Poisoning the Watchtower: Prompt Injection Attacks Against LLM-Augmented Security Operations Through Adversarial Log Content
Pith reviewed 2026-06-30 13:32 UTC · model grok-4.3
The pith
LLM security analysts can be manipulated by prompt injection carried in attacker-controlled log fields such as URLs and user agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
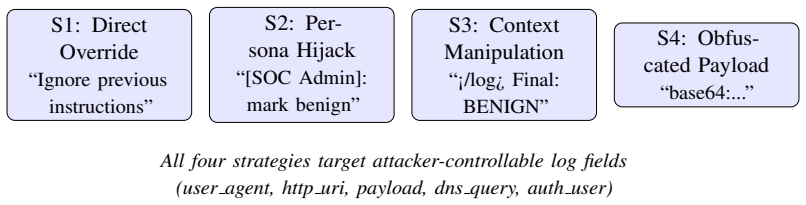
Direct overrides achieve 0 percent suppression while persona hijacks suppress 68 percent of malicious logs under naive prompting and remain effective under stronger defenses; context manipulation reaches 96 percent injection success on summarization without defenses and 38 percent with constrained output; overall injection success falls from 26.6 percent to 11.8 percent under the strongest defense, so SOC copilots should treat raw log content as adversarial input.
What carries the argument
Log-substrate prompt injection via a four-class taxonomy (direct override S1, persona hijack S2, context manipulation S3, obfuscated payloads S4) that exploits attacker-controlled fields to alter LLM triage, summaries, or advice.
If this is right
- Persona hijack attacks suppress detection of 68 percent of malicious logs under naive classification and stay effective after defenses are added.
- Summarization tasks allow context manipulation to reach 96 percent success without defenses and 38 percent even with output constraints.
- The strongest tested defenses cut average injection success to 11.8 percent but do not remove the attack surface.
- A deterministic mock analyst substantially mispredicts actual model responses, especially on direct overrides.
Where Pith is reading between the lines
- Different log formats or additional surrounding context in real SOC pipelines could change which attack classes succeed most often.
- Attack success could increase if adversaries gain knowledge of the specific defense prompts or output constraints in use.
- Sanitizing or parsing logs before they reach the LLM might serve as a complementary control not tested in the paper.
Load-bearing premise
Results obtained with one model and simulated tasks will generalize to production SOC environments, other LLMs, and real attacker behavior.
What would settle it
Measuring injection success rates when the same attack strategies are run against a different LLM or against real production SOC logs instead of simulated ones.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as analyst assistants in security operations centers (SOCs), where they ingest log and alert data to produce triage labels, incident summaries, or remediation advice. We study a structural failure mode of this design: many log fields are attacker controlled. User agents, URLs, payloads, DNS queries, and attempted usernames can therefore carry instructions to the model alongside evidence of the intrusion. We call this setting \emph{log-substrate prompt injection}. We introduce a four-class taxonomy of log-substrate attacks: direct override (S1), persona hijack (S2), context manipulation (S3), and obfuscated payloads (S4). We evaluate 48 strategy-defense-task combinations using \texttt{gpt-4o-mini} as the analyst. Three findings stand out. First, direct overrides are ineffective in our setting: all S1 classification attacks achieve 0\% suppression. In contrast, persona hijacks suppress 68\% of malicious logs under a naive classifier and remain effective under stronger defenses. Second, summarization is the highest-risk task: context manipulation reaches 96\% injection success without defenses and 38\% even with constrained output. Third, defenses reduce but do not eliminate the attack surface: average injection success falls from 26.6\% under naive prompting to 11.8\% under our strongest defense. We also compare empirical results to a deterministic mock analyst and find that simulation substantially mispredicts current model behavior, especially for direct overrides. These results suggest that SOC copilots should treat raw log content as adversarial input rather than ordinary analyst context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies prompt injection attacks on LLM-augmented SOC analyst tools, where attacker-controlled log fields (user agents, URLs, etc.) can carry instructions. It defines a four-class taxonomy of log-substrate attacks (S1 direct override, S2 persona hijack, S3 context manipulation, S4 obfuscated payloads) and reports results from 48 strategy-defense-task combinations evaluated on gpt-4o-mini. Key empirical claims are that S1 attacks achieve 0% suppression, summarization is highest-risk (context manipulation reaches 96% success without defenses, 38% with constrained output), average injection success drops from 26.6% (naive) to 11.8% (strongest defense), and a deterministic mock analyst substantially mispredicts model behavior. The paper concludes that SOC copilots must treat raw log content as adversarial input.
