Summoning the Oracle to Slay It: Mitigating Look-Ahead Bias in Financial Backtesting with Large Language Models
Pith reviewed 2026-06-30 12:52 UTC · model grok-4.3
The pith
FinCAD suppresses parametric look-ahead bias in LLM financial backtests by scaling context-aware decoding with memorization estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
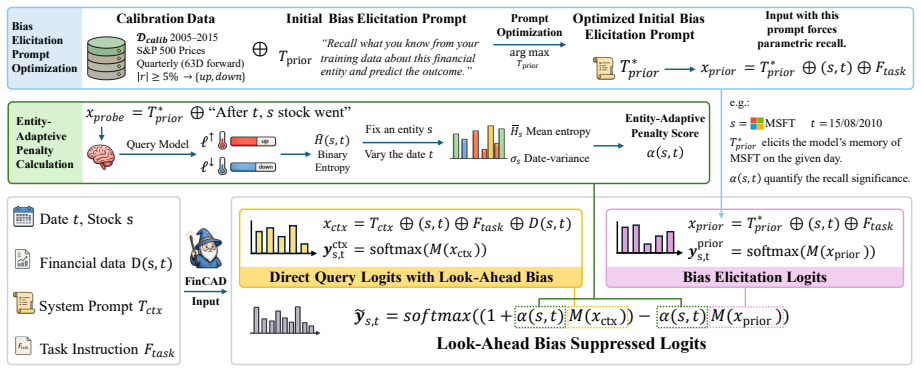
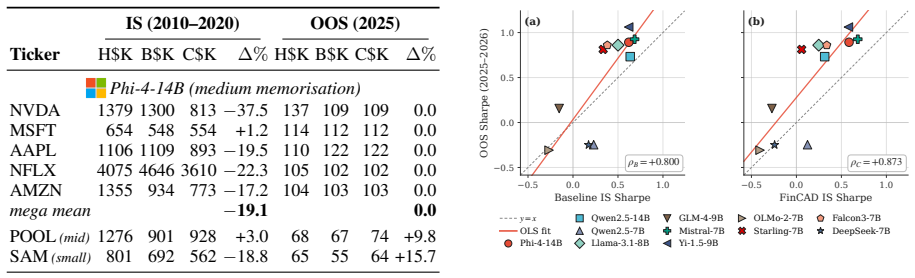
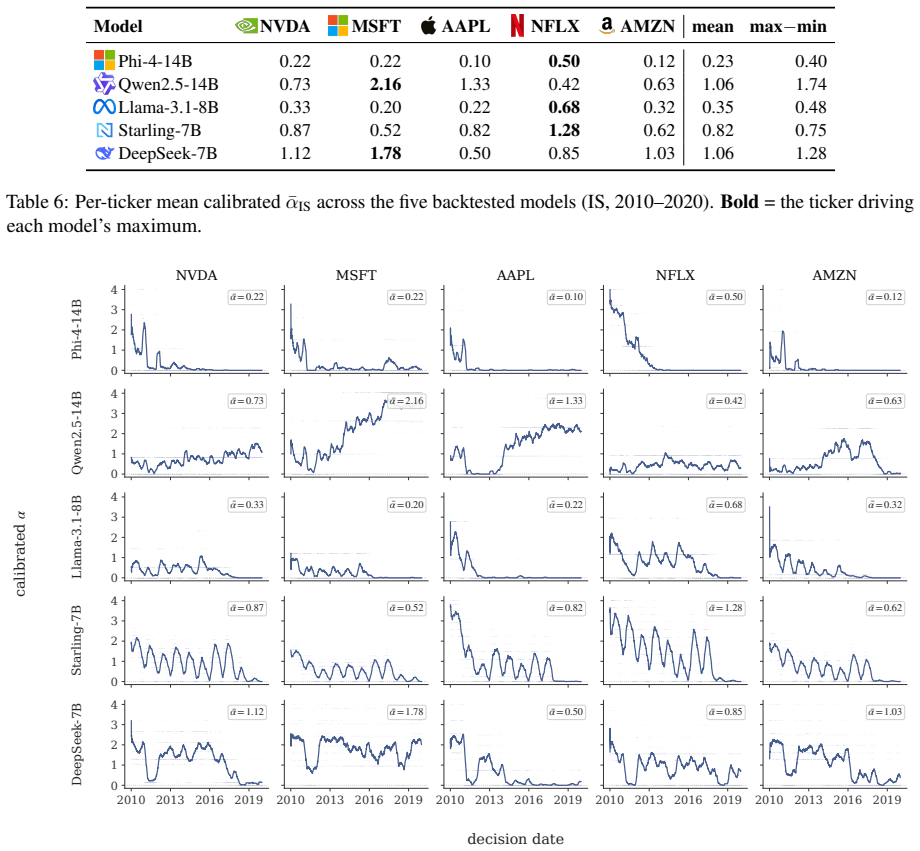
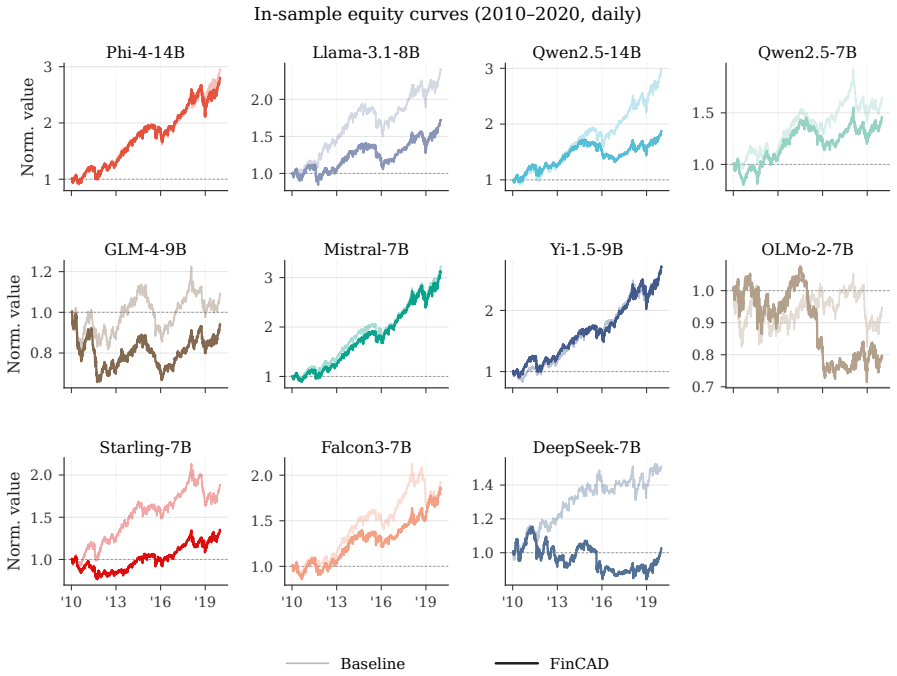
FinCAD pairs an adversarial bias-discovery pipeline that learns a model-specific memory-activating prior prompt with an entity- and date-adaptive rule that scales the CAD strength to per-(entity, date) memorisation, so the penalty fires on memorised in-sample dates and decays to zero out-of-sample. Across five 7-14B LLMs and five mega-cap equities, FinCAD cuts in-sample backtest returns by up to -67.1% on memorised dates while leaving 2025 out-of-sample returns within $8K and Sharpe within 0.10 of baseline, and preserves general-purpose reasoning within 1.7 pts. On an eleven-model leaderboard, it raises the in-sample / out-of-sample Spearman correlation from +0.779 to +0.846, recovering rank
What carries the argument
Context-Aware Decoding adapted with a learned adversarial prior prompt and per-(entity, date) memorization scaling to suppress recall of historical financial outcomes.
If this is right
- In-sample backtest returns drop by up to 67.1 percent on dates the model has memorized.
- Out-of-sample returns and Sharpe ratios remain within $8K and 0.10 of the unadjusted baseline.
- General-purpose reasoning scores stay within 1.7 points of the original model.
- Spearman correlation between in-sample and out-of-sample rankings rises from 0.779 to 0.846 across eleven models.
Where Pith is reading between the lines
- The same adaptive-suppression pattern could be tested on non-financial time-series tasks where LLMs leak later events.
