DexSIM: Real-time Dexterous Simulation with Unified Causal Video Diffusion
Pith reviewed 2026-06-30 13:48 UTC · model grok-4.3
The pith
DexSIM simulates real-time dexterous hand manipulation by embedding action trajectories into a causal video diffusion model with a spatial cache for memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
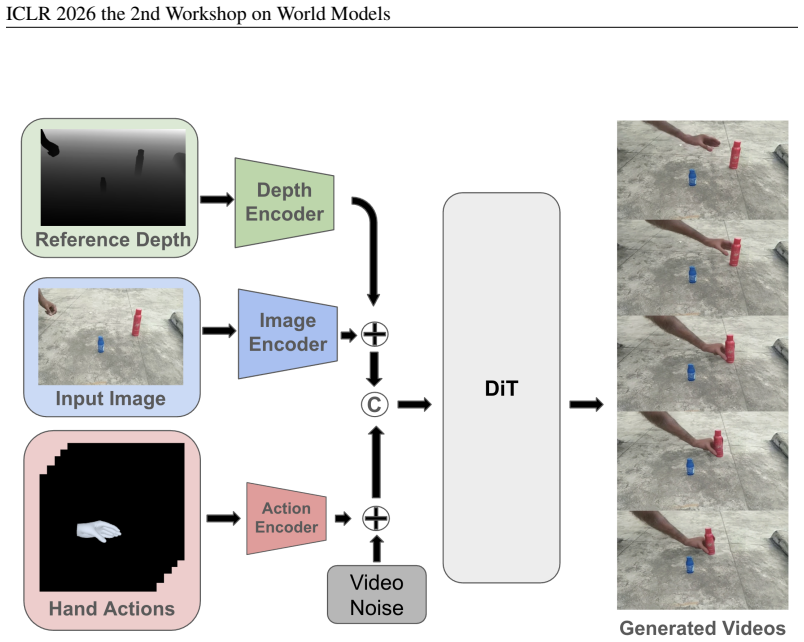
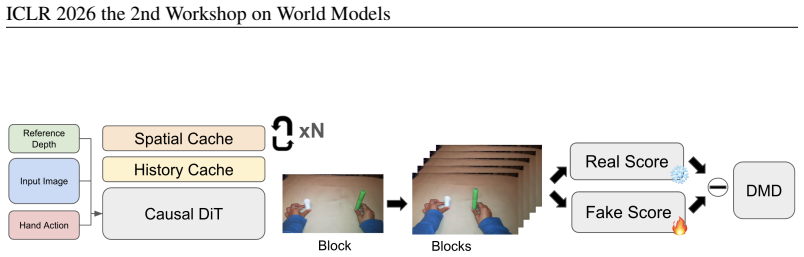
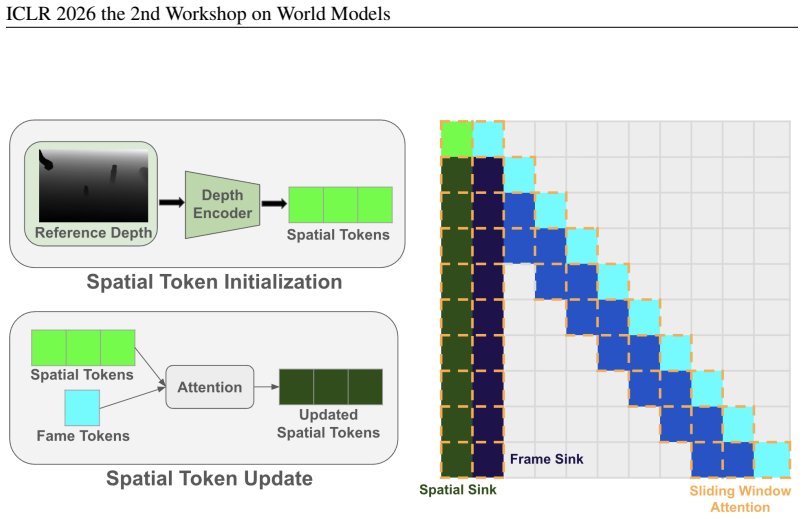
A bi-directional video diffusion model is first trained by jointly embedding hand action trajectories and video in a unified feature space with Gaussian heatmap hand encoding; this is followed by roll-out based autoregressive training that uses an updated spatial cache as attention sink to maintain long-term consistency and 3D-aware dexterous manipulation simulation.
