Exploration of Perceptual Speech Features for Clinical Decision-Support in Mental Health Care
Pith reviewed 2026-06-30 13:17 UTC · model grok-4.3
The pith
A feature analysis framework finds stable links between speech irregularities and symptom severity in depression, anxiety, and ADHD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
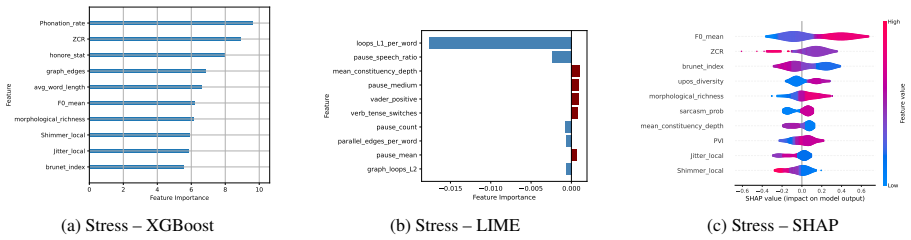
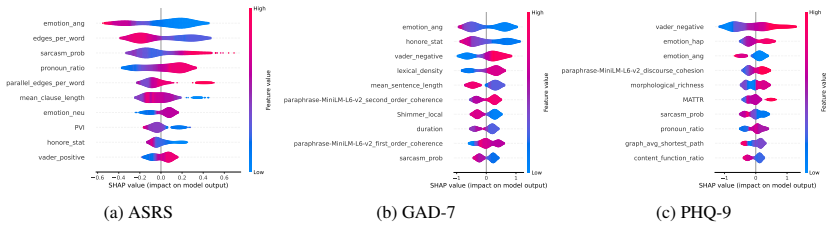
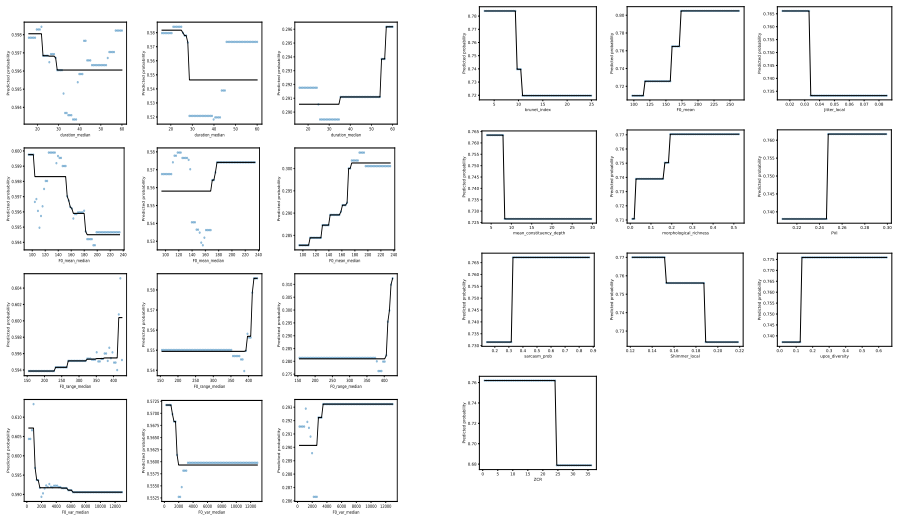
