AVBench: Human-Aligned and Automated Evaluation Benchmark for Audio-Video Generative Models
Pith reviewed 2026-06-30 13:32 UTC · model grok-4.3
The pith
AVBench supplies continuous scores for audio-video generations by deriving probabilistic confidence from fine-tuned binary evaluators trained on perturbed real videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
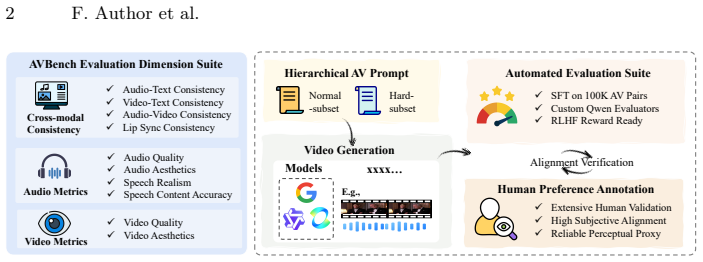
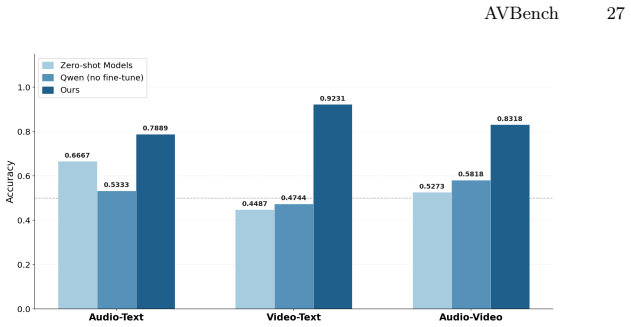
AVBench derives continuous evaluation scores from the model's prediction confidence on binary decisions for ten human-centric dimensions in audio-video generation, achieved by fine-tuning evaluators on pairs constructed from real-world videos with controlled perturbations, enabling reliable detection of cross-modal inconsistencies and closer alignment with human judgment than traditional VQA-style methods.
What carries the argument
Specialized evaluators fine-tuned via preference learning on perturbed real-video pairs, using probabilistic scoring from binary decision confidence.
If this is right
- Provides automated evaluation covering ten dimensions of visual quality, audio quality, and multi-level consistency for human-centric AV scenarios.
- Enables data filtering by identifying high-quality generated samples.
- Supplies a differentiable reward signal usable in RLHF pipelines for AV model improvement.
- Captures human-related details that preset generic multimodal LLM evaluations overlook.
Where Pith is reading between the lines
- The perturbation-based training data construction could be adapted to create evaluators for other multimodal generation tasks such as text-to-3D or image-to-video.
- Continuous scores from the same evaluators might serve as an auxiliary loss term during the training of AV generators themselves.
- If the evaluators generalize across different base models, AVBench could function as a standardized leaderboard metric without repeated human annotation.
Load-bearing premise
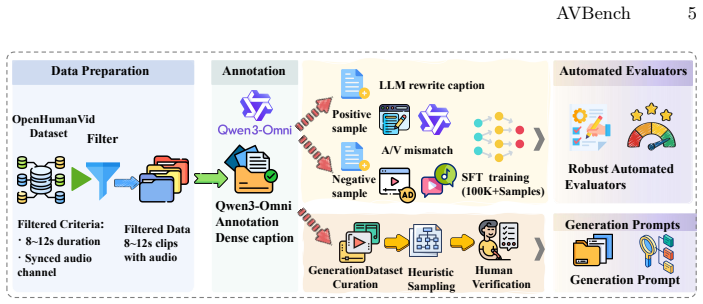
Transforming real-world videos into diverse training pairs with controlled perturbations supplies high-quality supervision that allows the fine-tuned evaluators to reliably detect subtle cross-modal inconsistencies in generated AV content.
