How Many Tools Should an LLM Agent See? A Chance-Corrected Answer
Pith reviewed 2026-06-30 12:19 UTC · model grok-4.3
The pith
A chance-corrected metric shows adaptive tool shortlists outperform fixed sizes for LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
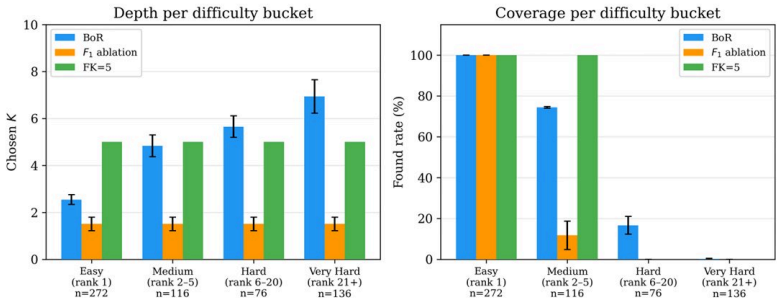
The paper claims that Bits-over-Random (BoR) supplies a standard metric for deciding tool shortlist depth and that an RL policy trained on BoR rewards yields adaptive depths whose coverage nearly matches showing 50 tools while averaging only 7, that the approach locates tools on hard queries where fixed lists of 5 fail, and that these shorter adaptive lists raise downstream LLM correct selection from 87.1% to 93.1% overall and from 60.9% to 76.8% on medium queries.
What carries the argument
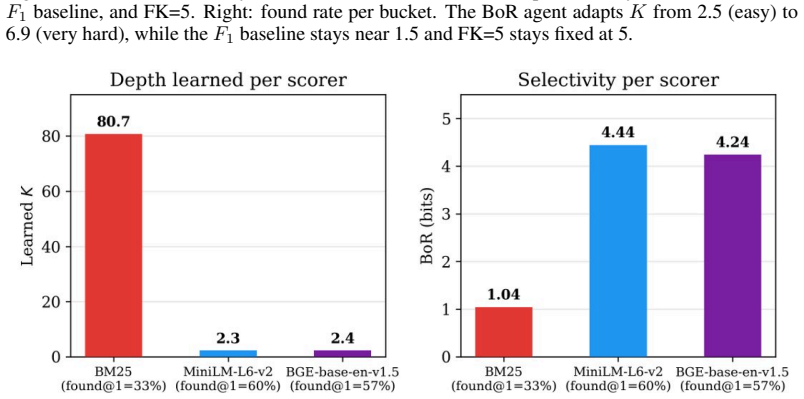
The Bits-over-Random (BoR) metric, which quantifies success at a given shortlist depth relative to random chance at that depth and serves as both an evaluation standard and an RL reward.
If this is right
- On BFCL with 370 tools, the adaptive policy reaches 90.3% coverage with an average of 7 tools versus 90.8% for a fixed list of 50.
- On ToolBench with 3,251 tools, the adaptive policy finds tools on hard queries where a fixed list of 5 finds none.
- Downstream LLM selection accuracy improves with adaptive lists, with the gap widening when the correct tool is not ranked first.
- The reward decreases automatically as lists grow, removing the need for an engineered depth penalty.
Where Pith is reading between the lines
- BoR could be tested as an evaluation standard for shortlist sizes in other retrieval settings such as document or API suggestion systems.
- The adaptive depths learned on one benchmark might transfer to new registries if the correlation between BoR and downstream accuracy holds.
- Larger-scale experiments could check whether optimal average depths scale predictably with registry size.
Load-bearing premise
The deliberately simple RL agent serves as a valid unbiased probe of the BoR metric without its policy learning process introducing confounding biases.
What would settle it
A head-to-head experiment in which fixed shortlist sizes achieve equal or higher downstream LLM tool selection accuracy than the BoR-adaptive policy on the same benchmarks would falsify the advantage of adaptive lists.
