Code2UML: Agentic LLMs with context engineering for scalable software visualization
Pith reviewed 2026-06-30 13:31 UTC · model grok-4.3
The pith
An agentic LLM system paired with deterministic IR compaction generates UML diagrams from large code repositories while respecting token limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
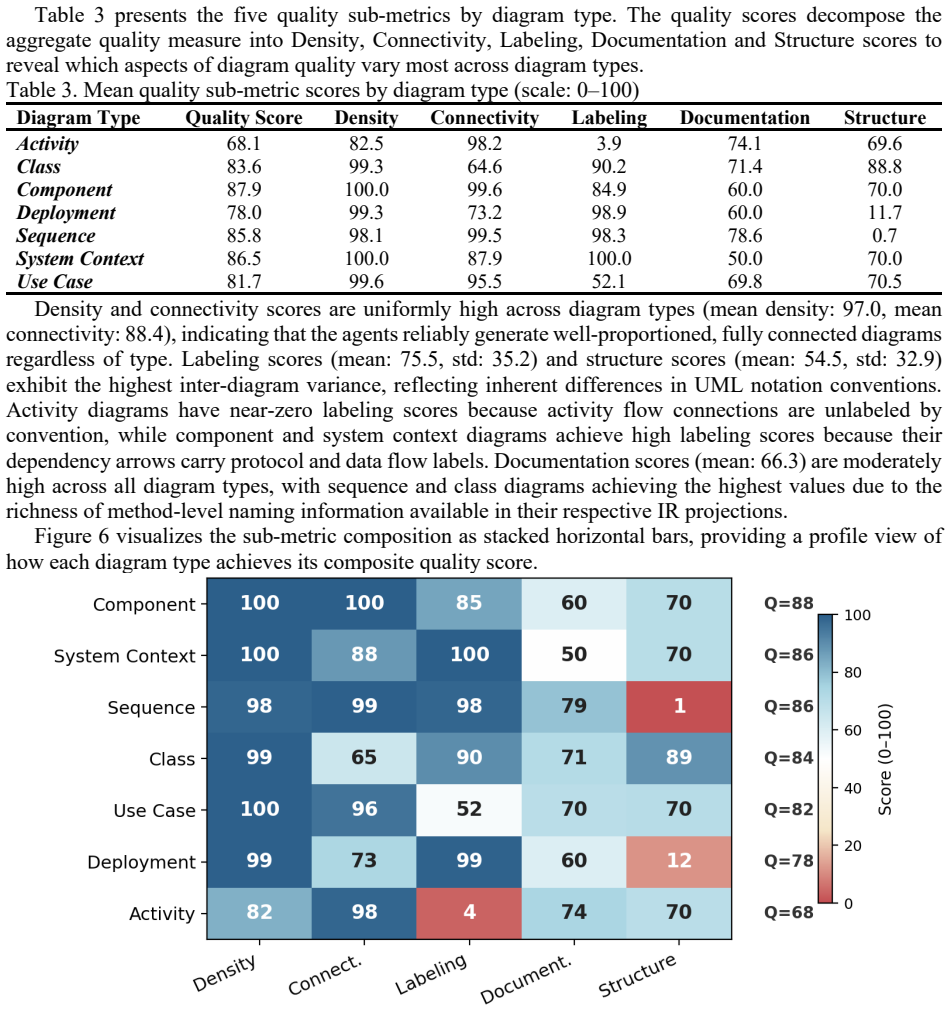
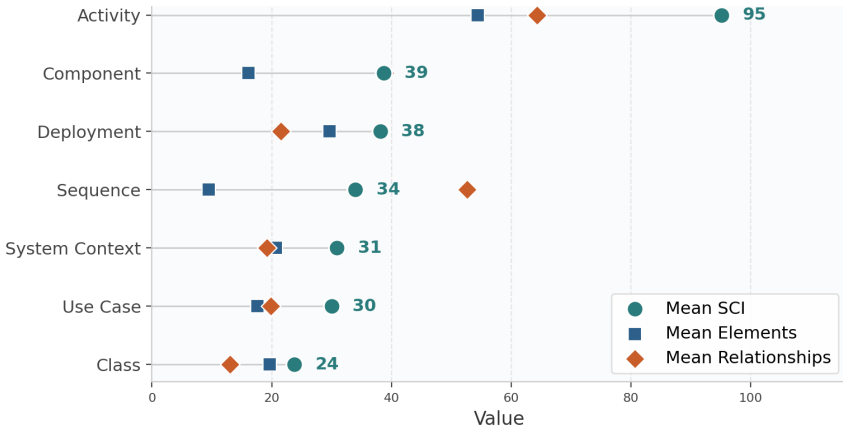
The authors establish that the five-agent hierarchy combined with the deterministic importance-weighted IR compaction layer produces UML diagrams from complete project representations that exceed typical context windows, delivering high syntactic validity and relationship precision whose scores remain stable independent of the number of entities in the input.
