AstroMind: A High-Fidelity Benchmark for Spacecraft Behavior Reasoning Based on Large Language Models
Pith reviewed 2026-06-30 13:08 UTC · model grok-4.3
The pith
AstroMind turns high-fidelity spacecraft simulations into verifiable LLM reasoning tasks for intent, maneuvers, and threats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AstroMind is a physics-grounded benchmark designed to close that gap. It draws on high-fidelity astrodynamics simulations and real observational constraints, converting them into verifiable reasoning problems across three task types: intent inference, maneuver parameter estimation, and threat assessment. Each scenario includes realistic sensing noise and multi-source textual intelligence at varying reliability levels. Evaluation metrics capture both semantic correctness and quantitative consistency under physical constraints.
What carries the argument
Conversion of high-fidelity astrodynamics simulations plus sensing noise and multi-source intelligence into three task families (intent inference, maneuver parameter estimation, threat assessment) scored on semantic and physical-consistency metrics.
If this is right
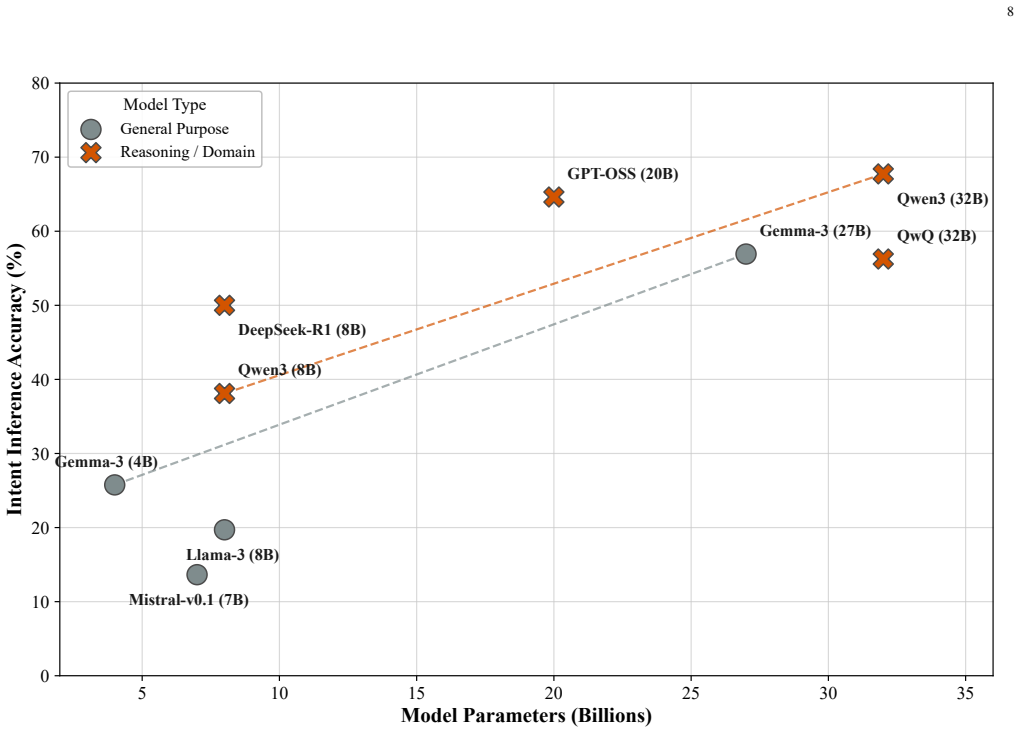
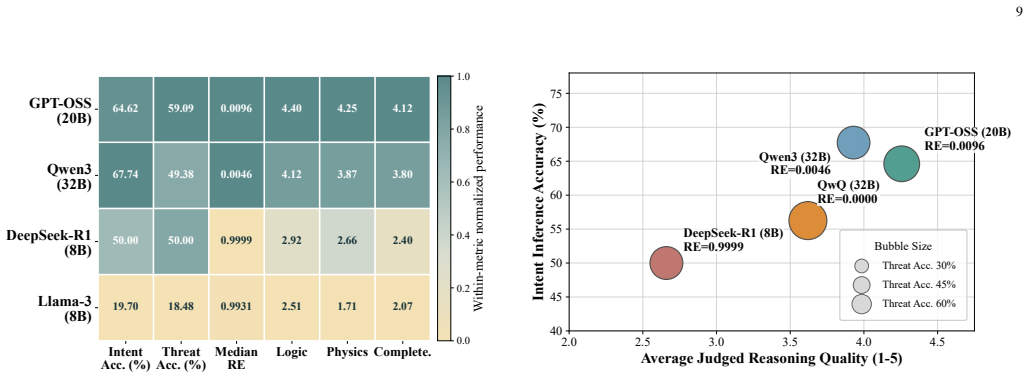
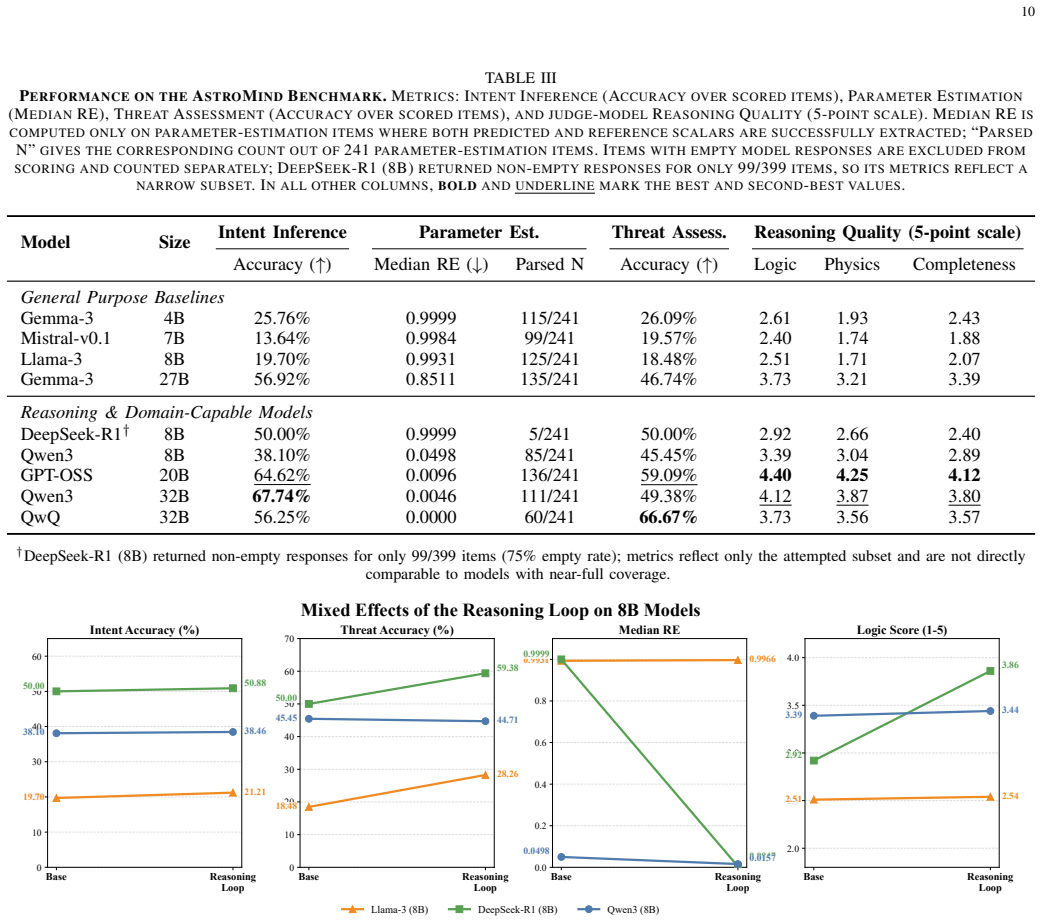
- No single open-weight model leads on every task; Qwen3-32B leads intent inference while QwQ-32B leads threat assessment and error metrics.
