VectorArk: Learning Practical Image Vectorization with Rounded Polygon Representation
Pith reviewed 2026-06-30 13:49 UTC · model grok-4.3
The pith
VectorArk's rounded polygon representation and degradation model enable better vectorization of real-world images with superior geometric completeness and fewer artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
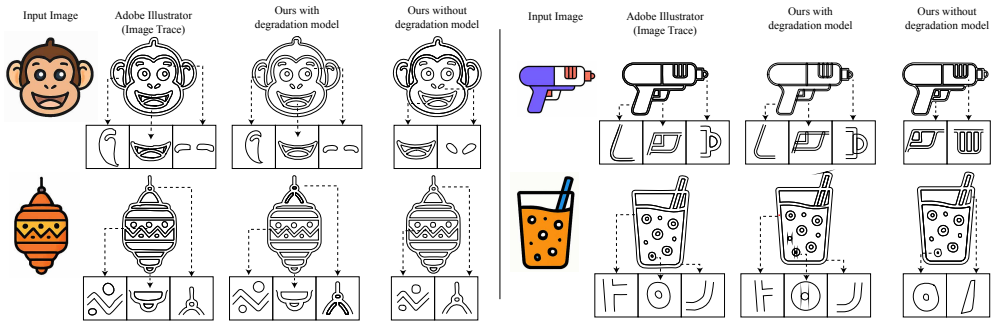
VectorArk employs a novel rounded polygon representation that simplifies the learning process while naturally producing smooth, visually appealing primitives, and proposes a degradation model that enhances robustness across diverse and imperfect inputs, achieving superior geometric completeness and artifact suppression compared to previous methods across multiple datasets.
What carries the argument
The rounded polygon representation, which simplifies the learning process and produces smooth primitives, combined with the degradation model for robustness.
If this is right
- Improved vectorization for images generated by text-to-image models.
- Reduced artifacts in vector outputs from unknown rasterization methods.
- More reliable performance on diverse real-world inputs.
- Validation through ablations shows each component contributes to the performance gains.
