NudgeVAD: Language-Nudged End-to-End Driving via FiLM Residuals
Pith reviewed 2026-06-30 13:33 UTC · model grok-4.3
The pith
Language nudges improve end-to-end driving only when high-level commands are unreliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
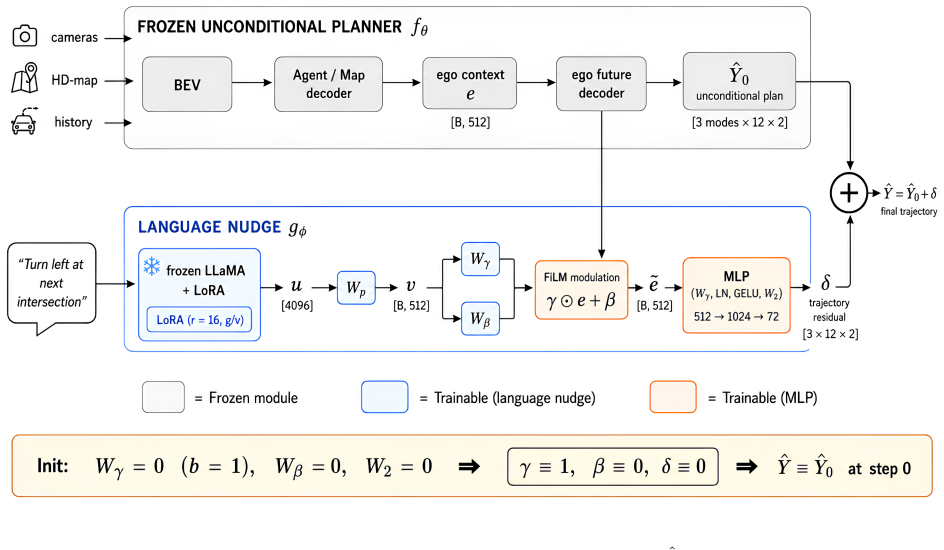
NudgeVAD demonstrates that language is not universally additive for end-to-end driving; it is most valuable when the categorical command channel is unreliable. With reliable commands, language improves the initial planner but offers little extra gain over VAD-FT (UNCOND). With random commands, detaching text degrades ADE6s to 3.166 m while NudgeVAD with text recovers 2.806 m and outperforms the unconditional baseline by 0.312 m. The framework uses identity-initialized FiLM and a zero-initialized residual head so that learned deviations arise solely from language-conditioned residuals on a frozen planner.
What carries the argument
NudgeVAD residual framework: a frozen base planner plus FiLM-conditioned language residuals initialized to produce zero change at the start.
If this is right
- Language improves the initial planner but becomes nearly redundant with reliable commands when compared to a fine-tuned unconditional model.
- With random commands, language becomes essential and recovers 0.36 m of ADE6s error.
- The residual design guarantees that any performance change is produced only by language-conditioned deviations.
- Conditional usefulness appears clearly only when the evaluation separates reliable from unreliable command regimes.
Where Pith is reading between the lines
- Hybrid planners could monitor command reliability and activate language nudges only below a certain threshold to reduce unnecessary compute.
- The same residual pattern might apply to other control domains where one input channel is sometimes noisy.
- Testing a continuous spectrum of command noise levels could locate the exact reliability point at which language overtakes the categorical channel.
Load-bearing premise
The evaluation along a command-reliability axis with the chosen baselines is sufficient to show language is conditionally useful rather than universally additive.
What would settle it
A replication in which NudgeVAD with text fails to recover the reported ADE6s improvement under random commands or fails to outperform VAD-FT (UNCOND) by the stated margin.
Figures
read the original abstract
Natural-language instructions promise controllable end-to-end driving, but their benefit can be hidden when planners already receive reliable high-level commands. We propose NudgeVAD, a frozen-planner residual framework that uses language as a calibrated nudge to a VAD trajectory. With identity-initialized FiLM and a zero-initialized residual head, NudgeVAD is equivalent to the frozen planner at initialization, so learned deviations arise only from language-conditioned residuals. We evaluate NudgeVAD along a command-reliability axis. With reliable commands, language improves the initial planner but becomes nearly redundant once compared against VAD-FT (UNCOND), a compute-matched VAD model fine-tuned without language. With random commands, however, language becomes essential: detaching text degrades ADE6s to 3.166 m, while NudgeVAD with text recovers 2.806 m and outperforms VAD-FT (UNCOND) by 0.312 m. These results show that language is not universally additive; it is most valuable when the categorical command channel is unreliable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NudgeVAD, a residual framework for language-conditioned end-to-end driving that applies natural-language instructions as a calibrated nudge to a frozen VAD planner via identity-initialized FiLM layers and a zero-initialized residual head. This ensures the model starts equivalent to the base planner. Evaluation is performed along a command-reliability axis (reliable vs. random commands). Under reliable commands, language yields modest gains but becomes nearly redundant relative to VAD-FT (UNCOND), a compute-matched fine-tuned unconditional VAD model. Under random commands, detaching text degrades ADE6s to 3.166 m while NudgeVAD recovers 2.806 m and outperforms VAD-FT (UNCOND) by 0.312 m, supporting the claim that language is conditionally useful rather than universally additive.