- Structured reasoning prompts improve results consistently, with larger gains for models already able to track physical constraints.
- Training data composition and reasoning style affect performance at least as much as raw model size.
- The benchmark supplies a shared test where both physics fidelity and tactical interpretation must hold for success.
Where Pith is reading between the lines
- The same simulation-to-text pipeline could be adapted to test LLMs on other constrained physical domains such as air-traffic or maritime traffic analysis.
- If models improve on AstroMind, they may become usable for initial triage of real orbital events before human analysts review the raw data.
- The finding that prompt structure helps suggests targeted fine-tuning on physics-consistent reasoning traces could close remaining gaps.
Load-bearing premise
High-fidelity simulations with added noise and mixed-reliability text can be turned into problems that actually measure an LLM's ability to reason under physical constraints.
What would settle it
Models achieve near-random accuracy or produce answers that violate basic orbital mechanics on a large fraction of the benchmark items even when given the full scenario data.
Figures

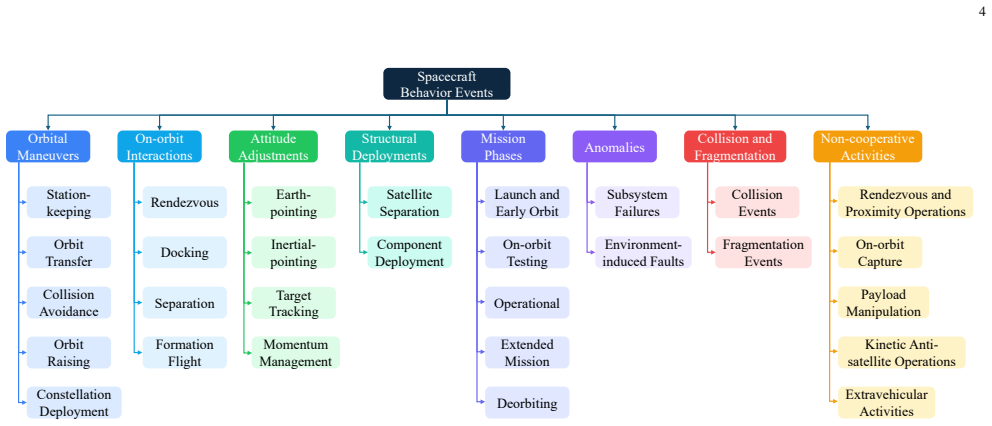
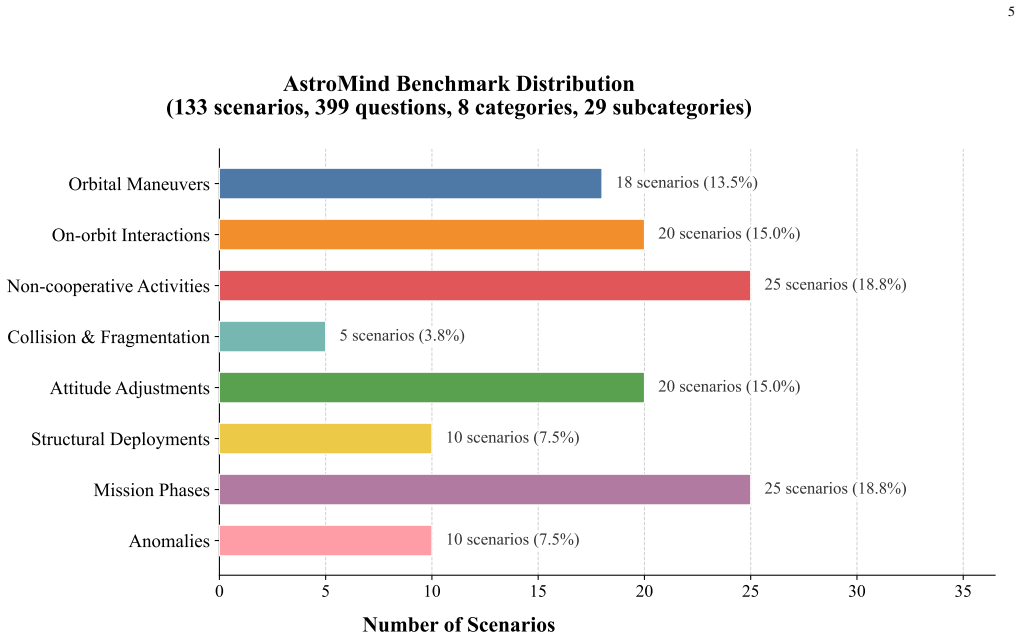
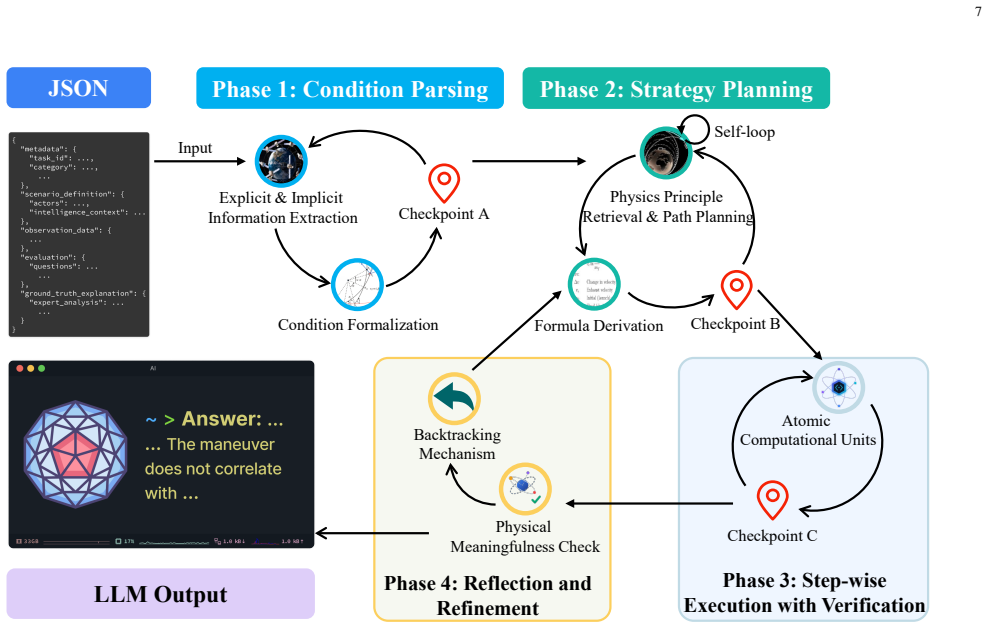
read the original abstract
Understanding why a spacecraft maneuvers -- rather than simply that it did -- is an increasingly important problem for space domain awareness as Earth orbits grow crowded and contested. Current analysis pipelines are built for detection: they are good at picking up that something happened, less good at reasoning about what it means. AstroMind is a physics-grounded benchmark designed to close that gap. It draws on high-fidelity astrodynamics simulations and real observational constraints, converting them into