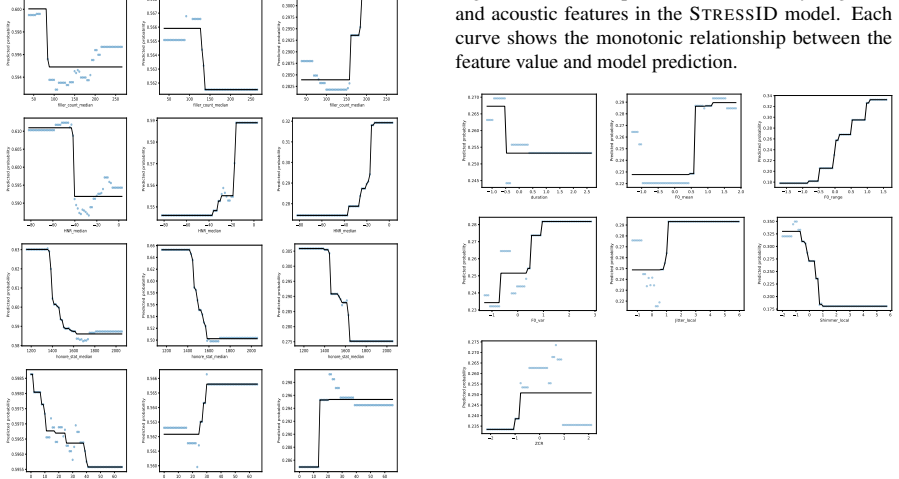
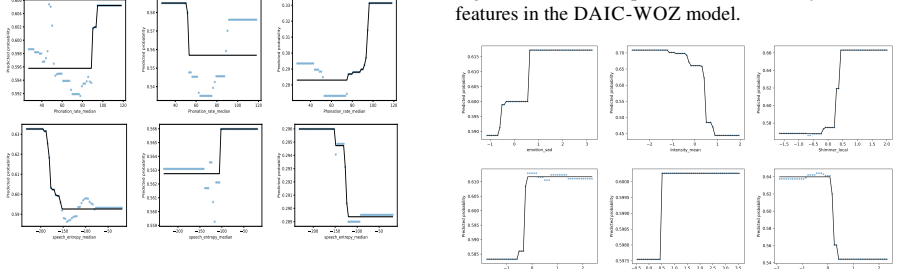
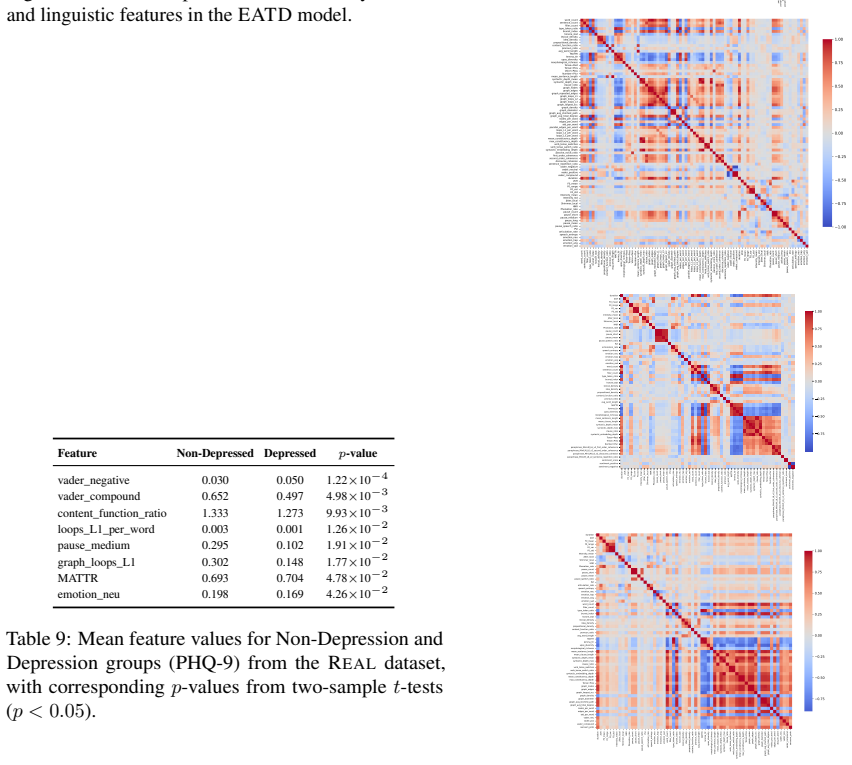
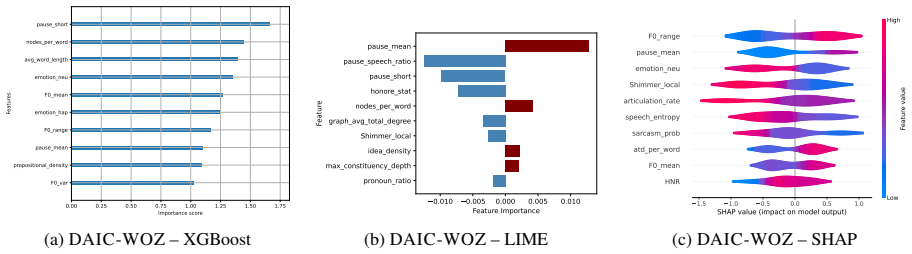
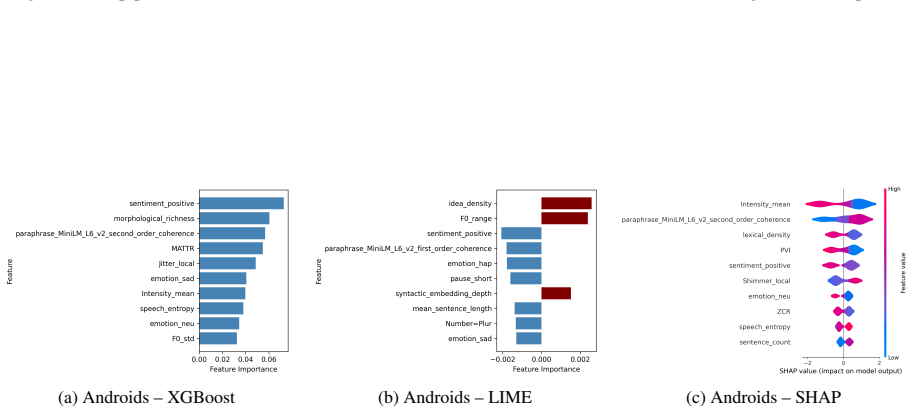
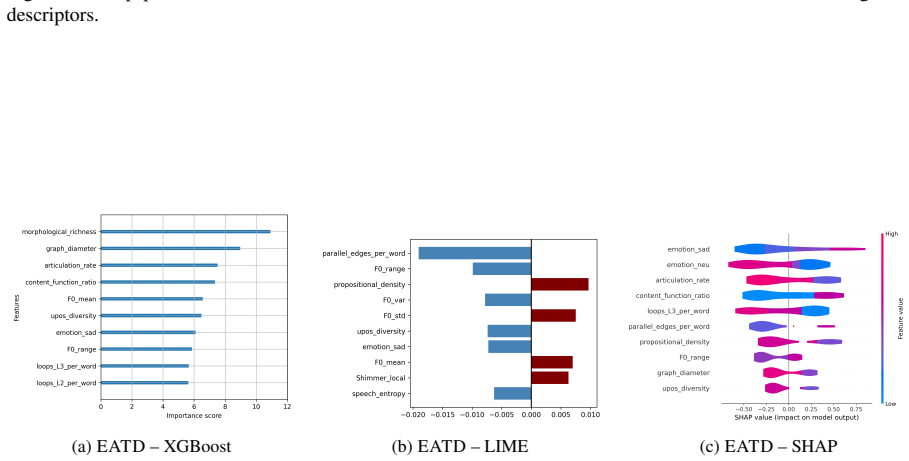
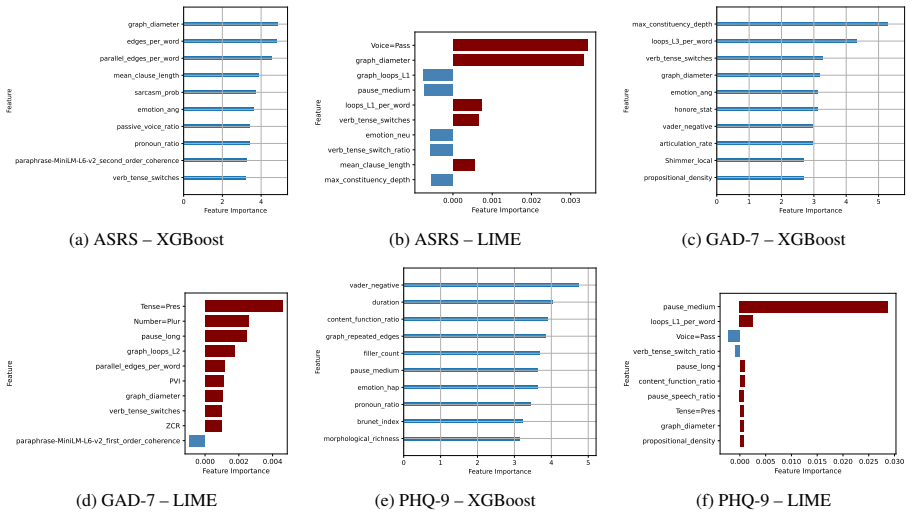
Using a systematic feature-based analysis framework leveraging perceptually grounded acoustic and linguistic characteristics, including prosody, vocal quality, semantic coherence, syntactic structure, and sarcasm, and applying statistical analysis and interpretable machine learning (XGBoost with SHAP and LIME), the paper examines associations between speech features and validated symptom measures of depression, anxiety, and ADHD. Evaluated on controlled benchmark datasets and a real-world clinical dataset, the framework reveals stable and consistent relationships between symptom severity and vocal irregularities (e.g., shimmer, jitter), lexical-syntactic patterns, and affective tone.
