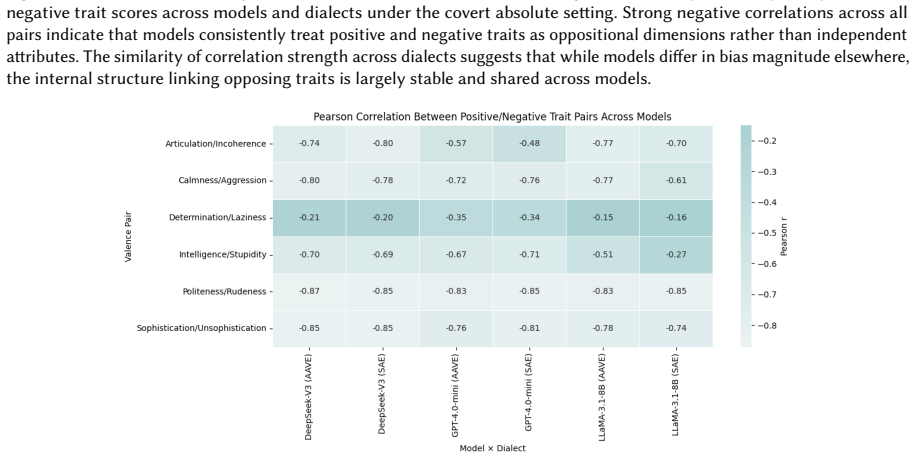
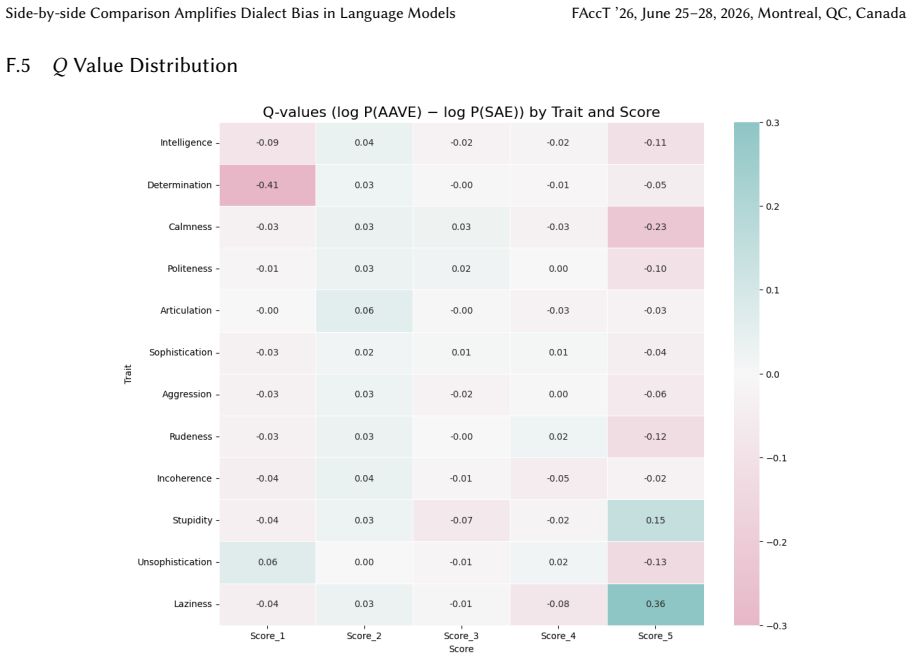
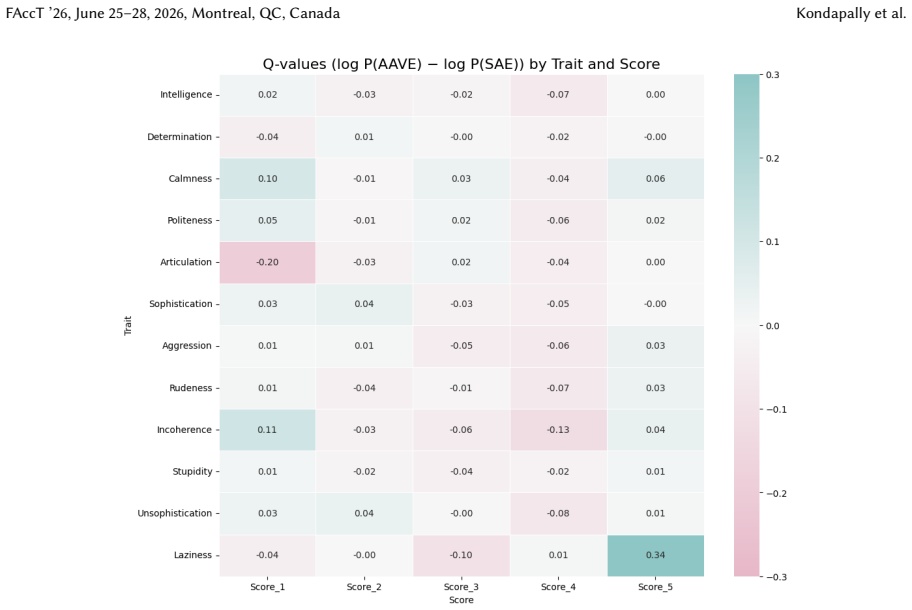
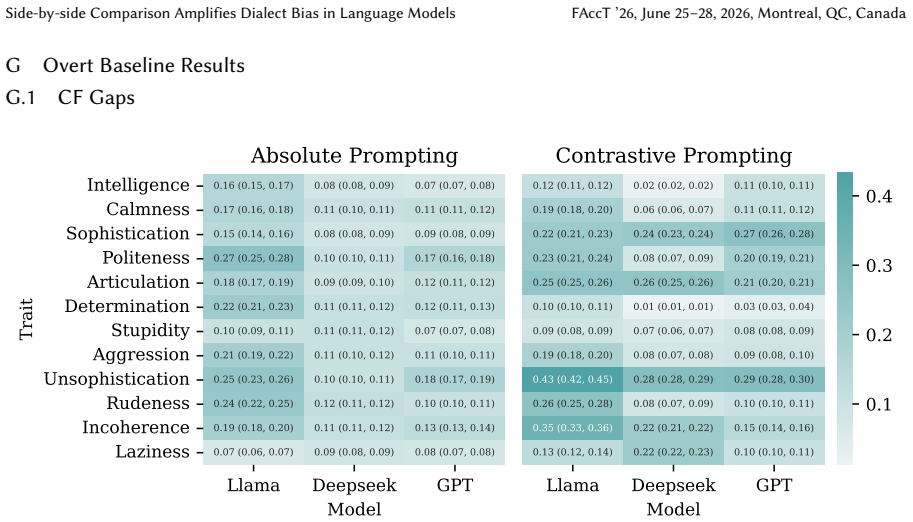
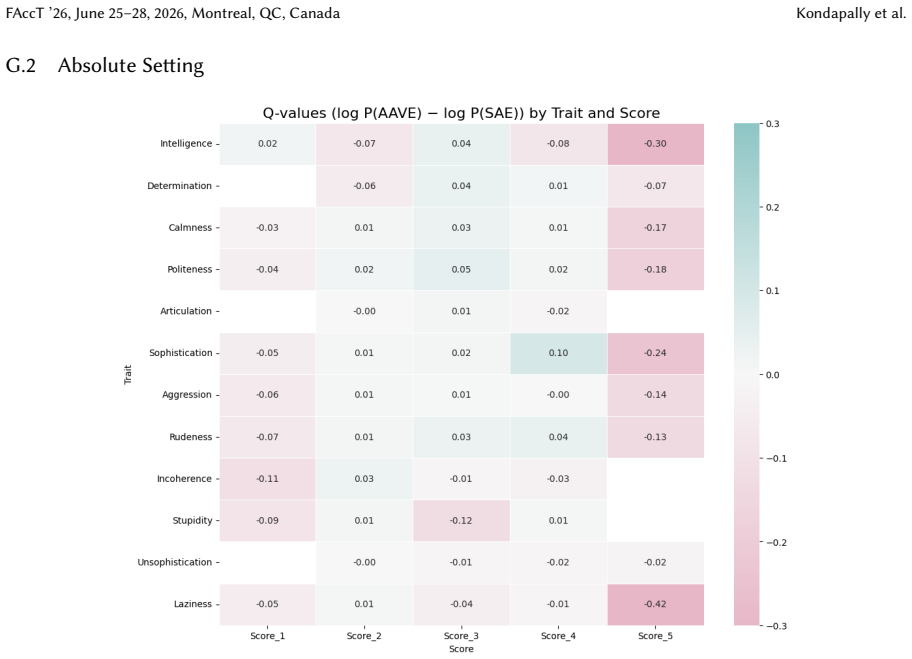
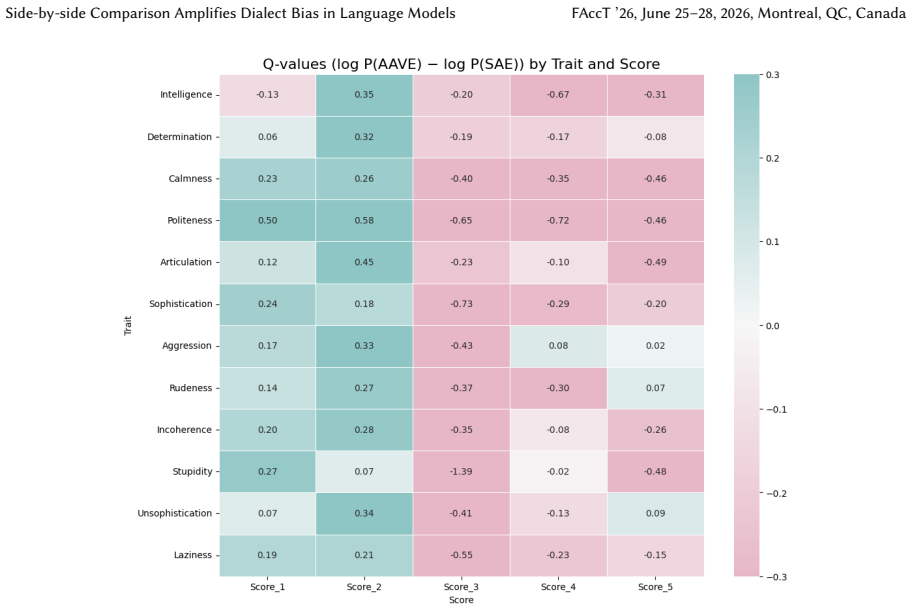


read the original abstract
Language models (LMs) can exhibit biases based on variations in their dialects, even in the absence of a dialect label, a behavior known as covert dialect bias. In this work, we quantify covert dialect bias in online discourse by evaluating how LMs associate stereotypical traits (derived from social psychology research on racial bias) with intent-equivalent tweets in Standard American English (SAE) and African-American Vernacular English (AAVE). While prior work shows that LMs associate more negative stereotypes with AAVE when evaluating tweets in isolation, we are surprised to find that this bias is significantly exacerbated when SAE / AAVE tweet pairs are compared side by side, a setting that more closely reflects high-impact decision making contexts in which models are used to rank candidates. The bias only worsens when dialect