verifiable reasoning problems across three task types: intent inference, maneuver parameter estimation, and threat assessment. Each scenario includes realistic sensing noise and multi-source textual intelligence at varying reliability levels. Evaluation metrics capture both semantic correctness and quantitative consistency under physical constraints. Benchmarking a suite of open-weight models shows no single model dominates every axis: Qwen3 (32B) leads on intent inference accuracy; QwQ (32B) leads on threat assessment and achieves the lowest median relative error on parsed items; GPT-OSS (20B) produces the strongest judged reasoning quality and extracts the most scalar values for parameter estimation (136 of 241 parsed items). Training data composition and reasoning style matter as much as model size. Structured reasoning prompts help consistently across tested 8B models, with larger gains for those that can already track physical constraints. AstroMind gives the field a shared test for a problem where getting the physics right and reading the tactical situation correctly are both required -- neither is sufficient on its own.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AstroMind, a benchmark for LLM-based reasoning on spacecraft behavior in space domain awareness. It converts high-fidelity astrodynamics simulations and real observational constraints into three task types—intent inference, maneuver parameter estimation, and threat assessment—incorporating realistic sensing noise and multi-source textual intelligence of varying reliability. Evaluation uses metrics for semantic correctness and quantitative physical consistency. Benchmarking open-weight models (e.g., Qwen3-32B, QwQ-32B, GPT-OSS-20B) shows no single model dominates; performance depends on training data composition and reasoning style, with structured prompts helping smaller models track constraints.