What would settle it
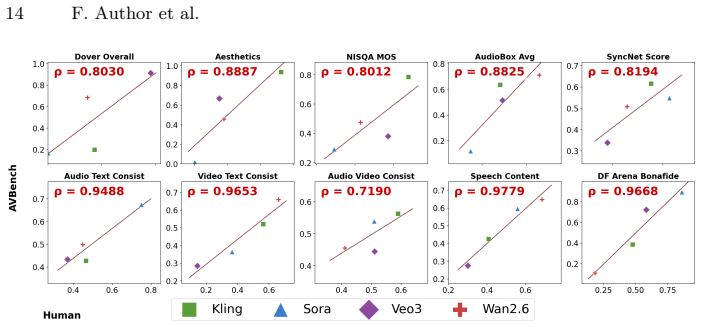
Collect human ratings on a held-out set of generated AV clips and compute correlation with AVBench continuous scores; correlation near zero or negative would indicate the scores do not align with human judgment.
Figures







read the original abstract
Rapid advances in audio-video (AV) generation have enabled high-fidelity synthesis with synchronized sound, particularly for human-related scenarios involving speech and interactions. Yet evaluation for AV generation remains at an early stage, with only a few coarse-grained benchmarks for human-related scenarios and relying on limited preset evaluations with generic multimodal LLMs, leading to inaccurate assessments of model capabilities. To address these issues, we introduce AVBench, a fully automated benchmark tailored for human-centric AV generation. AVBench is built on two key designs for comprehensive and accurate evaluation: (i) Human-centric and fine-grained metrics. AVBench integrates ten evaluation dimensions designed for human-centered real-world scenarios, covering visual quality, audio quality, and multi-level consistency across modalities. These practical metrics capture human-related details that existing benchmarks often overlook. (ii) Specialized evaluators via preference learning. To address the lack of specialized training data, we construct large-scale supervision by transforming real-world videos into diverse training pairs with controlled perturbations. After fine-tuning on this high-quality dataset, the evaluators learn to reliably detect subtle cross-modal inconsistencies. Crucially, instead of producing discrete textual judgment, AVBench derives continuous evaluation scores from the model's prediction confidence on binary decisions. This probabilistic scoring mechanism enables a more reliable assessment than traditional VQA-style evaluation and aligns closely with human judgment. Taken together, AVBench offers automated evaluation for AV generation, demonstrates strong potential for data filtering, and serves as a differentiable reward signal for Reinforcement Learning from Human Feedback (RLHF).