What carries the argument
The deterministic importance-weighted IR compaction layer that converts full project IRs into diagram-specific views without any LLM involvement.
If this is right
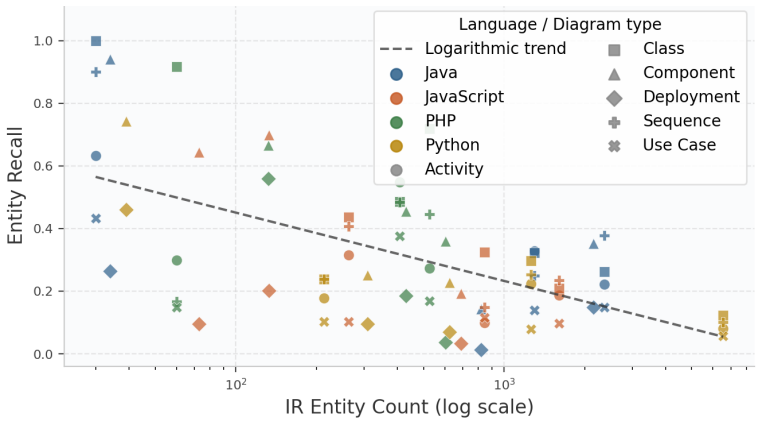
- Diagram quality metrics stay consistent as the number of IR entities grows from dozens to thousands.
- The approach works across multiple programming languages and seven different UML diagram types.
- Entity recall stays deliberately moderate because the design favors precise architectural relationships over exhaustive coverage.
- Software documentation automation becomes feasible for projects whose full IR would otherwise exceed model limits.
Where Pith is reading between the lines
- The same deterministic reduction step could support other LLM tasks that currently hit context ceilings in code analysis.
- Embedding the agent hierarchy in an IDE might allow diagrams to update automatically as code changes.
- The clean split between the deterministic layer and the LLM agents may lower overall token usage in production documentation pipelines.
Load-bearing premise
The compaction layer can reduce full project IRs to diagram-specific views that fit token limits while retaining every piece of information required for accurate diagram generation.
What would settle it
A repository where the compacted view drops a required relationship or entity, producing a diagram that fails to match the actual code structure.