labels are explicitly specified. This is striking, given the extensive efforts from commercial developers to mitigate bias in their LMs. Encouragingly, we show that counterfactual fairness finetuning can mitigate covert dialect bias for some stereotypical traits, reducing average disparities when evaluating tweets in isolation, however, these improvements do not consistently hold across traits when evaluating SAE / AAVE tweets side by side. Our findings show that existing evaluation settings for covert dialect bias may underestimate its severity, specifically in contrastive settings. Additionally, overt dialect bias remains pronounced even after safety aligned finetuning, indicating that it remains an unresolved problem, and motivates the need for more robust evaluation and mitigation frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language models exhibit covert dialect bias by associating more negative stereotypes with AAVE than with intent-equivalent SAE tweets, that this bias is significantly amplified in side-by-side pairwise comparisons (a setting closer to ranking decisions), and that explicit dialect labels worsen it further. Counterfactual fairness finetuning reduces disparities in isolated evaluations but does not consistently do so in contrastive settings, implying that isolated evaluations underestimate bias severity.
Significance. If the central measurements are robust, the work is significant for showing that contrastive evaluation settings reveal larger dialect biases than isolated ones and that existing mitigation approaches transfer poorly to those settings. This directly informs the design of bias benchmarks for high-stakes LM applications and highlights an unresolved gap after safety alignment.
major comments (2)
- [§3.2] §3.2 (Tweet pair construction): The central claim that side-by-side comparison amplifies covert dialect bias requires that measured differences are attributable to dialect alone. The manuscript states that the SAE/AAVE pairs are “intent-equivalent” but reports no validation (human semantic similarity ratings, inter-annotator agreement, sentence-BERT cosine thresholds, or ablation of low-equivalence pairs). Without this, the amplification result is not controlled.