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AVBench, a benchmark for automated evaluation of audio-video generative models focused on human-centric scenarios. It defines ten fine-grained metrics spanning visual quality, audio quality, and multi-level cross-modal consistency. Training data is created by applying controlled perturbations to real-world videos to form preference pairs; evaluators are fine-tuned on this data and produce continuous scores derived from prediction confidence on binary decisions rather than discrete VQA-style outputs. The work claims this yields stronger human alignment than generic multimodal LLMs and positions the benchmark for data filtering and use as a differentiable RLHF reward.
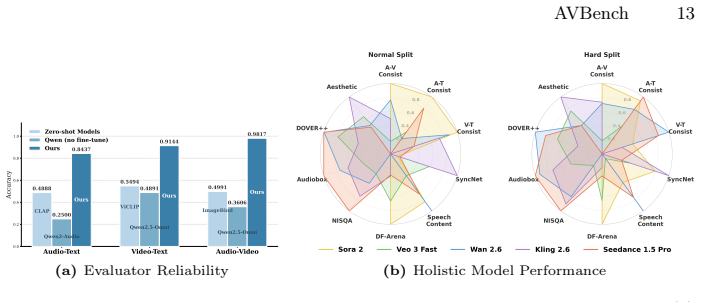
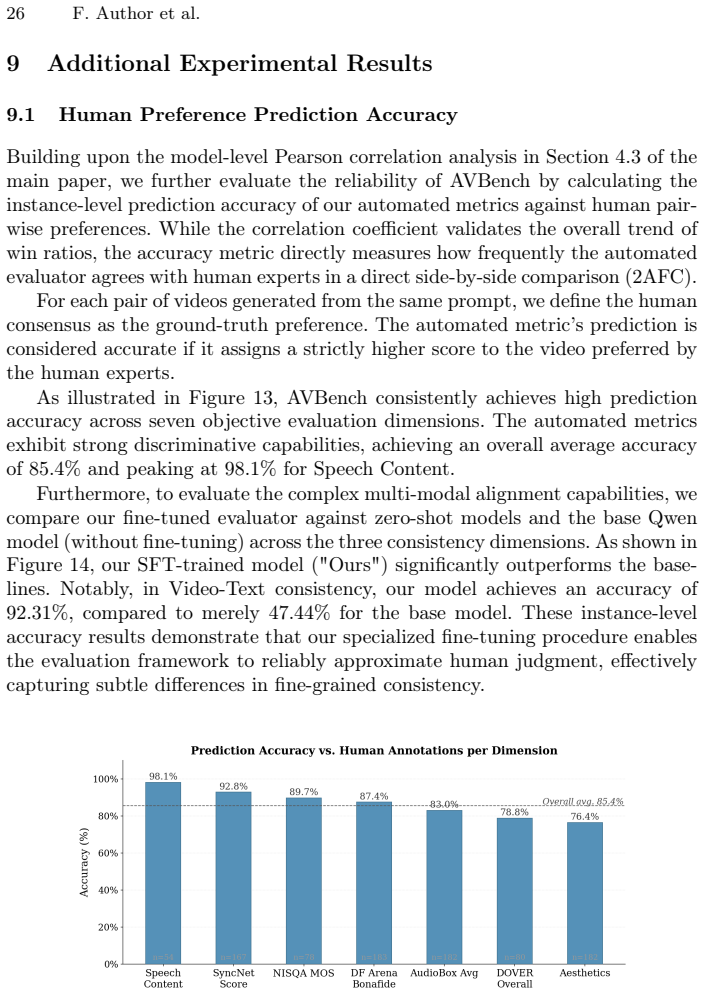
Significance. If the perturbation-trained evaluators prove calibrated on actual generator outputs and the continuous scores correlate with human judgments, AVBench would address a clear gap in scalable, automated AV evaluation. The probabilistic scoring mechanism and construction of large-scale synthetic supervision are technically interesting and could support downstream uses in filtering and RLHF; however, these strengths remain conditional on validation that is not yet demonstrated.
major comments (1)
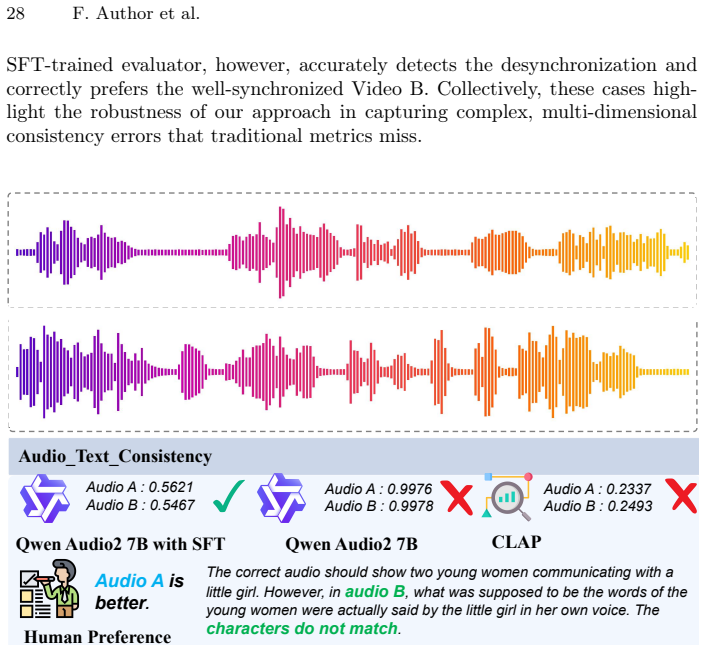
- Abstract: the central claim that fine-tuned evaluators 'learn to reliably detect subtle cross-modal inconsistencies' after training on perturbed real videos rests on the unverified assumption that the chosen perturbation distribution reproduces the actual failure modes of current AV generators (temporal desync, lip-motion drift, audio-visual hallucination). No experiments, ablations, or comparisons against model-generated content are described to test this match; without such evidence the continuous scores cannot be shown to be well-calibrated on the target distribution.