What carries the argument
Perceptually grounded acoustic features (prosody, vocal quality) and linguistic features (semantic coherence, syntactic structure, sarcasm) analyzed through statistical methods and interpretable machine learning (XGBoost with SHAP and LIME) to identify associations with symptom severity.
If this is right
- Symptom severity of depression, anxiety, and ADHD shows consistent ties to vocal irregularities such as shimmer and jitter.
- Lexical-syntactic patterns and affective tone provide additional stable indicators of symptom levels across datasets.
- The associations persist when the same framework is applied to both controlled benchmarks and real clinical recordings.
- Ablation across datasets isolates the feature groups that contribute most to the observed relationships.
- The method supplies objective, interpretable cues that can support clinical decision-making in mental health care.
Where Pith is reading between the lines
- If the identified feature relationships hold in longitudinal recordings, the framework could track symptom change over time without repeated clinical visits.
- Combining these speech features with other observable signals such as facial movement or heart-rate variability could increase the reliability of automated screening.
- The same perceptual feature set might be tested on additional conditions such as bipolar disorder or PTSD to check for overlapping or distinct patterns.
- Deployment in mobile apps could allow non-clinical users to obtain preliminary indicators that prompt professional evaluation.
Load-bearing premise
The chosen perceptual acoustic and linguistic features remain reliably associated with validated symptom measures when moving from controlled benchmark datasets to real-world clinical recordings.
What would settle it
Absence of the reported correlations between features such as shimmer, jitter, lexical-syntactic patterns, and symptom severity scores in a new independent collection of real-world clinical speech recordings would falsify the claim of stable relationships.
Figures

read the original abstract
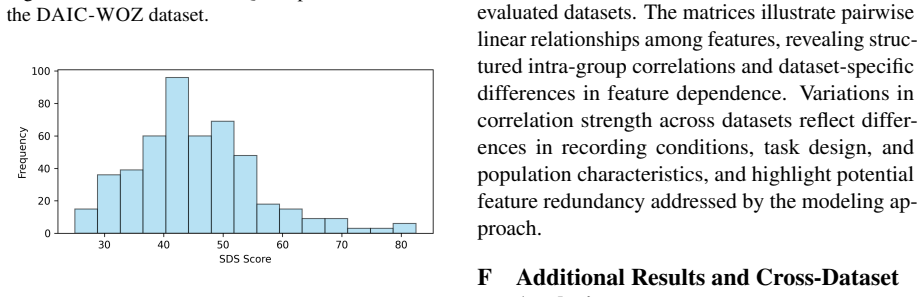
Speech and language technologies offer valuable opportunities for supporting mental health assessment through objective and interpretable cues. We present a systematic feature-based analysis framework leveraging perceptually grounded acoustic and linguistic characteristics, including prosody, vocal quality, semantic coherence, syntactic structure, and sarcasm. Using statistical analysis and interpretable machine learning (XGBoost with SHAP and LIME), we examine associations between speech features and validated symptom measures of depression, anxiety, and ADHD. Evaluated on both controlled benchmark datasets (StressID, DAIC-WOZ, Androids, EATD) and a real-world clinical dataset, the framework reveals stable and consistent relationships between symptom severity and vocal irregularities (e.g., shimmer, jitter), lexical-syntactic patterns, and affective tone. An ablation study conducted across all datasets further identifies the most informative feature groups. This work explores a transparent and clinically interpretable approach to speech-based mental health analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic feature-based analysis framework that extracts perceptually grounded acoustic (prosody, vocal quality) and linguistic (semantic coherence, syntactic structure, sarcasm) features from speech and examines their associations with validated symptom measures of depression, anxiety, and ADHD. It applies statistical analysis together with interpretable ML (XGBoost + SHAP/LIME) to both controlled benchmark corpora (StressID, DAIC-WOZ, Androids, EATD) and a real-world clinical dataset, asserts that the same features exhibit stable directional relationships with symptom severity, and reports an ablation study identifying the most informative feature groups.