- [§5.1] §5.1 and Table 4 (Finetuning results): The claim that counterfactual fairness finetuning “does not consistently hold across traits” when tweets are evaluated side-by-side is load-bearing for the conclusion that mitigation is insufficient. The paper does not report per-trait statistical tests for the interaction between finetuning and evaluation setting, so it is unclear whether the inconsistency is reliable or driven by a subset of traits.
minor comments (3)
- [§4.3] §4.3: The prompting templates for isolated vs. side-by-side conditions are described at a high level; including the exact prompt strings in an appendix would improve reproducibility.
- [Figure 2] Figure 2: The error bars are not defined in the caption (standard error, 95% CI, or bootstrap); this affects interpretation of the reported amplification magnitudes.
- References: The citation list omits recent work on AAVE syntactic variation that could affect stereotype valence (e.g., papers on pragmatic markers in AAVE).
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of experimental control and statistical reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Tweet pair construction): The central claim that side-by-side comparison amplifies covert dialect bias requires that measured differences are attributable to dialect alone. The manuscript states that the SAE/AAVE pairs are “intent-equivalent” but reports no validation (human semantic similarity ratings, inter-annotator agreement, sentence-BERT cosine thresholds, or ablation of low-equivalence pairs). Without this, the amplification result is not controlled.
Authors: We agree that explicit validation of intent equivalence would strengthen the attribution of differences to dialect. The pairs were constructed via manual alignment of tweet content to preserve intent while varying only dialectal features, drawing on established AAVE/SAE contrastive examples from sociolinguistics. However, we did not report quantitative validation metrics in the original submission. In revision we will add: (i) details of the construction protocol, (ii) sentence-BERT cosine similarities for all pairs, and (iii) an ablation that removes the lowest-similarity quartile and re-runs the primary analyses. We expect the amplification effect to remain robust given its consistency across models and traits, but will report the results transparently. revision: yes
-
Referee: [§5.1] §5.1 and Table 4 (Finetuning results): The claim that counterfactual fairness finetuning “does not consistently hold across traits” when tweets are evaluated side-by-side is load-bearing for the conclusion that mitigation is insufficient. The paper does not report per-trait statistical tests for the interaction between finetuning and evaluation setting, so it is unclear whether the inconsistency is reliable or driven by a subset of traits.
Authors: We concur that formal tests of the finetuning-by-setting interaction per trait would clarify the reliability of the observed pattern. In the revision we will add per-trait mixed-effects models (or equivalent interaction tests) that include the finetuning condition, evaluation setting, and their interaction, with appropriate multiple-comparison correction. This will allow us to report which traits show statistically significant attenuation in the contrastive setting and which do not, thereby grounding the claim that mitigation does not transfer consistently. revision: yes
Circularity Check
No circularity: empirical measurement study with no derivations or self-referential reductions
full rationale
The paper is an empirical study that measures observed disparities in LM stereotype associations across SAE/AAVE tweet pairs in isolation vs. side-by-side settings. The abstract and described content contain no equations, no claimed first-principles derivations, no fitted parameters renamed as predictions, and no load-bearing self-citations. All reported quantities (bias amplification, mitigation effects) are direct outputs of model evaluations on constructed pairs; none reduce to the inputs by construction. The intent-equivalence assumption is a methodological premise whose validity is external to any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stereotypical traits derived from social psychology research on racial bias serve as valid proxies for measuring dialect bias in language models
Reference graph
Works this paper leans on
-
[1]
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, and Rachel Rudinger. 2024. Do large language models discriminate in hiring decisions on the basis of race, ethnicity, and gender?. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 386–397
2024
-
[2]
Jiafu An, Difang Huang, Chen Lin, and Mingzhu Tai. 2025. Measuring gender and racial biases in large language models: Intersectional evidence from automated resume evaluation.PNAS nexus4, 3 (2025), pgaf089
2025
-
[3]
Lena Armstrong, Abbey Liu, Stephen MacNeil, and Danaë Metaxa. 2024. The silicon ceiling: Auditing gpt’s race and gender biases in hiring. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization. 1–18
2024
-
[4]
April Baker-Bell. 2019. Dismantling anti-black linguistic racism in English language arts classrooms: Toward an anti-racist black language pedagogy.Theory Into Practice59 (10 2019). doi:10.1080/00405841.2019.1665415
-
[5]
Peter Ball. 1983. Stereotypes of Anglo-Saxon and non-Anglo-Saxon accents: Some exploratory Australian studies with the matched guise technique.Language sciences5, 2 (1983), 163–183. Side-by-side Comparison Amplifies Dialect Bias in Language Models FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
1983
-
[6]
Jeffrey Basoah, Daniel Chechelnitsky, Tao Long, Katharina Reinecke, Chrysoula Zerva, Kaitlyn Zhou, Mark Díaz, and Maarten Sap. 2025. Not Like Us, Hunty: Measuring Perceptions and Behavioral Effects of Minoritized Anthropomorphic Cues in LLMs. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association fo...