Simulated Author's Rebuttal
We thank the referee for highlighting this important assumption underlying our perturbation-based training approach. We address the concern point-by-point below and outline planned revisions.
read point-by-point responses
-
Referee: Abstract: the central claim that fine-tuned evaluators 'learn to reliably detect subtle cross-modal inconsistencies' after training on perturbed real videos rests on the unverified assumption that the chosen perturbation distribution reproduces the actual failure modes of current AV generators (temporal desync, lip-motion drift, audio-visual hallucination). No experiments, ablations, or comparisons against model-generated content are described to test this match; without such evidence the continuous scores cannot be shown to be well-calibrated on the target distribution.
Authors: We acknowledge that the manuscript does not include direct experiments applying the trained evaluators to outputs from current AV generative models or ablations comparing perturbation-induced failures against real generator artifacts. Our perturbation design (detailed in Section 3.2) targets documented failure modes from the AV generation literature, such as temporal misalignment and lip desynchronization, to create controlled preference pairs. However, this leaves open the question of distribution shift to actual model outputs. We agree this validation is necessary to fully support claims of calibration and human alignment on the target distribution. In the revised manuscript we will add a new subsection with experiments that (i) generate samples from representative AV models, (ii) obtain human preference labels on those samples, and (iii) compare evaluator scores against both human judgments and generic multimodal LLM baselines to quantify calibration on real generator outputs. revision: yes
Circularity Check
No circularity: evaluation pipeline is independent of target models
full rationale
The paper constructs large-scale supervision by applying controlled perturbations to real-world videos (external to any generative model outputs), fine-tunes evaluators on the resulting pairs, and derives continuous scores from the fine-tuned model's binary-decision confidence. No equations, self-citations, or fitted parameters are described that would make the final AVBench scores equivalent to the perturbation definitions or training inputs by construction. The chain remains self-contained against external benchmarks because the training distribution is deliberately chosen to be independent of the generative failure modes being measured.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world videos can be transformed into diverse training pairs with controlled perturbations that simulate generation artifacts for preference learning.
Reference graph
Works this paper leans on
-
[1]
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Cao, Z., Wang, T., Wang, J., Wang, Y., Zhang, Y., Chen, J., Deng, M., Wang, J., Guo, Y., Liao, C., et al.: T2av-compass: Towards unified evaluation for text-to- audio-video generation. arXiv preprint arXiv:2512.21094 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation
Chao, J., Gao, J., Tan, W., Sun, Y., Song, R., Ru, L.: Jointavbench: A benchmark for joint audio-visual reasoning evaluation. arXiv preprint arXiv:2512.12772 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: 2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI)
Chen, C.: Training generative judge with hard negative mining: A metric learning perspective. In: 2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI). pp. 778–785. IEEE (2025)
2025
-
[4]
arXiv preprint arXiv:2509.08519 (2025)
Chen, L., Ma, T., Liu, J., Li, B., Chen, Z., Liu, L., He, X., Li, G., He, Q., Wu, Z.: Humo:Human-centricvideogenerationviacollaborativemulti-modalconditioning. arXiv preprint arXiv:2509.08519 (2025)
-
[5]
Chu, Y., Xu, J., Yang, Q., Wei, H., Wei, X., Guo, Z., Leng, Y., Lv, Y., He, J., Lin, J., et al.: Qwen2-audio technical report. arXiv preprint arXiv:2407.10759 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Work- shop on Multi-view Lip-reading, ACCV (2016)
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Work- shop on Multi-view Lip-reading, ACCV (2016)
2016
-
[7]
IEEE Open Journal of Signal Pro- cessing pp
Dowerah, S., Kulkarni, A., Kulkarni, A., Tran, H.M., Kalda, J., Fedorchenko, A., Fauve, B., Lolive, D., Alumäe, T., Magimai.-Doss, M.: Speech df arena: A leader- board for speech deepfake detection models. IEEE Open Journal of Signal Pro- cessing pp. 1–9 (2026).https://doi.org/10.1109/OJSP.2026.3652496