- Pairing FinCAD with retrieval-augmented setups might further limit dependence on parametric memory.
- The memorization-scaling rule could be re-derived from logit differences alone if the adversarial prompt step proves brittle.
Load-bearing premise
The adversarial bias-discovery pipeline produces a prior prompt that selectively activates memory of historical financial outcomes without broadly degrading the model's reasoning, and that the per-(entity, date) memorization estimate used to scale CAD strength can be computed accurately enough to avoid either under-penalizing leakage or over-penalizing genuine signals.
What would settle it
Applying FinCAD to a model and dates where memorization estimates are independently verified as zero, yet still observing large drops in in-sample returns, would falsify the claim that the penalty acts only on memorized content.
Figures
read the original abstract
Backtesting large language models (LLMs) on historical financial data is unreliable because pre-training cuts off after the events happened. An LLM trained in 2024 already "knows" which way 2018-2020 stocks moved. We name this failure parametric look-ahead bias and propose FinCAD, an inference-time adaptation of Context-Aware Decoding that suppresses an LLM's memory of historical outcomes without retraining. FinCAD pairs an adversarial bias-discovery pipeline that learns a model-specific memory-activating prior prompt with an entity- and date-adaptive rule that scales the CAD strength to per-(entity, date) memorisation, so the penalty fires on memorised in-sample dates and decays to zero out-of-sample. Across five 7-14B LLMs and five mega-cap equities, FinCAD cuts in-sample backtest returns by up to -67.1% on memorised dates while leaving 2025 out-of-sample returns within $8K and Sharpe within 0.10 of baseline, and preserves general-purpose reasoning within 1.7 pts. On an eleven-model leaderboard, it raises the in-sample / out-of-sample Spearman correlation from +0.779 to +0.846, recovering rankings that genuinely predict out-of-sample performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FinCAD, an inference-time adaptation of Context-Aware Decoding (CAD) to mitigate parametric look-ahead bias in LLM backtesting on historical financial data. It uses an adversarial bias-discovery pipeline to learn a model-specific memory-activating prior prompt and an entity- and date-adaptive scaling rule for CAD strength based on per-(entity, date) memorization estimates. The paper reports that across five 7-14B LLMs and five mega-cap equities, FinCAD reduces in-sample backtest returns by up to -67.1% on memorized dates, keeps 2025 out-of-sample returns within $8K and Sharpe within 0.10 of baseline, preserves general-purpose reasoning within 1.7 points, and improves the in-sample/out-of-sample Spearman correlation from +0.779 to +0.846 on an eleven-model leaderboard.
Significance. If the results hold and the method selectively suppresses memory of historical outcomes without broadly degrading reasoning or introducing new biases, this would address a critical issue in evaluating LLMs for financial applications, where look-ahead bias can invalidate backtests. The improvement in leaderboard correlation suggests better predictive validity for out-of-sample performance. However, the significance depends on validating the selectivity of the learned prompt and the accuracy of the memorization estimates, which are not directly tested in the provided description.
major comments (2)
- [Abstract] The adversarial bias-discovery pipeline learns the prior prompt via an objective defined in terms of the same historical outcomes used in the backtest evaluation. This creates a circular dependence, as the memory-activating prompt and the per-(entity, date) scaling factor are derived from the test data itself, raising the risk that the observed reductions in in-sample returns reflect fitting to the evaluation rather than genuine bias mitigation.
- [Abstract] The per-(entity, date) memorization estimate used to scale the CAD strength lacks direct validation. If this estimate is noisy or correlated with signal strength, the -67.1% in-sample drop could result from over-penalization of genuine signals rather than targeted removal of look-ahead bias, while the out-of-sample stability and Spearman improvement might be artifacts. The 1.7 pt reasoning preservation is aggregate and does not isolate effects on financial queries.
minor comments (2)
- The abstract reports deltas like $8K and 0.10 Sharpe without error bars, variance estimates, or baseline context for the -67.1% figure, making it difficult to assess if changes are within noise.