Significance. If the claimed cross-dataset stability were quantitatively demonstrated, the work would offer a transparent, clinically interpretable route to speech-based mental-health decision support. The use of perceptual features and ablation analysis aligns with the need for explainable methods in healthcare AI.
major comments (2)
- [Abstract] Abstract: the central claim that the framework 'reveals stable and consistent relationships' between symptom severity and vocal irregularities (shimmer, jitter), lexical-syntactic patterns, and affective tone across benchmark and real-world datasets is unsupported by any cross-dataset metric (effect-size correlation, Kendall-tau rank agreement, or dataset-type × feature interaction test). Per-dataset significance tests alone cannot establish that the associations survive changes in recording conditions and unmeasured covariates.
- [Abstract] Abstract and results sections: the ablation study is described as identifying the most informative feature groups, yet the manuscript supplies no quantitative results, error bars, sample sizes, or statistical controls, rendering the claim that particular feature groups are most informative unevaluable.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the two major comments below and will revise the manuscript to provide the requested quantitative support for cross-dataset stability and the ablation study.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework 'reveals stable and consistent relationships' between symptom severity and vocal irregularities (shimmer, jitter), lexical-syntactic patterns, and affective tone across benchmark and real-world datasets is unsupported by any cross-dataset metric (effect-size correlation, Kendall-tau rank agreement, or dataset-type × feature interaction test). Per-dataset significance tests alone cannot establish that the associations survive changes in recording conditions and unmeasured covariates.
Authors: We agree that the current presentation relies on per-dataset directional consistency without formal cross-dataset aggregation. In the revision we will add Kendall-tau rank correlations on SHAP-based feature importance orderings across the five datasets and Pearson correlations of the per-feature effect sizes (or regression coefficients) between dataset pairs. These metrics, together with a brief dataset-type interaction analysis where feasible, will be reported in a new results subsection and the abstract will be updated to reference them. revision: yes
-
Referee: [Abstract] Abstract and results sections: the ablation study is described as identifying the most informative feature groups, yet the manuscript supplies no quantitative results, error bars, sample sizes, or statistical controls, rendering the claim that particular feature groups are most informative unevaluable.
Authors: We acknowledge that the main text currently summarizes the ablation outcomes only qualitatively. The revision will insert a main-text table that reports, for each dataset, the change in model performance (AUC or Pearson r) when each feature group is removed, together with standard deviations obtained from 5-fold cross-validation, the number of samples per condition, and paired statistical tests (e.g., DeLong or Williams tests) for the significance of the performance drops. The abstract will be edited to point to these quantitative results. revision: yes
Circularity Check
No circularity: purely empirical analysis on external datasets with no derivations or self-referential predictions.
full rationale
The manuscript describes a feature-based statistical and ML analysis (XGBoost + SHAP/LIME) of acoustic and linguistic features against symptom scores on independent benchmark corpora and one clinical set. No equations, parameter-fitting steps, or predictions are presented that could reduce to the inputs by construction. The central claim of observed associations is an empirical result, not a definitional or fitted tautology. Any self-citations (none load-bearing in the supplied text) do not substitute for external validation or create a self-referential chain. This is the normal case of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Armen C Arevian, Daniel Bone, Nikolaos Malandrakis, Victor R Martinez, Kenneth B Wells, David J Mik- lowitz, and Shrikanth Narayanan
Reflections of depression in acoustic measures of the patient’s speech.Journal of affective disorders, 66(1):59–69. Armen C Arevian, Daniel Bone, Nikolaos Malandrakis, Victor R Martinez, Kenneth B Wells, David J Mik- lowitz, and Shrikanth Narayanan. 2020. Clini- cal state tracking in serious mental illness through computational analysis of speech.PLoS one...