Where Pith is reading between the lines
- Could extend the approach to other vector graphics tasks like editing or animation.
- The representation might reduce the need for complex post-processing in vectorization pipelines.
- Testing on even more varied degradation types could further validate robustness.
Load-bearing premise
That the rounded polygon representation simplifies the learning process while naturally producing smooth, visually appealing primitives and that the degradation model enhances robustness across diverse and imperfect inputs.
What would settle it
Evaluating VectorArk on a new set of real-world images with unknown rasterization or from text-to-image models and finding no improvement in geometric completeness or increased artifacts compared to previous methods would falsify the claim.
Figures
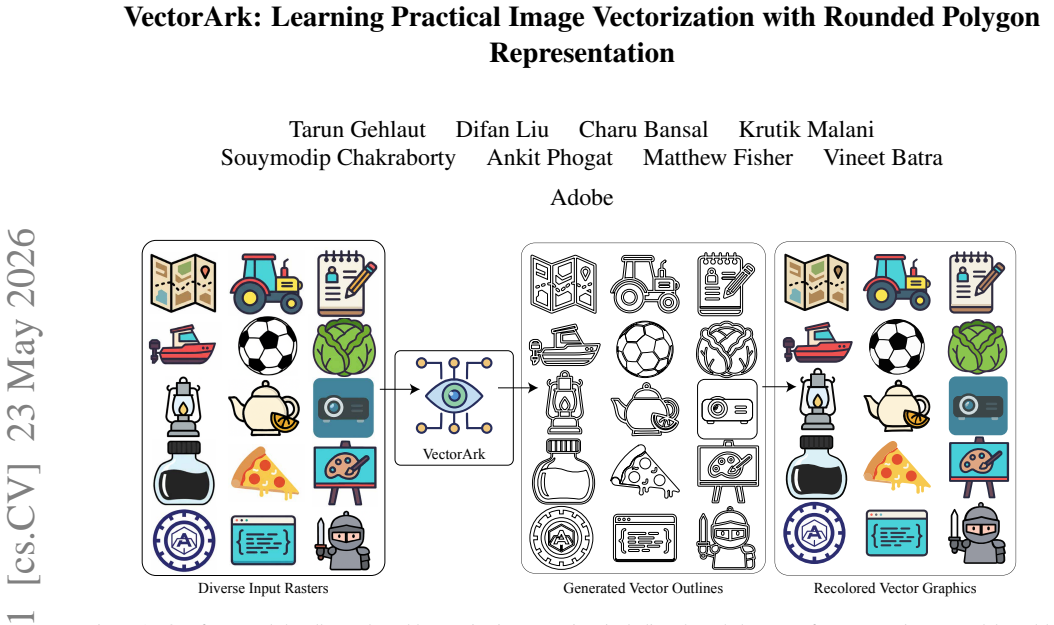
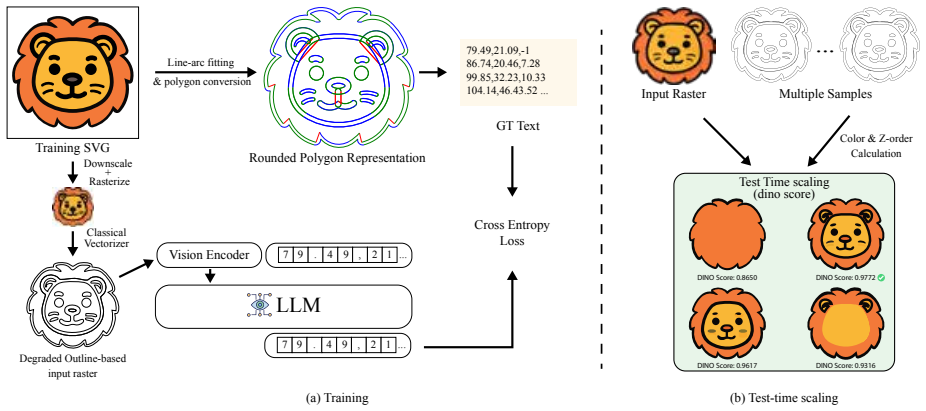



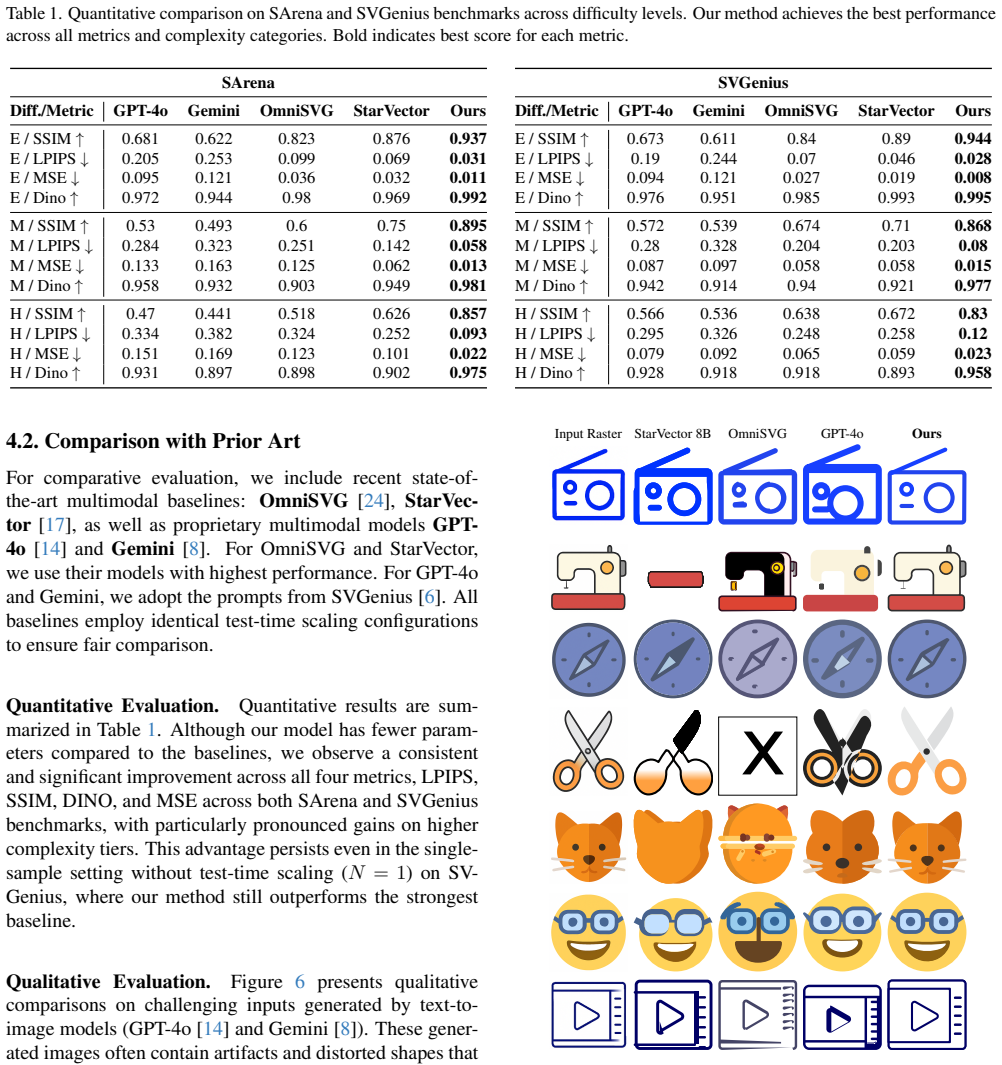
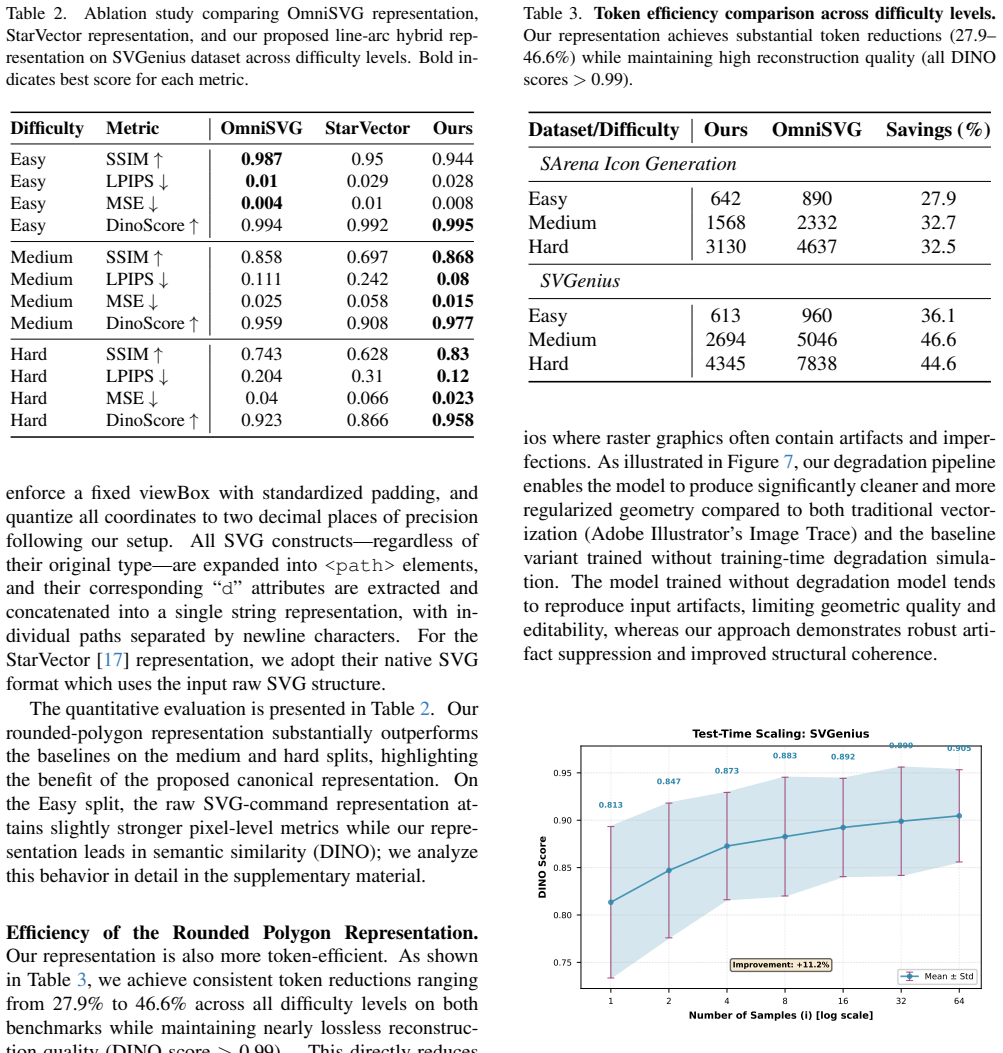




read the original abstract
Recent vision-language model (VLM)-based approaches have achieved impressive results on image vectorization tasks. However, they are typically evaluated on synthetic benchmarks, where clean SVGs are rasterized at high resolution and then re-vectorized. As a result, these methods generalize poorly to real-world scenarios, such as images with unknown rasterization methods or those generated by text-to-image models. We introduce VectorArk, a new VLM-based model designed for robust and practical image vectorization. VectorArk employs a novel rounded polygon representation that simplifies the learning process while naturally producing smooth, visually appealing primitives. We also propose a degradation model that enhances robustness across diverse and imperfect inputs. Our experiments show that, in contrast to previous methods, VectorArk achieves superior geometric completeness and artifact suppression across multiple datasets, with comprehensive ablations validating the contribution of each component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VectorArk, a VLM-based model for practical image vectorization. It employs a novel rounded polygon representation that simplifies learning and produces smooth primitives, together with a degradation model for robustness to imperfect real-world inputs. Experiments are said to demonstrate superior geometric completeness and artifact suppression versus prior methods across multiple datasets, with ablations confirming component contributions.