-
[8]
In: ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP)
Elizalde, B., Deshmukh, S., Al Ismail, M., Wang, H.: Clap learning audio con- cepts from natural language supervision. In: ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[9]
In: CVPR (2023)
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: CVPR (2023)
2023
-
[10]
Google DeepMind: Veo 3.https://deepmind.google/technologies/veo/(2025), accessed: 2026-03-05
2025
-
[11]
Guo, X., Ye, F., Sun, Q., Chen, L., Li, B., Zhang, P., Liu, J., Zhao, S., He, Q., Hou, X.: Dreamid-omni: Unified framework for controllable human-centric audio-video generation. arXiv preprint arXiv:2602.12160 (2026)
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Haji-Ali, M., Menapace, W., Siarohin, A., Skorokhodov, I., Canberk, A., Lee, K.S., Ordonez, V., Tulyakov, S.: Av-link: Temporally-aligned diffusion features for cross- modal audio-video generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19373–19385 (2025)
2025
-
[13]
arXiv preprint arXiv:2405.17842 (2024) 16 F
Hayakawa, A., Ishii, M., Shibuya, T., Mitsufuji, Y.: Mmdisco: Multi-modal discriminator-guided cooperative diffusion for joint audio and video generation. arXiv preprint arXiv:2405.17842 (2024) 16 F. Author et al
-
[14]
VABench: A Comprehensive Benchmark for Audio-Video Generation
Hua, D., Wang, X., Zeng, B., Huang, X., Liang, H., Niu, J., Chen, X., Xu, Q., Zhang, W.: Vabench: A comprehensive benchmark for audio-video generation. arXiv preprint arXiv:2512.09299 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
- [16]
-
[17]
Li, C., Zhang, C., Xu, W., Lin, J., Xie, J., Feng, W., Peng, B., Chen, C., Xing, W.: Latentsync: Taming audio-conditioned latent diffusion models for lip sync with syncnet supervision. arXiv preprint arXiv:2412.09262 (2024)
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, H., Xu, M., Zhan, Y., Mu, S., Li, J., Cheng, K., Chen, Y., Chen, T., Ye, M., Wang, J., et al.: Openhumanvid: A large-scale high-quality dataset for enhanc- ing human-centric video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7752–7762 (2025)
2025
-
[19]
Proceed- ings of the International Conference on Machine Learning pp
Liu, H., Chen, Z., Yuan, Y., Mei, X., Liu, X., Mandic, D., Wang, W., Plumbley, M.D.: AudioLDM: Text-to-audio generation with latent diffusion models. Proceed- ings of the International Conference on Machine Learning pp. 21450–21474 (2023)
2023
-
[20]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Low, C., Wang, W., Katyal, C.: Ovi: Twin backbone cross-modal fusion for audio- video generation. arXiv preprint arXiv:2510.01284 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
In: Interspeech (2021),https://api.semanticscholar.org/CorpusID:233296150
Mittag, G., Naderi, B., Chehadi, A., Möller, S.: Nisqa: A deep cnn-self-attention model for multidimensional speech quality prediction with crowdsourced datasets. In: Interspeech (2021),https://api.semanticscholar.org/CorpusID:233296150
2021
-
[22]
OpenAI: Sora 2 Is Here.https://openai.com/index/sora-2/(2025), accessed: 2026-03-03
2025
-
[23]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[24]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Xu,T.,Brockman,G.,McLeavey,C.,Sutskever,I.:Robust speech recognition via large-scale weak supervision. In: International conference on machine learning. pp. 28492–28518. PMLR (2023)
2023
-
[25]
LAION-5B: An open large-scale dataset for training next generation image-text models
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kun- durthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., Jitsev, J.: Laion-5b: An open large-scale dataset for training next generation image-text models. ArXivabs/2210.08402(2022),https://api.semanticscholar....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Seedance, T., Chen, H., Chen, S., Chen, X., Chen, Y., Chen, Y., Chen, Z., Cheng, F., Cheng, T., Cheng, X., et al.: Seedance 1.5 pro: A native audio-visual joint generation foundation model. arXiv preprint arXiv:2512.13507 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
-
[28]
Vyas, A., Shi, B., Le, M., Tjandra, A., Wu, Y.C., Guo, B., Zhang, J., Zhang, X., Adkins, R., Ngan, W., Wang, J., Cruz, I., Akula, B., Akinyemi, A., Ellis, B., Moritz, R., Yungster, Y., Rakotoarison, A., Tan, L., Summers, C., Wood, C., Lane, J., Williamson, M., Hsu, W.N.: Audiobox: Unified audio generation with natural language prompts (2023),https://arxiv...