What carries the argument
Two-stage training that unifies hand trajectory and video features inside a bi-directional diffusion model, then applies autoregressive roll-outs with a spatial cache serving as attention sink.
If this is right
- DexSIM exceeds baseline performance on pixel similarity, semantic similarity, motion fidelity, and hand projection accuracy.
- The model enables hand motion transfer between different scenes.
- Simulation runs at 15.24 FPS, supporting real-time interactive use.
Where Pith is reading between the lines
- If the spatial cache alone suffices for consistency, the same mechanism could be tested on longer sequences or multi-object scenes without added geometry.
- The unified trajectory-video space might transfer to non-hand manipulation tasks if the Gaussian encoding is generalized.
- Real-time output could be plugged directly into reinforcement-learning loops for policy training on dexterous tasks.
Load-bearing premise
Embedding hand action trajectories and video together in one feature space plus an updated spatial cache as attention sink will produce long-term 3D-aware consistency without explicit 3D reconstruction or extra geometric constraints.
What would settle it
Measure whether generated hand-object videos maintain consistent 3D geometry and hand projection accuracy across dozens of frames when the spatial cache is removed or when the joint embedding is replaced by separate conditioning.
Figures



read the original abstract
Recent progress of video diffusion models have enabled extensive simulation of the physical world. While simulation with hand object interaction has been less explored. We propose DexSIM, a dexterous simulation framework for simulating dexterous manipulation in real-time. While previous works utilizing video diffusion and 3D reconstruction focus on navigation, dexterous manipulation has been limited while it has extensive applications for creating interactive experiences with the simulated world and for generating synthetic data for robotics. Existing methods lack real-time interactivity and long-term spatial consistency and memory. We propose a 2-stage training framework for DexSIM. First we train a bi-directional video diffusion model by jointly embedding the hand action trajectory and video in a unified feature space. We utilize gaussian heatmap hand encoding for more accurate hand representation. Then we conduct a roll-out based autoregressive training with updated spatial cache as attention sink for spatial memory, which improves long-term consistency and 3D aware dexterous manipulation simulation. DexSIM outperforms the baseline on pixel and semantic similarity, motion fidelity, and hand projection accuracy. It also allows new applications such as hand motion transfer and runs at 15.24 FPS real-time interactivity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DexSIM, a real-time dexterous simulation framework for hand-object manipulation based on video diffusion models. It proposes a two-stage training procedure: first, a bi-directional diffusion model that jointly embeds hand action trajectories (via Gaussian heatmap encoding) and video frames into a unified feature space; second, autoregressive roll-out training that uses an updated spatial cache as an attention sink to maintain long-term consistency. The paper claims this yields superior performance over baselines on pixel/semantic similarity, motion fidelity, and hand projection accuracy, enables applications such as hand motion transfer, and achieves real-time operation at 15.24 FPS without explicit 3D reconstruction.
Significance. If the empirical claims hold and the mechanism demonstrably enforces 3D-aware consistency, DexSIM would address a notable gap in applying diffusion models to interactive dexterous simulation, with potential utility for robotics data generation and real-time virtual environments. The provision of real-time interactivity and new downstream applications would be a concrete contribution if supported by reproducible experiments.
major comments (2)
- [Abstract and §3] Abstract and §3 (training procedure): the central claim that the unified embedding plus spatial-cache attention sink produces '3D aware dexterous manipulation simulation' and long-term spatial consistency rests on an unverified implicit effect. No 3D geometric metrics, hand-object penetration rates, or ablation against explicit 3D constraints are referenced; 2D appearance coherence alone does not guarantee the claimed 3D structure, directly undermining the outperformance statements on hand projection accuracy and 3D awareness.
- [Abstract] Abstract: the statements that DexSIM 'outperforms the baseline on pixel and semantic similarity, motion fidelity, and hand projection accuracy' and runs at 15.24 FPS cannot be assessed because no quantitative tables, datasets, baselines, or experimental protocol appear in the provided text. Without these load-bearing results, the superiority claims remain unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'unified causal video diffusion' in the title is not explained in the abstract; clarify whether the model is causal during inference or only during the second-stage roll-out.
- [Abstract] Abstract: 'gaussian heatmap hand encoding' is introduced without a reference or brief description of how the heatmaps are generated or injected into the diffusion U-Net.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (training procedure): the central claim that the unified embedding plus spatial-cache attention sink produces '3D aware dexterous manipulation simulation' and long-term spatial consistency rests on an unverified implicit effect. No 3D geometric metrics, hand-object penetration rates, or ablation against explicit 3D constraints are referenced; 2D appearance coherence alone does not guarantee the claimed 3D structure, directly undermining the outperformance statements on hand projection accuracy and 3D awareness.