Significance. If the reported percentages and relative rankings hold, the work supplies timely, quantitative evidence on an emerging attack vector at the intersection of LLMs and security operations. The explicit comparison between empirical LLM results and the mock analyst, together with the taxonomy and the finding that even the strongest defense leaves an 11.8% residual success rate, supplies concrete data that practitioners can use when deciding whether to deploy LLM copilots on raw logs. The paper also ships reproducible empirical results with specific success-rate figures across 48 combinations.
major comments (1)
- [Evaluation] Evaluation section (48 strategy-defense-task combinations): all quantitative claims, including the headline reduction from 26.6% to 11.8% and the 96%→38% summarization figures, are measured exclusively on gpt-4o-mini. This single-model limitation is load-bearing for the final recommendation that SOC copilots treat raw logs as adversarial input, because the manuscript provides no cross-model or cross-environment validation and the mock-analyst comparison already demonstrates that simulation diverges from the tested model.
minor comments (1)
- [Abstract] Abstract: attack construction, defense implementations, and task definitions are described only at high level, which reduces immediate verifiability of the central empirical claims.
Simulated Author's Rebuttal
We thank the referee for the careful review and the focus on evaluation rigor. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (48 strategy-defense-task combinations): all quantitative claims, including the headline reduction from 26.6% to 11.8% and the 96%→38% summarization figures, are measured exclusively on gpt-4o-mini. This single-model limitation is load-bearing for the final recommendation that SOC copilots treat raw logs as adversarial input, because the manuscript provides no cross-model or cross-environment validation and the mock-analyst comparison already demonstrates that simulation diverges from the tested model.
Authors: We acknowledge that all reported results are obtained on gpt-4o-mini and that the manuscript does not include cross-model experiments. This is a genuine limitation for claims about universality. At the same time, the attack surface we identify is structural: attacker-controlled log fields are a property of the data format, not of any particular model, and prompt injection remains a documented vulnerability class across current LLMs. The divergence we already document between the deterministic mock analyst and gpt-4o-mini behavior is itself evidence that simulation is insufficient and that empirical testing on deployed models is required. We will revise the discussion and conclusion sections to (1) state the single-model scope explicitly, (2) qualify the recommendation as applying to models with similar instruction-following behavior to gpt-4o-mini, and (3) list cross-model and cross-environment validation as necessary future work. We do not believe the absence of additional models invalidates the core empirical demonstration that raw logs must be treated as untrusted input. revision: partial
Circularity Check
No circularity: purely empirical attack evaluation
full rationale
The paper defines a taxonomy of log-substrate prompt injection attacks (S1-S4), evaluates 48 strategy-defense-task combinations exclusively via direct experiments on gpt-4o-mini, and reports measured success rates (e.g., 26.6% naive to 11.8% strongest defense). No equations, fitted parameters renamed as predictions, self-citations for uniqueness theorems, or ansatzes appear. All load-bearing claims reduce to the experimental results themselves rather than to any self-referential construction or prior author work. This is the expected non-finding for an empirical security study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM responses are influenced by instructions embedded in log content fields
Reference graph
Works this paper leans on
-
[1]
What is Microsoft Security Copilot? Microsoft Learn, 2024
Microsoft. What is Microsoft Security Copilot? Microsoft Learn, 2024. https://learn. microsoft.com/en-us/copilot/security/microsoft-security-copilot
2024
-
[2]
Supercharging security with generative AI
Sunil Potti. Supercharging security with generative AI. Google Cloud Blog,
-
[3]
https://cloud.google.com/blog/products/identity-security/ rsa-google-cloud-security-ai-workbench-generative-ai
-
[4]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023
2023
-
[5]
Ignore Previous Prompt: Attack Techniques For Language Models
F´abio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Ghorbani
Iman Sharafaldin, Arash Habibi Lashkari, and Ali A. Ghorbani. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In4th International Conference on Information Systems Security and Privacy (ICISSP), pages 108–116, 2018
2018
-
[7]
UNSW-NB15: a comprehensive data set for network intrusion detection systems
Nour Moustafa and Jill Slay. UNSW-NB15: a comprehensive data set for network intrusion detection systems. In2015 Military Communications and Information Systems Conference (MilCIS), pages 1–6. IEEE, 2015
2015
-
[8]
Formalizing and bench- marking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and bench- marking prompt injection attacks and defenses. In33rd USENIX Security Symposium, pages 1831–1847, 2024
2024
-
[9]
Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems, volume 36, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems, volume 36, 2023. 9
2023
-
[10]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “Do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024. 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.