Significance. If the benchmark construction and metrics are rigorously validated, AstroMind could fill a gap by providing a shared, physics-grounded test for LLMs that must combine semantic understanding with quantitative consistency under physical constraints. This is relevant for applications in contested orbital environments where both tactical interpretation and physical feasibility matter.
major comments (1)
- [Abstract / Methods] The abstract and high-level description provide no details on simulation generation, data splits, metric computation formulas, or error analysis (e.g., how relative error on parsed items or physical consistency is quantified). This makes it impossible to verify the central claim that the tasks meaningfully test physics-constrained reasoning; a methods section with explicit generation pipeline and validation against real constraints is required.
minor comments (2)
- [Evaluation] Clarify the exact number of scenarios per task type and how textual intelligence reliability levels are parameterized.
- [Experiments] Specify the open-weight model versions and prompting templates used for the structured reasoning experiments.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency. We agree that the abstract is high-level by design and that explicit details on benchmark construction are essential for verifying the physics-constrained reasoning claims. We will revise the manuscript with an expanded Methods section.
read point-by-point responses
-
Referee: [Abstract / Methods] The abstract and high-level description provide no details on simulation generation, data splits, metric computation formulas, or error analysis (e.g., how relative error on parsed items or physical consistency is quantified). This makes it impossible to verify the central claim that the tasks meaningfully test physics-constrained reasoning; a methods section with explicit generation pipeline and validation against real constraints is required.
Authors: We acknowledge the concern. The current manuscript includes a Methods section (Section 3) outlining the overall pipeline, but it does not provide the level of explicit formulas, split statistics, or validation steps requested. In revision we will add: (1) the precise simulation generation process (astrodynamics integrator, orbital element sampling ranges, and noise models drawn from real sensor specifications); (2) data split details (scenario counts and stratification criteria); (3) exact metric definitions, including the relative error formula for parsed parameters and the physical consistency scoring procedure; and (4) validation steps comparing generated scenarios against public orbital catalogs. These additions will directly support the central claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces AstroMind as a benchmark constructed from astrodynamics simulations, observational constraints, sensing noise, and textual intelligence. No equations, derivations, fitted parameters, or predictions appear in the abstract or described structure. The work reports evaluation results on existing models rather than deriving new quantities from prior fitted values or self-citations. No load-bearing steps reduce to inputs by construction, making the central claim self-contained as a benchmark definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Esa space environment report 2025,
European Space Agency, “Esa space environment report 2025,” ESA Space Debris Office, Darmstadt, Germany, Tech. Rep. GEN-DB-LOG- 00288-OPS-SD, 2025. [Online]. Available: https://www.sdo.esoc.esa. int/environment report/Space Environment Report latest.pdf