Figures
read the original abstract
Before an LLM agent can use a tool, a retrieval system must decide which candidate tools to show to the agent. How long should that shortlist be? Show too many tools and the model struggles to choose. Show too few and the correct tool may not appear. Most systems apply a fixed shortlist size to every query, but no standard metric exists to evaluate whether that size was appropriate. We treat the number of tools shown to an LLM agent as the object of evaluation and we apply Bits-over-Random (BoR), a chance-corrected metric that asks whether success at a given depth is better than what random selection would achieve at that same depth. We evaluate BoR across three tool-selection benchmarks, multiple scorers, and registries ranging from 20 to 3,251 tools. We then turn the same principle into a reinforcement learning (RL) reward for choosing tool shortlist depth per query. The RL agent is deliberately simple, serving as a probe of the metric rather than a proposed system. As the shortlist grows, random chance of including the correct tool rises, so the reward naturally decreases, reducing the need for an engineered depth penalty. On BFCL (370 tools), the learned policy nearly matches the coverage of showing 50 tools ($90.3\%$ vs $90.8\%$) while presenting only 7 on average. On ToolBench (3,251 tools), a fixed shortlist of 5 tools achieves higher aggregate coverage ($64.7\%$ vs $61.9\%$) but finds nothing on hard queries (correct tool ranked 6th-20th). The BoR agent finds $16.7\%$ on those same queries by searching deeper. Downstream validation with Claude Sonnet 4.6 indicates that shorter adaptive lists also improve the LLM's ability to select the right tool: $93.1\%$ versus $87.1\%$ when always shown 5 tools, widening to $76.8\%$ vs $60.9\%$ on medium-difficulty queries where the correct tool is present but not ranked first.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Bits-over-Random (BoR), a chance-corrected metric for evaluating whether a given tool shortlist depth is appropriate for an LLM agent. It evaluates BoR across three benchmarks with registries of 20–3,251 tools, then uses BoR-derived rewards in a deliberately simple RL agent (positioned as a probe, not a proposed system) to select adaptive per-query depths. The adaptive policy nearly matches fixed-50 coverage (90.3% vs 90.8%) at average depth 7 on BFCL, retrieves 16.7% on hard ToolBench queries where fixed-5 fails, and yields downstream gains with Claude Sonnet 4.6 (93.1% vs 87.1% tool-selection accuracy overall; 76.8% vs 60.9% on medium-difficulty queries).
Significance. If the results hold, the work supplies a principled, chance-corrected alternative to fixed shortlist sizes in tool retrieval for agents. The explicit probe framing of the RL agent and the inclusion of downstream LLM validation experiments are strengths. The approach could encourage adaptive retrieval strategies and improve efficiency-accuracy trade-offs in agent systems.
major comments (3)
- Abstract and methods: the abstract presents benchmark results and downstream validation but provides no exact definition or derivation of BoR, no error bars, and no full experimental protocol; without these the central claims cannot be verified or reproduced.
- RL probe section: the claim that the RL agent serves as an independent probe of BoR is load-bearing for the validation, yet the reward is defined directly from BoR and the policy is learned to maximize it on the same benchmarks; the reported accuracy gains (93.1% vs 87.1%; 76.8% vs 60.9%) may therefore be partly artifacts of the optimization rather than independent evidence for the metric.
- Results on BFCL/ToolBench: coverage numbers (e.g., 90.3% vs 90.8% on BFCL; 16.7% on hard queries) and accuracy figures lack error bars, confidence intervals, or statistical tests, weakening the reliability of the comparisons that support the adaptive-depth claim.
minor comments (2)
- The BoR formula should be stated explicitly as an equation in the main text to allow readers to confirm the chance-correction property.
- Figure and table captions should report the number of runs, random seeds, and any hyper-parameter settings used for the RL experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract and methods: the abstract presents benchmark results and downstream validation but provides no exact definition or derivation of BoR, no error bars, and no full experimental protocol; without these the central claims cannot be verified or reproduced.
