VaaWIT: Visual-Aware Adaptation of Large Language Models for Multilingual Web Image Translation
Pith reviewed 2026-06-30 13:30 UTC · model grok-4.3
The pith
VaaWIT adapts large language models for multilingual web image translation by using bidirectional attention and a visual adapter to close the fine-grained visual gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
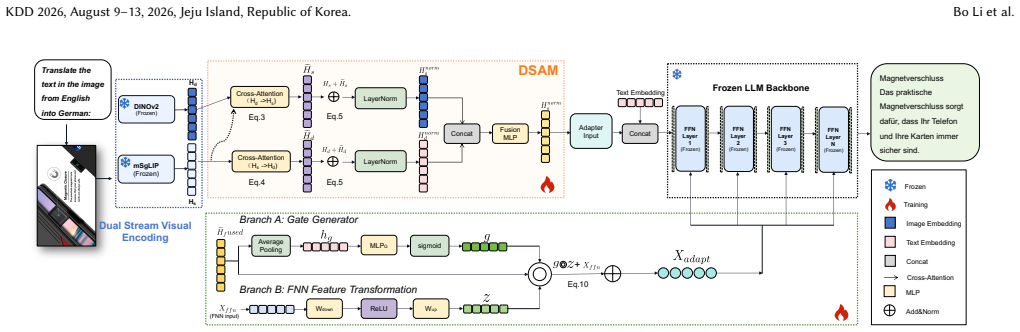
VaaWIT is an end-to-end adaptation framework that adds a Dual-Stream Attention Module to create bidirectional exchanges between multilingual semantic features and fine visual details, producing unified representations robust to character variations, and a Visual-Aware Adapter that injects the resulting cues into a frozen LLM backbone in a parameter-efficient manner, thereby aligning visual context with linguistic reasoning for multilingual web image translation.
What carries the argument
The Dual-Stream Attention Module (DSAM) that performs bidirectional interaction between multilingual semantic features and detailed visual representations to synthesize unified robust features, together with the Visual-Aware Adapter (VAA) that dynamically injects the fused cues into the LLM.
If this is right
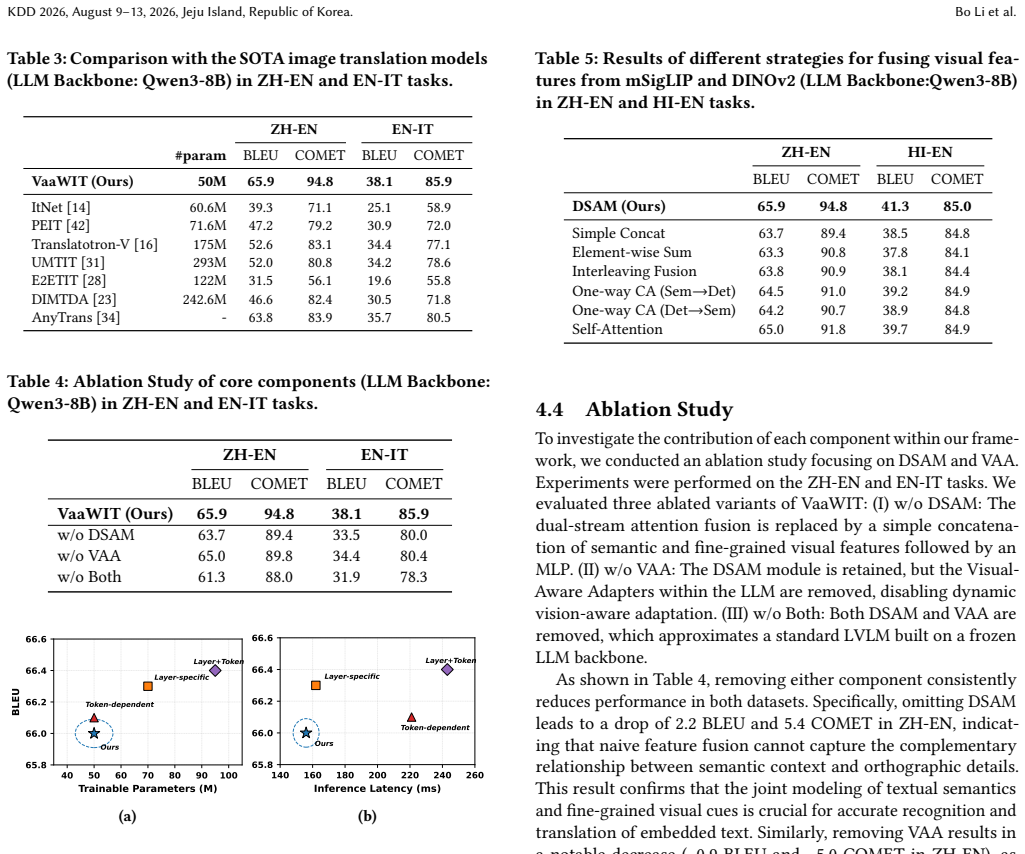
- Outperforms state-of-the-art open-source baselines on eight tasks across three public benchmarks.