Figures
read the original abstract
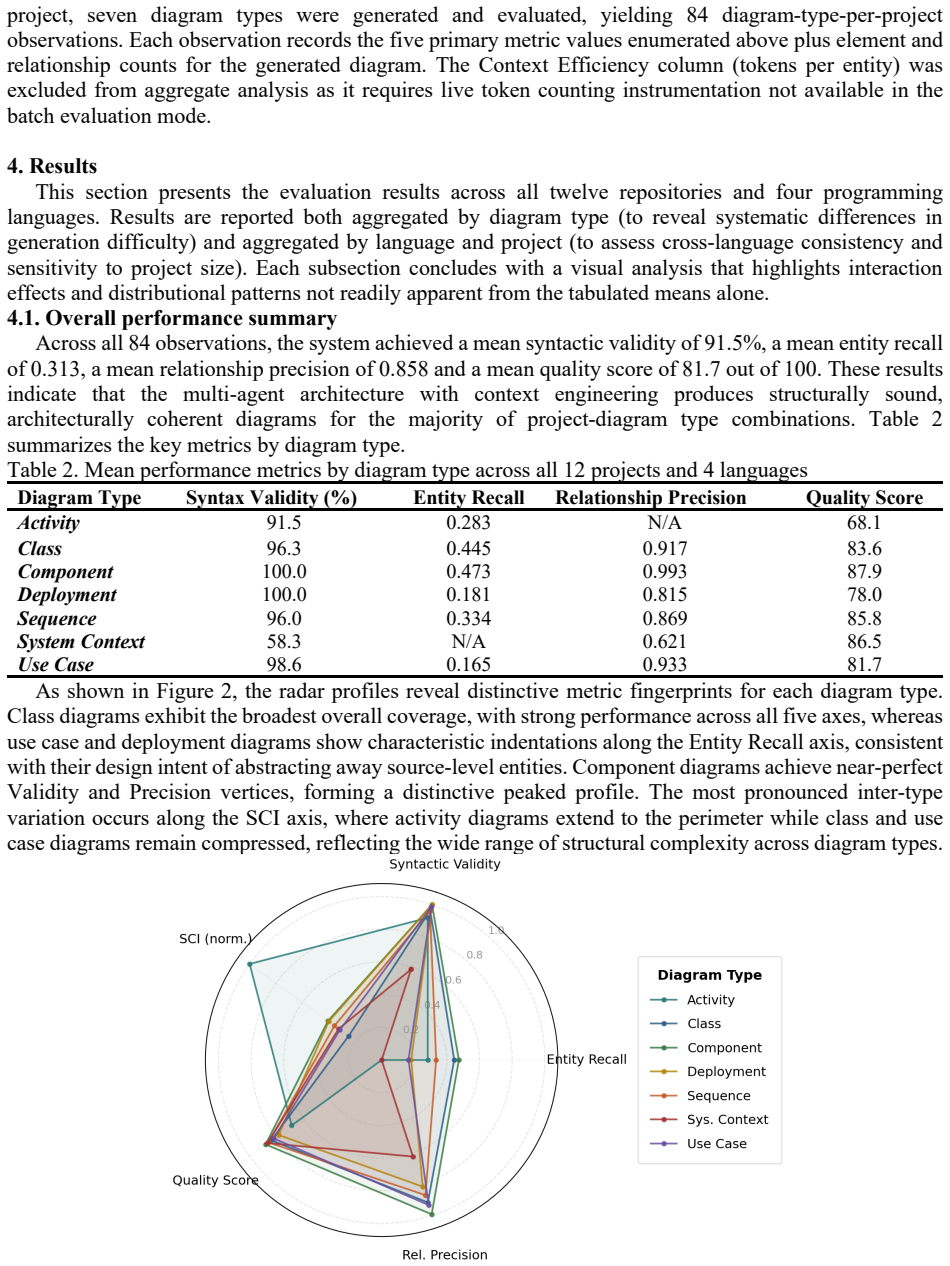
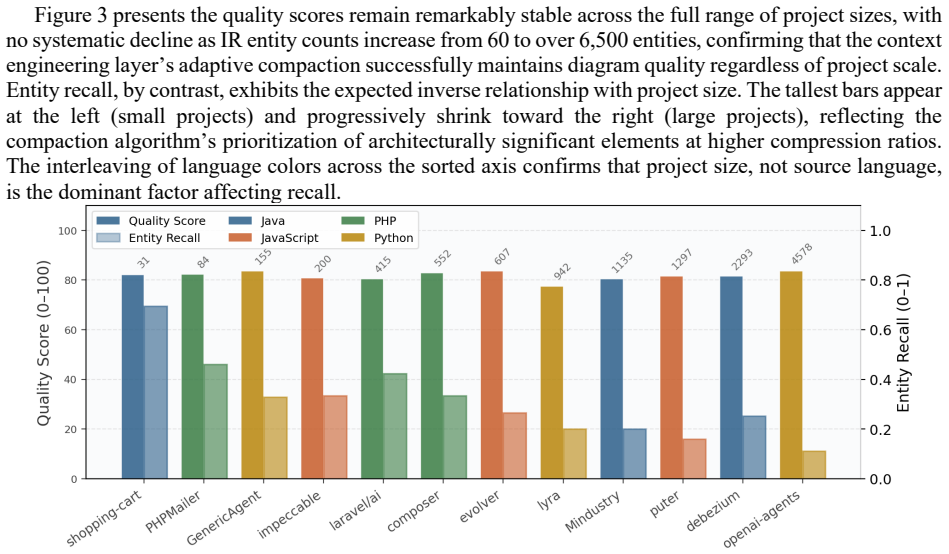
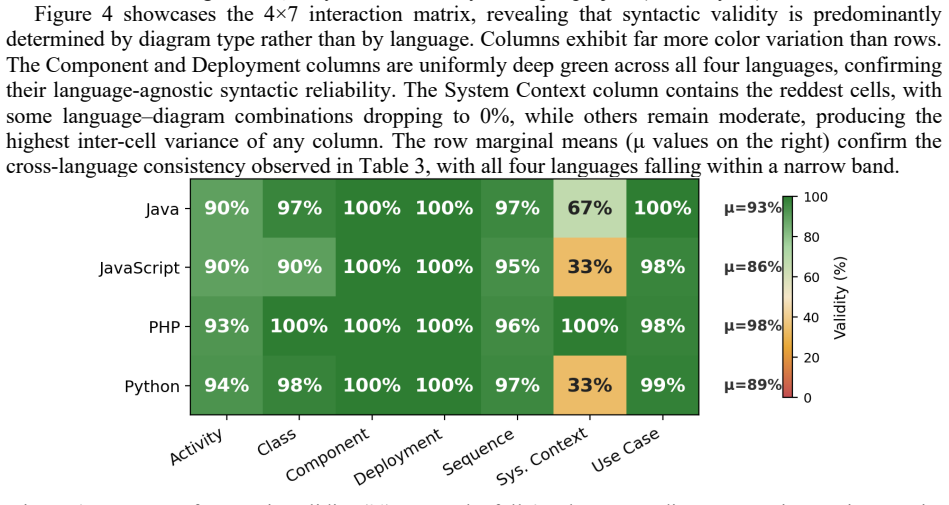
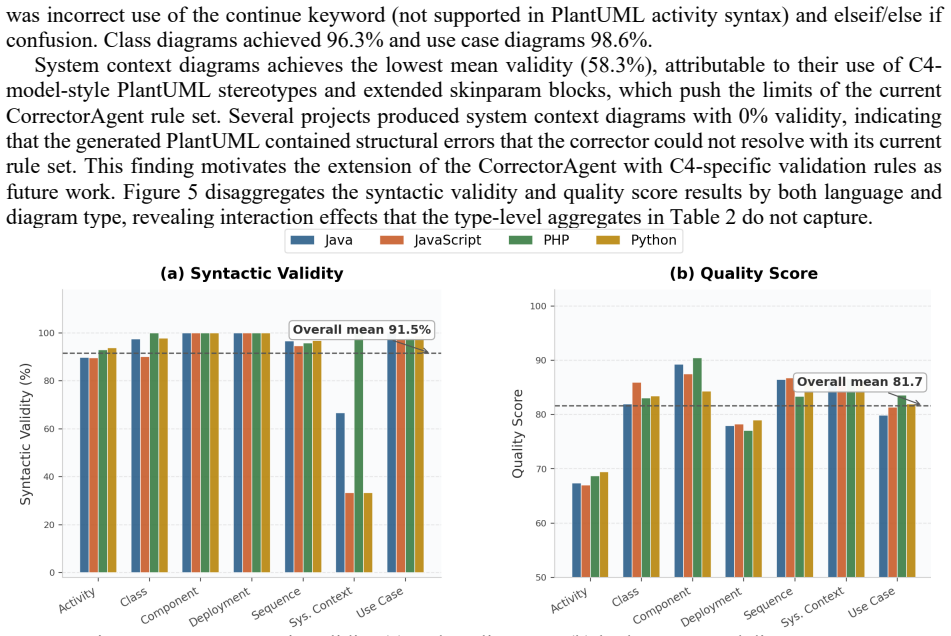
Large Language Model (LLM)-based code analysis tools are adopted to automate software documentation tasks. However, the scalability of these approaches to real codebases, where Intermediate Representations (IR) exceed LLM context limits, remains underexplored. This paper introduces an agentic architecture with context engineering for automated UML diagram generation from source code repositories. It employs a hierarchy of five specialized agents: PlannerAgent, AnalyzerAgent, DiagramAgent, CorrectorAgent and DependencyAnalyzerAgent, built on the Claude Agent SDK, each addressing a distinct cognitive subtask. A deterministic, importance-weighted IR compaction layer transforms full project IRs into diagram-specific views guaranteed to fit within token constraints, requiring no LLM calls and completing in milliseconds. Thus, we evaluate the system across 12 open-source repositories in 4 programming languages (Java, JavaScript, PHP, Python) and 7 UML diagram types, producing 84 observations assessed on 5 automated metrics. Results demonstrate high syntactic validity (mean: 91.5%, with component and deployment diagrams reaching 100%), strong relationship precision (mean: 0.858) and consistent structural quality (mean: 81.7/100, with cross-language