Authors: The provided abstract does contain a concise definition of BoR ('a chance-corrected metric that asks whether success at a given depth is better than what random selection would achieve at that same depth'), but we agree it lacks a formal statement or pointer to the derivation. We will revise the abstract to include a brief mathematical definition of BoR and a reference to its derivation in Section 3. The full experimental protocol, including benchmark details, scorers, registries, and evaluation procedures, is already described in Sections 4 and 5; we will ensure these sections are explicitly cross-referenced from the abstract and methods. For error bars, we will add them in the revision for all reported metrics. revision: yes
-
Referee: RL probe section: the claim that the RL agent serves as an independent probe of BoR is load-bearing for the validation, yet the reward is defined directly from BoR and the policy is learned to maximize it on the same benchmarks; the reported accuracy gains (93.1% vs 87.1%; 76.8% vs 60.9%) may therefore be partly artifacts of the optimization rather than independent evidence for the metric.
Authors: This is a fair critique. The RL agent is positioned as a simple probe whose reward is BoR-derived, so the downstream gains with Claude Sonnet necessarily reflect optimization toward the metric rather than fully independent corroboration. The use of an unseen LLM provides partial separation, but we will revise the text to explicitly acknowledge this limitation, reframe the experiment as demonstrating the practical utility of BoR for adaptive selection (rather than independent validation), and avoid any implication of full independence. revision: partial
-
Referee: Results on BFCL/ToolBench: coverage numbers (e.g., 90.3% vs 90.8% on BFCL; 16.7% on hard queries) and accuracy figures lack error bars, confidence intervals, or statistical tests, weakening the reliability of the comparisons that support the adaptive-depth claim.
Authors: We agree that the absence of error bars, confidence intervals, and statistical tests weakens the presented comparisons. In the revised manuscript we will add error bars (standard deviation across multiple random seeds or bootstrap resampling) to all coverage and accuracy figures and include appropriate statistical tests (e.g., McNemar's test or paired t-tests) for the fixed-vs-adaptive comparisons on BFCL and ToolBench. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines BoR explicitly against an external random baseline at each depth and applies it for both static evaluation and as an RL reward. The RL component is framed as a deliberately simple probe of the metric, not a proposed system, and the central downstream claims (e.g., 93.1% vs 87.1% tool-selection accuracy) are measured on an independent external LLM (Claude Sonnet 4.6) using separate accuracy metrics on the same benchmarks. No equations reduce a reported result to a fitted parameter or self-citation by construction; no self-citations appear load-bearing; and no ansatz or uniqueness claim is imported from prior author work. The derivation chain is self-contained against external benchmarks and random baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Success rate at a given shortlist depth can be meaningfully compared against the probability of random inclusion at that same depth
Forward citations
Cited by 2 Pith papers
-
Looking Is Not Picking: An Attention-Segment Account of Tool-Selection Failures in LLM Agents
Attention analysis shows that LLM tool selection failures occur at the readout/decision stage, not because the model fails to attend to the correct tool definition.
-
ToolChoiceConfusion: Causal Minimal Tool Filtering for Reliable LLM Agents
CMTF is a causal filtering method that reduces tool exposure to one per step while matching baseline success rates and cutting token use by ~90% in 102-task benchmarks with 100 tools.