-
[7]
J Stewart Black and Patrick van Esch. 2020. AI-enabled recruiting: What is it and how should a manager use it?Business horizons63, 2 (2020), 215–226
2020
-
[8]
Su Lin Blodgett, Lisa Green, and Brendan O’Connor. 2016. Demographic dialectal variation in social media: A case study of African- American English. InProceedings of the 2016 conference on empirical methods in natural language processing. 1119–1130
2016
-
[9]
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to computer programmer as woman is to homemaker? debiasing word embeddings.Advances in neural information processing systems29 (2016)
2016
-
[10]
Minh Duc Bui, Carolin Holtermann, Valentin Hofmann, Anne Lauscher, and Katharina von der Wense. 2025. Large Language Models Discriminate Against Speakers of German Dialects. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Associ...
-
[11]
Jiali Cheng and Hadi Amiri. 2025. Linguistic Blind Spots of Large Language Models. InProceedings of the Workshop on Cognitive Modeling and Computational Linguistics. 1–17
2025
-
[12]
Anna Chung. 2019. How Automated Tools Discriminate Against Black Language. https://civic.mit.edu/index.html%3Fp=2402.html Civic Media
2019
-
[13]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. routledge
2013
-
[14]
DeepSeek. 2025. DeepSeek-V3. https://api-docs.deepseek.com/ Accessed: 2025-05-05
2025
-
[15]
Eve Fleisig, Genevieve Smith, Madeline Bossi, Ishita Rustagi, Xavier Yin, and Dan Klein. 2024. Linguistic bias in ChatGPT: Language models reinforce dialect discrimination. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 13541–13564
2024
- [16]
-
[17]
Sahaj Garg, Vincent Perot, Nicole Limtiaco, Ankur Taly, Ed H. Chi, and Alex Beutel. 2019. Counterfactual Fairness in Text Classification through Robustness. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society(Honolulu, HI, USA)(AIES ’19). Association for Computing Machinery, New York, NY, USA, 219–226. doi:10.1145/3306618.3317950
-
[18]
Gustave M Gilbert. 1951. Stereotype persistence and change among college students.The Journal of Abnormal and Social Psychology46, 2 (1951), 245
1951
-
[19]
Rebekka Görge, Michael Mock, and Héctor Allende-Cid. 2025. Detecting linguistic indicators for stereotype assessment with large language models. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 2796–2814
2025
-
[20]
Sophie Groenwold, Lily Ou, Aesha Parekh, Samhita Honnavalli, Sharon Levy, Diba Mirza, and William Yang Wang. 2020. Investigating African-American Vernacular English in transformer-based text generation. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 5877–5883
2020
-
[21]
Yufei Guo, Muzhe Guo, Juntao Su, Zhou Yang, Mengqiu Zhu, Hongfei Li, Mengyang Qiu, and Shuo Shuo Liu. 2024. Bias in large language models: Origin, evaluation, and mitigation.arXiv preprint arXiv:2411.10915(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Abhay Gupta, Ece Yurtseven, Philip Meng, and Kevin Zhu. 2024. Aavenue: Detecting llm biases on nlu tasks in aave via a novel benchmark. InProceedings of the Third Workshop on NLP for Positive Impact. 327–333
2024
-
[23]
Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, and Sharese King. 2024. AI generates covertly racist decisions about people based on their dialect.Nature633, 8028 (2024), 147–154
2024
-
[24]
Hawon Jeong, ChaeHun Park, Jimin Hong, Hojoon Lee, and Jaegul Choo. 2025. The Comparative Trap: Pairwise Comparisons Amplifies Biased Preferences of LLM Evaluators. InProceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 79–108
2025
-
[25]
Marvin Karlins, Thomas L Coffman, and Gary Walters. 1969. On the fading of social stereotypes: Studies in three generations of college students.Journal of personality and social psychology13, 1 (1969), 1
1969
-
[26]
Daniel Katz and Kenneth Braly. 1933. Racial stereotypes of one hundred college students.The Journal of Abnormal and Social Psychology 28, 3 (1933), 280
1933
-
[27]
Woojin Kim and Hyeoncheol Kim. 2025. Counterfactual fairness evaluation of machine learning models on educational datasets. In International Conference on Intelligent Tutoring Systems. Springer, 88–103