2025
-
[2]
The low earth orbit satellite population and impacts of the spacex starlink constellation,
J. C. McDowell, “The low earth orbit satellite population and impacts of the spacex starlink constellation,”The Astrophysical Journal Letters, vol. 892, no. 2, p. L36, 2020. [Online]. Available: https://doi.org/10.3847/2041-8213/ab8016
-
[3]
Collision frequency of artificial satellites: The creation of a debris belt,
D. J. Kessler and B. G. Cour-Palais, “Collision frequency of artificial satellites: The creation of a debris belt,”Journal of Geophysical Research: Space Physics, vol. 83, no. A6, pp. 2637–2646, 1978. [Online]. Available: https://doi.org/10.1029/JA083iA06p02637
-
[4]
Global counterspace capabilities: An open source assessment,
Secure World Foundation, “Global counterspace capabilities: An open source assessment,” Secure World Foundation (SWF), Tech. Rep., April 2025. [Online]. Available: https://www.swfound.org/ publications-and-reports/2025-global-counterspace-capabilities-report
2025
-
[5]
Space threat assessment 2025,
C. Swope, K. A. Bingen, M. Young, and K. LaFave, “Space threat assessment 2025,” Center for Strategic and International Studies (CSIS), Tech. Rep., April 2025. [Online]. Available: https: //www.csis.org/analysis/space-threat-assessment-2025
2025
-
[6]
Artificial intelligence and machine learning for space domain awareness: Characterizing the impact on mission effectiveness,
L. A. Zhang, K. Langeland, J. Tran, J. Logue, P. Puri, G. Nacouzi, A. Jacques, and G. J. Briggs, “Artificial intelligence and machine learning for space domain awareness: Characterizing the impact on mission effectiveness,” RAND Corporation, Tech. Rep., 2024. [Online]. Available: https://www.rand.org/pubs/research reports/RRA2318-1.html 12
2024
-
[7]
Inferring spacecraft maneuver intention via inverse optimal control,
M. R. Goulet, T. Goulet, K. A. LeGrand, and S. Mou, “Inferring spacecraft maneuver intention via inverse optimal control,” inAIAA SCITECH 2025 Forum. American Institute of Aeronautics and Astronautics, January 2025. [Online]. Available: https://doi.org/10. 2514/6.2025-0982
2025
-
[8]
Survey mode: A review of machine learning in resident space object detection and characterization,
K. Tsaprailis, G. Choumos, V . Lappas, and C. Kontoes, “Survey mode: A review of machine learning in resident space object detection and characterization,” inAIAA SCITECH 2024 Forum, January 2024. [Online]. Available: https://doi.org/10.2514/6.2024-2065
-
[9]
Time-llm: Time series forecasting by reprogramming large language models,
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan, and Q. Wen, “Time-llm: Time series forecasting by reprogramming large language models,” inInternational Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://openreview.net/forum?id=Unb5CVPtae
2024
-
[10]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” inProceedings of the International Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[11]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams,
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large-scale open domain question answering dataset from medical exams,”Applied Sciences, vol. 11, no. 14, p. 6421, 2021. [Online]. Available: https://doi.org/10. 3390/app11146421
2021
-
[12]
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models,
N. Guha, J. Nyarko, D. E. Ho, C. R ´e, A. Chilton, A. Narayana, A. Chohlas-Wood, A. Peters, B. Waldonet al., “Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models,” inAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), Datasets and Benchmarks Track, 2023. [Online]. Available: https://openrev...