Reference graph
Works this paper leans on
-
[1]
Where to Stop Reading a Ranked List?: Threshold Optimization Using Truncated Score Distributions
Avi Arampatzis, Jaap Kamps, and Stephen Robertson. Where to Stop Reading a Ranked List?: Threshold Optimization Using Truncated Score Distributions. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 524–531, 2009
2009
-
[2]
Self-RAG: Learn- ing to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learn- ing to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Choppy: Cut Trans- former for Ranked List Truncation
Dara Bahri, Yi Tay, Che Zheng, Donald Metzler, and Andrew Tomkins. Choppy: Cut Trans- former for Ranked List Truncation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1721–1724, 2020
2020
-
[4]
Lu Dai, Yijie Xu, Jinhui Ye, Hao Liu, and Hui Xiong. SePer: Measure Retrieval Utility Through The Lens Of Semantic Perplexity Reduction.arXiv preprint arXiv:2503.01478, 2025
-
[5]
Tiantian Gan and Qiyao Sun. RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation.arXiv preprint arXiv:2505.03275, 2025
-
[6]
Smar- tRAG: Jointly Learn RAG-Related Tasks From the Environment Feedback
Jingsheng Gao, Linxu Li, Ke Ji, Weiyuan Li, Yixin Lian, Yuzhuo Fu, and Bin Dai. Smar- tRAG: Jointly Learn RAG-Related Tasks From the Environment Feedback. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11143–11156, 2024
2024
-
[8]
Shoichet, and John J
Niu Huang, Brian K. Shoichet, and John J. Irwin. Benchmarking Sets for Molecular Docking. Journal of Medicinal Chemistry, 49(23):6789–6801, 2006
2006
-
[9]
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use
Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, and Lichao Sun. MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[10]
Mohammed Iratni, Mohand Boughanem, and Taoufiq Dkaki. Dynamic Context Selection for Retrieval-Augmented Generation: Mitigating Distractors and Positional Bias.arXiv preprint arXiv:2512.14313, 2025
-
[11]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park. Adaptive- RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language Technologies, pages 7036–7050, 2024
2024
-
[12]
Yucheng Ji, Rui Meng, Zhiliang Li, and Daqing He. Curriculum Guided Reinforce- ment Learning for Efficient Multi-Hop Retrieval-Augmented Generation.arXiv preprint arXiv:2505.17391, 2025
-
[13]
Active Retrieval Augmented Generation
Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active Retrieval Augmented Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969– 7992, 2023
2023
-
[14]
LongFuncEval: Measuring the effectiveness of long context models for function calling,
Kiran Kate, Tejaswini Pedapati, Kinjal Basu, Yara Rizk, Vijil Chenthamarakshan, Subhajit Chaudhury, Mayank Agarwal, and Ibrahim Abdelaziz. LongFuncEval: Measuring the Ef- fectiveness of Long Context Models for Function Calling.arXiv preprint arXiv:2505.10570, 2025
-
[15]
Adaptive Document Retrieval for Deep Ques- tion Answering
Bernhard Kratzwald and Stefan Feuerriegel. Adaptive Document Retrieval for Deep Ques- tion Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 576–581, 2018
2018
-
[16]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, 2023. 10
2023
-
[17]
InfoRM: Mitigating Reward Hacking in RLHF via Information-Theoretic Reward Modeling
Yuchun Miao, Sen Zhang, Liang Ding, Rong Bao, Lefei Zhang, and Dacheng Tao. InfoRM: Mitigating Reward Hacking in RLHF via Information-Theoretic Reward Modeling. InAd- vances in Neural Information Processing Systems, volume 37, pages 134387–134429, 2024
2024
-
[18]
ToolSandbox: A Stateful, Conversational, Interactive Evalu- ation Benchmark for LLM Tool Use Capabilities
Jiarui Lu, Thomas Holleis, et al. ToolSandbox: A Stateful, Conversational, Interactive Evalu- ation Benchmark for LLM Tool Use Capabilities. InFindings of the Association for Compu- tational Linguistics: NAACL 2025, pages 1160–1183, 2025
2025
- [19]
-
[20]
Ranked List Truncation for Large Language Model-based Re-Ranking
Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, and Maarten de Rijke. Ranked List Truncation for Large Language Model-based Re-Ranking. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024
2024
-
[21]
Shuai Meng, Yue Liu, Ding Wang, et al. From Ranking to Selection: A Simple but Efficient Dynamic Passage Selector for Retrieval Augmented Generation.arXiv preprint arXiv:2508.09497, 2025
-
[22]
Less is More: Optimizing Function Calling for LLM Execution on Edge Devices