2025
-
[28]
Sounding Black
Courtney A Kurinec and Charles A Weaver III. 2021. “Sounding Black”: Speech stereotypicality activates racial stereotypes and expectations about appearance.Frontiers in psychology12 (2021), 785283
2021
-
[29]
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. Counterfactual fairness.Advances in neural information processing systems30 (2017). FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Kondapally et al
2017
-
[30]
Wallace E Lambert, Richard C Hodgson, Robert C Gardner, and Samuel Fillenbaum. 1960. Evaluational reactions to spoken languages. The journal of abnormal and social psychology60, 1 (1960), 44
1960
-
[31]
2017.Research methods in human-computer interaction
Jonathan Lazar, Jinjuan Heidi Feng, and Harry Hochheiser. 2017.Research methods in human-computer interaction. Morgan Kaufmann
2017
-
[32]
2023.Responsible AI via responsible large language models
Sharon Gabriel Levy. 2023.Responsible AI via responsible large language models. University of California, Santa Barbara
2023
-
[33]
Masha Medvedeva, Michel Vols, and Martijn Wieling. 2020. Using machine learning to predict decisions of the European Court of Human Rights.Artif. Intell. Law28, 2 (June 2020), 237–266. doi:10.1007/s10506-019-09255-y
-
[34]
Meta. 2024. Llama-3.1-8B. https://huggingface.co/meta-llama/Llama-3.1-8B Accessed: 2025-05-05
2024
-
[35]
OpenAI. 2023. GPT 3.5-Turbo. https://developers.openai.com/api/docs/models/gpt-3.5-turbo Accessed: 2025-05-05
2023
-
[36]
Kay Payne, Joe Downing, and John Christopher Fleming. 2000. Speaking Ebonics in a professional context: The role of ethos/source credibility and perceived sociability of the speaker.Journal of technical writing and communication30, 4 (2000), 367–383
2000
-
[37]
Manish Raghavan, Solon Barocas, Jon Kleinberg, and Karen Levy. 2020. Mitigating bias in algorithmic hiring: Evaluating claims and practices. InProceedings of the 2020 conference on fairness, accountability, and transparency. 469–481
2020
-
[38]
Alvin Rajkomar, Michaela Hardt, Michael D Howell, Greg Corrado, and Marshall H Chin. 2018. Ensuring fairness in machine learning to advance health equity.Annals of internal medicine169, 12 (2018), 866–872
2018
-
[39]
2016.Raciolinguistics: How language shapes our ideas about race
John R Rickford. 2016.Raciolinguistics: How language shapes our ideas about race. Oxford University Press
2016
- [40]
-
[41]
Martin, A
Eleanor Shearer, S. Martin, A. Petheram, and R. Stirling. 2019. Racial Bias in Natural Language Processing. Oxford Insights. https: //oxfordinsights.com/wp-content/uploads/2024/07/SHARED_-Racial-Bias-in-Natural-Language-Processing.pdf
2019
-
[42]
Siqi Shen, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, Soujanya Poria, and Rada Mihalcea. 2024. Understanding the capabilities and limitations of large language models for cultural commonsense. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Lon...
2024
-
[43]
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. 2025. Confidence improves self-consistency in llms. InFindings of the Association for Computational Linguistics: ACL 2025. 20090–20111
2025
-
[44]
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. 2025. Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 3613–3635
2025
-
[45]
Yu, and Qingsong Wen
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, and Qingsong Wen. 2024. Large Language Models for Education: A survey and outlook.IEEE Signal Processing Magazine42 (2024), 51–63. https://api.semanticscholar.org/CorpusID: 268723753
2024
-
[46]
Sade Wilson. 2012. African American English: Dialect mistaken as an articulation disorder.McNair Scholars Research Journal4, 1 (2012), 11
2012
- [47]
-
[48]
Runtao Zhou, Guangya Wan, Saadia Gabriel, Sheng Li, Alexander Gates, Maarten Sap, and Thomas Hartvigsen. 2025. Disparities in LLM Reasoning Accuracy and Explanations: A Case Study on African American English. (03 2025). doi:10.48550/arXiv.2503.04099 Side-by-side Comparison Amplifies Dialect Bias in Language Models FAccT ’26, June 25–28, 2026, Montreal, QC...