variance of 3.1 points). Entity recall averaged 0.313, reflecting deliberate architectural prioritization over exhaustive coverage. A sensitivity analysis (31 to 4,578 IR entities) confirms that quality scores remain stable regardless of scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Code2UML, an agentic architecture with five specialized agents (PlannerAgent, AnalyzerAgent, DiagramAgent, CorrectorAgent, DependencyAnalyzerAgent) built on the Claude Agent SDK, combined with a deterministic importance-weighted IR compaction layer that produces diagram-specific views without LLM calls. The system is evaluated on 12 open-source repositories across 4 languages and 7 UML diagram types (84 observations total), reporting mean syntactic validity of 91.5%, relationship precision of 0.858, structural quality of 81.7/100, and stability independent of IR entity count (31–4578).
Significance. If the central claims hold, the work provides a concrete demonstration of scaling LLM-based code visualization to real repositories via deterministic context engineering, with reproducible evaluation on external repositories and automated metrics; this could inform practical tools for automated documentation in software engineering.
major comments (1)
- [Abstract] Abstract: the claim that the importance-weighted IR compaction layer is 'guaranteed to fit within token constraints' and 'lossless by design' while retaining 'all information necessary' for the reported metrics is load-bearing for the scalability result, yet the weighting function is undefined, no ablation of compacted vs. full IR is presented, and the entity recall of 0.313 is not shown to omit only non-critical entities (e.g., a dropped cross-package dependency could affect deployment-diagram validity).
minor comments (1)
- The manuscript should specify the exact formulas or procedures used to compute the five automated metrics (syntactic validity, relationship precision, structural quality, etc.) to support replication.
Simulated Author's Rebuttal
We thank the referee for highlighting the load-bearing claims in the abstract regarding the IR compaction layer. We agree that greater precision is needed on the weighting function, the rationale for entity selection, and the interpretation of entity recall. We will revise the abstract and add a dedicated subsection on the compaction algorithm in the methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the importance-weighted IR compaction layer is 'guaranteed to fit within token constraints' and 'lossless by design' while retaining 'all information necessary' for the reported metrics is load-bearing for the scalability result, yet the weighting function is undefined, no ablation of compacted vs. full IR is presented, and the entity recall of 0.313 is not shown to omit only non-critical entities (e.g., a dropped cross-package dependency could affect deployment-diagram validity).