Significance. If the empirical comparisons hold, the work provides evidence that language nudging delivers its primary value when high-level categorical commands are unreliable, with implications for efficient integration of controllable inputs in autonomous driving systems. The frozen-planner residual design is a practical engineering contribution that avoids catastrophic forgetting while enabling language-conditioned deviations.
major comments (2)
- [Experiments / Results] Experiments / Results (abstract and § on evaluation): The central claim that language is 'most valuable when the categorical command channel is unreliable' rests on the reported ADE6s gap of 0.312 m under random commands and the statement of near-redundancy under reliable commands. However, no explicit table or deltas are provided comparing language-enabled vs. UNCOND models across both regimes, nor confirmation that VAD-FT (UNCOND) was fine-tuned and evaluated under identical random-command perturbations (including whether perturbation occurs only at test time).
- [Method and Experiments] Method and Experiments: NudgeVAD keeps the planner frozen while VAD-FT (UNCOND) fine-tunes the entire model. This introduces a potential confound between the residual-language conditioning mechanism and the effects of full fine-tuning, undermining direct attribution of the 0.312 m gap to language alone even if compute is matched.
minor comments (2)
- [Abstract / Results] Abstract and results: No error bars, standard deviations, or multi-seed statistics are reported for the ADE6s figures (e.g., 2.806 m, 3.166 m), reducing confidence in the stability of the 0.312 m gap.
- [Abstract] Evaluation protocol: Dataset details, command distribution parameters, and exact definition of 'random commands' are not summarized in the abstract, making it harder to assess generalizability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Experiments / Results] Experiments / Results (abstract and § on evaluation): The central claim that language is 'most valuable when the categorical command channel is unreliable' rests on the reported ADE6s gap of 0.312 m under random commands and the statement of near-redundancy under reliable commands. However, no explicit table or deltas are provided comparing language-enabled vs. UNCOND models across both regimes, nor confirmation that VAD-FT (UNCOND) was fine-tuned and evaluated under identical random-command perturbations (including whether perturbation occurs only at test time).
Authors: We agree an explicit table would improve readability. In revision we will add a table reporting ADE6s (with deltas) for NudgeVAD, detached-text, and VAD-FT (UNCOND) under both reliable and random regimes. VAD-FT (UNCOND) was fine-tuned and evaluated under the identical test-time random-command perturbation protocol used for NudgeVAD; we will add this explicit statement to the experimental setup. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: NudgeVAD keeps the planner frozen while VAD-FT (UNCOND) fine-tunes the entire model. This introduces a potential confound between the residual-language conditioning mechanism and the effects of full fine-tuning, undermining direct attribution of the 0.312 m gap to language alone even if compute is matched.
Authors: The frozen-planner design is deliberate to avoid catastrophic forgetting while still enabling language-conditioned residuals; this is the central engineering contribution. VAD-FT (UNCOND) is presented as a compute-matched unconditional baseline precisely to isolate the incremental value of the language nudge. We will add a paragraph in the method section clarifying this rationale and why the comparison supports attribution to the residual language mechanism. revision: partial
Circularity Check
No significant circularity; empirical results are direct measurements
full rationale
The paper proposes an empirical architecture (NudgeVAD) and reports ADE6s metrics under two command regimes (reliable vs. random). No equations, derivations, or fitted parameters are shown that reduce the reported gains (e.g., 2.806 m vs. 3.166 m) to quantities defined inside the paper by construction. The initialization details (identity FiLM, zero residual head) are design choices that make the model start equivalent to the frozen planner, but this is stated explicitly rather than used to derive a prediction. No self-citations appear in the provided text, and the central claim rests on direct experimental comparisons rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020. 1, 3
2020
-
[2]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hu, Yalu Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yalu Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations (ICLR),
-
[4]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi tugboat Chai, Senyao Du, Tianyuan Lin, Wenhai Wang, Lewei Geng, Hongyang Li, Jiyan He, Jifeng Yu, Jifeng Dai, Yu Wang, and Ping Luo. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14229–14238, 2023. 1
2023
-
[5]
Vad: Vectorized autonomous driving via spatial- temporal graph neural networks
Bo Jiang, Shaoyu Chen, Qing Wang, Wenyu Liu, and Xing- gang Wang. Vad: Vectorized autonomous driving via spatial- temporal graph neural networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8642–8651, 2023. 1, 2, 4
2023
-
[6]
Navigation-guided sparse scene representation for end-to-end autonomous driving
Peidong Li and Dixiao Cui. Navigation-guided sparse scene representation for end-to-end autonomous driving. InInter- national Conference on Learning Representations (ICLR),
-
[7]
Bev- former: Learning bird’s-eye-view representation from multi- camera images via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong Chong, Jifeng Yu, Xiaohui Liang, Yu Qiao Shao, Ping Shen, Wenyu Liu, Jialin Yang, Jie Zhou, and Jifeng Dai. Bev- former: Learning bird’s-eye-view representation from multi- camera images via spatiotemporal transformers. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 1–18, 2022. 1
2022
-
[8]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Du- moulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Con- ference on Artificial Intelligence, 2018. 1, 3
2018
-
[9]
Parthib Roy, Srinivasa Perisetla, Shashank Shriram, Harsha Krishnaswamy, Keskar Aryan, and Ross Greer. doscenes: An autonomous driving dataset with natural language in- struction for human interaction and vision-language naviga- tion.arXiv preprint arXiv:2412.05893, 2024. 1, 3
-
[10]
Sparsedrive: End-to-end au- tonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Hao- ran Wu, and Sifa Zheng. Sparsedrive: End-to-end au- tonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025. 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.