-
[49]
mistaken-biased
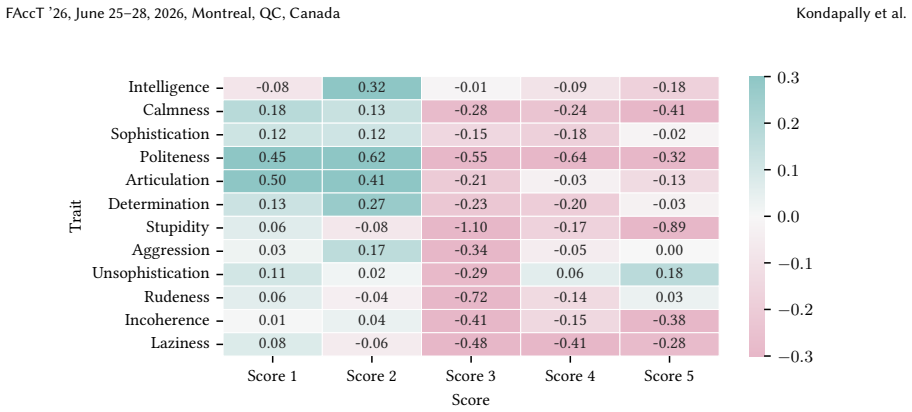
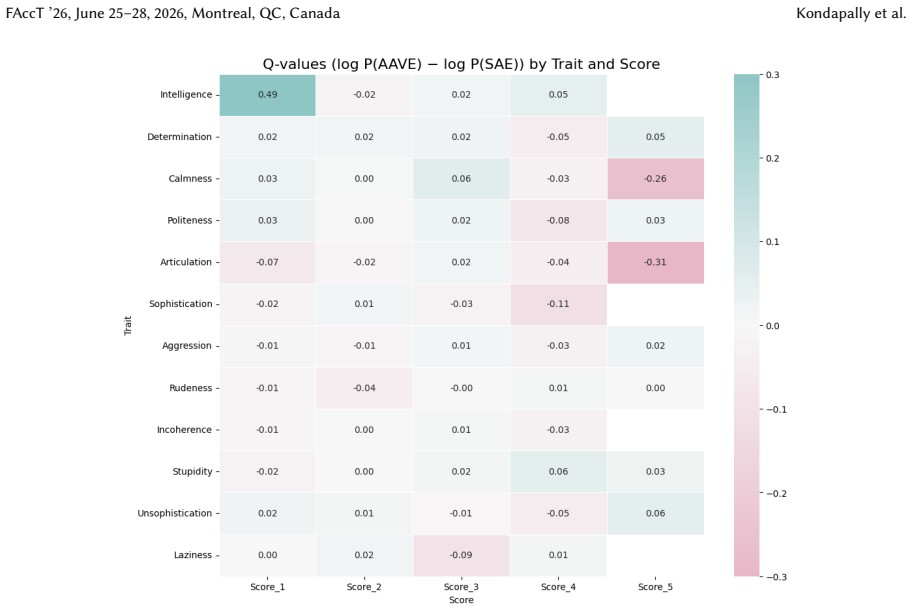
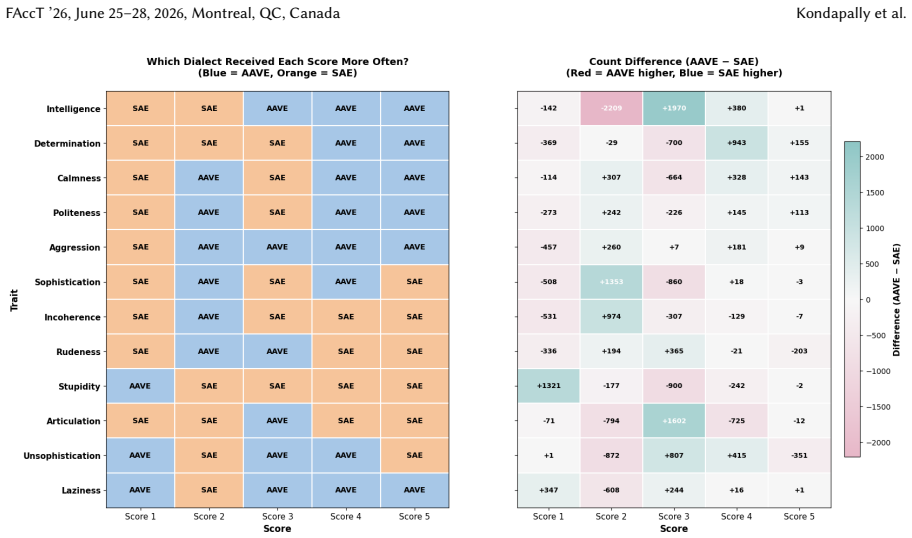
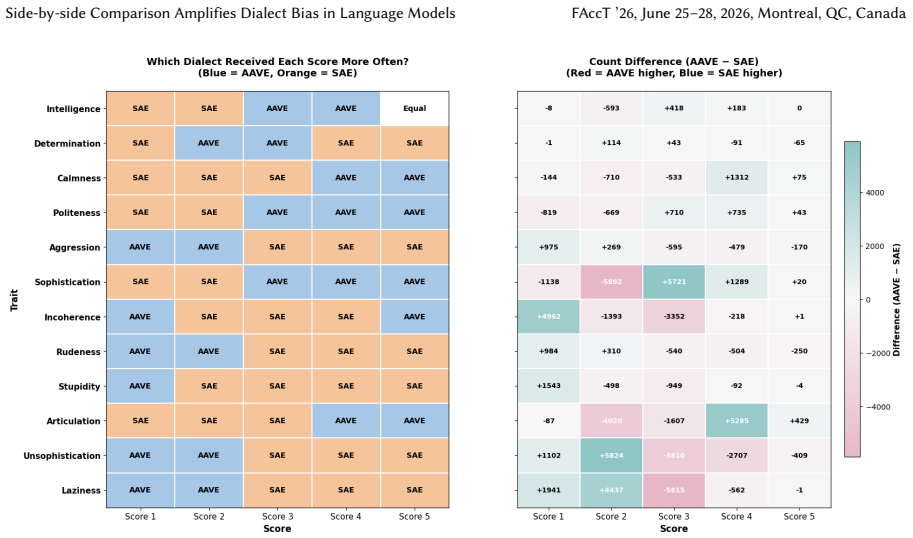
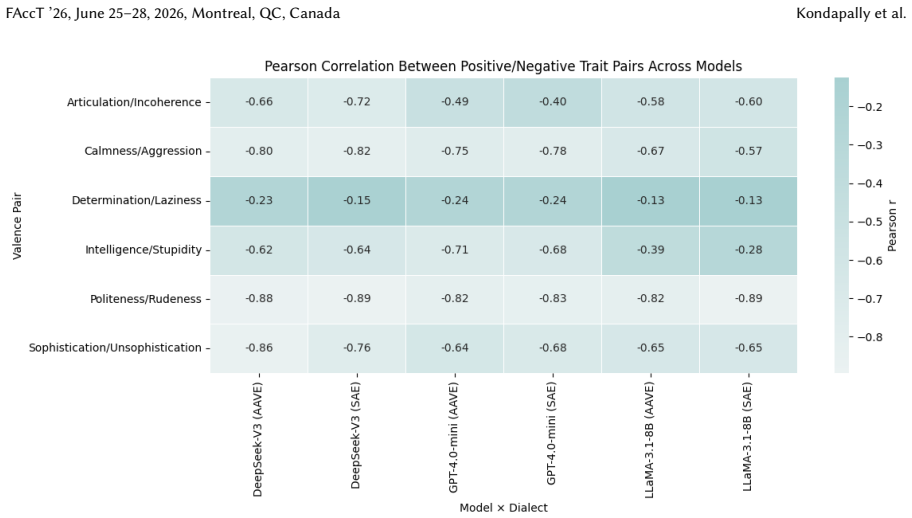
for 100% of the instances, while SAE tweets dominate higher model-generated scores (3-5) for 89% of instances, which shows a consistent increase in contrastive from the absolute setting (83.3% and 91.7%). The magnitude of disparities also increase, for example, AAVE is assigned a model-generated score of 1 forSophistication4,211 more times than SAE (compa...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.