- Reaches competitive performance against proprietary models.
- Aligns visual context with linguistic reasoning while keeping computational costs low through parameter-efficient updates.
- Produces features robust to textual variations in web images.
Where Pith is reading between the lines
- The same adapter pattern could be tried on other vision-language tasks that need fine visual detail such as scene text recognition or document understanding.
- Because the language model stays frozen, the approach may scale to larger backbones with modest added training cost.
- Performance on real social media and e-commerce images suggests the method could reduce reliance on manual translation services for cross-language content.
Load-bearing premise
The visual representation gap is the main bottleneck and the proposed bidirectional module plus adapter will reliably produce robust features for diverse character shapes without creating new failure modes.
What would settle it
Direct evaluation on the three public benchmarks where VaaWIT fails to exceed the accuracy of current open-source baselines on the eight tasks.
Figures

read the original abstract
Translating text embedded in Web images is crucial for improving content accessibility and cross-lingual information retrieval, particularly within social media and e-commerce domains. Although Large Vision-Language Models (LVLMs) have advanced multimodal understanding, applying them to Web image translation remains challenging due to the visual representation gap: standard encoders often prioritize high-level semantics over the fine-grained visual details required for recognizing diverse character morphologies. To address this challenge, we propose VaaWIT, an end-to-end framework that adapts Large Language Models for multilingual Web image translation. The framework introduces two key technical contributions: (1) a Dual-Stream Attention Module (DSAM), which facilitates bidirectional interaction between multilingual semantic features and detailed visual representations, thereby synthesizing unified features robust to textual variations; and (2) a Visual-Aware Adapter (VAA), a parameter-efficient fine-tuning strategy that dynamically injects these fused visual cues into the frozen LLM backbone. This design enables the model to align the visual context with linguistic reasoning effectively while minimizing computational costs. Extensive experiments on eight tasks on three public benchmarks demonstrate that VaaWIT significantly outperforms state-of-the-art (SOTA) open-source baselines and achieves competitive performance against proprietary models. These results validate the efficacy of integrating fine-grained visual perception into LLMs for complex Web content analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VaaWIT, an end-to-end framework adapting Large Language Models for multilingual Web image translation. It introduces a Dual-Stream Attention Module (DSAM) to enable bidirectional interaction between multilingual semantic features and detailed visual representations for synthesizing unified features robust to textual variations, and a Visual-Aware Adapter (VAA) as a parameter-efficient fine-tuning strategy to dynamically inject these fused visual cues into a frozen LLM backbone. Experiments across eight tasks on three public benchmarks show that VaaWIT significantly outperforms state-of-the-art open-source baselines and achieves competitive performance against proprietary models.
Significance. If the reported gains hold under scrutiny, the work provides a practical, efficient solution to the visual representation gap in LVLMs for fine-grained text recognition in web images with diverse character morphologies. The parameter-efficient design and focus on web content accessibility are strengths that could support broader applications in cross-lingual retrieval.
minor comments (2)
- [Abstract] Abstract: the claim of significant outperformance would be strengthened by including at least one concrete metric (e.g., accuracy or BLEU) and the names of the three benchmarks.
- [Method] The integration points of VAA into the LLM layers and the exact form of the bidirectional interaction in DSAM would benefit from an additional diagram or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of VaaWIT, the recognition of its practical contributions to multilingual web image translation, and the recommendation for minor revision.