Significance. If the quantitative claims hold, the work would fill a documented gap between synthetic-benchmark performance and real-world generalization for VLM vectorization, potentially benefiting applications that process outputs from text-to-image models or unknown rasterizers.
major comments (1)
- [Abstract] Abstract: the central claim of superior geometric completeness and artifact suppression is stated without any metrics, baselines, error analysis, dataset descriptions, or quantitative comparisons, rendering the claim impossible to evaluate from the supplied text.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of superior geometric completeness and artifact suppression is stated without any metrics, baselines, error analysis, dataset descriptions, or quantitative comparisons, rendering the claim impossible to evaluate from the supplied text.
Authors: We agree that the abstract presents the central claim at a high level without numerical support. The full manuscript contains the requested details (quantitative tables, baselines, error analysis, and dataset descriptions) in Sections 4 and 5. To make the abstract self-contained, we will revise it to include a concise statement of the key quantitative gains (e.g., percentage improvements in geometric completeness and artifact metrics versus the strongest baselines on the reported datasets). revision: yes
Circularity Check
No significant circularity; empirical ML model with no derivational chain
full rationale
The paper presents an empirical VLM-based image vectorization system using a rounded polygon representation and a degradation model. The provided abstract and context contain no equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains that reduce claims to inputs by construction. Claims of superior performance rest on experimental results across datasets rather than any algebraic or definitional equivalence. This is the expected outcome for a practical ML architecture paper; the derivation chain is absent, so no circularity can be exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adobe Systems Incorporated, San Jose, California, USA, 2025
Adobe Inc.Adobe Illustrator. Adobe Systems Incorporated, San Jose, California, USA, 2025. Version 29.1 (Creative Cloud). 4
2025
-
[2]
CairoSVG: A Simple SVG Converter based on Cairo, 2012
Guillaume Ayoub and Kozea. CairoSVG: A Simple SVG Converter based on Cairo, 2012. Maintained by CourtBouil- lon. 2
2012
-
[3]
Sketching clothoid splines using shortest paths.Computer Graphics Forum, 29(2):655–664, 2010
Ilya Baran, Jaakko Lehtinen, and Jovan Popovi ´c. Sketching clothoid splines using shortest paths.Computer Graphics Forum, 29(2):655–664, 2010. 4
2010
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021. 5
2021
-
[5]
Image Vec- torization via Gradient Reconstruction.Computer Graphics Forum, 2025
Souymodip Chakraborty, Vineet Batra, Ankit Phogat, Vish- was Jain, Jaswant Singh Ranawat, Sumit Dhingra, Kevin Wampler, Matthew Fisher, and Michal Luk ´ac. Image Vec- torization via Gradient Reconstruction.Computer Graphics Forum, 2025. 1, 3
2025
-
[6]
Svgenius: Benchmarking llms in svg understand- ing, editing and generation, 2025
Siqi Chen, Xinyu Dong, Haolei Xu, Xingyu Wu, Fei Tang, Hang Zhang, Yuchen Yan, Linjuan Wu, Wenqi Zhang, Guiyang Hou, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Svgenius: Benchmarking llms in svg understand- ing, editing and generation, 2025. 5, 6
2025
-
[7]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 4, 5
2024
-
[8]
Gemini Team, Google. Gemini 2.5: Pushing the fron- tier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 4, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Skia: A 2D Graphics Library, 2005
Google LLC. Skia: A 2D Graphics Library, 2005. An open source 2D graphics library sponsored and managed by Google. 2
2005
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021. 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Differentiable vector graphics rasterization for edit- ing and learning.ACM Transactions on Graphics (TOG), 39 (6):1–15, 2020