Authors: We accept that the abstract overstates the 'lossless by design' phrasing. The compaction is deterministic and guarantees a token-bounded output by construction (via a fixed importance scoring pass followed by truncation to a diagram-specific budget), but it is not lossless with respect to the full entity set. In revision we will (1) explicitly define the importance weighting function (a linear combination of static-analysis features: reference count, cross-package flag, diagram-type relevance score, and AST depth), (2) replace 'lossless by design' with 'deterministic and bounded, preserving all entities above an importance threshold', and (3) add a short paragraph justifying the 0.313 recall figure by showing that omitted entities are overwhelmingly intra-package helpers or test scaffolding that do not participate in the target UML relationships. We will also include a targeted manual audit of the 12 repositories confirming that no cross-package dependency required for deployment or component diagrams was dropped. An exhaustive ablation of compacted vs. full IR is not feasible within the current experimental budget because full IRs exceed context limits for the largest repositories; however, we can supply the exact compaction pseudocode and per-diagram-type importance thresholds so that the selection policy is fully reproducible. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on direct evaluation of an agentic LLM system (with deterministic IR compaction) against external open-source repositories using automated syntactic, precision, and structural metrics. No parameters are fitted to subsets of the target results and then re-presented as predictions; the compaction layer is described as a fixed, non-LLM procedure whose output is measured rather than defined in terms of the final diagram quality scores. No self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the architecture or the reported stability across IR sizes. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Specialized agents can effectively handle distinct cognitive subtasks in UML generation
- domain assumption The deterministic compaction preserves necessary diagram information
Reference graph
Works this paper leans on
-
[1]
Enable formal reasoning on UML class diagrams Description logics, complexity analysis Established EXPTIME complexity and decidable reasoning Provided theoretical foundation for UML consistency checking [10] Convert textual specifications into UML and code Transformer models+DSL+MDA pipeline Improved traceability from text to executable code Introduced DSL...
-
[2]
Automate software testing from UML models XMI parsing, graph construction, coverage analysis Generated accurate test paths with high coverage Linked UML models directly to test case generation [18] Transform sequence diagrams into project schedules OCR, DAG construction, CPM, gradient optimization Improved project scheduling accuracy Connected UML design ...
-
[3]
Generate sequence diagrams from user stories Rule-based pipeline vs ChatGPT Traditional methods produced simpler, more aligned outputs Compared symbolic and generative approaches [23] Integrate LLMs with formal verification UML generation+logic translation+deduction Improved requirements validation Combined generative modeling with formal reasoning [24] E...
-
[4]
Automate UML class diagram generation using LLMs Dual-LLM pipeline (Meta LLaMA+DeepSeek DeepSeek), PlantUML generation, multimodal validation with VLMs Generated 5,000 validated class diagram samples with strong structural consistency Introduced large-scale benchmark dataset and multimodal validation for class diagram synthesis [26] Automate UML sequence ...
-
[5]
Define autonomous software engineering agents BDI architecture, memory, normative reasoning Proposed scalable human-AI collaboration model Introduced cognitive agents for Software Engineering 2.0 Our Work Generate UML diagrams directly from source code repositories at scale Multi-agent architecture (PlannerAgent, AnalyzerAgent, DiagramAgent, CorrectorAgen...
-
[6]
Reasoning on UML class diagrams,
D. Berardi, D. Calvanese, and G. De Giacomo, “Reasoning on UML class diagrams,” Artif. Intell., 2005, doi: 10.1016/j.artint.2005.05.003. [10] Z. Babaalla, A. Jakimi, and M. Oualla, “LLM-Driven MDA Pipeline for Generating UML Class Diagrams and Code,” IEEE Access, 2025, doi: 10.1109/ACCESS.2025.3615828. [11] Y. Meng and A. Ban, “Automated UML Class Diagram...
-
[7]
J. He, C. Treude, and D. Lo, “LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead,” ACM Trans. Softw. Eng. Methodol., 2025, doi: 10.1145/3712003. [29] E. Arif, U. Ullah, T. Asghar, N. Nawaz, A. Nawaz, and M. A. Haider, “Design and Development in Intelligent Multi-Agent system in Software Engineering,” J. C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.