Circularity Check
No significant circularity; framework is empirical with external validation
full rationale
The paper introduces DSAM and VAA as architectural modules for adapting LVLMs, with performance claims resting on experiments across eight tasks on three public benchmarks. No equations, derivations, or parameter-fitting steps are described that would reduce predictions to inputs by construction. No self-citation chains are invoked to justify uniqueness or ansatzes. The central claims are falsifiable via the reported benchmark comparisons and do not rely on self-referential definitions.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Dual-Stream Attention Module (DSAM)
no independent evidence
-
Visual-Aware Adapter (VAA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
AI@Meta. 2024. Llama 3 Model Card.llama.com(2024). https://github.com/meta- llama/llama3/blob/main/MODEL_CARD.md
2024
-
[3]
Dzmitry Bahdanau. 2014. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-VL Technical Report. (2025). arXiv:2511.21631 [cs.CV] https://arxiv.org/abs/2511. 21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198
2024
-
[6]
Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Ben- gio. 2014. On the properties of neural machine translation: Encoder–decoder approaches. InProceedings of SSST-8, eighth workshop on syntax, semantics and structure in statistical translation. 103–111
2014
-
[7]
DeepMind and Google. 2025. Gemini Pro — Google DeepMind.DeepMind / Google(2025). https://deepmind.google/models/gemini/pro/
2025
- [8]
-
[9]
Team Gemini. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530 [cs.CL] https://arxiv.org/abs/ 2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2017. Non-autoregressive neural machine translation.arXiv preprint arXiv:1711.02281 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. InInternational conference on machine learning. PMLR, 2790–2799
2019
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[14]
Puneet Jain, Orhan Firat, Qi Ge, and Sihang Liang. 2021. Image translation network.Github.com(2021)
2021
- [15]
-
[16]
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, Min Zhang, and Jinsong Su. 2024. Translatotron-V (ison): An end-to-end model for in-image machine translation. InFindings of the Association for Computational Linguistics: ACL 2024. 5472–5485
2024
- [17]
-
[18]
Bo Li, Ningyuan Deng, Tianyu Dong, Shaobo Wang, Shaolin Zhu, and Lijie Wen
-
[19]
MNAFT: modality neuron-aware fine-tuning of multimodal large language models for image translation.Science China Information Sciences69, 5 (2026), 150104
2026
-
[20]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Bo Li, Shaolin Zhu, and Lijie Wen. 2025. MIT-10M: A large scale parallel corpus of multilingual image translation. InProceedings of the 31st International Conference on Computational Linguistics. 5154–5167
2025
- [22]
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[24]
Yupu Liang, Yaping Zhang, Cong Ma, Zhiyang Zhang, Yang Zhao, Lu Xiang, Chengqing Zong, and Yu Zhou. 2024. Document Image Machine Translation with Dynamic Multi-pre-trained Models Assembling. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
-
[25]
Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al . 2023. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. LLaVA-NeXT: Improved reasoning, OCR, and world knowl- edge. https://llava-vl.github.io/blog/2024-01-30-llava-next/
2024
-
[27]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. 2024. Deepseek-vl: towards real- world vision-language understanding.arXiv preprint arXiv:2403.05525(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Cong Ma, Yaping Zhang, Mei Tu, Xu Han, Linghui Wu, Yang Zhao, and Yu Zhou
-
[30]
Improving End-to-End Text Image Translation From the Auxiliary Text Translation Task.2022 26th International Conference on Pattern Recognition (ICPR) (2022), 1664–1670
2022
-
[31]
Cong Ma, Yaping Zhang, Mei Tu, Yang Zhao, Yu Zhou, and Chengqing Zong
-
[32]
InInternational Conference on Document Analysis and Recognition
Multi-teacher knowledge distillation for end-to-end text image machine translation. InInternational Conference on Document Analysis and Recognition. Springer, 484–501
- [33]
-
[34]
Liqiang Niu, Fandong Meng, and Jie Zhou. 2024. UMTIT: Unifying Recognition, Translation, and Generation for Multimodal Text Image Translation. InProceed- ings of the 2024 Joint International Conference on Computational Linguistics, Lan- guage Resources and Evaluation (LREC-COLING 2024), Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, ...
2024
-
[35]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting on Association for Computational Linguistics(Philadelphia, Penn- sylvania)(ACL ’02). Association for Computational Linguistics, USA, 311–318. doi:10.3115/1073083.1073135
-
[37]
Zhipeng Qian, Pei Zhang, Baosong Yang, Kai Fan, Yiwei Ma, Derek F Wong, Xiaoshuai Sun, and Rongrong Ji. 2024. Anytrans: Translate anytext in the im- age with large scale models. InFindings of the Association for Computational Linguistics: EMNLP 2024. 2432–2444
2024
-
[38]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PMLR, 8748–8763
2021
-
[39]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. COMET: A Neural Framework for MT Evaluation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 2685–2702. doi:10.18653/v1/2020.emnlp-main.213
- [40]
-
[41]
I Sutskever. 2014. Sequence to Sequence Learning with Neural Networks.arXiv preprint arXiv:1409.3215(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. 24824–24837
2022
-
[43]
Yongjing Yin, Jiali Zeng, Jinsong Su, Chulun Zhou, Fandong Meng, Jie Zhou, Degen Huang, and Jiebo Luo. 2023. Multi-modal graph contrastive encoding for neural machine translation.Artificial Intelligence323 (2023), 103986
2023
-
[44]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid loss for language image pre-training. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 11975–11986
2023
-
[45]
Translate the text in the image from [Source Language] into [Target Language]:
Shaolin Zhu, Shangjie Li, Yikun Lei, and Deyi Xiong. 2023. PEIT: bridging the modality gap with pre-trained models for end-to-end image translation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13433–13447. VaaWIT: Visual-Aware Adaptation of Large Language Models for Multilingual Web Im...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.