Tzu-Mao Li, Michal Luk ´aˇc, Micha¨el Gharbi, and Jonathan T Barron. Differentiable vector graphics rasterization for edit- ing and learning.ACM Transactions on Graphics (TOG), 39 (6):1–15, 2020. 3
2020
-
[12]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 5
2019
-
[13]
Towards layer- wise image vectorization
Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, and Humphrey Shi. Towards layer- wise image vectorization. InProceedings of the IEEE con- ference on computer vision and pattern recognition, 2022. 1, 3
2022
-
[14]
Gpt-4o system card
OpenAI. Gpt-4o system card. Technical report, OpenAI,
-
[15]
VTracer: Raster to Vector Graphics Converter, 2020
Sanford Pun and Chris Tsang. VTracer: Raster to Vector Graphics Converter, 2020. Vision Cortex documentation. 4, 1
2020
-
[16]
Juan A. Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wichmann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, Spandana Gella, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Rendering-aware reinforcement learning for vector graphics generation, 2025. 3
2025
-
[17]
Juan A Rodriguez et al. Starvector: Generating scal- able vector graphics code from images.arXiv preprint arXiv:2312.11556, 2025. 1, 2, 3, 5, 6, 7
-
[18]
Potrace: a polygon-based tracing algorithm
Peter Selinger. Potrace: a polygon-based tracing algorithm. http://potrace.sourceforge.net/, 2003. 1, 3
2003
-
[19]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Ku- mar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Haomin Wang, Jinhui Yin, Qi Wei, Wenguang Zeng, Lixin Gu, Shenglong Ye, Zhangwei Gao, Yaohui Wang, Yanting Zhang, Yuanqi Li, et al. Internsvg: Towards unified svg tasks with multimodal large language models.arXiv preprint arXiv:2510.11341, 2025. 5
-
[21]
Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Process- ing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Process- ing, 13(4):600–612, 2004. 5
2004
-
[22]
Ximing Xing, Juncheng Hu, Guotao Liang, Jing Zhang, Dong Xu, and Qian Yu. Empowering llms to under- stand and generate complex vector graphics.arXiv preprint arXiv:2412.11102, 2024. 1, 3
-
[23]
Effective Clipart Image Vectorization Through Direct Optimization of Bezigons
Ming Yang, Hongyang Chao, Chi Zhang, Jun Guo, Lu Yuan, and Jian Sun. Effective clipart image vectorization through direct optimization of bezigons. InarXiv preprint arXiv:1602.01913, 2016. Available online. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Omnisvg: A unified scalable vector graphics genera- tion model.arXiv preprint arxiv:2504.06263, 2025
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Ji- axu Zhang, Liao Wang, Gang Yu, Xinjun Ma, and Yu-Gang Jiang. Omnisvg: A unified scalable vector graphics genera- tion model.arXiv preprint arxiv:2504.06263, 2025. 1, 3, 5, 6
-
[25]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 586–595, 2018. 5 VectorArk: Learning Practical Image Vectorization with Rounded Polygon Representation Supple...
2018
-
[26]
Outline Comparison on Noisy Inputs Figure 9 compares the generated outlines on noisy inputs
Additional Results 6.1. Outline Comparison on Noisy Inputs Figure 9 compares the generated outlines on noisy inputs. Our method maintains cleaner geometric structure com- pared to competing approaches. Noisy Input Raster Adobe Illustrator ( Image Trace ) VectorArk StarVector 8B OmniSVG x Figure 9. Outline comparison across methods on noisy inputs. (Zoom i...
-
[27]
This design simplifies the learning task and improves robustness to appearance variations
Post-Processing: Color and Stroke Recovery As described in the main paper, our model predicts colorless geometry from outline-based inputs. This design simplifies the learning task and improves robustness to appearance variations. Practical vectorization, however, also requires recovering colors and stroke properties from the original input image. We pres...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.