- Details on the exact memorization metric, statistical significance tests, and how the adversarial pipeline is implemented (e.g., number of iterations, loss function) are not provided in the abstract, which would be needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We provide point-by-point responses to the major comments below. We believe these points can be addressed through clarifications and additional experiments in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] The adversarial bias-discovery pipeline learns the prior prompt via an objective defined in terms of the same historical outcomes used in the backtest evaluation. This creates a circular dependence, as the memory-activating prompt and the per-(entity, date) scaling factor are derived from the test data itself, raising the risk that the observed reductions in in-sample returns reflect fitting to the evaluation rather than genuine bias mitigation.
Authors: We appreciate this observation regarding potential circularity. The adversarial pipeline is intended to identify prompts that activate the model's parametric memory of historical events, using those events as supervision for prompt discovery. However, to ensure the mitigation is not an artifact of fitting to the evaluation data, we will revise the manuscript to perform the bias-discovery and scaling factor estimation on a separate held-out set of historical dates, disjoint from those used in the reported backtests. This change will be documented in Section 3 and the experimental setup. revision: yes
-
Referee: [Abstract] The per-(entity, date) memorization estimate used to scale the CAD strength lacks direct validation. If this estimate is noisy or correlated with signal strength, the -67.1% in-sample drop could result from over-penalization of genuine signals rather than targeted removal of look-ahead bias, while the out-of-sample stability and Spearman improvement might be artifacts. The 1.7 pt reasoning preservation is aggregate and does not isolate effects on financial queries.
Authors: We agree that direct validation of the memorization estimates is important for confirming selectivity. In the revision, we will include a new experiment that correlates the per-(entity, date) memorization scores with the model's actual recall accuracy on a set of probing questions about historical events. Additionally, we will report results on financial-specific reasoning tasks to isolate the impact on domain-relevant queries. These additions will address concerns about over-penalization and aggregate metrics. revision: yes
Circularity Check
Adaptive CAD scaling and adversarial prior prompt are fitted directly to evaluation outcomes
specific steps
-
fitted input called prediction
[Abstract]
"FinCAD pairs an adversarial bias-discovery pipeline that learns a model-specific memory-activating prior prompt with an entity- and date-adaptive rule that scales the CAD strength to per-(entity, date) memorisation, so the penalty fires on memorised in-sample dates and decays to zero out-of-sample."
The scaling rule and prior prompt are constructed by fitting to per-(entity, date) memorization estimates and adversarial objectives computed on the identical historical outcomes that constitute the in-sample backtest data; the observed -67.1% return cut is therefore produced by construction of the fitted inputs rather than by an external mechanism.
full rationale
The paper's core mitigation (FinCAD) defines the penalty strength via a per-(entity, date) memorization estimate and an adversarial pipeline whose objective is defined on the same historical financial outcomes used for backtesting. This makes the reported in-sample return reduction a direct consequence of the fitting process rather than an independent correction. The out-of-sample stability and Spearman improvement are therefore not independently validated against this dependence. No other circular patterns (self-citation chains, ansatz smuggling, or renaming) are present in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- memory-activating prior prompt
- per-(entity, date) CAD strength scaling factor
axioms (2)
- domain assumption LLMs encode historical financial outcomes in their parameters from pre-training data
- domain assumption Context-aware decoding can be repurposed to suppress specific memorized facts without harming general reasoning
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. 2024. Dola: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth International Conference on Learning Representations. Karl Cobbe, Vineet Kosaraju, Mohammad...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Zheye Deng, Weixiang Yan, Changlong Yu, and Jiashu Wang. 2026. Alphaquanter: An end-to-end tool- augmented agentic reinforcement learning frame- work for stock trading.Preprint, arXiv:2510.14264. Qianggang Ding, Haochen Shi, and Bang Liu. 2024. Tradexpert: Revolutionizing trading...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Suchow, and Khaldoun Khashanah
Finrobot: An open-source ai agent platform for financial applications using large language models. Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Denghui Zhang, Rong Liu, Jordan W. Su- chow, and Khaldoun Khashanah. 2023. Finmem: A performance-enhanced llm trading agent with layered memory and character design.Preprint, arXiv:2311.13743. Yangya...
-
[4]
action": one of
receives a system message and a context body, and must respond with a single JSON object. The system message establishes the role, the look-ahead disclaimer, and the output schema; the context body supplies the price-derived financial summary, the current portfolio state, and the action-space limits. System message You are a portfolio manager for a single...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.