Authors: We agree that explicit 3D geometric metrics such as penetration rates or direct comparisons to 3D-constrained methods would provide stronger evidence. The hand projection accuracy metric is presented as a proxy for 3D consistency, and the spatial cache is intended to enforce long-term spatial coherence that supports 3D-aware behavior in the generated videos. We will revise §3 and the discussion to clarify this distinction and add an ablation isolating the contribution of the spatial cache to consistency. revision: partial
-
Referee: [Abstract] Abstract: the statements that DexSIM 'outperforms the baseline on pixel and semantic similarity, motion fidelity, and hand projection accuracy' and runs at 15.24 FPS cannot be assessed because no quantitative tables, datasets, baselines, or experimental protocol appear in the provided text. Without these load-bearing results, the superiority claims remain unverified.
Authors: The full manuscript contains Section 4 with the requested quantitative tables (including comparisons on the listed metrics), dataset details, baseline descriptions, and the full evaluation protocol. The reported FPS was measured under the conditions stated in the experiments. We will add explicit cross-references from the abstract to Section 4 and include a concise summary of key results in the abstract for the revised version. revision: yes
Circularity Check
No significant circularity; method is empirical training procedure
full rationale
The paper describes a two-stage training procedure for a bi-directional video diffusion model (joint embedding of hand trajectories via Gaussian heatmaps, followed by autoregressive rollout with spatial cache as attention sink) and reports empirical outperformance on similarity, fidelity, and accuracy metrics. No equations, first-principles derivations, or predictions are shown that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims rest on the training architecture and observed results rather than tautological reductions, making the chain self-contained without circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video diffusion models can be conditioned on hand action trajectories via joint embedding
- domain assumption Spatial cache as attention sink maintains long-term consistency in autoregressive roll-outs
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
9 ICLR 2026 the 2nd Workshop on World Models Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators
2026
-
[2]
Raktim Gautam Goswami, Amir Bar, David Fan, Tsung-Yen Yang, Gaoyue Zhou, Prashanth Krishnamurthy, Michael Rabbat, Farshad Khorrami, and Yann LeCun. World models can leverage human videos for dexter- ous manipulation.arXiv preprint arXiv:2512.13644,
-
[3]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations. Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei- Fei. Pointworld: Scaling 3d world models for in-the-w...
-
[5]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025a. Yubo Huang, Hailong Guo, Fangtai Wu, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, et al. Live avatar: Streaming real-time audio-dri...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. InProc. arXiv:2410.11831,
-
[7]
Dexterous world models.arXiv preprint arXiv:2512.17907,
Byungjun Kim, Taeksoo Kim, Junyoung Lee, and Hanbyul Joo. Dexterous world models.arXiv preprint arXiv:2512.17907,
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URL https://arxiv.org/abs/2506.15742. Runjia Li, Moayed Haji-Ali, Ashkan Mirzaei, Chaoyang Wang, Arpit Sahni, Ivan Skorokhodov, Aliaksandr Siarohin, Tomas Jakab, Junlin Han, Sergey Tulyakov, et al. Egoedit: Dataset, real-time streaming model, and benchmark for egocentric video editing.arXiv preprint arXiv:2512.06065,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Motionstream: Real-time video generation with interactive motion controls,
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, and Xun Huang. Mo- tionstream: Real-time video generation with interactive motion controls.arXiv preprint arXiv:2511.01266,
-
[11]
Playerone: Egocentric world simulator.arXiv preprint arXiv:2506.09995, 2025
Yuanpeng Tu, Hao Luo, Xi Chen, Xiang Bai, Fan Wang, and Hengshuang Zhao. Playerone: Egocentric world simulator.arXiv preprint arXiv:2506.09995,
-
[12]
Wan: Open and Advanced Large-Scale Video Generative Models
10 ICLR 2026 the 2nd Workshop on World Models Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Rui...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Real-time motion-controllable autoregressive video diffusion.arXiv preprint arXiv:2510.08131,
Kesen Zhao, Jiaxin Shi, Beier Zhu, Junbao Zhou, Xiaolong Shen, Yuan Zhou, Qianru Sun, and Hanwang Zhang. Real-time motion-controllable autoregressive video diffusion.arXiv preprint arXiv:2510.08131,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.