-
[29]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) AVBench 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
arXiv preprint arXiv:2601.04151 (2026)
Wang, J., Qiang, C., Guo, Y., Wang, Y., Zeng, X., Zhang, C., Wan, P.: Klear: Unified multi-task audio-video joint generation. arXiv preprint arXiv:2601.04151 (2026)
-
[31]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Chen, X., Wang, Y., Luo, P., Liu, Z., Wang, Y., Wang, L., Qiao, Y.: Internvid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wu,H.,Zhang,E.,Liao,L.,Chen,C.,Hou,J.,Wang,A.,Sun,W.,Yan,Q.,Lin,W.: Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 20144–20154 (2023)
2023
-
[33]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report (2025), https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., et al.: Qwen3-omni technical report. arXiv preprint arXiv:2509.17765 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
MISMATCHED
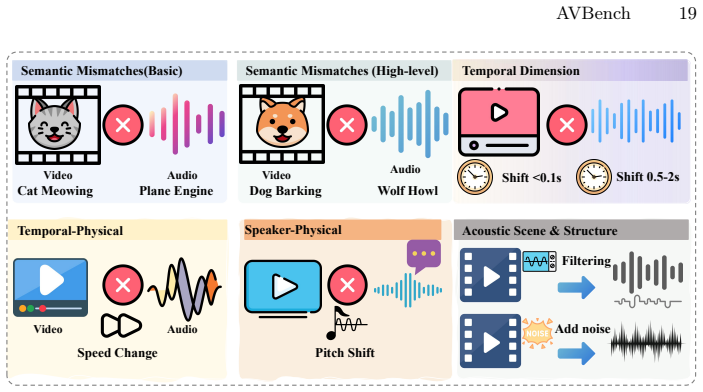
Yang, S., Lyu, Y., Chen, Z., Li, Y., Dong, B., Han, X., Yang, P., Wang, Z., Rao, A., Liu, Z., et al.: Human-centric content generation with diffusion models: A survey. Authorea Preprints (2026) 18 F. Author et al. 7 Extended Details on Negative Sample Construction 7.1 Negative Sample Construction Pipeline To systematically evaluate the fine-grained alignm...
2026
-
[37]
woman" with
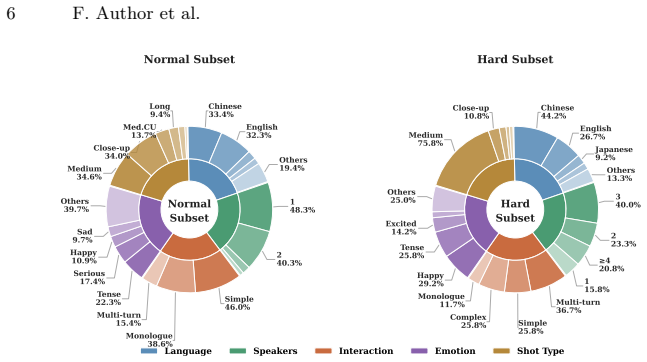
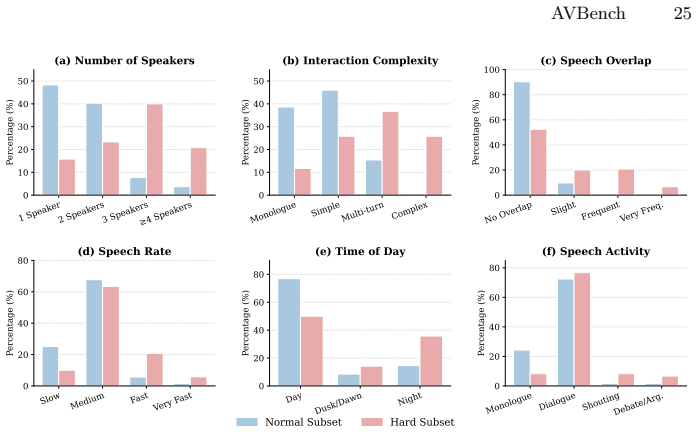
and aHard Subset(N= 120). This structured design is intended to provide a comprehensive assessment of the model’s capabilities across varying levels of difficulty. Fig. 12 illustrates the significant distribution shifts across six key dimensions. 8.1 Linguistic and Interaction Complexity The dataset exhibits high linguistic diversity, covering 15 language...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.