Varatheepan Paramanayakam, Andreas Karatzas, Iraklis Anagnostopoulos, and Dimitrios Sta- moulis. Less is More: Optimizing Function Calling for LLM Execution on Edge Devices. arXiv preprint arXiv:2411.15399, 2025
-
[23]
Dynamic Tool Dependency Retrieval for Lightweight Function Calling
Bhavin Patel, Davide Belli, Amir Jalalirad, Michael Arnold, Artem Ermovol, and Brendan Major. Dynamic Tool Dependency Retrieval for Efficient Function Calling.arXiv preprint arXiv:2512.17052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. InProceedings of the 42nd International Conference on Machine Learning. PMLR, 2025
2025
-
[25]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is All Tool Learning Needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hongjin Qian and Zheng Liu. Scent of Knowledge: Optimizing Search-Enhanced Reasoning with Information Foraging.arXiv preprint arXiv:2505.09316, 2025
-
[27]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
On the Robustness of Agentic Function Calling
Ella Rabinovich and Ateret Anaby-Tavor. On the Robustness of Agentic Function Calling. In Proceedings of the 5th Workshop on Trustworthy Natural Language Processing (TrustNLP), pages 298–304, 2025
2025
-
[29]
Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. Pro- cess vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning.arXiv preprint arXiv:2505.14069, 2025
-
[30]
The 99% Success Paradox: When Near-Perfect Retrieval Equals Random Selection
Vyzantinos Repantis, Harshvardhan Singh, Tony Joseph, Cien Zhang, Akash Vishwakarma, Svetlana Karslioglu, Michael Wyatt Thot, and Ameya Gawde. The 99% Success Paradox: When Near-Perfect Retrieval Equals Random Selection. InICLR Blogposts 2026, 2026
2026
-
[31]
Retrieval Models Aren’t Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models
Zhengliang Shi, Yue Wang, Langlin Yan, Peiyu Ren, Shuo Wang, Dawei Yin, and Zhaochun Ren. Retrieval Models Aren’t Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[32]
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
Joykirat Singh, Raghav Magazine, Yash Pandya, and Akshay Nambi. ARTIST: Agen- tic Reasoning and Tool Integration for LLMs via Reinforcement Learning.arXiv preprint arXiv:2505.01441, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Zhipeng Song, Yizhi Zhou, Xiangyu Kong, Jiulong Jiao, Xinrui Bao, Xu You, Xueqing Shi, Yuhang Zhou, and Heng Qi. Less is More for RAG: Information Gain Pruning for Generator- Aligned Reranking and Evidence Selection.arXiv preprint arXiv:2601.17532, 2026. 11
-
[34]
DynamicRAG: Leveraging Out- puts of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation
Jiashuo Sun, Xianrui Zhong, Sizhe Zhou, and Jiawei Han. DynamicRAG: Leveraging Out- puts of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[35]
Efficient Context Selection for Long- Context QA: No Tuning, No Iteration, Just Adaptive-k
Chihiro Taguchi, Seiya Maekawa, and Nikita Bhutani. Efficient Context Selection for Long- Context QA: No Tuning, No Iteration, Just Adaptive-k. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[36]
Early Recognition
Jean-François Truchon and Christopher I. Bayly. Evaluating Virtual Screening Methods: Good and Bad Metrics for the “Early Recognition” Problem.Journal of Chemical Information and Modeling, 47(2):488–508, 2007
2007
-
[37]
Zhao Wang, Ziliang Zhao, and Zhicheng Dou. ProRAG: Process-Supervised Reinforcement Learning for Retrieval-Augmented Generation.arXiv preprint arXiv:2601.21912, 2026
-
[38]
Yifan Xu, Vipul Gupta, Rohit Aggarwal, Varsha Mahadevan, and Bhaskar Krishnamachari. Cluster-based Adaptive Retrieval: Dynamic Context Selection for RAG Applications.arXiv preprint arXiv:2511.14769, 2025
-
[39]
Shunyu Yao et al.τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Wenqing Zheng, Dmitri Kalaev, Noah Fatsi, Daniel Barcklow, Owen Reinert, Igor Melnyk, Senthil Kumar, and C. Bayan Bruss. MIGRASCOPE: Revisiting RAG Retrievers: An Infor- mation Theoretic Benchmark.arXiv preprint arXiv:2602.21553, 2026
-
[41]
ToolRerank: Adap- tive and Hierarchy-Aware Reranking for Tool Retrieval
Yuanhang Zheng, Peng Li, Wei Liu, Yang Liu, Jian Luan, and Bin Wang. ToolRerank: Adap- tive and Hierarchy-Aware Reranking for Tool Retrieval. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16263–16273, 2024. A Retrieval Validation We validate BoR on three d...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.