2023
-
[13]
Orbit estimation of a continuously thrusting spacecraft using variable dimension filters,
G. M. Goff, J. T. Black, and J. A. Beck, “Orbit estimation of a continuously thrusting spacecraft using variable dimension filters,” Journal of Guidance, Control, and Dynamics, vol. 38, no. 12, pp. 2390– 2404, 2015. [Online]. Available: https://doi.org/10.2514/1.G001091
-
[14]
B. D. Tapley, B. E. Schutz, and G. H. Born,Statistical Orbit Determi- nation. Elsevier, 2004, the standard textbook for orbit determination and Kalman filters. [Online]. Available: https://shop.elsevier.com/books/ statistical-orbit-determination/tapley/978-0-12-683630-1
2004
-
[15]
Satellite maneuver detection and estimation with optical survey observations,
A. Pastor, G. Escribano Bl ´azquez, M. Sanjurjo-Rivo, and D. Escobar, “Satellite maneuver detection and estimation with optical survey observations,”The Journal of the Astronautical Sciences, vol. 69, pp. 879–917, 2022. [Online]. Available: https://doi.org/10.1007/s40295-022-00311-5
-
[16]
L. Porcelli, A. Pastor, A. Cano, G. Escribano Bl ´azquez, M. Sanjurjo- Rivo, D. Escobar, and P. Di Lizia, “Satellite maneuver detection and estimation with radar survey observations,”Acta Astronautica, vol. 201, pp. 274–287, 2022. [Online]. Available: https://doi.org/10.1016/j. actaastro.2022.08.021
work page doi:10.1016/j 2022
-
[17]
Advances in Space Research72(4), 907–921 (2023) https://doi.org/10.1016/j.asr
G. Escribano Bl ´azquez, M. Sanjurjo-Rivo, J. A. Siminski, A. Pastor, and D. Escobar, “Automatic maneuver detection and tracking of space objects in optical survey scenarios based on stochastic hybrid systems formulation,”Advances in Space Research, vol. 69, no. 9, pp. 3460–3477, 2022. [Online]. Available: https://doi.org/10.1016/j.asr. 2022.02.034
-
[18]
A review of anomaly detection in spacecraft telemetry data,
A. Fejjari, A. Delavault, R. Camilleri, and G. Valentino, “A review of anomaly detection in spacecraft telemetry data,”Applied Sciences, vol. 15, no. 10, p. 5653, 2025. [Online]. Available: https://doi.org/10.3390/app15105653
-
[19]
H. Liu, P. Guo, S. Yang, Z. Jiang, Q. Hu, and D. Li, “Spaceseg: A high-precision intelligent perception segmentation method for multi- spacecraft on-orbit targets,”arXiv preprint arXiv:2503.11133, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.11133
-
[20]
Orbitzoo: Real orbital systems challenges for reinforcement learning,
A. Oliveira, K. Dyreby, F. M. Caldas, and C. Soares, “Orbitzoo: Real orbital systems challenges for reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025. [Online]. Available: https://openreview.net/forum?id=oElWLpkOux
2025
-
[21]
Superglue: A stickier benchmark for general-purpose language understanding systems,
A. Wang, Y . Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “Superglue: A stickier benchmark for general-purpose language understanding systems,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019. [Online]. Available: https://papers.nips.cc/paper/8589-superglue
2019
-
[22]
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohlet al., “Large language models encode clinical knowledge,”Nature, vol. 620, no. 7972, pp. 172–180, 2023. [Online]. Available: https: //doi.org/10.1038/s41586-023-06291-2
-
[23]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Evaluating Large Language Models Trained on Code
[Online]. Available: https://doi.org/10.48550/arXiv.2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[25]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 24 824–24 837. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2022/hash/ 9d5609613524e...
2022
-
[26]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/hash/ 271db9922b8d1f4dd7aaef84ed5ac703-Abstract-Con...
2023
-
[27]
Solving quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, S. Imanol, T. Gutman- Soloet al., “Solving quantitative reasoning problems with language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 3843–3857. [Online]. Available: https://proceedings.neurips.cc/paper files/paper...