2020
-
[2]
InAdvances in Neural Information Process- ing Systems, volume 36, pages 29798–29811
Stressid: a multimodal dataset for stress identi- fication. InAdvances in Neural Information Process- ing Systems, volume 36, pages 29798–29811. Curran Associates, Inc. Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages...
2016
-
[3]
Methods, 151:41–54
Speech analysis for health: Current state-of- the-art and the increasing impact of deep learning. Methods, 151:41–54. Nicholas Cummins, Stefan Scherer, Jarek Krajewski, Sebastian Schnieder, Julien Epps, and Thomas F Quatieri. 2015. A review of depression and suicide risk assessment using speech analysis.Speech com- munication, 71:10–49. Jacob Devlin, Ming...
2015
-
[4]
Towards A Rigorous Science of Interpretable Machine Learning
Understanding the association between humor and emotional distress: The role of light and dark humor in predicting depression, anxiety, and stress. Europe’s Journal of Psychology, 19(4):358. Jon Donnelly, Luke Moffett, Alina Jade Barnett, Hari Trivedi, Fides Schwartz, Joseph Lo, and Cynthia Rudin. 2024. Asymmirai: interpretable mammography-based deep lear...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Eric Ettore, Philipp Müller, Jonas Hinze, Michel Benoit, Bruno Giordana, Danilo Postin, Amandine Lecomte, Hali Lindsay, P
Language production strategies and disfluen- cies in multi-clause network descriptions: a study of adult attention-deficit/hyperactivity disorder.Neu- ropsychology, 25(4):442. Eric Ettore, Philipp Müller, Jonas Hinze, Michel Benoit, Bruno Giordana, Danilo Postin, Amandine Lecomte, Hali Lindsay, P. Robert, and Alexandra König. 2022. Digital phenotyping for...
2022
-
[6]
InProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 3123– 3128, Reykjavik, Iceland
The distress analysis interview corpus of human and computer interviews. InProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 3123– 3128, Reykjavik, Iceland. European Language Re- sources Association (ELRA). James J Gross and Hooria Jazaieri. 2014. Emotion, emo- tion regulation, and psychopathology: An ...
2014
-
[7]
Andreas Holzinger, Georg Langs, Helmut Denk, Kurt Zatloukal, and Heimo Müller
A survey of methods for explaining black box models.ACM computing surveys (CSUR), 51(5):1– 42. Andreas Holzinger, Georg Langs, Helmut Denk, Kurt Zatloukal, and Heimo Müller. 2019. Causability and explainability of artificial intelligence in medicine. Wiley interdisciplinary reviews: data mining and knowledge discovery, 9(4):e1312. Matthew Honnibal, Ines M...
2019
-
[8]
InInterspeech 2019, pages 3890–3894
Interpretable Deep Learning Model for the Detection and Reconstruction of Dysarthric Speech. InInterspeech 2019, pages 3890–3894. Roman Kotov, Robert Krueger, David Watson, Thomas Achenbach, Robert Althoff, R. Bagby, Timothy Brown, William Carpenter, Avshalom Caspi, Lee Clark, Nicholas Eaton, Miriam Forbes, Kelsie For- bush, David Goldberg, Deborah Hasin,...
2019
-
[9]
Scott M Lundberg and Su-In Lee
Automated assessment of psychiatric disorders using speech: A systematic review.Laryngoscope investigative otolaryngology, 5(1):96–116. Scott M Lundberg and Su-In Lee. 2017. A unified ap- proach to interpreting model predictions.Advances in neural information processing systems, 30. Felix Menne, Felix Dörr, Julia Schräder, Johannes Tröger, Ute Habel, Alex...
2017
-
[10]
A tutorial on clinical speech ai development: From data collection to model validation.arXiv preprint arXiv:2410.21640. Stavros Ntalampiras. 2025. Interpretable probabilis- tic identification of depression in speech.Sensors, 25(4):1270. James W Pennebaker and Laura A King. 1999. Lin- guistic styles: language use as an individual differ- ence.Journal of pe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.