2022
-
[28]
Nature Reviews Physics , author =
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021. [Online]. Available: https://doi.org/10.1038/s42254-021-00314-5
-
[29]
C. Spearman, “”general intelligence,” objectively determined and measured,”The American Journal of Psychology, vol. 15, no. 2, pp. 201–292, 1904. [Online]. Available: https://doi.org/10.2307/1412107
-
[30]
Gardner,Frames of mind: The theory of multiple intelligences
H. Gardner,Frames of mind: The theory of multiple intelligences. Basic Books, 1983. [Online]. Available: https://books.google.com/ books/about/Frames of Mind.html?id=ObgOAAAAQAAJ
1983
-
[31]
Joint Publication 3-14: Space Operations,
Joint Chiefs of Staff, “Joint Publication 3-14: Space Operations,” 2020, original publication dated April 10, 2018; incorporating Change 1 dated October 26, 2020
2020
-
[32]
Orbit Data Messages,
Consultative Committee for Space Data Systems, “Orbit Data Messages,” CCSDS, Blue Book CCSDS 502.0-B-3, 2023, recommended Standard. [Online]. Available: https://public.ccsds.org/Pubs/502x0b3e1. pdf
2023
-
[33]
Recommended Design and Opera- tional Practices,
Consortium for Execution of Rendezvous and Ser- vicing Operations, “Recommended Design and Opera- tional Practices,” CONFERS, Tech. Rep., 2022. [Online]. Available: https://cdn.ymaws.com/satelliteconfers.org/resource/resmgr/ confers publications/confers operating practices .pdf
2022
-
[34]
K. Bhattarai, I. Y . Oh, J. M. Sierra, J. Tang, P. R. O. Payne, Z. Abrams, and A. M. Lai, “Leveraging gpt-4 for identifying cancer phenotypes in electronic health records: a performance comparison between gpt-4, gpt-3.5-turbo, flan-t5, llama-3-8b, and spacy’s rule-based and machine learning-based methods,”JAMIA Open, vol. 7, no. 3, p. ooae060, 2024. [Onli...
-
[35]
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, S. Wang, K. Zhang, Y . Wang, W. Gao, L. Ni, and J. Guo, “A survey on llm-as-a-judge,”The Innovation, p. 101253, 2026, originally released as arXiv:2411.15594. [Online]. Available: https://doi.org/10.1016/j.xinn.2025.101253
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.xinn.2025.101253 2026
-
[36]
P ´olya,How to Solve It: A New Aspect of Mathematical Method, ser
G. P ´olya,How to Solve It: A New Aspect of Mathematical Method, ser. Princeton Science Library. Princeton University Press, 2014
2014
-
[37]
L. Diana and P. Dini, “Review on hardware devices and software techniques enabling neural network inference onboard satellites,” Remote Sensing, vol. 16, no. 21, p. 3957, 2024. [Online]. Available: https://doi.org/10.3390/rs16213957
-
[38]
A comprehensive survey of orbital edge computing: Systems, applications, and algorithms,
Z. Yin, C. Wu, C. Guo, Y . Li, M. Xu, W. Gao, and C. Chi, “A comprehensive survey of orbital edge computing: Systems, applications, and algorithms,”Chinese Journal of Aeronautics, vol. 38, no. 7, 2025. [Online]. Available: https://doi.org/10.1016/j.cja.2024.11.026
-
[39]
Fractionated spacecraft: The new sprout in distributed space systems,
J. Guo, D. C. Maessen, and E. Gill, “Fractionated spacecraft: The new sprout in distributed space systems,” inProceedings of the 60th International Astronautical Congress, 2009, iAC Paper IAC-09-D1.1.4
2009
-
[40]
Satellite edge artificial intelligence with large models: Architectures and technologies,
Y . Shi, J. Zhu, C. Jiang, L. Kuang, and K. B. Letaief, “Satellite edge artificial intelligence with large models: Architectures and technologies,”Science China Information Sciences, vol. 68, no. 7,
-
[41]
Available: https://doi.org/10.1007/s11432-024-4425-y
[Online]. Available: https://doi.org/10.1007/s11432-024-4425-y
-
[42]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b & gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.